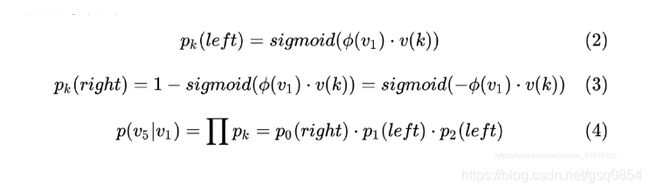DeepWalk算法(个人理解)
DeepWalk
什么是网络嵌入
将网络中的点用一个低维的向量表示,并且这些向量要能反应原先网络的某些特性。
一种网络嵌入的方法叫DeepWalk,它的输入是一张图或者网络,输出为网络中顶点的向量表示。DeepWalk通过截断随机游走(truncated random walk)学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。并且该方法还具有可扩展的优点,能够适应网络的变化。
learn social representations
-
适应性,网络表示必须能适应网络的变化。网络是一个动态的图,不断地会有新的节点和边添加进来,网络表示需要适应网络的正常演化。
-
属于同一个社区的节点有着类似的表示。网络中往往会出现一些特征相似的点构成的团状结构,这些节点表示成向量后必须相似。
-
低维。代表每个顶点的向量维数不能过高,过高会有过拟合的风险,对网络中有缺失数据的情况处理能力较差。
-
连续性。低维的向量应该是连续的。
网络嵌入:将网络中的节点用向量表示。
网络节点的表示中节点构成的序列就是随机游走。
图形嵌入
图形嵌入是解决图形分析问题的有效的方法。它将图形数据转换为低维空间,其中最大程度保留了图形结构信息和图形属性。节点嵌入的目标是将节点编码为低维向量,总结其图形位置和他们的局部图领域的结构。这些低维嵌入可以被视为将节点编码或投影到潜在空间中,其中该潜在空间中的几何关系对应与原始图形中的相互作用(例如,边缘)。
嵌入空间中的节点之间的距离反应了原始图中的节点相似性,并根据不同的颜色编码的社区对节点嵌入进行空间聚类。
Graph Embedding技术将图中的节点以低维稠密向量的形式进行表达,要求在原始图中相似(不同的方法对相似的定义不同)的节点其在低维表达空间也接近。得到的表达向量可以用来进行下游任务,如节点分类,链接预测,可视化或重构原始图等。
随机游走
所谓随机游走(random walk ),就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从当前节点相连的边中随机选择一条,沿着选定的边移动到下一个定点,不断重复这个过程。截断随机游走实际上就是长度固定的随机游走。
随机游走的好处:
- 并行化,随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
- 适应性,可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
$Pr(vi|v0,v1,…,vi-1)) $
即为所要优化的目标,意义为:当知道 ( v 0 , v 1 , . . . , v i − 1 ) (v_0,v_1,...,v_{i-1}) (v0,v1,...,vi−1)游走路径后,游走的下一个节点是 v i v_i vi的概率为多少。
由于顶点本身无法计算,需引入一个映射函数,将顶点映射为向量,从而得以计算。
Alogrithm
整个DeepWalk看算法包含两部分,一部分 是随机游走的生成,一部分是参数的更新。

其中第2步是构建Hierarchical Softmax,第3步对每个节点做γ次随机游走,第4步打乱网络中的节点,第5步以每个节点为根节点生成长度为t的随机游走,第7步根据生成的随机游走使用skip-gram模型利用梯度的方法对参数进行更新。

Word2vec
Word2vec是2013年由Tomas Mikolov提出的,其核心思想是**用一个词的上下文去刻画这个词。**从这个思想出发,有两种不同的模型:
- CBOW:给定中心词的上下文 预测 该中心词
- Skip-Gram:给定一个中心词去预测它的上下文
给定一个语料库,它可以由多篇文档组成,为了简化,假设该语料库可以表示为一个序列C={w 1 ,w 2 ,…,w N },语料库的长度为N,单词的词表为V,w i ∈V。Skip-gram模型是使用中心词去预测其上下文词,这里定义上下文词为以中心词为中心的某个窗口内的词,假设窗口大小为2m+1。给定中心词,要能够正确地预测上下文词,即我们希望在给定某个中心词的条件下,输出词为上下文的概率最大。
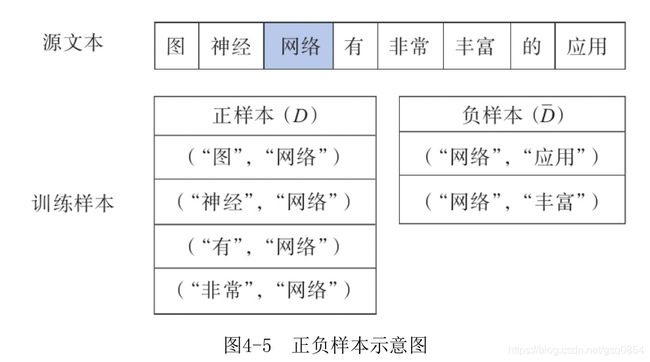
以如图4-5所示的一句话为例,选择m=2,考查中心词“网络”,它的上下文为{“图”,“神经”,“有”,“非常”},我们可以构造这样的单词对[(“图”,“网络”),(“神经”,“网络”),(“有”,“网络”),(“非常”,“网络”)],我们称这种由中心词及其上下文词构成的单词对为正样本,记为D,由中心词与其非上下文词构成的单词对为负样本,记为D,比如(“网络”,“应用”)。
要想正确地根据中心词预测上下文词,可以最大化样本中的单词对作为上下文出现的概率,同时最小化负样本中单词对作为上下文出现的概率,以此构造目标函数。具体来说,对正负样本定义标签,如下:其中 w c w_c wc表示中心词。

