Ubuntu18.04实现Tensorflow框架下的Fasterrcnn目标检测
参考链接有,再次感谢各位前辈:
https://github.com/XuleiTao/ilove996/tree/master/tf-faster-rcnn
Faster R-CNN Github源码 tensorflow GPU下demo运行,训练,测试,验证,可视化。_CVDLML的博客-CSDN博客
python3+Tensorflow+Faster R-CNN训练自己的数据_北冥有杨其名为超的博客-CSDN博客
Ubuntu+GPU+Tensorflow运行tf-faster-rcnn【光纤分类项目】 - 简书
最近因为需要完成FasterRCNN的加速优化,找了一些资料,参考一些博客和github上的代码,找到了一个可能实现的,准备试一试。首先第一步要实现FasterRCNN的模型训练和检测,找到一个在前辈们努力的基础上实现的一个代码,现在记录下我走过的过程,供大家参考!也方便自己以后需要的时候回顾,持续更新..........
Faster_RCNN源码:GitHub - endernewton/tf-faster-rcnn: Tensorflow Faster RCNN for Object Detection
一、环境配置
1、系统:Ubuntu18.04
2、显卡:GTX 1060 (后面有用先要确认)
lspci | grep -i vga
# 显卡是GeForce GTX 1060 6GB3、虚拟环境(Anaconda3)
一般情况下,我都是创建虚拟环境进行训练测试,因为很方便,用完后可以直接删掉,并且出错了可以重来,不用害怕死机,下面是我之前写的一个文章有Anaconda3的安装,有需要可以看看
Ubuntu18.04+CUDA10.0+cudnn7.6.5+Anaconda3+pytorch==1.2.0 torchvision==0.4.0_beautifulback的博客-CSDN博客
步骤:
conda create -n tf_fasterrcnn python==3.6
# To activate this environment, use
#
# $ conda activate tf_fasterrcnn
#
# To deactivate an active environment, use
#
# $ conda deactivate
conda activate tf_fasterrcnn4、Tensorflow1.9 + cuda10.2+cudnn8.3.0
! ! ! 当然你也可以用自己现有的版本,只是说你的cuda+cudnn需要和Tensorflow版本对应
! ! ! 这个工程之前有博主(上面链接有,他用的是cuda==9.0)验证过tensorflow1.2.1不行,升级到tensorflow1.12.0版本太高,与CUDN9.0不兼容(CUDN9.0 + CUDNN7.0.5(安装参考此教程)tensorflow-gpu 1.7.0,python -m pip install tensorflow-gpu==1.7.0)
因为原博客是几年前写的当时的cuda用的是9.0,但是现在我大多数时候都是用的cuda==10.2,不想麻烦重新下旧版本,就直接在cuda10.2+cudnn8.3.0基础上找对应的Tensorflow的版本,有博客推荐用Tensorflow==1.9,于是我安装的1.9,实时证明可以成功了!
① cuda10.2+cudnn8.3.0安装:https://blog.csdn.net/m0_53397118/article/details/121896304
nvcc -V # 查看cuda的版本
cat /usr/local/cuda-10.2/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 # 查看cudnn的版本② Tensorflow==1.9安装:
conda install tensorflow-gpu=1.9
# 安装完成后,可以在环境中用下面的命令查看(我的是这样的)
(base) lh@lh:~$ conda activate tf_fasterrcnn
(tf_fasterrcnn) lh@lh:~$ python
Python 3.6.0 | packaged by conda-forge | (default, Feb 9 2017, 14:36:55)
[GCC 4.8.2 20140120 (Red Hat 4.8.2-15)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow
>>> tensorflow.__version__
'1.9.0'但是刚刚安装完可能会出现这样的情况,可以看到最后import tensorflow也是对的,并且我也试过并不影响后面的使用,但是后来我还是看着不太舒服,想把这一串报错去掉,找到了原因。
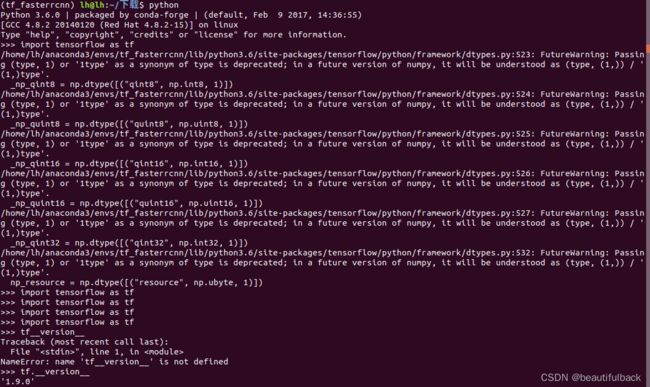
我们一般现在创建虚拟换将python==3.6或者以上,都是自带的numpy==1.19.5,这与这个tensorflow版本有点冲突,需要降低numpy的版本,很简单!两条命令就可以解决:
参考:Numpy卸载与重装_多多有个梦想的博客-CSDN博客_卸载numpy
pip uninstall numpy # Successfully uninstalled numpy-1.19.5(卸载高版本的numpy==1.19.5)
pip install numpy==1.16.4 # Successfully installed numpy-1.16.4(安装低版本numpy==1.16.4)
# pip install -U numpy== 1.16.4 (或可使用)
如果出现卸载不了numpy==1.19.5,可以直接在我们自己创建的虚拟环境中手动移动到回收站,在site-packages里面,
