Graph Embedding:DeepWalk
参考文章:
我是从第一个链接理解deepwalk的,DeepWalk = Random + Skip_gram(NLP中的)两部分组成的,random walk类似于图的DFS,Skip_gram比较难理解,看了一天也是比较懵,希望有一天我能理解,然后写一篇非常容易理解skip_gram的博客。现在不会能直接调用函数,还是比较省事的哈哈哈哈哈
使用DeepWalk从图中提取特征从表格或图像数据中提取特征的方法已经众所周知了,但是图(数据结构的图)数据呢? https://mp.weixin.qq.com/s?src=11×tamp=1636794172&ver=3433&signature=aNRyUQjNYGBUv5eXY4myRsQC1s4oicDLbIRrliL4FK6lo*Lyo24q3tHXT86hTmnY8EEHa*1n4fwj81Qokpc-YYks4EHCJ3wfX6tzMO9krX0D7vsJ4AGzthWObr5B6kvY&new=1
https://mp.weixin.qq.com/s?src=11×tamp=1636794172&ver=3433&signature=aNRyUQjNYGBUv5eXY4myRsQC1s4oicDLbIRrliL4FK6lo*Lyo24q3tHXT86hTmnY8EEHa*1n4fwj81Qokpc-YYks4EHCJ3wfX6tzMO9krX0D7vsJ4AGzthWObr5B6kvY&new=1
下面这个链接是阿里的浅梦大佬给出的code,比第一个code麻烦点,算是换个角度看code理解deepwalk吧
【Graph Embedding】LINE:算法原理,实现和应用 - 知乎之前介绍过DeepWalk,DeepWalk使用DFS随机游走在图中进行节点采样,使用word2vec在采样的序列学习图中节点的向量表示。 DeepWalk:算法原理,实现和应用LINE也是一种基于邻域相似假设的方法,只不过与DeepWalk使用… https://zhuanlan.zhihu.com/p/56478167
https://zhuanlan.zhihu.com/p/56478167
论文链接:http://www.perozzi.net/publications/14_kdd_deepwalk.pdf http://www.perozzi.net/publications/14_kdd_deepwalk.pdf
http://www.perozzi.net/publications/14_kdd_deepwalk.pdf
目录:
-
数据的图示
-
不同类型的基于图的特征
-
节点属性
-
局部结构特征
-
节点嵌入
-
DeepWalk简介
-
在Python中实施DeepWalk以查找相似的Wikipedia页面
1.数据的图示
当你想到“网络”时,会想到什么?通常是诸如社交网络,互联网,已连接的IoT设备,铁路网络或电信网络之类的事物。在图论中,这些网络称为图。
网络是互连节点的集合。节点表示实体,它们之间的连接是某种关系。
例如,我们可以用图的形式表示一组社交媒体帐户:

节点是用户的数字档案,连接表示他们之间的关系,例如谁跟随谁或谁与谁是朋友。
图的用例不仅限于社交媒体!我们还可以使用图和网络表示其他类型的数据
为什么我们将数据表示为图?
为什么不仅仅使用典型的数据可视化技术来可视化数据?为什么要更复杂并学习新概念?下面我们会给出答案。
图数据集和数据库可帮助我们应对在处理结构化数据时面临的若干挑战。这就是为什么当今的主要科技公司,例如Google,Uber,Amazon和Facebook使用某种形式的图的原因。
让我们以一个例子来理解为什么图是数据的重要表示形式。看下图:

这是一小部分Facebook用户(a, B, C, D, E, F, G)的数据集。图像的左半边包含这个数据的表格形式。每一行代表一个用户和他/她的一个朋友。
右半部分包含代表同一组用户的图。该图的边缘告诉我们,连接的节点是Facebook上的朋友。现在,让我们解决一个简单的查询:
“找到用户A的朋友和用户A朋友的朋友。”
查看表格数据和上面的图。哪种数据形式更适合回答此类查询?
使用图来解决该问题要容易得多,因为我们只需要遍历从节点A长度为2的路径(ABC和ADF),即可找到朋友和朋友的朋友。
因此,图可以轻松捕获节点之间的关系,这在常规数据结构中是一项艰巨的任务。现在,让我们看看使用图可以解决什么样的问题
基于图的特征的不同类型
为了解决上述问题,我们无法将图直接提供给机器学习模型。我们必须首先从中创建特征,然后模型将使用这些特征。
此过程类似于我们在自然语言处理(NLP)或计算机视觉中所做的过程。我们首先从文本或图像中提取数字特征,然后将这些特征作为输入提供给机器学习模型:

