天池安泰杯金融科技挑战赛冠军方案/零基础风控学习赛TOP方案分享
详细的特征工程+个人理解
-
- 前言
- 1 赛题理解
-
- 2 数据预处理
-
- 2.1 缺失值分析
- 2.2 编码选择
- 3 特征工程
-
- 3.1 可解释特征
- 3.2 组合交叉特征
- 3.3 暴力特征
- 4 模型融合
-
- 4.1 模型选取
- 4.2 特征筛选
- 4.3 差异化模型和stacking融合
- 5 总结
前言
大家好,我是coggle开源小组成员 庐州小火锅,这篇文章将会介绍天池安泰杯金融科技学习赛/贷款违约预测的TOP方案,现附上比赛链接天池安泰杯金融科技学习赛.
本次分享内容普遍适用于数据挖掘,金融风控比赛,相应长期赛刚刚开始,希望能给大家一点启发。
1 赛题理解

赛题以预测用户贷款是否违约为任务,输出不同用户违约概率(0-1之间),该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
2 数据预处理
原始数据包括训练集和测试集有100万条,数据量相当大,后续进行特征工程会导致更多的内存损耗,因此进行内存优化是有必要的,先提供以下函数负责减少数据占用存储空间大小。
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum()
print('内存占用{:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum()
print('优化后内存为: {:.2f} MB'.format(end_mem))
print('内存使用减少 {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
2.1 缺失值分析

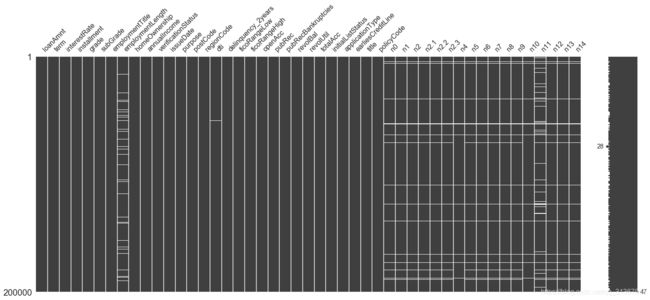
训练集和测试集的缺失情况如上图,缺失字段包括’employmentTitle’, ‘employmentLength’, ‘postCode’, ‘dti’, ‘pubRecBankruptcies’, ‘revolUtil’, ‘title’, ‘n0’, ‘n1’, ‘n2’, ‘n4’, ‘n5’, ‘n6’, ‘n7’, ‘n8’, ‘n9’, ‘n10’, ‘n11’, ‘n12’, ‘n13’, ‘n14’。
缺失值的处理有三种方法:1.填充(平均值,众数,或与已有数值明显区分的数值-999等);2.直接删除(删除存在缺失值或缺失率较高的样本);3.缺失值预测(利用其他列来预测缺失列数据,会有意想不到的惊喜,这里就不展开了)。可知缺失情况较为严重的n0-n14特征在train和test中同时缺失较为突出,简单的对这些缺失值填充-999,之后对缺失数据分析统计意义特征。
下面展示一些 内联代码片。
cols = ['employmentTitle', 'employmentLength', 'postCode', 'dti', 'pubRecBankruptcies', 'revolUtil', 'title',
'n0', 'n1', 'n2', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14']
for col in cols:
data[col].fillna(r'\N', inplace=True)
cols = [f for f in cols if f not in ['employmentLength']]
for col in cols:
data[col].replace({r'\N': -999}, inplace=True)
data[col] = data[col]
2.2 编码选择
针对原始数据中出现的非数值型特征,我们需要将其转换成模型可识别的数值符号,这就涉及到多种编码形式。编码选取应思考两个问题:(1)尽可能准确的表示。(2)不带来干扰或错误信息。常见的编码方法如下:

其中count encoder,one-hot encoder,label encoder主要针对低基数无序特征,比如性别。针对高基数无序特征,比如地区,邮编等,可以采用target encoder或者mean encoder的方法。
值得注意的是,许多人认为目标编码就是平均编码,这是不正确的,两者原理非常类似,常用的target encoder指的是用类别对应的标签的期望来代替原始的类别,所谓的期望,简单理解为均值即可(均值形式的target encoder)。同时target encoder还可以采用类别对应的标签中位值,标准差,最大值等形式来进行编码表示。而mean encoder与均值形式的target encoder原理类似,但为避免过拟合加入了一些特别的手段而已。可以参考相关说明: 特征编码方法总结。下面分别是两种编码的代码应用。
先附上mean encoder代码:
#平均编码类定义
class MeanEncoder:
def __init__(self, categorical_features, n_splits=5, target_type='classification', prior_weight_func=None):
"""
:param categorical_features: list of str, the name of the categorical columns to encode
:param n_splits: the number of splits used in mean encoding
:param target_type: str, 'regression' or 'classification'
:param prior_weight_func:
a function that takes in the number of observations, and outputs prior weight
when a dict is passed, the default exponential decay function will be used:
k: the number of observations needed for the posterior to be weighted equally as the prior
f: larger f --> smaller slope
"""
self.categorical_features = categorical_features
self.n_splits = n_splits
self.learned_stats = {}
if target_type == 'classification':
self.target_type = target_type
self.target_values = []
else:
self.target_type = 'regression'
self.target_values = None
if isinstance(prior_weight_func, dict):
self.prior_weight_func = eval('lambda x: 1 / (1 + np.exp((x - k) / f))', dict(prior_weight_func, np=np))
elif callable(prior_weight_func):
self.prior_weight_func = prior_weight_func
else:
self.prior_weight_func = lambda x: 1 / (1 + np.exp((x - 2) / 1))
@staticmethod
def mean_encode_subroutine(X_train, y_train, X_test, variable, target, prior_weight_func):
X_train = X_train[[variable]].copy()
X_test = X_test[[variable]].copy()
if target is not None:
nf_name = '{}_pred_{}'.format(variable, target)
X_train['pred_temp'] = (y_train == target).astype(int) # classification
else:
nf_name = '{}_pred'.format(variable)
X_train['pred_temp'] = y_train # regression
prior = X_train['pred_temp'].mean()
col_avg_y = X_train.groupby(by=variable, axis=0)['pred_temp'].agg({'mean': 'mean', 'beta': 'size'})
col_avg_y['beta'] = prior_weight_func(col_avg_y['beta'])
col_avg_y[nf_name] = col_avg_y['beta'] * prior + (1 - col_avg_y['beta']) * col_avg_y['mean']
col_avg_y.drop(['beta', 'mean'], axis=1, inplace=True)
nf_train = X_train.join(col_avg_y, on=variable)[nf_name].values
nf_test = X_test.join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name].values
return nf_train, nf_test, prior, col_avg_y
def fit_transform(self, X, y):
"""
:param X: pandas DataFrame, n_samples * n_features
:param y: pandas Series or numpy array, n_samples
:return X_new: the transformed pandas DataFrame containing mean-encoded categorical features
"""
X_new = X.copy()
if self.target_type == 'classification':
skf = StratifiedKFold(self.n_splits)
else:
skf = KFold(self.n_splits)
if self.target_type == 'classification':
self.target_values = sorted(set(y))
self.learned_stats = {'{}_pred_{}'.format(variable, target): [] for variable, target in
product(self.categorical_features, self.target_values)}
for variable, target in product(self.categorical_features, self.target_values):
nf_name = '{}_pred_{}'.format(variable, target)
X_new.loc[:, nf_name] = np.nan
for large_ind, small_ind in skf.split(y, y):
nf_large, nf_small, prior, col_avg_y = MeanEncoder.mean_encode_subroutine(
X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, target,
self.prior_weight_func)
X_new.iloc[small_ind, -1] = nf_small
self.learned_stats[nf_name].append((prior, col_avg_y))
else:
self.learned_stats = {'{}_pred'.format(variable): [] for variable in self.categorical_features}
for variable in self.categorical_features:
nf_name = '{}_pred'.format(variable)
X_new.loc[:, nf_name] = np.nan
for large_ind, small_ind in skf.split(y, y):
nf_large, nf_small, prior, col_avg_y = MeanEncoder.mean_encode_subroutine(
X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, None,
self.prior_weight_func)
X_new.iloc[small_ind, -1] = nf_small
self.learned_stats[nf_name].append((prior, col_avg_y))
return X_new
def transform(self, X):
"""
:param X: pandas DataFrame, n_samples * n_features
:return X_new: the transformed pandas DataFrame containing mean-encoded categorical features
"""
X_new = X.copy()
if self.target_type == 'classification':
for variable, target in product(self.categorical_features, self.target_values):
nf_name = '{}_pred_{}'.format(variable, target)
X_new[nf_name] = 0
for prior, col_avg_y in self.learned_stats[nf_name]:
X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[
nf_name]
X_new[nf_name] /= self.n_splits
else:
for variable in self.categorical_features:
nf_name = '{}_pred'.format(variable)
X_new[nf_name] = 0
for prior, col_avg_y in self.learned_stats[nf_name]:
