DOTA数据集应用于Yolo-v4(-Tiny)系列1——切割图片与转换Annotation格式
文章目录
- 前言
- 一、从raw图制作数据集
-
- 1.1 安装步骤
- 1.2 使用方法(以VOC格式为例)
- 1.3 解读标签(以VOC和YOLO格式为例)
- 二、对DOTA图片切割
-
- 2.1 可以直接使用的YOLO标签格式的DOTA数据集
- 2.2 自己制作YOLO标签格式的DOTA数据集
-
- 2.2.1 环境和安装
- 2.2.2 切割图片
-
- 1. 观察DOTA数据集内的情况
- 2. 使用ImgSplit_multi_process.py切割DOTA中的train和val
- 3. 使用SplitOnlyImage_multi_process.py切割DOTA中的test
- 三、DOTA的annotation格式转换为YOLO格式
-
-
- 3.1 环境和安装
- 3.2 DOTA的标签格式和分类名称
- 3.3使用YOLO_Transformer.py转换标签格式
-
- 总结
前言
因为项目需要在Zynq开发板上实现深度网络的部署,采用Yolo-v4(-Tiny)两种目标检测模型,并使用武汉大学开源的DOTA数据集来训练和推断。因为此前使用计算机视觉相关的代码都是直接用已经处理好的数据集比如Pascal VOC、COCO、ImageNet等,DOTA数据集由于图片分辨率比较高,(2K-3K)*(2K-3K)分辨率,如果直接用于训练,效果不如将图片分割为多张图片,这样反而可以增加一张图片的目标框数量,对于提高模型精度十分有帮助。其次,DOTA数据集的标签格式不同于YOLO,所以需要在两种之间实现转换。此外,之前从未处理过raw的图片来制作数据集,所以也趁着这个机会对raw图做VOC或者YOLO格式的标签。另外在Darknet框架和Pytorch框架下都实现了Yolov4和Yolov4-Tiny框架的训练和推断。
趁着在部署到板子上之前,记录总结这一周多的工作。
由于篇幅较长,所以将分为几篇文章来记录。
一、从raw图制作数据集
如果想直接使用DOTA数据集,这一节可以跳过。这一节整理了如何从raw图制作数据集。labelimg是一个可视化的图像标定工具,使用功能非常容易看懂的界面来对图片批注PASCAL VOC格式(ImageNet使用的格式)并可另存为.XML文件,此外也支持YOLO格式,并另存为.txt文件。
工具:labelimg
环境:windows10
1.1 安装步骤
使用annconda prompt安装若干包,依次按照下述命令安装
pip install PyQt5
pip install pyqt5-tools
pip install lxml
pip install labelimg
提示:安装过程中容易出现读取网页链接时间过长,重新运行安装命令即可。
1.2 使用方法(以VOC格式为例)
在anaconda prompt中输入labelimg就会跳出页面框
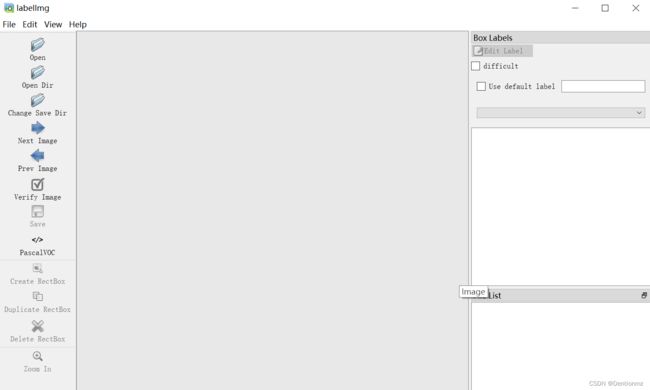
随后选择打开文件夹,并在类型中选择YOLO或者别的格式,同时点击Create RectBox。如下图:
对所有图片标注之后,如下

在文件夹中

其中几张图片都是从VOC中拎出来的,如下

1.3 解读标签(以VOC和YOLO格式为例)
随便打开一个.xml文件,会看到如下内容:

这张图来源,该图非常好,比较清晰地解释了VOC格式下的各行含义。
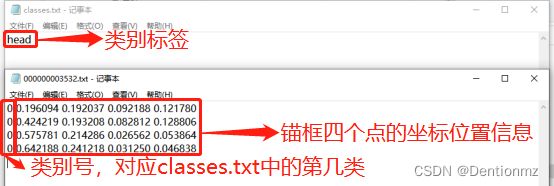
使用labelimg以YOLO模式进行标注产生的标注文件如下,图源来自与VOC相同的链接,其中classes.txt文件中存放的是类别标签,需要提前制作,而在VOC格式下的classes.txt的文件,可以在VOC格式注释完以后再自制classes.txt文件,略去不谈。标签文件中以类别+锚框的位置坐标信息进行保存,文件中有几行则说明对应的标注图像中有几个锚框。
二、对DOTA图片切割
2.1 可以直接使用的YOLO标签格式的DOTA数据集
特别感谢该博主提供的数据集,我已经测试过该数据集在Yolo-v4和Yolo-v4-Tiny上的可靠性,该数据集内已经包含训练集和验证集已经切割好的图片(都在images文件夹内)与对应的YOLO格式的标签(都在labels文件夹内),同时保留了原来DOTA格式的标签(都在labelTxt文件夹内),关于DOTA格式的标签我将在第三节展开介绍。
如果直接使用这一步,可以结束这一章往系列2走。
如果希望体会一个完整的DOTA,请往下走。
2.2 自己制作YOLO标签格式的DOTA数据集
2.2.1 环境和安装
环境和安装包(安装包使用武汉大学提供的官方分割图像的包)如下:
环境:恒源云服务器
lib:DOTA_devkit(链接:https://github.com/CAPTAIN-WHU/DOTA_devkit)
数据集:DOTA(链接:https://captain-whu.github.io/DOTA/dataset.html)
补充:数据集DOTA也可以直接从云服务器提供的公开数据集中找到
安装步骤如下
sudo apt-get install swig
swig -c++ -python polyiou.i
