简易多元线性回归学习
目录
- 多元线性回归
- 一、问题分析
- 二、数据预处理(excel)
-
- 1.数据清洗
- 2.数据全数值化
- 三、使用EXcel回归
-
- 回归实现
- 回归分析
- 四、使用代码实现回归
-
- ⅠStatsmodels
-
- 1.数据处理
- 2.绘制热力图探讨价格与其他之间的联系
- 3.利用statsmodels建立回归方程
- ⅡSklearn
-
- 数据处理及计算R方
- 小结
- 相关链接
多元线性回归
多元线性回归是一般线性模型到多个自变量的概括,以及一般线性模型的特例,仅限于一个因变量。
一般线性模型(general linear model, multivariate regression model)是一个统计学上常见的线性模型。
其公式一般写为:
其中Y是一个包含反应变量的矩阵。X是一个包含独立自变量的设计矩阵。B是一个包含多个估计参数的矩阵。U 是一个包含误差和剩余项的矩阵。通常假设误差在测量之间是不相关的,并遵循多元正态分布。如果误差不遵循多元正态分布,则可以使用广义线性模型来放宽关于Y和U的假设。
一般线性模型包含许多不同的统计模型:ANOVA,ANCOVA,MANOVA,MANCOVA,普通线性回归,t检验和F检验。一般线性模型是对多于一个因变量的情况的多元线性回归的推广。如果Y,B和U是列向量,则上面的矩阵方程将表示多元线性回归。
使用一般线性模型的假设检验可以通过两种方式进行:多变量或多个独立的单变量检验。在多变量测试中,Y的列一起测试,而在单变量测试中,Y列独立地测试,即作为具有相同设计矩阵的多个单变量测试。

意义:事物的联系也是多方面的,而影响事物发展的因素是多样的。由多个自变量的最优组合共同来估计因变量,比单一的自变量预测更有效,更符合实际。
一、问题分析
通过对某段时间某地区的已售房价数据进行线性回归分析,探索影响房价高低的主要因素,并对这些影响因素的影响程度进行分析,利用分析得到的数据,对未来房价的趋势和走向进行预测。
本文探究街区(neighborhood),房屋面积(area),卧室(bedrooms),浴室数(bathrooms),房屋风格(style)与 房价(price)的关系以及影响大小。
二、数据预处理(excel)
1.数据清洗
原始数据中,存在有房屋数据存在 没有卧室,没有浴室或房屋面积不合理等疑似错误数据。
筛选
去掉bedroom为0
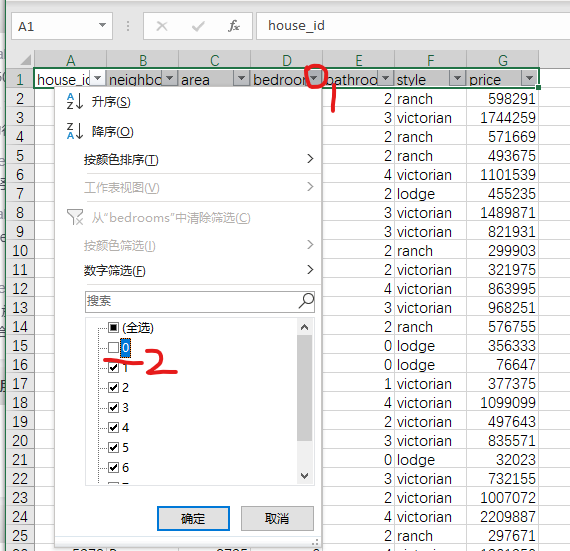
bathroom同理

将area值小于1000清洗

2.数据全数值化
neighborhood和style为非数值型数据,需要转换成数值型数据进行回归分析。
-A,B,C -1,2,3
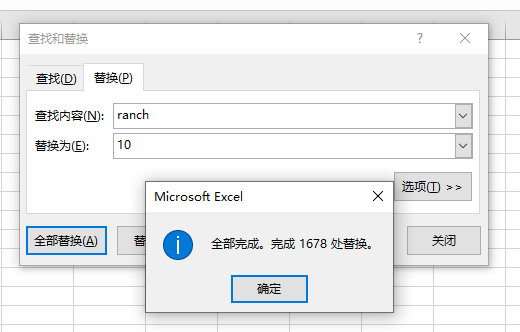
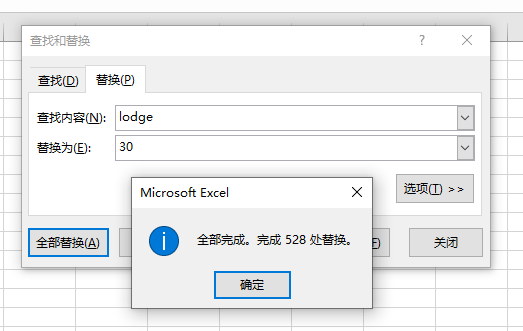
-ranch、victorian、lodge -10、20、30
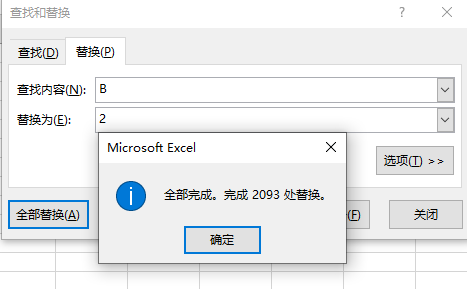
替换A 为 1