X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[
nf_name]
X_new[nf_name] /= self.n_splits
return X_new
对高基数无序特征进行平均编码
class_list = ['postCode', 'purpose', 'regionCode', 'grade', 'subGrade', 'homeOwnership', 'employmentTitle','title']
MeanEnocodeFeature = class_list # 声明需要平均数编码的特征
ME = MeanEncoder(MeanEnocodeFeature, target_type='classification') # 声明平均数编码的类
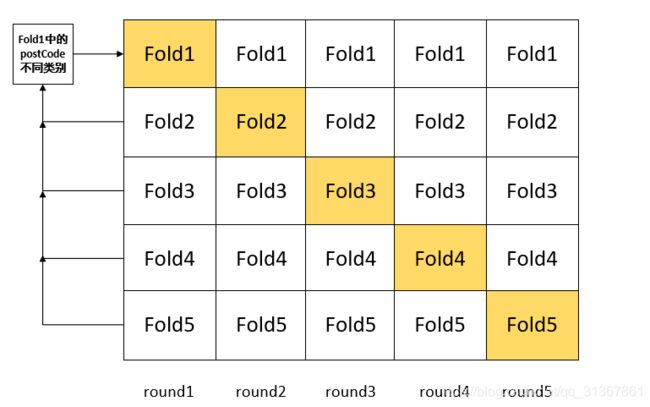
常规的target encoder目标编码代码容易造成过拟合,因此我们引入5折交叉验证的形式改进编码,即将样本分为5块(fold),如下图,每一fold中的该高基数无序特征类别由其它4个fold中的类别对应标签平均值替换表示:
代码如下:
def kfold_stats_feature(train, test, feats, k):
folds = StratifiedKFold(n_splits=k, shuffle=True, random_state=6666) # 这里最好和后面模型的K折交叉验证保持一致
train['fold'] = None
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train, train['isDefault'])):
train.loc[val_idx, 'fold'] = fold_
kfold_features = []
for feat in feats:
nums_columns = ['isDefault']
for f in nums_columns:
colname = feat + '_' + f + '_kfold_mean'
kfold_features.append(colname)
train[colname] = None
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train, train['isDefault'])):
tmp_trn = train.iloc[trn_idx]
order_label = tmp_trn.groupby([feat])[f].mean()
tmp = train.loc[train.fold == fold_, [feat]]
train.loc[train.fold == fold_, colname] = tmp[feat].map(order_label)
# fillna
global_mean = train[f].mean()
train.loc[train.fold == fold_, colname] = train.loc[train.fold == fold_, colname].fillna(global_mean)
train[colname] = train[colname].astype(float)
for f in nums_columns:
colname = feat + '_' + f + '_kfold_mean'
test[colname] = None
order_label = train.groupby([feat])[f].mean()
test[colname] = test[feat].map(order_label)
# fillna
global_mean = train[f].mean()
test[colname] = test[colname].fillna(global_mean)
test[colname] = test[colname].astype(float)
del train['fold']
return train, test
target_encode_cols = ['postCode', 'regionCode', 'homeOwnership', 'employmentTitle','title']
kflod_num=5 #5折交叉验证
train, test = kfold_stats_feature(train, test, target_encode_cols, kflod_num)
针对含有次序意义的特征,target编码和mean编码无法反映次序大小关系,会丢失部分信息,比如两个十分关键的特征grade(贷款等级)以及subGrade(贷款等级子等级)有着明显的次序关系,我们对其进行自定义编码,如下:
def gradeTrans(x):
dict = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6, 'G': 7}
result = dict[x]
return result
def subGradeTrans(x):
dict = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6, 'G': 7}
result = dict[x[0]]
result = result * 5 + int(x[1])
return result
data['grade'] = data['grade'].apply(lambda x: gradeTrans(x))
data['subGrade'] = data['subGrade'].apply(lambda x: subGradeTrans(x))
3 特征工程
样本质量和特征决定着指标的上限,模型只能决定接近这个上限的程度,特征工程是重中之重,下面介绍一些常用的组合,交叉以及暴力特征。
3.1 可解释特征
金融风控领域比赛构造特征的一个思路在于衡量用户的价值和创利能力,下面是基于此思路的一些自定义的可解释特征。
// 以下是自定义的一些特征,用于衡量用户价值和创利能力
data['avg_income'] = data['annualIncome'] / data['employmentLength']
data['total_income'] = data['annualIncome'] * data['employmentLength']
data['avg_loanAmnt'] = data['loanAmnt'] / data['term']
data['mean_interestRate'] = data['interestRate'] / data['term']
data['all_installment'] = data['installment'] * data['term']
data['rest_money_rate'] = data['avg_loanAmnt'] / (data['annualIncome'] + 0.1) # 287个收入为0
data['rest_money'] = data['annualIncome'] - data['avg_loanAmnt']
data['closeAcc'] = data['totalAcc'] - data['openAcc']
data['ficoRange_mean'] = (data['ficoRangeHigh'] + data['ficoRangeLow']) / 2