python setup.py build_ext --inplace
2.2.2 切割图片
我们可以首先使用DOTA_devkit中的demo.ipynb来观察结果、源图片路径来源和生成图片的路径。
随后我们正式开始对DOTA数据集中的图片进行切割和产生对应的DOTA格式的标签文件。
1. 观察DOTA数据集内的情况
包含test train val三个文件夹
其中test文件夹内,一级为images,二级包括三个文件DOTA_test_part1.zip DOTA_test_part2.zip DOTA_test_test_info.json,
其中我们只解压两个压缩文件得到完整的test图像,但注意在解压过程中两个解压文件都会自行创建images文件夹,在创建得到的images文件内再放入图片,也就是<testpath>/images/images/,请记得将所有图片放置为符合<testpath>/images/的路径。
其中train文件夹内,一级为images labelTxt-v1.0 labelTxt-v1.5
我们使用images下的三个压缩文件,同test路径处理方式,<trainpath>/images
我们使用labelTxt-v1.0下的labelTxt.zip,同上路径处理方式,<trainpath>/labelTxt
其中val文件夹内,一级为images labelTxt-v1.0 labelTxt-v1.5
我们使用images下的1个压缩文件,同test路径处理方式,<valpath>/images
我们使用labelTxt-v1.0下的labelTxt.zip,同上路径处理方式,<valpath>/labelTxt
2. 使用ImgSplit_multi_process.py切割DOTA中的train和val
先观察.py文件某几段:
class splitbase():
def __init__(self,
basepath,
outpath,
code = 'utf-8',
gap=256,
subsize=1024,
thresh=0.7,
choosebestpoint=True,
ext = '.png',
padding=True,
num_process=8
):
其中我们需要gap指的是切割得到的单张图片和该图片在原始图片中的位置上相邻图片之间的重叠宽度,笔者使用了gap=256,指的是该切割图片与空间位置上相邻的四张图片之间的重复宽度都是256。subsize指的是切割得到的图片的宽度。这两个参数可以自己设计。
self.imagepath = os.path.join(self.basepath, 'images')
self.labelpath = os.path.join(self.basepath, 'labelTxt')
self.outimagepath = os.path.join(self.outpath, 'images')
self.outlabelpath = os.path.join(self.outpath, 'labelTxt')
这一段给出了路径设置,和我们在1中设置的路径一样
在main函数中,我的设定如下
if __name__ == '__main__':
# example usage of ImgSplit
# start = time.clock()
# split = splitbase(r'/data/dj/dota/val',
# r'/data/dj/dota/val_1024_debugmulti-process_refactor') # time cost 19s
# # split.splitdata(1)
# # split.splitdata(2)
# split.splitdata(0.4)
#
# elapsed = (time.clock() - start)
# print("Time used:", elapsed)
split = splitbase(r'trainexample',
r'trainexamplesplit')
#split = splitbase(r'valexample',
# r'valexamplesplit')
split.splitdata(1)
我在DOTA_devkit下自己创建了trainexample、trainexamplesplit、valexample、valexamplesplit这四个文件夹。并将1中得到的图片存放到./trainexample/images和./valexample/images、将label文件存放到./trainexample/labelTxt和./valexample/labelTxt中。
运行该.py文件即可在./trainexamplesplit和./valexamplesplit中得到结果,仍然是./trainexamplesplit/images、./trainexamplesplit/labelTxt和./valexamplesplit/images、./valexamplesplit/labelTxt中得到结果。
3. 使用SplitOnlyImage_multi_process.py切割DOTA中的test
