Linux中间件之redis存储原理和字典
redis存储原理
- redis 命令处理是单线程
-
- redis 的耗时操作有哪些
- redis 命令处理不采用多线程的原因
- redis 存储结构
-
- 编码的定义
- redis 存储转换
- 字典(dict)实现
-
- redisDb
- dict
- hash冲突
- 扩容
- 缩容
- 渐进式rehash
- scan命令
- redis 的expire机制
- 大KEY
- redis 使用单线程能高效的原因
-
- 在机制上
- 优化方式
- 总结
- 后言
redis 命令处理是单线程
对于单线程来说不能有耗时操作(所谓耗时是指阻塞IO或者CPU运算数据的时间比较长),对于redis而言耗时会影响响应性能。
redis 的耗时操作有哪些
那么redis有哪些耗时操作以及怎么解决的呢?
(1)IO密集型,磁盘IO。redis是一个数据库,支持持久化,这就有磁盘IO的操作,这是需要耗时的。redis会fork一个子进程,在子进程中做持久化,不占用主进程,不会干扰主进程的命令处理。此外,redis还有aof的持久化策略,在bio_aof_fsync线程中进行异步刷盘,也不会占用redis-server主线程。
(2)IO密集型,网络IO。当redis服务多个客户,数据请求或返回数据量比较大时(比如读取前100名排行榜,或者日志写入),这是耗时的。redis通过开启IO多线程(io_thd_* 线程)来处理网络IO,解决网络IO导致的耗时问题。
(3)CPU密集型,redis支持丰富的数据结构,如果数据结构的时间复杂度比较高(比如 O ( n ) O(n) O(n))可能导致CPU被占用大量的时间去运算,从而耗时。
redis 命令处理不采用多线程的原因
-
redis支持丰富的数据结构(string、list、hash、set、zset等),而且对象类型由多个数据结构实现,加锁复杂、锁粒度不好控制;它不像memcached只支持一种数据结构,加锁简单。
-
频繁的上下文切换,抵消多线程的优势。redis是一个数据库,有些时间段会密集访问,有些时间段又比较少的访问;如果使用多线程,就需要将一些线程休眠和将一些线程唤醒,这就存在线程调度问题,线程调度就会引发上下文切换。
redis 存储结构
编码的定义
redis支持的编码定义如下(server.h):
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
ZIPLIST初始的时候会分配一个连续的空间,ZIPLIST开始位置会存储第一个元素的地址,第一个元素放在最后面,第一个元素的后面也有偏移量,偏移量记录倒数第二个元素的位置,倒数第二个元素又会记录倒数第三的位置,以此类推;比如一个int数据,0~256,只需要一个字节就可以描述这个整数,如果超过256会进行紧凑压缩。
ZIPLIST按照插入顺序进行压缩。
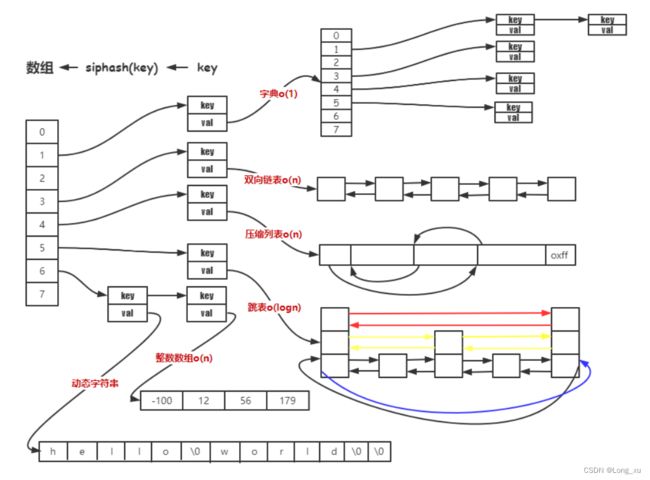
redis 存储转换
字典(dict)实现
redis 中 KV 组织是通过字典来实现的;hash 结构当节点超过512 个或者单个字符串长度大于 64 时,hash 结构采用字典实现。
redisDb
redis默认支持16个Db,但只会使用一种Db。可以通过select来选择使用哪种Db,默认是 select 0。
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]>
源码中redisDb的定义(server.h):
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
redisDb里面有散列表,散列表有很多的key-value,不同的value可能会是不同的类型。
dict
dict定义如下(dict.h):
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
dict相当于C++的类的封装。
dictType *type相当于所有的成员函数。
void *privdata相当于上下文。
dictht ht[2]存储所有的数据,是一个散列表。
