Task06 BERT应用到下游任务、训练和优化
文章目录
- 1 BERT-based Models
-
- 1.1 BertForPreTraining
- 1.2 BertForSeqence Classification
- 1.3 BertFor MultipleChoice
- 1.4 Bert For Token Classification
- 1.5 BertForQuestionAnswering
- 2 BERT训练和优化
-
- 2.1 Pre - Training
- 2.2 Fine-Tuning
-
- 2.2.1 AdamW
- 2.2.2 Warmup
- 总结
- 参考
1 BERT-based Models
1.1 BertForPreTraining
预训练的两个任务
Masked Language Model(MLM)
Next Sentence Prediction (NSP) ---->旨在训练模型理解预测句子间的关系
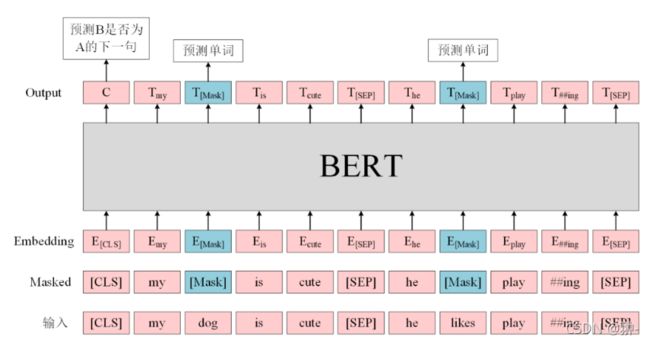
@add_start_docstrings(
"""Bert Model with a `language modeling` head on top for CLM fine-tuning. """, BERT_START_DOCSTRING
)
class BertLMHeadModel(BertPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
def __init__(self, config):
super().__init__(config)
if not config.is_decoder:
logger.warning("If you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`")
self.bert = BertModel(config, add_pooling_layer=False)
self.cls = BertOnlyMLMHead(config)
self.init_weights()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
labels=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
use_cache (:obj:`bool`, `optional`):
If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
decoding (see :obj:`past_key_values`).
Returns:
Example::
from transformers import BertTokenizer, BertLMHeadModel, BertConfig
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
config = BertConfig.from_pretrained("bert-base-cased")
config.is_decoder = True
model = BertLMHeadModel.from_pretrained('bert-base-cased', config=config)
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
prediction_logits = outputs.logits
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
use_cache = False
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
lm_loss = None
if labels is not None:
# we are doing next-token prediction; shift prediction scores and input ids by one
shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = CrossEntropyLoss()
lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((lm_loss,) + output) if lm_loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=lm_loss,
logits=prediction_scores,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past=None, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_shape)
# cut decoder_input_ids if past is used
if past is not None:
input_ids = input_ids[:, -1:]
return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past}
def _reorder_cache(self, past, beam_idx):
reordered_past = ()
for layer_past in past:
reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
return reordered_past
from transformers import BertTokenizer, BertLMHeadModel, BertConfig
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
config = BertConfig.from_pretrained("bert-base-uncased")
config.is_decoder = True
model = BertLMHeadModel.from_pretrained('bert-base-uncased', config=config)
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
prediction_logits = outputs.logits
Fine-tune 模型 分类任务
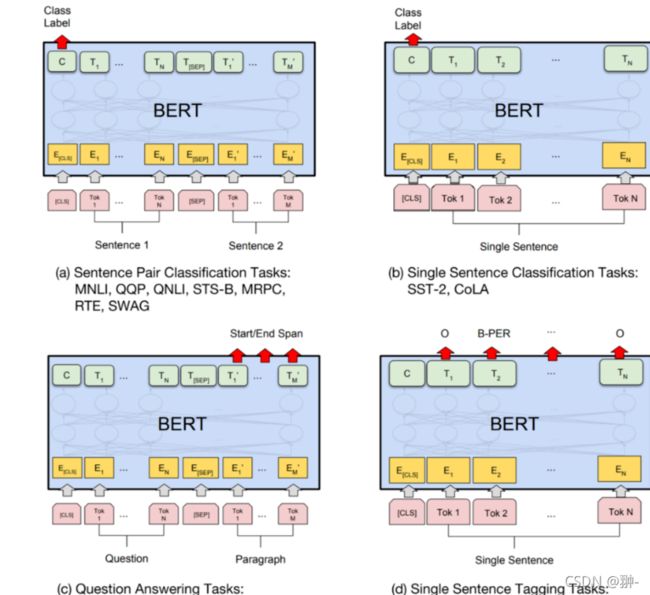
1.2 BertForSeqence Classification
可以用于句子分类 ( 也可以是回归) 任务
- 句子分类作为输入 输出 ----> 单个分类标签
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
# ...
- 如果初始化的num_labels = 1 那么默认为回归任务 ,使用MSELoss
- 否则认为是分类任务
1.3 BertFor MultipleChoice
用于多项选择 这模型 如 RocStories/SWAG任务
- 多项选择任务 : 输入<------ 一组分词输入的句子
输出 ------> 为选择某一句子的单个标签
1.4 Bert For Token Classification
用于序列标注 (词分类) 如NER任务
- 输入 <-----------为单个句子文本
- 输出-------------> 每个token对应的类别标签
1.5 BertForQuestionAnswering
用于解决问答任务
- 输入 <----------- 问题组成的句子对
- 输出 -----------> 为起始位置和结束位置用于标出回答中的具体文本
@add_start_docstrings(
"""
Bert Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
output) e.g. for GLUE tasks.
""",
BERT_START_DOCSTRING,
)
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss. Indices should be in :obj:`[0, ...,
config.num_labels - 1]`. If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
2 BERT训练和优化
2.1 Pre - Training
所有实现的PLM的word embedding和masked language model 的预测权重在初始化过程中都是共享的
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):
# ...
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the :obj:`torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning
the weights instead.
"""
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None and self.config.tie_word_embeddings:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if self.config.is_encoder_decoder and self.config.tie_encoder_decoder:
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
# ...
2.2 Fine-Tuning
2.2.1 AdamW
用于修复Adam的权重衰减错误的新方法

2.2.2 Warmup
在训练初期使用较小的学习率 在一定步数 内提高到正常大小
TYPE_TO_SCHEDULER_FUNCTION = {
SchedulerType.LINEAR: get_linear_schedule_with_warmup,
SchedulerType.COSINE: get_cosine_schedule_with_warmup,
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,
SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
SchedulerType.CONSTANT: get_constant_schedule,
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
}
总结
感觉有点懵 [捂脸] 一圈下来知道很复杂 可以做问答 句子里的词分类
参考
Datawhale基于transformers的自然语言处理(NLP入门)