PaddleSeg之语义分割模型训练
1.PaddleSeg框架搭建
1.1硬件环境
ubuntu1804,GPU:2080Ti,cuda-11.1,nvidia-470
1.2软件环境
1.源码下载
国内的gitee网速比github快,代码都是一样的。
git clone https://github.com/PaddlePaddle/PaddleSeg.git (国外)
OR
git clone https://gitee.com/paddlepaddle/PaddleSeg.git (国内)
# 训练过程和模型可视化源码
git clone https://gitee.com/paddlepaddle/VisualDL.git
2.创建环境
主要采用conda进行环境的创建和管理,IDE采用pycharm,这里就不介绍conda和pycharm的安装了。
#conda创建环境并进入
conda create -n paddleseg python=3.7
source activate paddleseg
#安装依赖包
cd PaddleSeg
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
#安装nccl 用于多卡训练
https://developer.nvidia.com/nccl/nccl2-download-survey
sudo dpkg -i nccl-local-repo-ubuntu1804-2.8.4-cuda11.1_1.0-1_amd64.deb
sudo apt update
sudo apt install libnccl2 libnccl-dev
3.paddlepaddle安装
进入官网https://www.paddlepaddle.org.cn/,根据自己的需求进行安装。
python3.7 -m pip install paddlepaddle-gpu==2.3.2.post111 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html

2.模型训练
2.1数据准备
第1步:通过labelme标注的分割数据集通过json2png.py转换成png标签图像,labelme需要自己安装。
python3 json2png.py -p [image+json文件目录] -i modle_train_dataset/images -l modle_train_dataset/annotations
-p:数据标注image+json文件夹
-i:保存的训练图像文件夹
-l:保存的训练label png图像文件夹
下面是json2png.py的源码,供参考。
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import numpy as np
import yaml
from labelme import utils
import shutil
import time
# 这个是类别,可根据自己的需求自行添加
label_name_to_value = {
"_background_":0,
"class1":1,
"class2":2,
"class3":3,
"class4":4}
def main():
parser = argparse.ArgumentParser(description="JsonToImage")
parser.add_argument('-p', '--path', default=None)
parser.add_argument('-i', '--imgpath', default=None)
parser.add_argument('-l', '--labelpath', default=None)
args = parser.parse_args()
saveimgpath = args.imgpath
savelabelpath = args.labelpath
if args.path:
json_file = args.path
else:
assert ("没有传入json路径")
list_path = list(filter(lambda x: '.json' in x,os.listdir(json_file)))
print('freedom =', json_file)
for i in range(0, len(list_path)):
path = os.path.join(json_file, list_path[i])
if os.path.isfile(path):
data = json.load(open(path))
img = utils.img_b64_to_arr(data['imageData'])
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['%d: %s' % (l, name) for l, name in enumerate(label_name_to_value)]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(path).split('.json')[0]
save_file_name = out_dir
if not osp.exists(json_file + 'mask'):
os.mkdir(json_file + 'mask')
maskdir = json_file + 'mask'
if not osp.exists(json_file + 'mask_viz'):
os.mkdir(json_file + 'mask_viz')
maskvizdir = json_file + 'mask_viz'
out_dir1 = maskdir
cur_tim = time.time()
PIL.Image.fromarray(np.uint8(lbl)).save(savelabelpath + '/' + save_file_name + "_" + str(cur_tim) + '_.png')
shutil.copy(json_file + '/' + save_file_name + '.jpg', saveimgpath + '/' + save_file_name + "_" + str(cur_tim) + '_.jpg')
PIL.Image.fromarray(lbl_viz).save(maskvizdir + '/' + save_file_name + "_" + str(cur_tim) +
'_label_viz.png')
with open(osp.join(out_dir1, 'label_names.txt'), 'w') as f:
for lbl_name in label_name_to_value:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_name_to_value)
with open(osp.join(out_dir1, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir1)
if __name__ == '__main__':
main()
第2步:划分数据集,分为训练集train,验证集val,测试集test,比例8:1:1(比例可自己修改)。
python tools/split_dataset_list.py
生成结果如下:
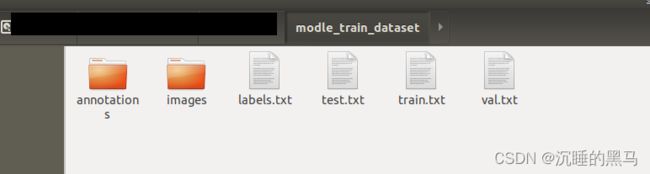
第3步:修改配置文件
这里采用的分割模型是hardnet,该模型比较小精度也不是很低,比较适合实时检测。
默认采用的是CityScapes数据集,如果要训练自己的数据集的话需要修改该文件:/PaddleSeg/configs/base/cityscapes.yml
train_dataset:
type: Dataset
mode: train
dataset_root: modle_train_dataset
train_path: modle_train_dataset/train.txt
num_classes: 7 #类别数
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [1024, 1024]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
val_dataset:
type: Dataset
mode: val
dataset_root: modle_train_dataset
val_path: modle_train_dataset/val.txt
num_classes: 7
transforms:
- type: Normalize
2.2训练
cd PaddleSeg
source activate paddleseg
# 单卡训练
export CUDA_VISIBLE_DEVICES=0
python train.py --config configs/hardnet/hardnet_cityscapes_1024x1024_160k.yml --do_eval --use_vdl --num_workers 4 --save_interval 500 --save_dir out
# 多卡训练
export CUDA_VISIBLE_DEVICES=0,1
python -m paddle.distributed.launch train.py --config configs/hardnet/hardnet_cityscapes_1024x1024_160k.yml --do_eval --use_vdl --num_workers 4 --save_interval 500 --save_dir out
参数介绍:


2.3可视化
在训练过程中可以通过VisualDL对训练过程中的参数进行可视化,这里只是展示下没有数据显示。
cd PaddleSeg
visualdl --logdir ./log
2.4模型测试
训练结束后,最好的模型保存在out/best_model中,可以通过下面的命令对模型效果进行测试。
python predict.py --config configs/hardnet/hardnet_cityscapes_1024x1024_160k.yml --model_path ./out/best_model/model.pdparams --image_path modle_train_dataset/test.txt --save_dir output/result
其中image_path可以是一张图片的路径,也可以是一个包含图片路径的文件列表,也可以是一个目录,这时候将对该图片或文件列表或目录内的所有图片进行预测并保存可视化结果图。
同样的,可以通过–aug_pred开启多尺度翻转预测, --is_slide开启滑窗预测。
下图只是实例图用于展示。