因为test数据集不包含标签文件,而2中提到的.py文件同时对图片和标签文件进行分割,当然可以修改但没必要。DOTA_devkit提供了只对图片切割的文件SplitOnlyImage_multi_process.py,同2中一样的源码和路径处理方式
class splitbase():
def __init__(self,
srcpath,
dstpath,
gap=256,
subsize=1024,
ext='.png',
padding=True,
num_process=32):
关于gap和subsize不再赘述
在main函数中
if __name__ == '__main__':
split = splitbase(r'testexample/images',
r'testexamplesplit')
split.splitdata(1)
三、DOTA的annotation格式转换为YOLO格式
3.1 环境和安装
环境和安装包如下:
环境:同二的恒源云服务器
安装包:还是使用DOTA_devkit,但需要额外补充一个文件YOLO_Transform.py
文件来源:https://github.com/hukaixuan19970627/DOTA_devkit_YOLO/blob/master/YOLO_Transform.py
3.2 DOTA的标签格式和分类名称
打开任意一个已经分割后的标签文件,如下
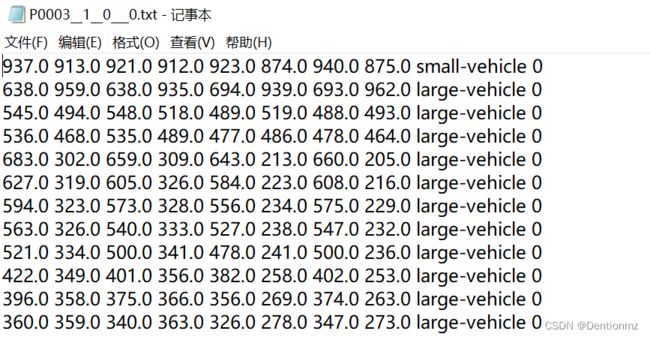
上图中前8个数据代表真实框四个点的坐标,small-vehicle是DOTA数据集的分类,最后的0表示识别难易程度是简单,为1表示难。DOTA数据集的分类名称如下:
classes_names = ['small-vehicle', 'large-vehicle', 'plane', 'storage-tank', 'ship', 'harbor', 'ground-track-field', 'soccer-ball-field', 'tennis-court', 'swimming-pool', 'baseball-diamond', 'roundabout', 'basketball-court', 'bridge', 'helicopter']
3.3使用YOLO_Transformer.py转换标签格式
我们只需关注dota2Darknet(imgpath, txtpath, dstpath, extractclassname)函数,并在main函数中调整
if __name__ == '__main__':
## an example
'''
dota2LongSideFormat('./DOTA_demo/images',
'./DOTA_demo/labelTxt',
'./DOTA_demo/yolo_labels',
util.classnames_v1_5)
drawLongsideFormatimg(imgpath='DOTA_demo/images',
txtpath='DOTA_demo/yolo_labels',
dstpath='DOTA_demo/draw_longside_img',
extractclassname=util.classnames_v1_5)
'''
# Format : dota2Darknet(imgpath, txtpath, dstpath, extractclassname)
extractclassname=['small-vehicle', 'large-vehicle', 'plane', 'storage-tank', 'ship', 'harbor', 'ground-track-field', 'soccer-ball-field', 'tennis-court', 'swimming-pool', 'baseball-diamond', 'roundabout', 'basketball-court', 'bridge', 'helicopter']
dota2Darknet('./valexamplesplit/images', './valexamplesplit/labelTxt', './valexamplesplit/labelYolo', extractclassname)
其中extractclassname就是classes_names,上述源码给出val的label和images的路径,待转标签格式的图片存放在./valexamplesplit/images,待转标签格式的标签存放在./valexamplesplit/labelTxt,转成Yolo标签格式的标签存放在./valexamplesplit/labelYolo。关于train可以类似操作。
我们运行该.py文件即可实现DOTA风格标签转Yolo风格的标签。
我们打开前述DOTA标签风格的P0003__1__0___0.txt经过转换后对应的文件,如下
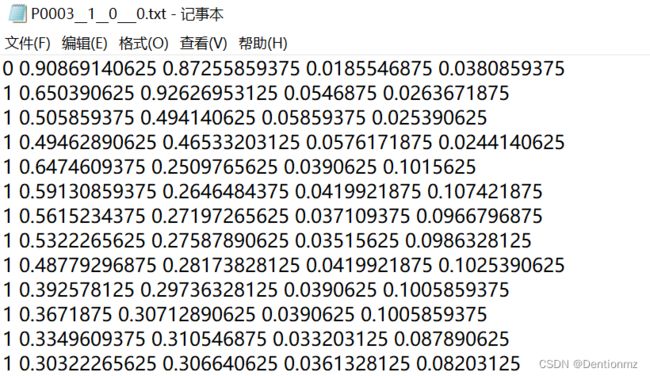
参照classes_names中0表示small-vehicle,1表示large-vehicle,所以可以与前述文件中的类对应起来。
总结
到这里为止,我们已经得到了分割后的DOTA数据集(Train、Val和Test)以及对应的DOTA风格标签转换为Yolo风格标签。