文本表征 Text Representation
-
基于 one-hot、tf-idf、textrank 等的 bag-of-words;
-
主题模型:LSA(SVD)、pLSA、LDA;
-
基于词向量的固定表征:Word2vec、FastText、GloVe
-
基于词向量的动态表征:ELMo、GPT、BERT
各模型的优缺点:
-
One-hot 表示 :维度灾难、语义鸿沟;静态表证
-
矩阵分解(LSA):利用全局语料特征,但 SVD 求解计算复杂度大;静态表证
-
基于 NNLM/RNNLM 的词向量:词向量为副产物,存在效率不高等问题;静态表证
-
Word2vec、FastText:优化效率高,但是基于局部语料;静态表证
-
GloVe:基于全局预料,结合了 LSA 和 Word2vec 的优点;静态表证
-
ELMo:双向LSTM;动态特征
-
GPT:单向Transformer;动态特征
-
BERT:双向Transformer;动态特征
TF-IDF
TF-IDF(Term Frequency/Inverse Document Frequency)用来衡量一个关键词w对于查询(Query,可看作文档)的重要性。
TF(Term Frequency, 词频)表示关键词w在文档Di中出现的频率:
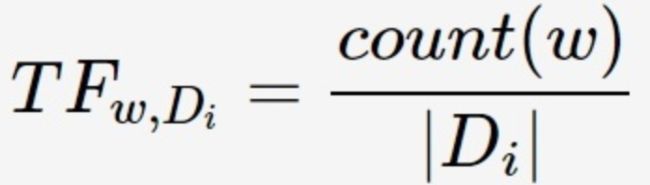
其中,count(w)为关键词w的出现次数,|Di|为文档Di中所有词的数量。
IDF(Inverse Document Frequency, 逆文档频率)反映关键词的普遍程度,当一个词越普遍(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。
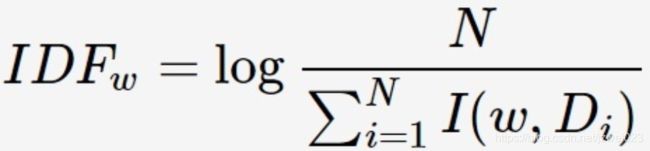
其中 N为所有的文档总数,I(w,Di)表示文档Di是否包含关键词,若包含则为1,若不包含则为0。IDF公式中的分母可能为0,因此需要对IDF做平滑(smooth):加1
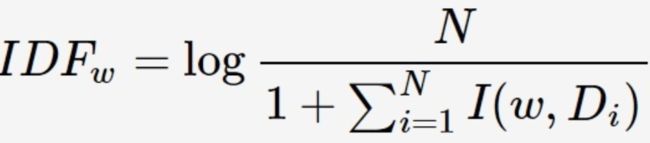
关键词w在文档Di的TF-IDF值:
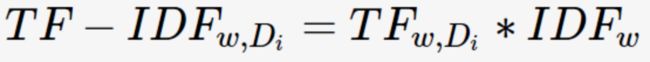
Textrank
通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词。PageRank本来是用来解决网页排名的问题,网页之间的链接关系即为图的边,迭代计算公式如下:
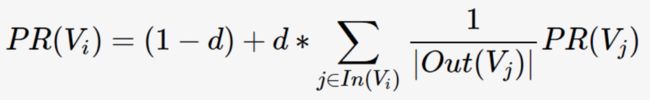
其中,PR(Vi)表示结点Vi的rank值,In(Vi)表示结点Vi的前驱结点集合,Out(Vj)表示结点Vj的后继结点集合,d为damping factor用于做平滑。
TextRank将某一个词与其前面的N个词、以及后面的N个词均具有图相邻关系(类似于N-gram语法模型),从而构建了一个无向图,并将共现作为无向图边的权值。TextRank的迭代计算公式如下:
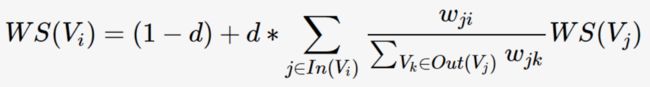
该公式比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度,即共现程度。
LSA
LSA(latent semantic analysis)潜在语义分析,也被称为LSI(latent semantic index)。基本思想就是把高维的文档Document降到低维空间,即潜在语义空间,从而可以从文本中发现隐含的语义维度-'Topic'或者'Concept'信息。具体步骤如下:
1. 分析文档集合,建立Term-Document矩阵A
2. 对Term-Document矩阵A进行奇异值分解
3. 对SVD分解后的矩阵进行降维
4. 使用降维后的矩阵构建潜在语义空间,或重建Term-Document矩阵
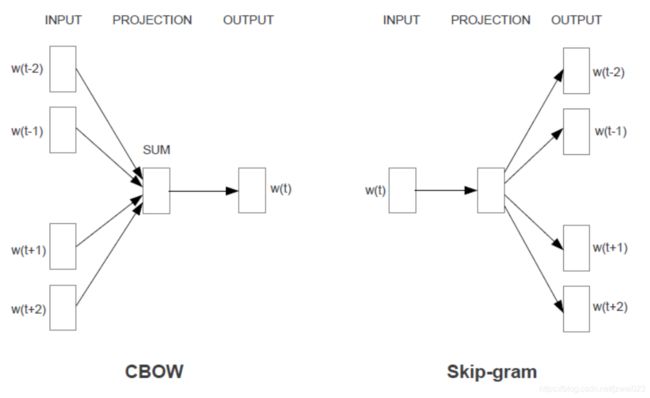
Word2vec
有2种模型:CBOW是根据上下文预测当前中间词,Skip-gram是根据当前中间词预测上下文。
word2vec通过将上下文关系转化为多分类任务,进而训练逻辑回归模型,这里的类别数量|V|词库大小。
实际应用中由于需要预测词典中所有词,效率太低,为了使得模型便于训练,提出了Hierarchical Softmax和Negative Sampling两种改进方法。hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling 更为直接,实质上对每一个样本中每一个词都进行负例采样;
优点:
1. Word2vec 是无监督学习,不需要人工标注
2. nnlm是根据前文生成下一个单词,而word2vec分为根据上下文预测中间词,或根据某一个词预测上下文
FastText
fastText模型架构和word2vec中的CBOW很相似, 不同之处是fastText预测标签(有监督学习)而CBOW预测的是中间词,即模型架构类似但是模型的任务不同。
Trick :1. 为保留一定的次序信息,引入n-gram 2. 应用层次softmax
GloVe
Global Vectors for Word Representation
1. 根据语料库(corpus)构建一个共现矩阵X
矩阵中的每一个元素Xij代表单词i和上下文单词j在特定大小的上下文窗口(context window)内共同出现的次数。一般而言,这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离d,提出了一个衰减函数(decreasing weighting):decay=1/d用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
2. 构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系,论文的作者提出以下的公式可以近似地表达两者之间的关系:
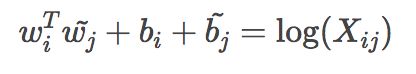
3. loss function
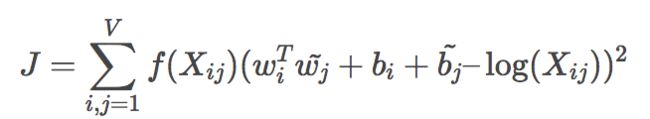