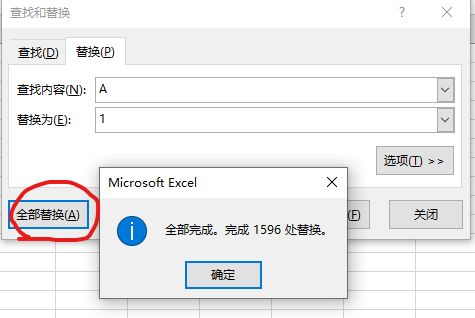
B:
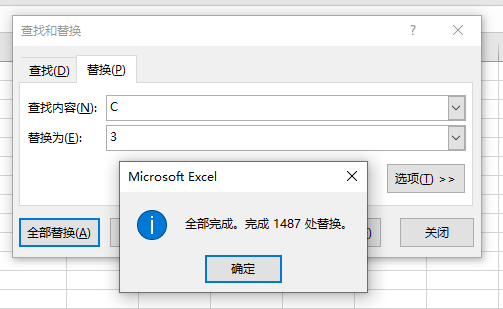
C:
ranch:
victorian:

lodge:
三、使用EXcel回归
回归实现
方法

房价(price)作为因变量其他变量作为自变量

回归分析
结果

Multiple R:相关系数R,用来衡量自变量x与y之间的相关程度的大小。
R Square:决定系数R方,反映因变量的全部变异能通过回归关系被自变量解释的比例。可以通俗地理解为使用均值作为误差基准,看预测误差是否大于或者小于均值基准误差。
本次数据集回归分析得到的R =0.778,表明x和y之间的关系为高度相关。
本次数据集回归分析得到的R方 = 0.605,说明自变量能解释因变量的60.5%
自变量 含义 Coefficients(系数)
X Variable 1 街区(neighborhood) 9768.8665605825
X Variable 2 房屋面积(area) 345.152705630739
X Variable 3 卧室数(bedrooms) -1733.14723959822
X Variable 4 浴室数(bathrooms) 8112.15494579683
X Variable 5 房屋风格(style) -455.450901280214
回归方程为: y=9768.8x1+345.1x2-1733.1x3+8112.1x4-455.4x5-6497.0
由上可以看出房屋面积x2的P值远小于显著性水平0.05房屋面积(area)与房价(price)相关。卧室数(bedrooms)和浴室数(bathrooms)的P值远大于显著性水平0.05,说明这卧室数(bedrooms)和浴室数(bathrooms)与房价(price)相关性较弱。
四、使用代码实现回归
ⅠStatsmodels
1.数据处理
导入数据
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('house_prices.csv')
df.info(); df.head()

