第一节: Pytorch介绍及环境搭建
第一节: Pytorch介绍及环境搭建
近年来随着深度学习的火爆,世界上出现了很多现成的深度学习的框架,可以让人们快速的搭建出自己的神经网络而不用浪费大量的时间用于重复造轮子,Pytorch就是诸多深度学习的框架之一
本节将首先讲解诸多深度学习框架之间的关系,而后讲解为什么我们选择Pytorch而非其他的框架
最后本教程实际上作为我自己学习Pytorch的笔记,为了后来参考我的笔记的人能够成功的跟随笔记 / 教程复现结果,将讲解我的电脑上的环境配置
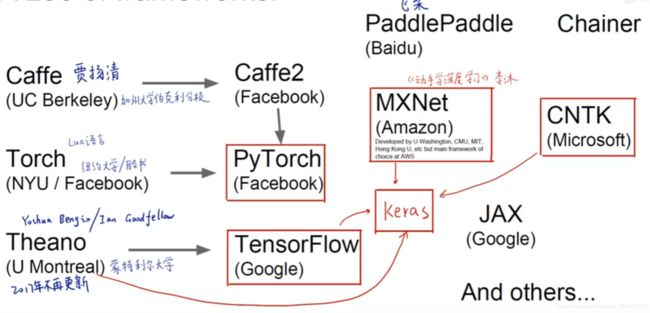
诸多深度学习框架间的关系
深度学习的火爆得益于2012年ImageNet挑战赛上卷积神经网络AlexNet成功地吊打其他所有非卷积神经网络算法引起的轰动
那时最早的深度学习的框架是贾扬清的Caffe,他在UC Berkeley读博的时候写的,后来贾扬清去Facebook的时候写出了Caffe2
Caffe在深度学习的早期,2012 2013年的时候是主流的平台
后来Facebook和NYU(纽约大学)基于Lua语言写了Torch框架,但是Lua语言并不流行,最后Facebook基于Python语言重写了一遍Torch,命名为PyTorch
更新到现在,PyTorch已经是PyTorch和Caffe2的合并版本
除了Facebook,Google提出了TensorFlow深度学习框架,TensorFlow是基于Theano框架演进的,Theano框架主要由Bengjo和Goodfellow(生成对抗网络之父)共同领导的,由蒙特利尔大学支持的,但是在2017年已经不再更新,但Theano中的很多库的思想和接口后来都被TensorFlow所继承
Amazon支持的框架就是MXNet,李沐老师的动手学深度学习就是基于这个框架编写的
Microsoft提出的就是CNTK框架
百度也有自己的框架就是PaddlePaddle,此外百度还有Apollo的无人驾驶平台
基于Theano,TensorFlow,MXNet,CNTK这四个底层的张量运算框架,Keras这个调包侠封装了更加高级的接口,只需要几行就可以创建复杂的神经网络
此外,最新版得TF2.0还将Keras集成到了其中,但是TF2.0的中文社区还没有形成,因此建议初学者先学Keras,然后学习PyTorch最后是TensorFlow
为什么选择Pytorch
对于初学者可以先学习Keras,因为Keras对诸多框架进行了高级别的封装,因此能够很轻易的创建出一个网络来感受深度学习
但是对于学界来说,更需要自己去创建出新的层,新的模块,因此就需要自己的进行底层框架的定制化开发,这个时候就需要使用TensorFlow和Pytorch等底层框架看
对于论文发表,学界来说,基本上所有的论文后面的模型的代码都是基于PyTorch的,因此未来想要进入学界的话,就得学习PyTorch
而且PyTorch有一个好处就是PyTorch可以和Numpy无缝对接,并在Numpuy的ndarray对象(详见我的Numpy学习笔记)的基础上创造了Tensor对象作为运算的基础,再加上PyTorch的自动求导机制,然后将其部署到GPU中,因此学习成本很低
TensorFlow则是基于Google的生态,由于2019年3月发布了TensorFlow2.0版本,而TF2.0对之前的版本并不兼容,因此很多之前的代码都会报错,而TensorFlow主要用于业界将学界的模型部署到真实的生产环境中
我本人是一个大一刚结束的学生,未来的方向是学界,因此本教程主要讲解Pytorch框架
前置要求
想要学习Pytorch,首先要有一系列的前置基础,否则直接学的话会学的一头雾水
