Pytorch实现简单神经网络
问题:MNIST数据集的数据分类
起始点是一幅MNIST数据集中的图像,它的像素个数为28×28=784。这意味着我们的神经网络的第一层必须有784个节点。最后的输出层是0~ 9的任意一个数字,也就是10种不同输出。为每一个可能的类别分配一个节点。
需要:
python + pytorch + mnist数据集(训练集与测试集)
具体步骤以及代码
第一步,导入库
# 导入库
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import pandas
import matplotlib.pyplot as plt第二步,定义处理数据集函数
# 数据集处理,提供__len__()方法,允许PyTorch通过len(mnist_dataset)获取数据集的大小。
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pandas.read_csv(csv_file, header=None) #csv_file被读入一个名为data_df的pandas DataFrame。
pass
def __len__(self):
return len(self.data_df) #返回DataFrame的大小
def __getitem__(self, index): #从数据集中的第index项中提取一个标签(label)
# image target (label)
label = self.data_df.iloc[index,0]
target = torch.zeros((10))
target[label] = 1.0
# image data, normalised from 0-255 to 0-1
image_values = torch.FloatTensor(self.data_df.iloc[index,1:].values) / 255.0
# return label, image data tensor and target tensor
return label, image_values, target
def plot_image(self, index): #为MnistDataset类添加一个制图方法,以方便查看我们正在处理的数据
img = self.data_df.iloc[index,1:].values.reshape(28,28)
plt.title("label = " + str(self.data_df.iloc[index,0]))
plt.imshow(img, interpolation='none', cmap='Blues')
pass
pass
第三步,导入训练数据并检查是否可用
#从类中创建一个数据集对象,并将其CSV文件位置传递给它
mnist_dataset = MnistDataset('mnist_data/mnist_train.csv')
#使用plot_image()函数绘制数据集中的第10幅图像,索引为9
mnist_dataset.plot_image(9)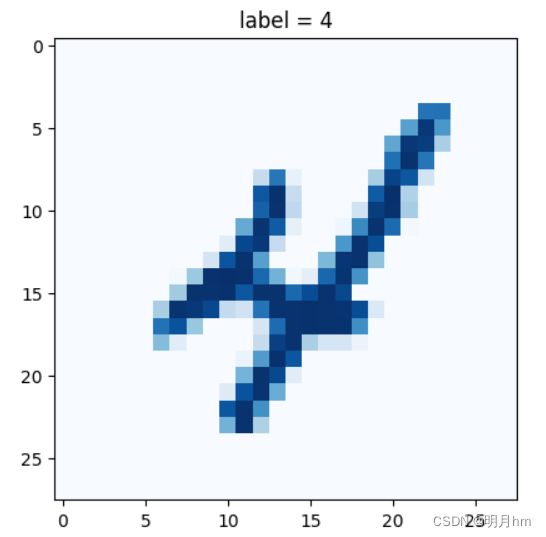
#检查mnist_dataset是否允许我们通过索引访问
mnist_dataset[100] #应该看到它返回标签、像素值和目标张量第四步,设计神经网络结构
#设计神经网络结构
class Classifier(nn.Module):
def __init__(self):
# 初始化PyTorch父类
super().__init__()
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(784, 200), #一个从784个节点到200个节点的全连接映射
nn.Sigmoid(), #S型逻辑激活函数
nn.Linear(200, 10), #将200个节点映射到10个节点的全连接映射
nn.Sigmoid() #S型逻辑激活函数
)
# 创建损失函数
self.loss_function = nn.MSELoss()
# 创建优化器,使用简单的梯度下降
self.optimiser = torch.optim.SGD(self.parameters(),
lr=0.01)
# 记录训练进展的计数器和列表
self.counter = 0
self.progress = []
pass
def forward(self,inputs):
# 直接运行模型
return self.model(inputs)
def train(self, inputs, targets):
# 计算网络的输出值,使用forward()函数传递输入值给网络并获得输出值
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs, targets)
# 每隔10个训练样本增加一次计数器的值,并将损失值添加进列表的末尾
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
# 每10000次训练后打印计数器的值,这样可以了解训练进展的快慢
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
# 梯度归零,反向传播,并更新权重
# 使用损失来更新网络的链接权重,需要为每个节点计算误差梯度,再更新链接权值。PyTorch简化了这个过程。
self.optimiser.zero_grad() #将计算图中的梯度全部归零。
loss.backward() # 从loss函数中计算网络中的梯度
self.optimiser.step() #使用这些梯度来更新网络的可学习参数
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.',
grid=True, yticks=(0, 0.25, 0.5))
pass
pass第五步,开始训练
%%time
# 创建神经网络
C = Classifier()
# 在MNIST数据集训练神经网络
epochs = 4
for i in range(epochs):
print('training epoch', i+1, "of", epochs)
for label, image_data_tensor, target_tensor in mnist_dataset:
C.train(image_data_tensor, target_tensor)
pass
pass# 绘制分类器损失值
C.plot_progress()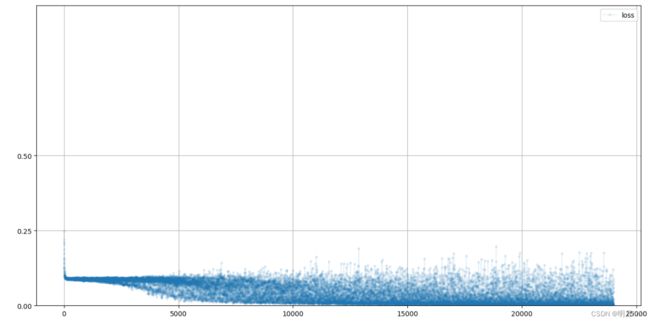
第六步,开始分类
#导入分类数据,即MNIST测试数据
mnist_test_dataset = MnistDataset('mnist_data/mnist_test.csv')# 挑选一幅图像
record = 19
# 绘制图像和标签
mnist_test_dataset.plot_image(record)
# 可视化:训练过的神经网络是如何判断这幅图像的
image_data = mnist_test_dataset[record][1]
# 调用训练后的神经网络
output = C.forward(image_data)
# 绘制输出张量
pandas.DataFrame(output.detach().numpy()).plot(kind='bar', legend=False, ylim=(0,1))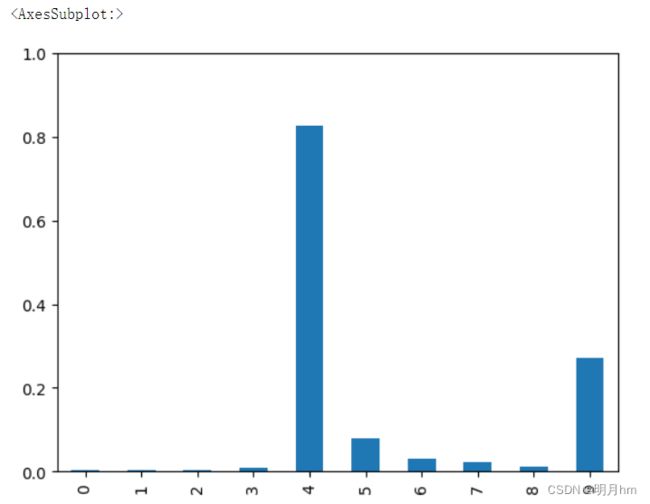
最后,展现效果
# 集中所有10000幅图像进行分类,并记录正确分类的样本数
# 分数score的初始值为0。接着遍历测试数据,并在每次网络输出与标签匹配时加分
# 打印最后得分以及神经网络答对的样本占总样本的分数
# answer.argmax()语句的作用是输出张量answer中最大值的索引。如果第一个值是最大的,则argmax是0。
score = 0
items = 0
for label, image_data_tensor, target_tensor in mnist_test_dataset:
answer = C.forward(image_data_tensor).detach().numpy()
if (answer.argmax() == label):
score += 1
pass
items += 1
pass
print(score, items, score/items)![]()