这个问题就转换为一个二分类问题,给定任意两个词,判断它们是否是上下文,因此,可以使用逻辑回归来建模这个问题。引入两个矩阵 U ∈ R ∣ D ∣ × d , V ∈ R ∣ D ∣ × d U \in R^{|D| ×d},V \in R^{|D|×d} U∈R∣D∣×d,V∈R∣D∣×d他们中的每一行都代表着一个词,在模型训练完成后,它们就是包含语义表达的词向量。 U , V U,V U,V分别对应一个词作为中心词和上下文词两种角色下的不同表达。
对于一个词w,定义 U w U_w Uw表示它对应的词向量,那么将式子(4.17)中概率表达为式子(4.18),其中 σ ( x ) \sigma(x) σ(x)表示sigmoid函数:

这个式子一方面增大正样本的概率,另一方面减小负样本的概率,我们注意到增大正样本的概率实际上是在增大
U w c ⋅ V w U_{w_c}·V_w Uwc⋅Vw,即中心词与上下文词的内积,也就是它们之间的相似度。也就是说,最小化式(4.19)实际上会使得中心词与上下文词之间的距离更小,而与非上下文词之间的距离更大,通过这种方式作为监督信号指导模型学习,收敛之后,参数矩阵U、V就是我们需要的词向量,通常我们使用U作为最终的词向量。
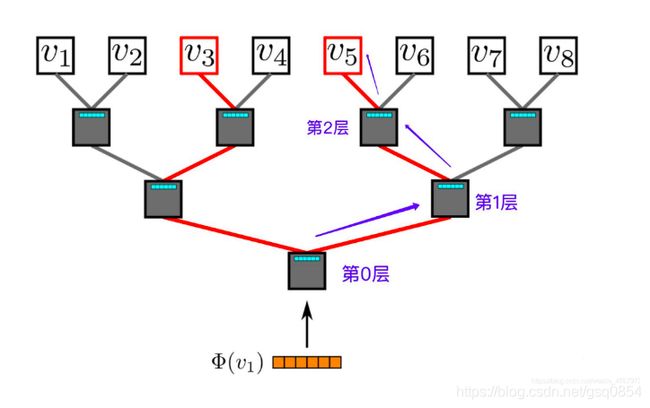
为减少计算量,构建哈弗曼树,将原来的复杂到由 ∣ V ∣ |V| ∣V∣降低到了 ∣ l o g V ∣ |logV| ∣logV∣。
哈弗曼树构建思想:
将词典中的每个词按照词频大小构建出一棵Huffman树,保证词频较大的词处于相对比较浅的层,词频较低的词相应的处于Huffman树较深层的叶子节点,每一个词都处于这棵Huffman树上的某个叶子节点。
哈弗曼树构建是根据是否是为正负样本 左子树为正样本,右子树为负样本。即问题变成了二分类问题。
注:要判断两个词是否为关联,并计算其关联的概率。将中心词输入到第0层,根据输入中心词的向量和上下文词的向量来计算,首先在原有的训练集中根据标签判断是有关联,如果有则为正样本,走左子树。如果没有,则为负样本,走右子树。在中间节点放置的为词频较高的词,词频越高层越浅。因此。当输入的两个词不为上下文关系时,走负样本。此时,再次比对路径中第一层节点是否与要求的上下文词有关联,以此类推。直到路径到达该上下 V w V_w Vw节点(最终目标节点)。将其中的经过的节点带入概率公式(4.19)计算,求去给定的两个词的关联概率。