我本人认为的需要提前掌握的内容有(也是我自己会的学习路线):
-
Python基础
Pytorch是Python的库,因此作为基础的Python必须要掌握,我因为一直在不断学习新的知识,一直没有写一个Python教程出来,未来有时间了可能会写 -
Numpy (详见我的Numpy学习专栏)
Numpy作为Python最早的科学数据处理包,是整个Python第三方库的基础核心,诸多第三方的库都是基于Numpy,利用了Numpy的数据处理能力开发的
除了直接调用Numpy的库以外,Numpy的诸多思想,API都或少的被其他库所继承,例如我们即将要学习的Pytorch的Tensor,和Numpy中的ndarray几乎一样
还有诸多的库都能实现和Numpy的无缝对接,因此Numpy是必须要提前掌握的内容 -
Matplotlib (详见我的Matpotlib学习专栏)
我们在使用Pytorch构建自己的网络模型的时候,不可避免的需要监视训练的过程或者表达训练的效果,这个时候我们就需要使用Python中最早也是最基础的可视化 / 绘图库了
因此对Matplotlib的掌握没有必要像Numpy一样必须深刻而全面,但是对于基础的使用必须掌握 -
Pandas (详见我的Pandas学习专栏)
Pandas是Python中用于数据处理,清洗,分析的第三方库,Numpy,Pandas和Matplotlib三个库加起来构成了Python生态的基础
虽然接下来我们讲解Pytorch时会自己搭建一个网络并且训练,训练用的数据集是直接可以用的,不需要进过清洗
但是我们在未来掌握Pytorch之后,自己搭建模型并且使用真实的业务数据时,就需要我们自己去寻找数据进行清洗 -
深度学习基础(详见我的深度学习专栏,目前我已经写好了,但是还没有上传)
深度学习指的我们用于学习的模型就是各类的神经网络,包括全连接神经网络,卷积神经网络,循环神经网络等等
而机器学习指的是我们让机器进行学习,具体使用什么样的方法(即算法)都是可以的,因此可以用决策树,支持向量机,神经网络等等算法
所以深度学习是机器学习的一个分支,我们如果想要用Pytorch搭建自己的神经网络,就首先必须掌握深度学习的内容,而作为基础的机器学习中的通用知识,例如过拟合,泛化等都要了解
我的机器学习专栏未来可能随着我的学习出出来,但是对于深度学习而言,在我的深度学习专栏中对于掌握深度学习必要的机器学习通用知识也有讲解 -
爬虫
理由和上面Pandas一样,都是为了未来我们能够获得用于训练的数据来提高我们的综合能力,现阶段可以不学,未来随着我个人的学习也会出爬虫专栏
环境要求
为了能够跟着本专栏进行学习,成功地做出结果,下面将贴出我自己的电脑配置及环境
-
硬件
- 电脑名: Alienware 51M
- CPU: i9-9900K
- GPU: NVIDIA RTX 2080
-
软件
- 系统: Ubuntu 18.04 LTS or 18.04/04(第四次更新版)
- 显卡驱动: NVIDIA 450
- CUDA: 10.1
- cuDNN: 7.5
- 虚拟环境管理器: conda和pyenv
pyenv主要负责其他项目的开发,conda主要负责机器学习相关内容开发 - 开发工具: Jupyter Notebook和VScode
Jupyter Notebook主要负责神经网络编程,VScode负责其他项目代码 - Python版本: conda管理的Python 3.7.9,环境名称为pytorchlearning
- Pytorch版本: 清华源的1.3.1
- Pytorch依赖库版本: conda自动安装
最后,关于如何搭建环境,参考CSDN上的博文即可,未来可能会补上一个搭建文章