从图中提取的特征可以大致分为三类:
-
节点属性:我们知道图中的节点代表实体,并且这些实体具有自己的特征属性。我们可以将这些属性用作每个节点的特征。例如,在航空公司航线网络中,节点将代表机场。这些节点将具有飞机容量,航站楼数量,着陆区等特征。
2.局部结构特点:节点的度(相邻节点的数量),相邻节点的平均度,一个节点与其他节点形成的三角形数,等等。 -
节点嵌入:上面讨论的特征仅包含与节点有关的信息。它们不捕获有关节点上下文的信息。在上下文中,我指的是周围的节点。节点嵌入通过用固定长度向量表示每个节点,在一定程度上解决了这个问题。这些向量能够捕获有关周围节点的信息(上下文信息)
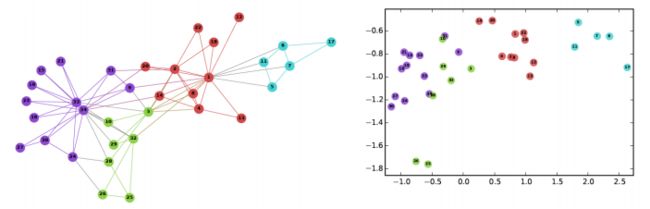
用于学习节点嵌入的两个重要的现代算法是DeepWalk和Node2Vec。在本文中,我们将介绍并实现DeepWalk算法。
DeepWalk简介
要了解DeepWalk,重要的是要正确理解词嵌入及其在NLP中的使用方式。我建议在下面的文章中仔细阅读Word2Vec的解释:
Build a Recommendation System Using word2vec in PythonLearn how to build your own recommendation system in Python using word2vec. Work on a retail dataset using word2vec in Python to recommend products.https://www.analyticsvidhya.com/blog/2019/07/how-to-build-recommendation-system-word2vec-python/?utm_source=blog&utm_medium=graph-feature-extraction-deepwalk
为了将事物置于上下文中,词嵌入是文本的向量表示形式,它们捕获上下文信息。让我们看看下面的句子:
-
我乘巴士孟买
-
我乘火车去孟买
粗体字(公共汽车和火车)的向量将非常相似,因为它们出现在相同的上下文中,即粗体文本之前和之后的词。该信息对于许多NLP任务非常有用,例如文本分类,命名实体识别,语言建模,机器翻译等等。
我们还可以在每个节点的图中捕获此类上下文信息。但是,为了学习NLP空间中的词嵌入,我们将句子提供给Skip-gram模型(浅层神经网络)。句子是按一定顺序排列的单词序列。
因此,要获得节点嵌入,我们首先需要安排图中的节点序列。我们如何从图中获得这些序列?有一项针对该任务的技术称为随机游走。
什么是随机游走?
随机游走是一种从图中提取序列的技术。我们可以使用这些序列来训练一个skip-gram模型来学习节点嵌入。
让我说明一下随机游走的工作原理。让我们考虑下面的无向图:

我们将在该图上应用随机游走并从中提取节点序列。我们将从节点1开始,并覆盖任意方向的两条边:
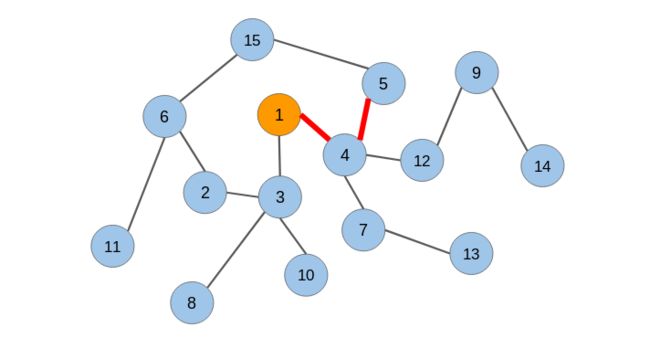
从节点1,我们可以转到任何连接的节点(节点3或节点4)。我们随机选择了节点4。现在再次从节点4开始,我们不得不随机选择前进的方向。我们将转到节点5。现在我们有3个节点的序列:[节点1 –节点4 –节点5]。
让我们生成另一个序列,但是这次是从另一个节点生成的