del data['ficoRangeHigh'], data['ficoRangeLow']
data['rest_pubRec'] = data['pubRec'] - data['pubRecBankruptcies']
data['rest_Revol'] = data['loanAmnt'] - data['revolBal']
data['dis_time'] = data['issueDate_year'] - (2020 - data['earliesCreditLine_year'])
3.2 组合交叉特征
包括离散型特征(类别特征)和连续性特征的一阶交叉:
//定义离散型特征和连续型特征
col_cat = ['subGrade', 'grade', 'employmentLength', 'term', 'homeOwnership', 'postCode', 'regionCode','employmentTitle','title']
col_num = ['dti', 'revolBal','revolUtil', 'ficoRangeHigh', 'interestRate', 'loanAmnt', 'installment', 'annualIncome', 'n14',
'n2', 'n6', 'n9', 'n5', 'n8']
# 定义离散型特征和连续型特征交叉特征统计函数
def cross_cat_num(df, num_col, cat_col):
for f1 in tqdm(cat_col):
g = df.groupby(f1, as_index=False)
for f2 in tqdm(num_col):
feat = g[f2].agg({
'{}_{}_max'.format(f1, f2): 'max', '{}_{}_min'.format(f1, f2): 'min',
'{}_{}_median'.format(f1, f2): 'median',
})
df = df.merge(feat, on=f1, how='left')
return (df)
data = cross_cat_num(data, col_num, col_cat) # 一阶交叉
print('一阶交叉特征处理后:', data.shape)
类别特征之间的二阶交叉:
def cross_qua_cat_num(df):
for f_pair in tqdm([
['subGrade', 'regionCode'], ['grade', 'regionCode'], ['subGrade', 'postCode'], ['grade', 'postCode'], ['employmentTitle','title'],
['regionCode','title'], ['postCode','title'], ['homeOwnership','title'], ['homeOwnership','employmentTitle'],['homeOwnership','employmentLength'],
['regionCode', 'postCode']
]):
### 共现次数
df['_'.join(f_pair) + '_count'] = df.groupby(f_pair)['id'].transform('count')
### n unique、熵
df = df.merge(df.groupby(f_pair[0], as_index=False)[f_pair[1]].agg({
'{}_{}_nunique'.format(f_pair[0], f_pair[1]): 'nunique',
'{}_{}_ent'.format(f_pair[0], f_pair[1]): lambda x: entropy(x.value_counts() / x.shape[0])
}), on=f_pair[0], how='left')
df = df.merge(df.groupby(f_pair[1], as_index=False)[f_pair[0]].agg({
'{}_{}_nunique'.format(f_pair[1], f_pair[0]): 'nunique',
'{}_{}_ent'.format(f_pair[1], f_pair[0]): lambda x: entropy(x.value_counts() / x.shape[0])
}), on=f_pair[1], how='left')
### 比例偏好
df['{}_in_{}_prop'.format(f_pair[0], f_pair[1])] = df['_'.join(f_pair) + '_count'] / df[f_pair[1] + '_count']
df['{}_in_{}_prop'.format(f_pair[1], f_pair[0])] = df['_'.join(f_pair) + '_count'] / df[f_pair[0] + '_count']
return (df)
3.3 暴力特征
针对数据中的n0-n14匿名特征,通过一套组合拳提取暴力特征
//求熵
def myEntro(x):
"""
calculate shanno ent of x
"""
x = np.array(x)
x_value_list = set([x[i] for i in range(x.shape[0])])
ent = 0.0
for x_value in x_value_list:
p = float(x[x == x_value].shape[0]) / x.shape[0]
logp = np.log2(p)
ent -= p * logp
# print(x_value,p,logp)
# print(ent)
return ent
#求均方根
def myRms(records):
records = list(records)
"""
均方根值 反映的是有效值而不是平均值
"""
return np.math.sqrt(sum([x ** 2 for x in records]) / len(records))
//求取众数
def myMode(x):
return np.mean(pd.Series.mode(x))
//分别求取10,25,75,90分位值
def myQ25(x):
return x.quantile(0.25)
def myQ75(x):
return x.quantile(0.75)
def myQ10(x):
return x.quantile(0.1)
def myQ90(x):
return x.quantile(0.9)
//求值的范围
def myRange(x):
return pd.Series.max(x) - pd.Series.min(x)
n_feat = ['n0', 'n1', 'n2', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14', ]
nameList = ['min', 'max', 'sum', 'mean', 'median', 'skew', 'std', 'mode', 'range', 'Q25','Q75']
statList = ['min', 'max', 'sum', 'mean', 'median', 'skew', 'std', myMode, myRange, myQ25, myQ75]
