基于Spark的KNN算法的非并行化与并行化实现
一、KNN的原理
K最近邻(K Nearest Neighbors,KNN)算法的思想较为简单。该算法认为有着相同分类号的样本相互之间也越相似,因此通过计算待预测样本和已知分类号的训练样本之间的距离来判断该样本属于某个已知分类号的概率,并选取概率最大的分类号作为待预测样本的分类号。
具体过程简单而言,就是输入一个待预测样本,计算它与每个训练样本的距离,获得离它最近的K个训练样本实例,然后根据这K个训练样本实例的分类号,用某种“投票”模型计算得到该待预测样本的分类号,或者直接选取K个分类中概率最大的分类值作为待预测样本的分类结果。
和K-Means相似,距离度量需要根据具体应用来使用不同的距离度量模型,本实验中为了方便,直接使用欧氏距离计算。同时在“投票”模型上,直接将距离最近的这K个训练样本实例中出现最多的分类号作为此样本的分类号。
二、数据集
为了便于上手、理解模型具体过程和测试程序,我选择了通俗易懂的西瓜数据集,该数据集是机器学习的“常客”了,数据的维数少,并且数据不需归一化处理来计算欧氏距离,将实验的重心放在算法实现上而不是数据集的格式上。如果能对该简单数据集处理过程有深入的了解,将其换成多维数据集(如鸢尾花数据集)也异曲同工,只需要在计算距离时进行简单的修改即可。
以下是数据集:
密度 含糖率 好瓜
0.697 0.460 1
0.774 0.376 1
0.634 0.264 1
0.608 0.318 1
0.556 0.215 1
0.403 0.237 1
0.481 0.149 1
0.437 0.211 1
0.666 0.091 0
0.243 0.267 0
0.245 0.057 0
0.343 0.099 0
0.639 0.161 0
0.657 0.198 0
0.360 0.370 0
0.593 0.042 0
0.719 0.103 0数据集用作训练集时,为了方便处理,将第一行label信息直接删去,避免函数中频繁地对第一行单独处理。
测试机使用随机生成的数据,同样的,第一行label信息在输入时也先删去。
密度 含糖率
0.615 0.380
0.731 0.466
0.612 0.364
0.448 0.318
0.126 0.295
0.383 0.467
0.461 0.949
0.737 0.281
0.566 0.101
0.945 0.297
0.855 0.657
0.373 0.549
0.699 0.211
0.557 0.198
0.369 0.170
0.698 0.642
0.699 0.003目标是得到每一行数据所对应的是1(好瓜)还是0(坏瓜)
三、串行化实现(scala)
为了体现并行和非并行的差异度,在这里我完全使用scala语言编写KNN算法(不引入spark库)。
代码实现
下面是主函数整体逻辑:
def main(args: Array[String]): Unit = {
//读文件
val train = Source.fromFile("/home/hadoop/test4/watermalon3.in").getLines().toArray
val test = Source.fromFile("/home/hadoop/test4/test.in").getLines().toArray
var output = ""
for (i <- test) {
val t = getKNN(i, train)
output += i + " " + t + "\n"
}
//输出到文件
val writer = new PrintWriter(new File("/home/hadoop/test4/KNNout"))
writer.write(output)
writer.close()
}首先从目录下读入训练集和测试集。使用了Source函数,这是scala.io库的函数,用于读取文件,返回的是String的迭代器,为了方便计算,用toArray转化为Array[String],这样每一个Array[i]表示读取的一行数据,例如train[0]就是“0.697 0.460 1”,test[0]就是“0.615 0.380”。
然后对test的每个数据(相当于一个给出了密度和含糖率西瓜),计算它与训练集train里每一个已经给出分类信息的数据距离,再选出最短的k个,然后找出这k个里面最多的类别是什么,就是这一个数据的标签。这些过程都通过getKNN()函数来实现。
getKNN(String,Array[String])输入为一个String测试数据和一个Array[String]训练集,然后返回这个测试数据的类别。
代码如下:
//KNN计算的主要过程,返回输入一行数据所对应的类别
def getKNN(theTest: String, theTrains: Array[String]): String = {
val distances = theTrains.map(y => getDistance(theTest, y))
//返回distances类型为Array[(Double,String)]
//对distances进行排序,并且保留前k个
val knn = distances.toList.sortBy(_._1).take(k)
//返回knn的类型List[(Double,String)]
//将前k个点聚类
val group = knn.map(x => (x._2, 1.0)).groupBy(_._1)
//返回group类型为 Map[String, List[(String, Double)]]
//返回类最多的类名
val list = group.map(x => (x._1, x._2.length)).toList.maxBy(_._2)
//返回list类型为 List[(String, Int)],String是类别,Int是个数
//返回最大的一个类
return list._1
} theTest是输入的一行数据,如“0.615 0.380”;theTrains是输入的多行数据,也就是训练集的所有数据。通过训练集theTrains的map映射计算的每个元素与theTest的距离得到distance。这里使用了一个getDistance(theTest, y)函数,函数功能是输入两个String内容,如训练集“1 2 1”,测试集“2 4”,两个String内容的距离为![]() ,返回的distance为(5,1),1是训练集的类别。然后对返回的多个distances按照距离进行排序,使用sortBy(_._1),再用take(k)取前k个,返回knn。使用sortBy之前必须要转成List,Array无法使用sortBy。
,返回的distance为(5,1),1是训练集的类别。然后对返回的多个distances按照距离进行排序,使用sortBy(_._1),再用take(k)取前k个,返回knn。使用sortBy之前必须要转成List,Array无法使用sortBy。
然后对knn里面的前k个统计最多的类。方法使用groupBy将相同属性值的聚在一起,然后统计出同一类的数据个数,使用maxBy找出最大的一个并返回。
上面提到的getDistance函数如下:
//计算两个点的距离
def getDistance(theTest: String, theTrain: String): (Double, String) = {
//对字符串分割
val testTuples = theTest.split(" ")
val trainTuples = theTrain.split(" ")
var sum = 0.0;
for (i <- 0 until 2) {
val delta = testTuples(i).toDouble - trainTuples(i).toDouble
sum += delta * delta
}
return (sum, trainTuples(2))
}过程将两个String按照“ ”分割得到每一个维度的值,然后相减再平方,然后累加。
最后就是将结果写回到文件。这里使用的是PrintWriter和File,分别是java.io库里的函数。用法简单,就是普通字符流操作。
分析
上面过程语言化描述是十分清晰的。假设测试集有10个点 ,训练集有20个点
,训练集有20个点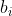 ,那么计算过程就是对于每个,依次计算
,那么计算过程就是对于每个,依次计算![]() 到
到![]() 的距离,然后返回最小的k个距离里面的最多的类。这样有一个问题就是,假设在计算的时候,
的距离,然后返回最小的k个距离里面的最多的类。这样有一个问题就是,假设在计算的时候,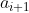 以及往后的点都必须等待它计算完才开始,哪怕它们之间是可以独立运行的。同时在计算到
以及往后的点都必须等待它计算完才开始,哪怕它们之间是可以独立运行的。同时在计算到![]() ~
~![]() 的距离时,也是可以并行的。让一个task去执行计算到
的距离时,也是可以并行的。让一个task去执行计算到 距离和另外一个task去执行 到
距离和另外一个task去执行 到![]() 距离是不冲突的,最后将结果收集起来找出最小的k个即可,因此引入并行化的实现。
距离是不冲突的,最后将结果收集起来找出最小的k个即可,因此引入并行化的实现。
源代码
import java.io.{File, PrintWriter}
import scala.io.{Source}
object KNN {
val k = 5 //KNN中的参数K
//计算两个点的距离
def getDistance(theTest: String, theTrain: String): (Double, String) = {
//对字符串分割
val testTuples = theTest.split(" ")
val trainTuples = theTrain.split(" ")
var sum = 0.0;
for (i <- 0 until 2) {
val delta = testTuples(i).toDouble - trainTuples(i).toDouble
sum += delta * delta
}
return (sum, trainTuples(2))
}
//KNN计算的主要过程,返回输入一行数据所对应的类别
def getKNN(theTest: String, theTrains: Array[String]): String = {
val distances = theTrains.map(y => getDistance(theTest, y))
//返回distances类型为Array[(Double,String)]
//对distances进行排序,并且保留前k个
val knn = distances.toList.sortBy((_._1)).take(k)
//返回knn的类型List[(Double,String)]
//将前k个点聚类
val group = knn.map(x => (x._2, 1.0)).groupBy(_._1)
//返回group类型为 Map[String, List[(String, Double)]]
//返回类最多的类名
val list = group.map(x => (x._1, x._2.length)).toList.maxBy(_._2)
//返回list类型为 List[(String, Int)],String是类别,Int是个数
//返回最大的一个类
return list._1
}
def main(args: Array[String]): Unit = {
//读文件
val train = Source.fromFile("/home/hadoop/test4/watermalon3.in").getLines().toArray
val test = Source.fromFile("/home/hadoop/test4/test.in").getLines().toArray
var output = ""
for (i <- test) {
val t = getKNN(i, train)
output += i + " " + t + "\n"
}
//输出到文件
val writer = new PrintWriter(new File("/home/hadoop/test4/KNNout"))
writer.write(output)
writer.close()
}
}
四、并行化实现(scala+spark)
spark的RDD是实现并行化的一个很好的方式。上面串行实现时可以发现有很多map映射操作。如果对RDD进行map操作,那么它将按照每个RDD的分区分配不同的task去执行,这样就体现了并行。
代码实现
函数过程如下,代码十分简短:
def main(args: Array[String]): Unit = {
//启动spark并读入数据
val sparConf = new SparkConf().setMaster("local").setAppName("KNN")
val sc = new SparkContext(sparConf)
val train = sc.textFile("file:///home/hadoop/test4/watermalon3.in", 2)
//广播变量,防止RDD嵌套
val train_brocast = sc.broadcast(train.collect())
val test = sc.textFile("file:///home/hadoop/test4/test.in", 2)
val result = test.map(x => {
val dis = train_brocast.value.map(y => getDistance(x, y))
val kNN = dis.sortBy(_._1).take(k)
val list = kNN.map(g => (g._2, 1.0)).groupBy(_._1)
.map(g => (g._1, g._2.length)).toList.maxBy(_._2)
(x.split(" ")(0) + " " + x.split(" ")(1) + " " + list._1)
})
// 输出到本地文件系统看看是否正确
val SavePath = "/home/hadoop/test4/KNNout_parallel_plus"
val file = new File(SavePath)
if (file.exists()) //文件路径存在
dirDel(file)
result.saveAsTextFile("file://" + SavePath)
}
下面具体分析:
//启动spark并读入数据
val sparConf = new SparkConf().setMaster("local").setAppName("KNN")
val sc = new SparkContext(sparConf)
val train = sc.textFile("file:///home/hadoop/test4/watermalon3.in", 2)
//广播变量,防止RDD嵌套
val train_brocast = sc.broadcast(train.collect())
val test = sc.textFile("file:///home/hadoop/test4/test.in", 2)前面两行是spark的基本操作,创建SparkConf,然后获得SparkContext,接着使用它来对文件数据进行读取。
这边读取train数据集后使用了一个广播变量train_brocast,是为了防止RDD嵌套。后面会详细说明,这里在逻辑上可以认为train_brocast与train没有差异。
读文件时设置了最小分区数为2,目的是提高并行度。
接下来是计算KNN的核心过程:
val result = test.map(x => {
val dis = train_brocast.value.map(y => getDistance(x, y))
val kNN = dis.sortBy(_._1).take(k)
val list = kNN.map(g => (g._2, 1.0)).groupBy(_._1)
.map(g => (g._1, g._2.length)).toList.maxBy(_._2)
(x.split(" ")(0) + " " + x.split(" ")(1) + " " + list._1)
})
整体函数思路与串行化是一致的,后面聚类为了简便,我将它们写在了一行。
区别是,对于测试集test的每一个元素x都是用map去执行计算其应该所属的类别,原本串行化使用的是for循环(用map也一样),而这里的test属性已经是RDD[String],虽然也是map,但是过程已经可以根据分区实现并行(也就是差别不是使用了map与否,而是进行map的对象不同了,原本是Array[String],现在是RDD[String])。
在计算一个数据点和多个数据点的距离时,也是并行的。如果我们假设没有使用train_bocast,那么train此时类型也是RDD[String],对其使用map(y => getDistance(x, y))也是并行的,我们这里把训练集分了两个分区,两个分区可以并行的计算到测试点的距离。
理想很美好,但是事实上这样运行会报错,因为RDD是无法嵌套的。原因是Spark程序的大部分操作都是RDD操作,通过传入函数给RDD操作函数来计算,这些函数在不同节点上并发执行,但每个内存的变量有不同的作用域,不能相互访问。
这里采用的是广播变量,将各个task需要用到训练集发送给到各个Executor。广播是由Driver发给当前Application分配的所有Executor内存级别的全局只读变量,Executor中的线程池中的线程共享该全局变量,极大的减少了网络传输(否则的话每个Task都要传输一次该变量)并极大的节省了内存,当然也隐性的提高了cpu的有效工作。
使用广播变量确实可以运行程序了,同时相比把训练集一起发送到每个task,把driver将训练集发送到每个Executor,减少了网络传输,也节省了内存的使用。但我始终存在一个疑问,就是广播变量是否失去了并行的能力?这样计算一个点与训练集数据点的距离时,是否就只能串行地计算?由于在网上查找不到关于广播变量运行时是否和RDD存在并行的机制的资料,因此这也只能画上一个问号。
源代码
import org.apache.spark.{SparkConf, SparkContext}
import java.io.File
object KNN_parallel_plus {
def dirDel(path: File): Unit = {
if (!path.exists()) //文件路径不存在
return
else if (path.isFile()) { //要删除的是一个文件
path.delete()
return
}
//要删除的是目录
val file: Array[File] = path.listFiles()
for (d <- file) {
dirDel(d)
}
path.delete()
}
val k = 5 //KNN中的参数K
//计算两个点的距离
def getDistance(theTest: String, theTrain: String): (Double, String) = {
//对字符串分割
val testTuples = theTest.split(" ")
val trainTuples = theTrain.split(" ")
var sum = 0.0;
for (i <- 0 until 2) {
val delta = testTuples(i).toDouble - trainTuples(i).toDouble
sum += delta * delta
}
return (sum, trainTuples(2))
}
def main(args: Array[String]): Unit = {
//启动spark并读入数据
val sparConf = new SparkConf().setMaster("local").setAppName("KNN")
val sc = new SparkContext(sparConf)
val train = sc.textFile("file:///home/hadoop/test4/watermalon3.in", 2).persist()
//广播变量,防止RDD嵌套
val train_brocast = sc.broadcast(train.collect())
val test = sc.textFile("file:///home/hadoop/test4/test.in", 2)
val result = test.map(x => {
val dis = train_brocast.value.map(y => getDistance(x, y))
val kNN = dis.sortBy(_._1).take(k)
val list = kNN.map(g => (g._2, 1.0)).groupBy(_._1)
.map(g => (g._1, g._2.length)).toList.maxBy(_._2)
(x.split(" ")(0) + " " + x.split(" ")(1) + " " + list._1)
})
// 输出到本地文件系统看看是否正确
val SavePath = "/home/hadoop/test4/KNNout_parallel_plus"
val file = new File(SavePath)
if (file.exists()) //文件路径存在
dirDel(file)
result.saveAsTextFile("file://" + SavePath)
}
}
五、一点感想
关于广播变量是否支持并行
使用spark实现并行化KNN时,理想状态是建立一个具有两层并行化的模型,第一层对于测试数据的每一个点计算类别时并行,第二层是对于每一个点计算与所有点的距离时并行。但没预料到会遇到RDD嵌套的问题。将训练集变成广播变量之后,因为对广播变量了解不深入,因此没法断定广播变量是否和RDD一样可以实现并行的计算。
以下是查到的关于广播变量的特点:
①使用广播变量避免了数据混洗操作;
②广播变量使用了一种高效而伸缩性强的点到点分发机制;
③每个工作节点只会复制一次数据;
④广播变量可以被多个任务多次使用;
⑤广播变量是序列化过的对象,可高效读取。
⑥广播变量只能在Driver端定义或修改,不能在Executor端定义或修改。
如果在机理上与Array无异而不同于RDD(由于查找不到资料,可能并不是这样,希望指正),那么最后就只能实现一层并行。或许在第二层实现并行上有其他方法能绕开RDD去实现,笔者能力有限,期待有所补充。
关于排序的优化
取前k个最近距离的点的时候,事实上可以不用每次都sortBy。可以建立一个容量为K的容器,每次都和这个容器里面最大的数据比较,如果小于这个数就将其替换。这样算法复杂度会降低许多。