rehashidx指示rehash到哪个位置了,它是从0开始的,如果rehashidx == -1,则重哈希未进行。
dictType的定义如下(dict.h):
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
dictht的定义如下(dict.h):
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
dictEntry **table是指针数组,其实是二维数组。
size是数组的长度,必须是2的n次幂( 2 n 2^n 2n)。
sizemask是数组长度-1,属于对字典的优化。因为散列表的存储是通过hash(key)%size=index 确定索引,sizemask是对取余长度的优化,将hash(key)%size变成hash(key) &sizemask,把除法优化为二进制的运算,从而提高执行速度,这种优化的前提是 数组的长度必须是2的n次幂( 2 n 2^n 2n)。
used是实际存储元素的个数。
hash冲突
- 散列表中有一个指针数组,因为数组的槽位需要存储一个链表。
-
key-value的存储位置通过hash(key) % size求得。
-
hash冲突:对key进行hash,那么经过hash(key) % size求得的索引很可能出现有多个key-value都映射到同一个index,需要通过链表方式进行连接。hash冲突会造成索引效率的降低。
-
负载因子,描述hash冲突的激烈程度。负载因子 = used / size;used 是数组存储元素的个数,size 是数组的长度;负载因子越小,冲突越小;负载因子越大,冲突越大;redis 的负载因子是 1。
- 字符串经过 hash 函数运算得到 64 位整数。
- 相同字符串多次通过 hash 函数得到相同的64位整数。
- 整数对 取余可以转化为位运算。
- 抽屉原理 n+1个苹果放在 n 个抽屉中,苹果最多的那个抽屉至少有 2 个苹果;64位整数远大于数组的长度,比如数组长度为 4,那么 1、5、9、1+4n 都是映射到1号位数组;所以大概率会发生冲突。
扩容
redis是翻倍扩容的方式。
如果负载因子 > 1,则会发生扩容;扩容的规则是翻倍;如果正在 fork (在 rdb、aof 复写以及 rdb-aof 混用情况下)时,会阻止扩容;但是此时若负载因子 > 5,索引效率大大降低, 则马上扩容;这里涉及到写时复制原理。
扩容时,rehash的key存储的index要么在oldIndex,要么在oldIndex+oldSize,不会存放到其他的index中,因为同一个key经过hash得到的值是不会变的,只是取余的size变成了2*size。
写时复制核心思想:只有在不得不复制数据内容时才去复制数据内容。
缩容
如果负载因子 < 0.1,则会发生缩容;缩容的规则是恰好包含used 的 2 n 2^n 2n。
比如:假如此时数组存储元素个数为 9,恰好包含该元素的就是 2 4 ( 2 3 < 9 < 2 4 ) 2^4(2^3<9<2^4) 24(23<9<24),也就是 16。
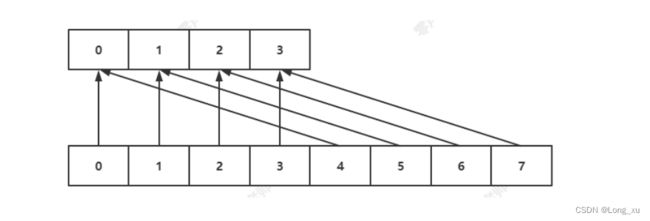
思考:为什么缩容的负载因子不是小于1?
因为缩容的负载因子是小于1的话会造成频繁的扩缩容,扩缩容都有分配内存的操作,内存操作变得频繁就会造成IO密集。
渐进式rehash
扩容和缩容都会导致rehash,因为映射算法发生了改变。
当 hashtable 中的元素过多的时候,因为redis是一个数据库,里面存储的数据非常多,不能一次性 rehash 到ht[1];这样会长期占用 redis,其他命令得不到响应;所以需要使用渐进式 rehash。
rehash步骤:
将 ht[0] 中的元素重新经过 hash 函数生成 64 位整数,再对ht[1] 长度进行取余,从而映射到 ht[1]。
渐进式规则:
(1) 分治的思想,将 rehash 分到之后的每步增删改查的操作当中。
(2)在定时器中,最大执行一毫秒 rehash ;每次步长 100 个数组槽位。
思考:
处于渐进式 rehash 阶段时,是否会发生扩容缩容?不会!