这个loss function的基本形式就是最简单的mean square loss,只不过在此基础上加了一个权重函数f(Xij),共现次数越多的单词i和j的f值越高。
优点or特点:
1. 相对LSA来说,LSA是使用co-occurance matrix的,但LSA是基于SVD的,计算复杂度高。同时,LSA对所有单词的统计权重都是一致的。
2. 相对word2vec来说,Glove使用了全局信息(co-occurance matrix)
3. 无监督学习,虽然实际上可以认为GloVe 还是有 label 的,即共现次数
4. Word2vec 损失函数实质上是带权重的交叉熵,权重固定;GloVe 的损失函数是最小平方损失函数,权重可以做映射变换。
缺点:
1. Glove是基于全局语料的,需要事先统计共现概率,因此Word2vec 可以进行在线学习,GloVe则需要统计固定语料信息。
ELMo
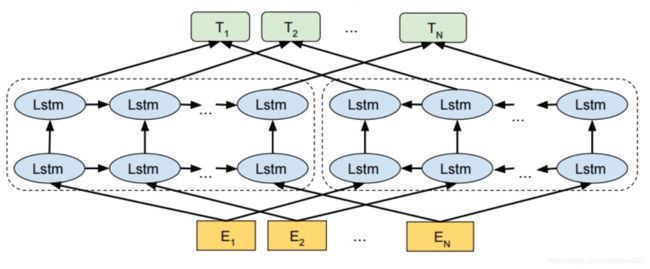
不同于以往的一个词对应一个向量,是固定的。在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时,将一句话或一段话输入模型,模型会根据上线文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。比如appele,可以根据前后文语境理解为公司或水果。
主要思想:ELMo第一使用了多层LSTM,第二增加了后向语言模型(backward LM)。
OpenAI GPT
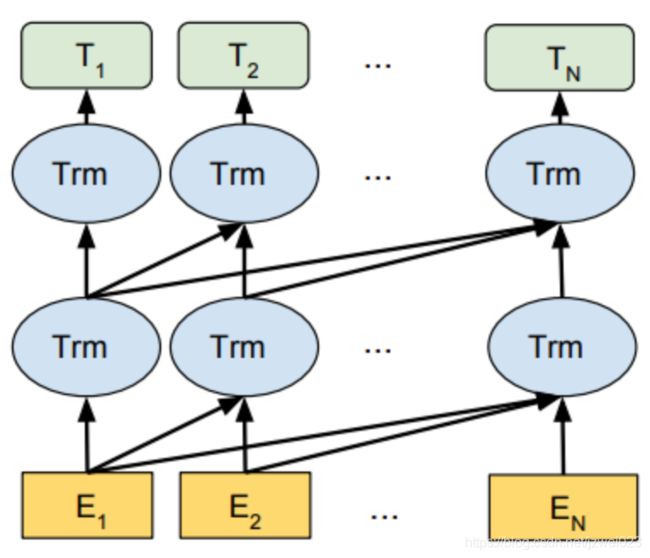
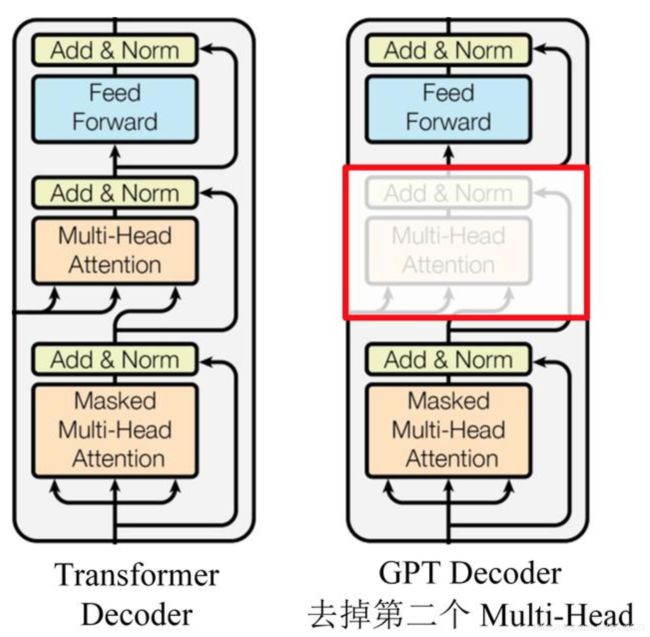
GPT 使用单向 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
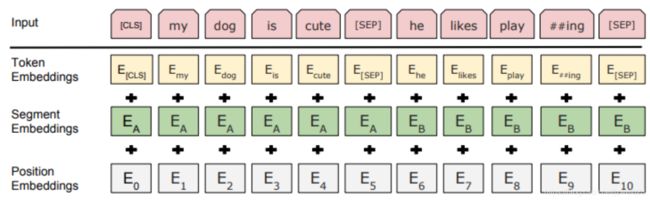
BERT
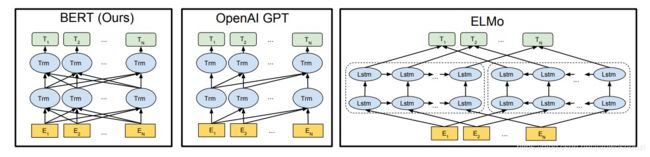
BERT与GPT非常的相似,都是基于Transformer的二阶段训练模型,都分为Pre-Training与Fine-Tuning两个阶段,都在Pre-Training阶段无监督地训练出一个可通用的Transformer模型,然后在Fine-Tuning阶段对这个模型中的参数进行微调,使之能够适应不同的下游任务。
虽然BERT与GPT看上去非常的相似,但是它们的训练目标和模型结构和使用上还是有着些许的不同:
- GPT采用的是单向的Transformer,而BERT采用的是双向的Transformer,也就是不用进行Mask操作
- GPT采用的是Transformer的decoder部分,BERT采用的是Transformer的encoder部分
- 使用的结构的不同,直接导致了它们在Pre-Training阶段训练目标的不同
2个任务: Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)