for i in range(len(nameList)):
data['n_feat_{}'.format(nameList[i])] = data[n_feat].agg(statList[i], axis=1)
print('n特征处理后:', data.shape)
4 模型融合
4.1 模型选取
针对金融风控领域:大部分选取的是机器学习模型中的Random Forests, lightgbm,xgboost,catboost等树模型,而不是深度学习模型,我认为原因主要包括:1.样本数量小 2.样本不均衡 3.深度学习模型对于特定结构的特征学习效果较好(比如文本和图像),而针对具有实际意义的金融领域特征来说,传统树模型构造的可解释性特征效果显著。
4.2 特征筛选
下面提供xgboost的模型代码,利用生成的特征重要性可以进一步的筛选特征。特征重要性保存在feature_importance.csv中。
def xgb_model(train, target, test, k):
feats = [f for f in train.columns if f not in ['id', 'isDefault']]
feaNum = len(feats)
print('参与训练的特征数目:', len(feats))
# seeds = [6666,2020]
seeds = [2020]
output_preds = 0
xgb_oof_probs = np.zeros(train.shape[0])
for seed in seeds:
folds = StratifiedKFold(n_splits=k, shuffle=True, random_state=seed)
oof_probs = np.zeros(train.shape[0])
offline_score = []
feature_importance_df = pd.DataFrame()
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'min_child_weight': 5,
'max_depth': 8,
'subsample': ss,
'colsample_bytree': fs,
'eta': 0.01,
# 'scale_pos_weight': 0.2,
'seed': seed,
'nthread': -1,
'tree_method': 'gpu_hist'
}
for i, (train_index, test_index) in enumerate(folds.split(train, target)):
train_y, test_y = target[train_index], target[test_index]
train_X, test_X = train[feats].iloc[train_index, :], train[feats].iloc[test_index, :]
train_matrix = xgb.DMatrix(train_X, label=train_y, missing=np.nan)
valid_matrix = xgb.DMatrix(test_X, label=test_y, missing=np.nan)
test_matrix = xgb.DMatrix(test[feats], missing=np.nan)
watchlist = [(train_matrix, 'train'), (valid_matrix, 'eval')]
model = xgb.train(params, train_matrix, num_boost_round=30000, evals=watchlist, verbose_eval=100,
early_stopping_rounds=600)
val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit)
train_pred = model.predict(train_matrix, ntree_limit=model.best_ntree_limit)
xgb_oof_probs[test_index] += val_pred / len(seeds)
# oof_probs[test_index] += val_pred
test_pred = model.predict(test_matrix, ntree_limit=model.best_ntree_limit)
# 绘制roc曲线
train_auc_value, valid_auc_value = plotroc(train_y, train_pred, test_y, val_pred)
print('train_auc:{},valid_auc{}'.format(train_auc_value, valid_auc_value))
offline_score.append(valid_auc_value)
print(offline_score)
output_preds += test_pred / k / len(seeds)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = model.get_fscore().keys()
fold_importance_df["importance"] = model.get_fscore().values()
fold_importance_df["fold"] = i + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
print('all_auc:', roc_auc_score(target.values, oof_probs))
print('OOF-MEAN-AUC:%.6f, OOF-STD-AUC:%.6f' % (np.mean(offline_score), np.std(offline_score)))
feature_sorted = feature_importance_df.groupby(['Feature'])['importance'].mean().sort_values(ascending=False)
feature_sorted.to_csv('feature_importance.csv')
top_features = feature_sorted.index
print(feature_importance_df.groupby(['Feature'])['importance'].mean().sort_values(ascending=False).head(50))
return output_preds, xgb_oof_probs, np.mean(offline_score), feaNum
4.3 差异化模型和stacking融合

构建差异化模型的目的在于提高系统的稳定性和鲁棒性,防止抖动。最终构建lightgbm,catboost,xgboost的pipline模型,同时利用皮尔逊相关系数分析模型结果的差异性,选取差异较大的结果文件,通过第二层为RF的双层stacking融合方式来进一步优化结果。
5 总结
第一次分享比赛经验,希望大家有所收获,作为竞赛圈的新人,期待和各位朋友交流:[email protected], 相关代码见我的github主页:代码链接.
对竞赛感兴趣的朋友欢迎关注公众号:Coggle数据科学,DataWhale。