异常值处理
# 异常值处理
# ================ 异常值检验函数:iqr & z分数 两种方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
# ================== 上下截断点法检验异常值 ==============================
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
# 四分位点;这里调用函数会存在异常
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位数
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 计算上下截断点
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
# ===================== Z 分数检验异常值 ==========================
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
# 计算两个 Z 分数的数值点
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
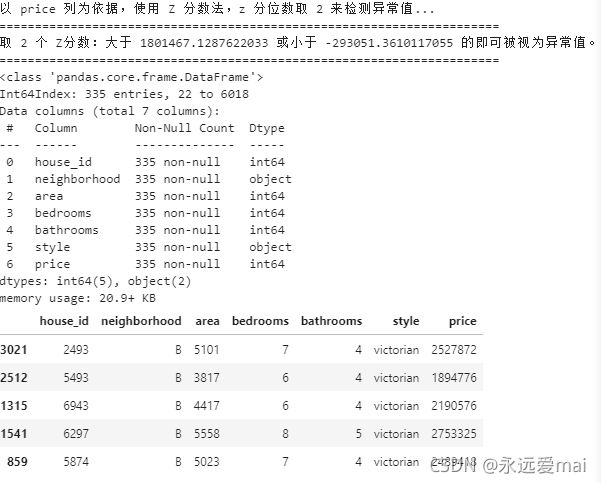
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier.info(); outlier.sample(5)
丢弃异常数据
df.drop(index=outlier.index, inplace=True)
2.绘制热力图探讨价格与其他之间的联系
# 热力图
def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
"""
data: 整份数据
method:默认为 pearson 系数
camp:默认为:RdYlGn-红黄蓝;YlGnBu-黄绿蓝;Blues/Greens 也是不错的选择
figsize: 默认为 10,8
"""
## 消除斜对角颜色重复的色块
# mask = np.zeros_like(df2.corr())
# mask[np.tril_indices_from(mask)] = True
plt.figure(figsize=figsize, dpi= 80)
sns.heatmap(data.corr(method=method), \
xticklabels=data.corr(method=method).columns, \
yticklabels=data.corr(method=method).columns, cmap=camp, \
center=0, annot=True)
# 要想实现只是留下对角线一半的效果,括号内的参数可以加上 mask=mask
heatmap(data=df, figsize=(6,5))
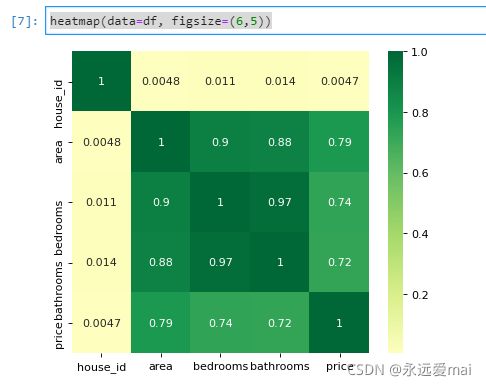
可以看出 area,bedrooms,bathrooms 等变量与房屋价格 price 的关联不小 放入模型中
3.利用statsmodels建立回归方程
import statsmodels.api as sm
from statsmodels.formula.api import ols # ols 为建立线性回归模型的统计学库
from statsmodels.stats.anova import anova_lm
# 数据集样本数量:6028,这里随机选择 600 条
df = df.copy().sample(600)
# 表示告诉 Python 这是分类变量,否则 Python 会当成连续变量使用
## 这里直接使用方差分析对所有分类变量进行检验
## 下面几行代码便是使用统计学库进行方差分析的标准姿势
lm = ols('price ~ C(neighborhood) + C(style)', data=df).fit()
anova_lm(lm)
from statsmodels.formula.api import ols
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()
结果R方为0.641 拟合程度一般可能存在多元共线性
再用Sklearn库试试

ⅡSklearn
数据处理及计算R方
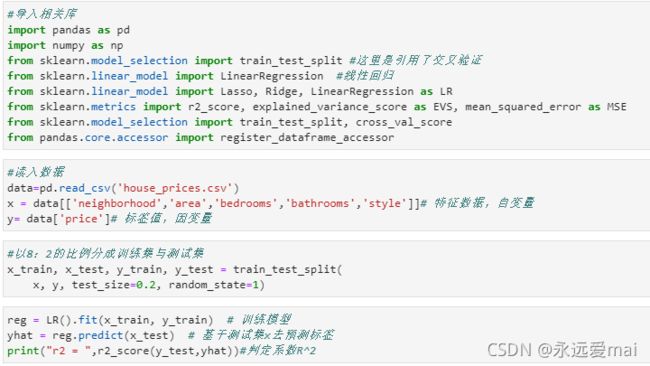
代码如下
#导入相关库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split #这里是引用了交叉验证
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.linear_model import Lasso, Ridge, LinearRegression as LR
from sklearn.metrics import r2_score, explained_variance_score as EVS, mean_squared_error as MSE
from sklearn.model_selection import train_test_split, cross_val_score
from pandas.core.accessor import register_dataframe_accessor
#读入数据
data=pd.read_csv('house_prices.csv')
x = data[['neighborhood','area','bedrooms','bathrooms','style']]# 特征数据,自变量
y= data['price']# 标签值,因变量
#以8:2的比例分成训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=1)
reg = LR().fit(x_train, y_train) # 训练模型
yhat = reg.predict(x_test) # 基于测试集x去预测标签
print("r2 = ",r2_score(y_test,yhat))#判定系数R^2
结果
![]()
小结
这次实验中基于Sklearn的线性回归模型的精准度高于基于Statsmodels的线性回归模型。需要注意的是在使用Excel和linear_model进行回归时,必须将非数值型数据转换为数值型数据。
相关链接
基于多元线性回归的房价预测
多元线性回归分析理论详解