scan命令
scan cursor [MATCH pattern] [COUNT count] [TYPE type]
scan命令采用高位进位加法的遍历顺序,rehash 后的槽位在遍历顺序上是相邻的。
会出现一种重复的情况:在scan过程当中,发生两次缩容的时候,会发生数据重复。

scan要达到的目的是从scan开始那刻起redis已经存在的数据进行遍历,不会重复和遗漏(例外是scan过程中两次缩容可能造成数据重复), 因为比如scan 已经快结束了,现在插入大量数据,这些数据肯定遍历不到。
扩容和缩容造成映射算法发生改变,但是使用高位进位累加的算法,可以对scan那刻起已经存在数据的遍历不会出错。
示例:
127.0.0.1:6379> keys *
1) "k1"
2) "fly"
3) "k3"
4) "rank"
5) "k2"
6) "k4"
7) "teacher"
8) "k5"
127.0.0.1:6379> scan 0 match * count 1
1) "4"
2) 1) "k1"
127.0.0.1:6379> scan 4 match * count 1
1) "2"
2) 1) "teacher"
127.0.0.1:6379> scan 2 match * count 1
1) "6"
2) 1) "k2"
2) "k4"
127.0.0.1:6379> scan 6 match * count 1
1) "1"
2) 1) "k5"
127.0.0.1:6379> scan 1 match * count 1
1) "5"
2) 1) "fly"
2) "k3"
3) "rank"
127.0.0.1:6379> scan 5 match * count 1
1) "0"
2) (empty array)
redis 的expire机制
只支持对最外层key过期。
expire key seconds
pexpire key milliseconds
ttl key
pttl key
(1) 惰性删除。
分布在每一个命令操作时检查 key 是否过期;若过期删除 key,再进行命令操作。
(2)定时删除。
在定时器中检查库中指定个数(25)个 key。
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20
/*Keys for each DB loop. */
/*The default effort is 1, and the maximum
configurable effort is 10. */
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP + ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort;
int activeExpireCycleTryExpire(redisDb *db,dictEntry *de, long long now);
大KEY
在 redis 实例中形成了很大的对象,比如一个很大的 hash 或很大的 zset,这样的对象在扩容的时候,会一次性申请更大的一块内存,这会导致卡顿;如果这个大 key 被删除,内存会一次性回收,卡顿现象会再次产生。
如果观察到 redis 的内存大起大落,极有可能因为大 key 导致的。
# 每隔0.1秒 执行100条scan命令
redis-cli -h 127.0.0.1 --bigkeys -i 0.1
redis 使用单线程能高效的原因
在机制上
- redis是内存数据库,数据存储在内存中,可以高效访问。
- redis使用hash table的数据组织方式,查询数据的时间复杂度为 O ( 1 ) O(1) O(1),能快速查找数据。
- redis支持丰富的数据结构,根据性能进行数据结构切换,执行效率与空间占用保持平衡。
- redis使用高效的reactor网络模型。
优化方式
- redis采用分治思想,把rehash分摊到每一个操作步骤当中,同时在定时器中以100为步长最多rehash 1ms,实现高效。
- redis将耗时阻塞的操作放在其他线程处理。
- redis的对象类型采用不同的数据结构实现。比如string对象有int、raw、embstr三种编码方式。
127.0.0.1:6379> get fly
"100"
127.0.0.1:6379> OBJECT encoding fly
"int"
127.0.0.1:6379> set fly 1024a
OK
127.0.0.1:6379> get fly
"1024a"
127.0.0.1:6379> OBJECT encoding fly
"embstr"
127.0.0.1:6379> set fly 123456789012345678901234567890123456789012345678901234567890
OK
127.0.0.1:6379> get fly
"123456789012345678901234567890123456789012345678901234567890"
127.0.0.1:6379> OBJECT encoding fly
"raw"
总结
- 项目中使用到scan命令时,要在server端自己去重。
- redis处于渐进式rehash时,不会发生扩容和缩容。
- scan采用高位进位加法的遍历顺序,遍历目标是:不重复,不遗漏。
后言
本专栏知识点是通过<零声教育>的系统学习,进行梳理总结写下文章,对c/c++linux系统提升感兴趣的读者,可以点击链接,详细查看详细的服务:C/C++服务器课程