它的路径是(我的是):/home/lh/anaconda3/envs/tf_fasterrcnn/lib/python3.6/site-packages/numpy-1.19.5.dist-info,只删除numpy-1.19.5.dist-info,其他不动。
然后再执行上面两步,如果有红色报错或者黄色警告,但最终有#后面生成的部分,就表示成功了,可以用它查看:
import numpy
numpy.__version__ # 1.16.45、补充需要的包的安装 + 出现过的错误(后续执行过程有什么问题都可以在这里找)
# ModuleNotFoundError: No module named 'Cython'
pip install cython
# ModuleNotFoundError: No module named 'matplotlib'
pip install matplotlib
# ModuleNotFoundError: No module named 'cv2'
pip install opencv-python
# ModuleNotFoundError: No module named 'easydict'
pip install easydict
# AttributeError: 'version_info' object has no attribute '__version__'
pip install pyparsing==2.4.7
# ModuleNotFoundError: No module named 'scipy'
pip install scipy --user
# ModuleNotFoundError: No module named 'yaml'
pip install pyyaml
#可能出现的错误
TypeError: load() missing 1 required positional argument: 'Loader'
由于Yaml 5.1版本后弃用了 yaml.load(file) 这个用法。Yaml 5.1版本之后就修改了需要指定Loader,通过默认加载器(FullLoader)禁止执行任意函数,使得此load函数的安全得到加强。
File "/home/lh/下载/tf-faster-rcnn/tools/../lib/model/config.py", line 362, in cfg_from_file
yaml_cfg = edict(yaml.load(f))
改为:yaml_cfg = edict(yaml.safe_load(f))二、文件配置和测试过程
1. 从Github上克隆或直接打开下面的链接下载提取工程文件tf-asterr-cnn
git clone https://github.com/endernewton/tf-faster-rcnn.git2. 根据自己电脑的显卡,更改对应的计算单元,在tf-faster-rcnn/lib/setup.py的第130行,GTX 1060对应的是sm_61。在这可以查到每种显卡对应的计算单元
# 我的路径如下
cd /home/lh/下载/tf-faster-rcnn/lib
vim steup.py3. 在 tf-faster-rcnn/lib文件夹下运行下面的代码:
make clean # 输出是:rm -rf */*.pyc 、 rm -rf */*.so
make # 输出是编译的过程
cd .. # 退回到tf-faster-rcnn根目录注意:这里结束后是在tf-faster-rcnn/文件夹下。
4. 安装COCO API(代码需要API来访问COCO dataset),按下面步骤运行即可:
cd data # 这里是tf-faster-rcnn/data/文件夹下
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI # 在data文件夹下,用上面的命令下载了coco文件夹,进入到里面的PythonAPI/文件夹下
make
cd ../../.. # 这里是退回到了tf-faster-rcnn/文件夹下5. 下载数据(与其他下载VOC2007一样),这里下载完后是在tf-faster-rcnn/文件夹下。
① Download the training, validation, test data and VOCdevkit(下载后有3个文件夹)
这个过程如下但很漫长,我下载并保存到了我的网盘中链接: Pascal VOC2007(提取码:htl5)
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
② Extract all of these tars into one directory named VOCdevkit(解压后得到一个文件夹)
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
③ It should have this basic structure(这是看它的文件夹下有那些内容)
$VOCdevkit/ # development kit
$VOCdevkit/VOCcode/ # VOC utility code
$VOCdevkit/VOC2007 # image sets, annotations, etc.
# ... and several other directories ...
④ Create symlinks for the PASCAL VOC dataset(创建软连接)
cd $FRCN_ROOT/data
ln -s $VOCdevkit VOCdevkit2007
之前看了好多博客关于这一步没有详细的写,或者创建软连接不成功(这种简单的办法就是直接将上面得到的VOCdevkit文件夹直接复制到tf-faster-rcnn/data/文件夹下)
以我自己的为例,这里的$VOCdevkit可以创建绝对路径就能成功了,看到有个向上的箭头!
