【Distilling】《Learning Efficient Object Detection Models with Knowledge Distillation》

NIPS-2017
文章目录
- 1 Background and Motivation
- 2 Advantages / Contributions
- 3 Method
-
- 3.1 Knowledge Distillation for Classification with Imbalanced Classes
- 3.2 Knowledge Distillation for Regression with Teacher Bounds
- 3.3 Hint Learning with Feature Adaptation
- 4 Experiments
-
- 4.1 Datasets
- 4.2 Overall Performance
- 4.3 Speed-Accuracy Trade off in Compressed Models
- 4.4 Ablation Study
- 5 Conclusion(own)
1 Background and Motivation
伴随着CNN 的发展,object detection 的精度有了极大的提升,然而要落地应用,实时性仍是个考验!
知识蒸馏,Knowledge Distillation:a shallow or compressed model trained
to mimic the behavior of a deeper or more complex model can recover some or all of the accuracy drop.(更多应用可参考下面三篇文章)
-
【Distilling】《Distilling the Knowledge in a Neural Network》(arXiv-2015, In NIPS Deep Learning Workshop, 2014)
-
【Mimic】《Mimicking Very Efficient Network for Object Detection》
-
【Very Tiny】《Quantization Mimic: Towards Very Tiny CNN for Object Detection》(ECCV-2018)
虽然能在保留精度的同时,能压缩模型,提升速度,但只在分类任务上得到了印证,在更复杂的 object detection 上还有待探索!
想要把 Knowledge Distillation 应用到 object detection 上,相比于 classification 任务,有如下问题和挑战:
- suffers more degradation with compression,因为目标检测任务的标签更 expensive,usually less voluminous.(感觉应该是说,目标检测任务标签信息量更大,根据标签学到的模型更为复杂,压缩后损失更多!就像高清壁纸和普通壁纸,同样的压缩比,高清壁会更模糊,这里的高清壁纸就可以理解为更 expensive)
- 分类任务中,each class is equally important,然后目标检测任务中,background class is far more prevalent
- 目标检测任务更为复杂,both classification and bounding box regression

最后一个挑战没看懂(可能没有看用知识蒸馏迁移不同领域任务的论文,get 不到作者的点)
2 Advantages / Contributions
- the first successful demonstration 目标检测中应用知识蒸馏压缩模型
- 提出了新的 loss 来处理上述的问题和挑战
- perform comprehensive empirical evaluation using multiple large-scale public benchmarks(在多个公共数据集上做了大量的验证实验)
- 对泛化性问题和欠拟合问题给出了自己的 insights
3 Method
作者采用的 Faster R-CNN framework,从主干网络,RPN,RCN(头部)三个部分,进行了知识蒸馏!
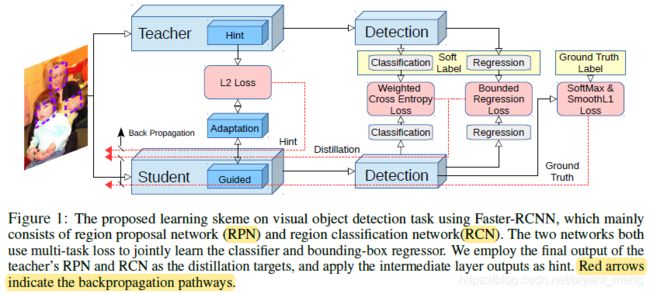
- 主干网络:adaptation layers for hint learning
- 分类任务:weighted cross entropy loss for severe category imbalance issue
- 回归任务:teacher bounded regression loss,teacher’s regression output as a form of upper bound,学生网络回归的更优则无损失
公式如下:
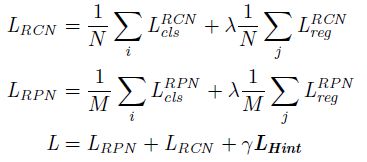
- N N N 和 M M M 分别是对应部分的 batch-size 大小, λ \lambda λ 和 γ \gamma γ 是超参数,作者这里分别设定为 1 和 0.5
- L c l s L_{cls} Lcls,分类损失包括 hard target 和知识蒸馏中的 soft target
- L r e g L_{reg} Lreg,回归损失包括 smooth L1 和新提出的 teacher bounded L2 regression loss
- L H i n t L_{Hint} LHint,是主干的损失
下面来详细看看各个部分的公式细节
3.1 Knowledge Distillation for Classification with Imbalanced Classes
老师网络的预测结果 P t P_t Pt 可以表示如下
![]()
其中, Z t Z_t Zt 是老师网络的 logits, T T T 是温度(细节介绍可以参考 【Distilling】《Distilling the Knowledge in a Neural Network》(arXiv-2015, In NIPS Deep Learning Workshop, 2014))
同样,学生网络的输出 P s P_s Ps 也可以表示成如下形式
![]()
在知识蒸馏方法中,学生网络的优化损失如下:
![]()
- L h r a d L_{hrad} Lhrad 就是用 gt 监督的 cross entropy
- L s o f t L_{soft} Lsoft 就是利用了老师网络的信息的 soft loss,好处是 The soft labels contain information about the relationship between different classes as discovered by teacher
- μ \mu μ 是超参数,来 balance hard and soft loss
在分类任务中,分类错误只会来自于 foreground categories,而目标检测任务中的分类子任务,background and foreground 的错误 can dominate the error,foreground 的误分概率比较低,作者通过增大背景类的权重来处理这个问题,形式如下,
![]()
多加了一个 w c w_c wc, w 0 = 1.5 w_0 = 1.5 w0=1.5 for the background class and w i = 1 w_i = 1 wi=1 for all the others(注意这里 P t Pt Pt 不是 ground truth 的 one-hot 编码,所有交叉熵中加权重是有效的)
作者讨论下温度 T T T 的问题,我们知道 T T T 越大,会缩小各类概率分布的差距,参考 【Distilling】《Distilling the Knowledge in a Neural Network》(arXiv-2015, In NIPS Deep Learning Workshop, 2014)。这在小任务中(such as classification on small datasets like MNIST)非常适用!
缺点是,也会增大噪声的分布,不利于学习,不适用于大任务,例如 classification on larger datasets 或者 object detection!
作者实验中把 T T T 设置为了 1
3.2 Knowledge Distillation for Regression with Teacher Bounds
- regression 不像 classification task,它是 unbounded,
- In addition, the teacher may provide regression direction that is contradictory to the ground truth direction.
基于以上两点,我们不能直接学 teacher network 的回归值(第二点,嗯……)!而把损失设计成如下形式:
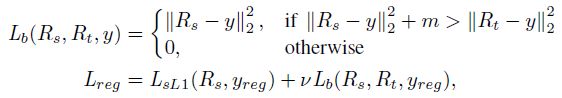
- m m m is a margin, v v v 权重,作者设置为了 0.5
- y r e g y_{reg} yreg denotes the regression ground truth label,就是 proposal 和 gt 之间的回归量
- R t R_t Rt 和 R s R_s Rs 是 teacher 和 student 网络学出来的回归量
- L s L 1 L_{sL1} LsL1 就是普通的 smooth L1 回归 loss
如果学生网络学出来的没有老师网络好,才会有惩罚!也就是达到老师的要求就不强求了! L b L_b Lb 不局限于是 L2 Loss 的形式,L1 或者 smooth L1 都行!!!
3.3 Hint Learning with Feature Adaptation
![]()
上述论文中证明,using the intermediate representation of the teacher as hint can help the training process and improve the final performance of the student.
![]()
L H i n t L_{Hint} LHint 是学主干的监督信息损失,形式如下
![]()
![]()
V , Z V, Z V,Z分别是来自老师和学生网路的 feature vectors,必须 h,w,channels 相同,有时候需要加 adaption layer(full connection 或者 1 ∗ 1 1*1 1∗1 convolution) 来使得 Z Z Z 和 V V V 维度一模一样!
作者发现,即使 V , Z V, Z V,Z dimension 一样,加了 adaption layer 效果会更好,adaption layer 也可以用在不同的模型之间,例如 VGG16 and AlexNet !
4 Experiments
4.1 Datasets
- KITTI
- PASCAL VOC 2007
- MS COCO
- ImageNet DET benchmark (ILSVRC 2014)
4.2 Overall Performance
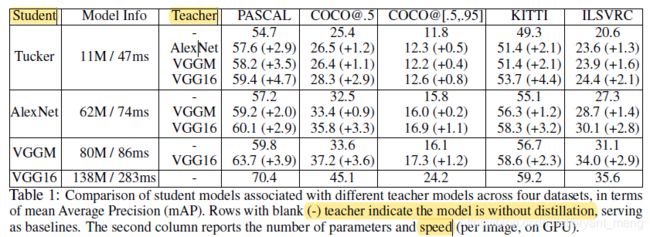
Teacher 列中 − - − 表示,teacher 和 student 是同网络,可以看出,大网络作为 teacher 能带来更多的提升
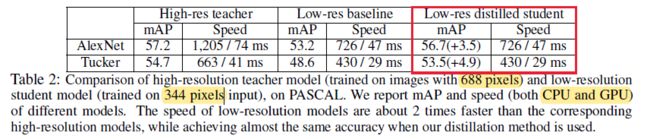
这个表是蒸馏分辨率(downsampling the input size quadratically reduces convolutional resources and speeds up computation.)
老师网络 688,学生网络 344!精度相当,速度接近 x2
4.3 Speed-Accuracy Trade off in Compressed Models

4.4 Ablation Study

VGG16 为 Teacher,Tucker 为 student,在 PASCAL 和 KITTI 上评估!对比了不同的蒸馏方式,可以看出,作者设计的 teacher bounded regression loss 比设计成 regression loss 形式好, weighted cross entropy loss 比 cross entropy loss 好,adaptation layers for hint learning 比没有 adaptation layers 的好!

-
Distillation improves generalization
(‘Car’ shares more common visual characteristics with ‘Truck’ than with ’Person’) -
Hint helps both learning and generalization
目标检测任务还路漫漫,It seems the learning algorithm is suffering from the saddle point problem. the hint may provide an effective guidance to avoid the problem by directly having a guidance at an intermediate layer.(避免陷入局部最优解???)
5 Conclusion(own)
- In object detection, however, failing to discriminate between background and foreground can dominate the error, while the frequency of having misclassification between foreground categories is relatively rare.
- 可以蒸馏分辨率
- Hint learning + knowledge distilling