基于协同过滤的推荐算法
1、推荐系统与推荐问题
推荐系统:根据用户的历史行为,挖掘出用户的喜好,为用户推荐与其喜好相符的商品或信息。推荐系统的任务是将信息和用户连接,帮助用户找到感兴趣的信息,让有价值的信息能触达潜在的用户。
推荐问题描述:核心问题是为用户推荐与其兴趣相似度比较高的商品。用一函数f(x)计算候选商品与用户之间的相似度。为预测出函数f(x),可用到的历史数据有:用户的历史行为数据,与该用户有关的其他用户信息,商品之间的相似性,文本的描述等。
f : C X S -> R
注:集合C表示所有用户,集合S表示所有商品,函数f表示商品到用户之间的有效性的效用函数,R是一个针对所有用户的排序的集合,对于每一个用户c∈C,希望从S中选择出s∈S,使得f的值最大。
推荐的常用算法:协同过滤的推荐,基于内容的推荐,基于关联规则的推荐,基于效用的推荐,基于知识的推荐,组合推荐。
2、基于协同过滤的推荐
2.1、协同过滤算法概述
协同过滤算法(Collaborative Filtering, CF)是最基本的推荐算法,
可分为:
(1)、基于用户的协同过滤算法(user-based):通过相似用户进行推荐,比较计算用户的相似性,越相似两者品味相近。
(2)、基于项的协同过滤算法(item-based):通过相似项推荐,比较计算项与项之间的相似性,为用户推荐与其打过分的项相似的项。
2.2、相似度的度量方法
1、欧式距离:欧几里得空间中两点间“普通”(即直线)距离。
2、皮尔森相关系数:若特征之间数量级相差过大,对欧式距离的影响比较大,就不能很好的判断。皮尔森相关系数对量级不敏感,它是两个向量之间的协方差和标准差之商。其取值在-1与+1之间,若r>0,表明两个变量是正相关;若r<0,表明两个变量是负相关。r 的绝对值越大表明相关性越强。具体形式是:
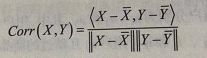
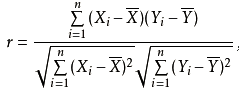
3、余弦相似度:是文本相似度度量使用较多的一个方法,计算两个向量的夹角余弦值来评估他们的相似度。对于两个向量X和Y,其对应形式如下:
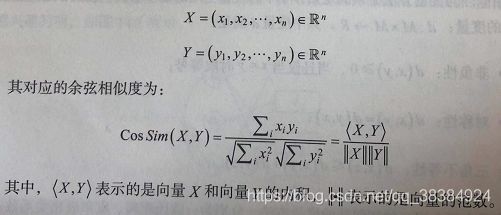
注意:通过计算相似度可得到相似度矩阵,相似度矩阵是一个对称矩阵。
2.3、基于协同过滤的推荐算法
1、基于用户的协同过滤算法
解释:为用户推荐和他兴趣相似的其他用户喜欢的物品。利用用户间的相似度,为用户u没有打分的项i打分。
用户商品矩阵:不同用户,不同商品,元素为用户对商品的打分,可能有的用户没有对某些商品打分,没打分的为0。
用户相似度矩阵:通过用户商品矩阵和相似性度量计算用户之间的相似度,是一个对称矩阵,对角线全是0。
商品打分:利用用户间的相似度,为用户u没有打分的项i打分:其中N(i)表示对商品打过分的用户的集合,其中的用户用v代表,Wu,v是用户u和用户v之间的相似度,rv,i表示的是用户v对商品i的打分。打分结果按降序排序并返回。
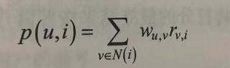
2、基于项的协同过滤算法
与前者不同的是:它计算的是商品相似度矩阵。I(u)表示的是用户u打过分的商品的集合,Wi.j表示商品i和j之间的相似度,rj,u表示的是用户u对商品j的打分。将打分降序排序。
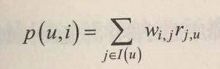
3、利用协同过滤算法进行推荐
3.1、准备,preparing.py
导入用户商品数据,形成用户-商品矩阵,定义相似性度量和相似度矩阵,首先初始化相似度矩阵,然后计算相似度进行填充。
import numpy as np
def load_data(file_path):#导入数据
f = open(file_path)
data = []
for line in f.readlines():
lines = line.strip().split("\t")
tmp = []
for x in lines:
if x != "-":
tmp.append(float(x))
else:
tmp.append(0)
data.append(tmp)
f.close()
return np.mat(data)
def cos_sim(x, y):#余弦相似度
numerator = x * y.T
denominator = np.sqrt(x * x.T) * np.sqrt(y * y.T)
return (numerator / denominator)[0, 0]
def similarity(data):#相似度矩阵
m = np.shape(data)[0]
w = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
w[i, j] = cos_sim(data[i,], data[j,])
w[j, i] = w[i, j]
else:
w[i, j] = 0
return w
3.2、基于用户的协同过滤算法推荐
在这里给出基于用户的协同过滤算法的代码,基于商品的协同过滤算法的代码类似,但需要注意的一点是,将用户商品矩阵转置成商品用户矩阵 data = data.T,方便计算。
import numpy as np
from preparing import load_data, similarity
def user_based_recommend(data, w, user): # 基于用户相似性为用户user推荐商品
m, n = np.shape(data)
interaction = data[user,]
not_inter = []
for i in range(n):
if interaction[0, i] == 0:
not_inter.append(i)
predict = {}
for x in not_inter:
item = np.copy(data[:, x])
for i in range(m):
if item[i, 0] != 0:
if x not in predict:
predict[x] = w[user, i] * item[i, 0]
else:
predict[x] = predict[x] + w[user, i] * item[i, 0]
return sorted(predict.items(), key=lambda d: d[1], reverse=True)
def top_k(predict, k): # 为用户推荐前k个商品
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
if __name__ == "__main__":
# 1、导入用户商品数据
print("------------ 1. load data ------------")
data = load_data("data.txt")
# 2、计算用户之间的相似性
print("------------ 2. calculate similarity between users -------------")
w = similarity(data)
# 3、利用用户之间的相似性进行推荐
print("------------ 3. predict ------------")
predict = user_based_recommend(data, w, 0)
# 4、进行Top-K推荐
print("------------ 4. top_k recommendation ------------")
top_recom = top_k(predict, 2)
print(top_recom)