让我们选择节点15作为原始节点。从节点5和6,我们将随机选择节点6。然后从节点11和2,我们选择节点2。新序列为[节点15 –节点6 –节点2]。
我们将对图中的每个节点重复此过程。这就是随机游走技术的工作原理
在生成节点序列之后,我们必须将它们提供给一个skip-gram模型以获得节点嵌入。整个过程被称为Deepwalk。
什么是Skip_gram?
我自己也是一知半解,就不在这里误人子弟了,看了许多博客,个人认为这篇写的很详细:
NLP之---word2vec算法skip-gram原理详解_Ricky-CSDN博客_skipgram1.词嵌入(word2vec)自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是用来表示词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌入(word embedding)。近年来,词嵌入已逐渐成为自然语言处理的基础知识。2.为何不采用one-hot向量【如何使用one-hot】假设词典中不同词的数量(词典大小)为NNN...https://blog.csdn.net/weixin_41843918/article/details/90312339?spm=1001.2014.3001.5506
Talk is cheap,show me the code
导入所需的Python库
import networkx as nx
import pandas as pd
import numpy as np
import random
from tqdm import tqdm
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
%matplotlib inline加载数据集
数据集下载
1我的博客:space_data.zip-其它文档类资源-CSDN下载我的博客里面GraphEmbedding:deepwalk里的数据集更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/weixin_49993963/41307438
2.原文章里链接:https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/11/space_data.ziphttps://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/11/space_data.zip
df = pd.read_csv("space_data.tsv", sep = "\t")
df.head()
Output:

源和目标都包含Wikipedia实体。对于所有行,目标实体在源实体的Wikipedia页面有其超链接。
构造图
G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())让我们检查图中的节点数:
len(G)
Output: 2088
我们将处理2,088个Wikipedia页面。
随机游走
'''
在这里,我定义了一个函数,将节点和被遍历的路径的长度作为输入。
它将从指定的输入节点以随机的方式穿过连接节点。最后,它将返回遍历节点的顺序
'''
def get_randomwalk(node, path_length):
random_walk = [node]
for i in range(path_length-1):
temp = list(G.neighbors(node))
temp = list(set(temp) - set(random_walk))
if len(temp) == 0:
break
random_node = random.choice(temp)
random_walk.append(random_node)
node = random_node
return random_walk让我们试试节点“space exploration”这个函数
get_randomwalk('space exploration', 10)
Output:

'''
在这里,我已指定要遍历的长度为10。
你可以更改此数字并进行操作。
接下来,我们将捕获数据集中所有节点的随机游走序列:
'''
# 从图获取所有节点的列表
all_nodes = list(G.nodes())
random_walks = []
for n in tqdm(all_nodes):
for i in range(5):
random_walks.append(get_randomwalk(n,10))
# 序列个数
len(random_walks)输出: 10,440
因此,将遍历长度设置为10,我们得到了10,440个节点的随机游动序列。我们可以将这些序列用作skip-gram模型的输入,并提取该模型学习到的权重。
完整代码:
# importing required libraries
import pandas as pd
import networkx as nx
import numpy as np
import random
from tqdm import tqdm
from sklearn.decomposition import PCA
import pprint
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
# read the dataset
df = pd.read_csv("space_data.tsv", sep = "\t")
print(df.head())
G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())
G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())
print('The number of nodes in pur graph: ',len(G))
def get_randomwalk(node, path_length):
random_walk = [node]
for i in range(path_length-1):
temp = list(G.neighbors(node))
temp = list(set(temp) - set(random_walk))
if len(temp) == 0:
break
random_node = random.choice(temp)
random_walk.append(random_node)
node = random_node
return random_walk
print('\n\nRandom sequence of nodes generated from Random Walk\n\n')
while True:
first_node = input("Enter name of first node (for example 'space exploration') : ")
if len(first_node) > 0:
break
pprint.pprint(get_randomwalk(first_node, 10))
# 从图中获取所有节点的列表
all_nodes = list(G.nodes())
random_walks = []
for n in tqdm(all_nodes):
for i in range(5):
random_walks.append(get_randomwalk(n,10))
# 序列长度
len(random_walks)
# 训练skip-gram (word2vec)模型
model = Word2Vec(window = 4, sg = 1, hs = 0,
negative = 10, # 负采样
alpha=0.03, min_alpha=0.0007,
seed = 14)
model.build_vocab(random_walks, progress_per=2)
model.train(random_walks, total_examples = model.corpus_count, epochs=20, report_delay=1)
print('\n\n Get similar nodes\n\n')
while True:
any_node = input("Enter name of any node (for example 'space toursim') : ")
if len(any_node) > 0:
break
pprint.pprint(model.similar_by_word(any_node))