# (tf_fasterrcnn) lh@lh:~/下载/tf-faster-rcnn$ cd data
cd data
# lh是我的用户名
ln -s /home/lh/下载/tf-faster-rcnn/VOCdevkit VOCdevkit2007 
6. 下载预训练模型
./data/scripts/fetch_faster_rcnn_models.sh
有几百M大小,下载速度慢,试过好像已经被删除了(这个文件夹里的文件就是这个作用)。提供以下网盘下载:voc_0712_80k-110k.tgz(提取码:9eob)、这里特别感谢:博主。下载的预训练模型为:voc_0712_80k-110k.tgz。
用下面的命令解压.tgz得到voc_2007_trainval+voc_2012_trainval文件夹:
tar xvf voc_0712_80k-110k.tgz至此,tf-faster-rcnn/data/文件夹下的所需的文件都已经准备齐全了!(蓝色的是本来有的、红色是后期下载准备的、橘色的就是创建的软连接)
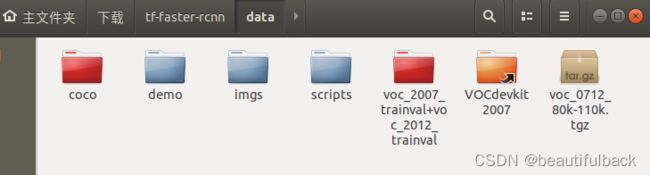
7. 创建一个文件夹和一个软链接以使用预训练模型
在tf-faster-rcnn根目录创建一个output文件夹并且在其中存放预训练模型的软链接,使用软连接来使用预训练模型,output文件夹中会在每次训练后存放训练好的模型,步骤:
NET=res101
TRAIN_IMDB=voc_2007_trainval+voc_2012_trainval
mkdir -p output/${NET}/${TRAIN_IMDB}
cd output/${NET}/${TRAIN_IMDB}
ln -s ../../../data/voc_2007_trainval+voc_2012_trainval ./default
cd ../../.. # 这里介绍后是在tf-faster-rcnn/文件加下
8. 测试demo(这里我的电脑用的GPU_ID= 0)
GPU_ID=0
CUDA_VISIBLE_DEVICES=${GPU_ID} ./tools/demo.py
运行过程:
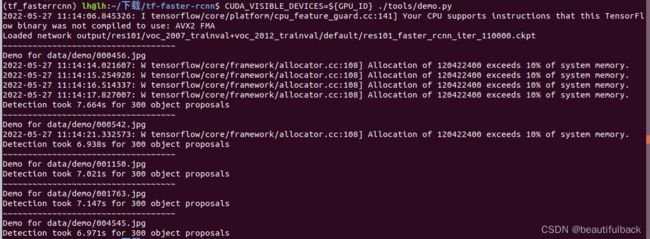
测试的图片在/tf-faster-rcnn/data/demo文件里
有的博客写的是 GPU_ID = 01,但是我用这个会出现下面的错误,于是改为GPU_ID = 0,如果在测试过程中也有这样的错误(no CUDA-capable device is detected),你可以改改!
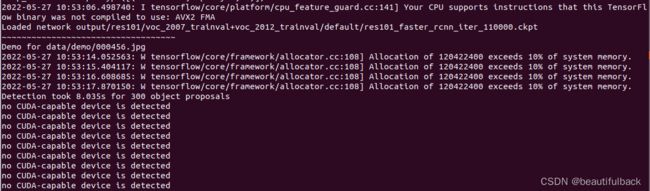
重点来了!忙了这么就终于可以看看效果了(会连续弹出好多张),其中一张结果如图:
demo.py效果图三、使用训练好的faster模型对数据进行测试
在tf-faster-rcnn/文件目录下运行:
GPU_ID=0
./experiments/scripts/test_faster_rcnn.sh $GPU_ID pascal_voc_0712 res101这里有点地方需要改:首先把 tf-faster-rcnn/lib/datasets/voc_eval.py的第121行的
with open(cachefile,'w') as f
修改为:
with open(cachefile,'wb') as f同时还要把第105行的
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
修改为:
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile.split("/")[-1].split(".")[0])过程中可能会出现问题,在上面第一大点的第5小点有相关解决办法(如果之前你已经安装了相应的包,应该在运行过程中就没有问题了),过程如图:
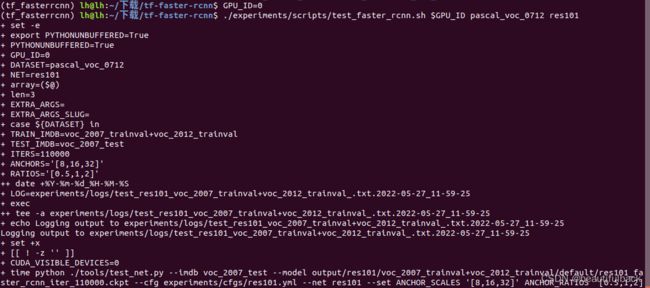
未完全测试完,待续.................
============================================================================
会在output文件夹下建立一个路径为:
/output/res101/voc_2007_test/default/res101_faster_rcnn_iter_110000/
的文件夹,res101代表网络名称,voc_2007_test代表数据集,与训练不同,该文件夹下不再是模型文件,tf-faster-rcnn平台搭建完成!
四、train: