【Hadoop配置】用最短的时间配置伪分布式Hadoop(个人亲身经历)
【Hadoop配置】用最短的时间配置伪分布式Hadoop(个人亲身经历)
目录
-
- 【Hadoop配置】用最短的时间配置伪分布式Hadoop(个人亲身经历)
-
- 一、概述
- 二、前言
- 三、详细过程
-
- (一)前期的尝试
- (二)从头配置Hadoop
-
- 1.下载hadoop-2.7.3.tar.gz和jdk-8u271-linux-x64.tar.gz
- 2.准备网络
- 3.修改主机名和hosts文件等
- 4.添加hadoop用户
- 5.hadoop用户授权
- 6.关闭防火墙
- 7.建立安装目录(文件夹)
- 8.上传hadoop-2.7.3.tar.gz和jdk-8u271-linux-x64.tar.gz到虚拟机
- 9.安装java
- 10.配置java环境变量
- 11.安装hadoop
- 12.配置hadoop环境变量
- 12.配置ssh免密登录
- 13.配置相关文件完成伪分布
-
- (1)hadoop-env.sh
- (2)core-site.xml
- (3)hdfs-site.xml
- (4)mapred-site.xml
- (5)yarn-site.xml
- (6)slaves
- (7)进行格式化
- 14.启动hadoop集群
- 四、上传文件测试
- 五、结语
一、概述
2022.10.26晚进行实验时,需要使用到hdfs上传文件,但是半年没用过虚拟机了,忘记了hadoop的安装位置,导致无法启动节点,于是将虚拟机上的原hadoop文件夹删除,将hadoop用户删除,重新配置了hadoop,为帮助遇到类似问题的小伙伴,同时也做一个记录以备我需要时查阅,特此记录全过程如下。
二、前言
注
1.本篇内容涉及到使用软件VMware® Workstation 16 Pro,但具体的安装激活方法不在讨论范围内,如有需要请评论留言,我会考虑再出一篇文章。
2.vi的文件操作本文就不过多涉及了,这里简要提一下:
I键或INSERT键—进入编辑模式
ESC键—进入命令模式
:wq—保存退出
q!—不保存退出
软件环境
虚拟机软件:VMware® Workstation 16 Pro
虚拟机名称:CentOS 7 64位
镜像文件名称:CentOS-7-x86_64-DVD-2009.iso
分配运行内存:4GB
处理器:1个2核,共2核
分配硬盘内存:20GB
网络适配器:桥接模式(重要)
本次Hadoop配置涉及到动态ip识别,非静态ip,所以虚拟机的网络适配器不能是NAT模式或其他模式,必须修改为桥接模式
三、详细过程
(一)前期的尝试
印象中记得是配置好过一次hadoop的,但是忘记了安装路径,随便做了下尝试,但结果不尽人意
cd /usr/local/hadoop
也有可能路径是对的,但是我的某个地方的配置是错的
为了不耽误实验进度,决定暴力删除文件和hadoop用户,重头再来
sudo rm -rf /usr/local/hadoop
userdel -r hadoop
这种暴力删除的行为存在一定风险,没有一定的把握尽量不要尝试
(二)从头配置Hadoop
1.下载hadoop-2.7.3.tar.gz和jdk-8u271-linux-x64.tar.gz
为了帮助大家有一个方便的免费途径下载这些资源,我从官网下载好文件,整理后上传到我自己的百度网盘里了,大家有需要的可以点击链接下载
https://pan.baidu.com/s/15GT-kCRHsLmqs4D19u_D4w?pwd=hls4
2.准备网络
使用root用户登录系统
su root
回到家目录
cd ~
检查ens33文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33

☝ens33截图
需要检查的地方如下,如果不对应需要改成这样:
BOOTPROTO=dchp
ONBOOT=yes
测试ping
ping www.4399.com #别的当然也可以
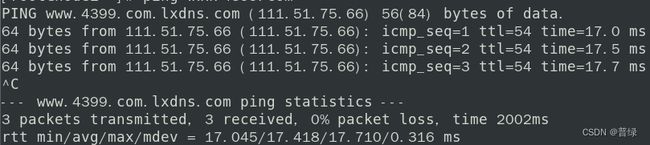
☝确保网络是正常的
3.修改主机名和hosts文件等
为方便后续操作,先将主机名修改为master
hostnamectl set-hostname master
reboot #重启系统
重启后再次进入root用户,查看主机名是否修改成功
hostname
![]()
☝检查用户名是不是master
查看/etc/hostname文件
cd ~ #回到家目录
vi /etc/hostname
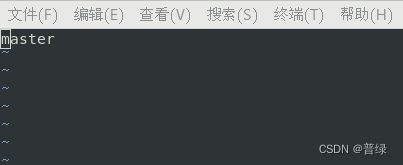
☝检查是不是master,不是的话需要修改
查看/etc/hosts文件
vi /etc/hosts
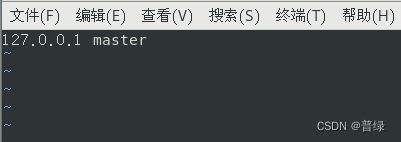
☝有其他的127.0.0.1开头的地方需要全部删除,只能留一个,后面的主机名一般是localhost.localdomain,需要改为master,和hostname中主机名一样
127.0.0.1是本地机回送地址,伪分布式配置只需要写这一个hosts就可以了,不需要写别的
4.添加hadoop用户
adduser hadoop #添加用户
passwd hadoop #设置密码,一般也是hadoop

☝不用管提示的“无效的密码”,反复输入密码后回车即可(注:密码是隐藏的,不放心的话先多按几次backspace删除,然后再输入密码)
5.hadoop用户授权
chmod -v u+w /etc/sudoers #添加sudoers文件可写权限
提示信息:mode of “/etc/sudoers” changed from 0440 (r–r-----) to 0640 (rw-r-----)
sudo vim /etc/sudoers #使用vim编辑器打开sudoers文件

☝找到Allow root to run any commands anywhere,在下面输入如图所示的代码
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
chmod -v u-w /etc/sudoers #收回sudoers文件可写权限
提示信息:mode of “/etc/sudoers” changed from 0640 (rw-r-----) to 0440 (r–r-----)
6.关闭防火墙
systemctl stop firewalld #关闭防火墙
systemctl status firewalld #查看防火墙状态
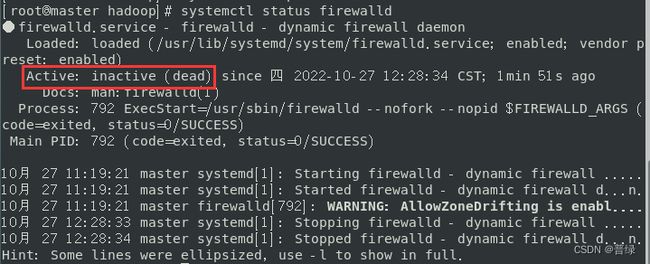
☝查看Active显示为dead,而不是running
7.建立安装目录(文件夹)
su hadoop #登入到hadoop用户
cd ~ #回到家目录
pwd #查看当前所在目录
提示信息:/home/hadoop
mkdir gzpackage #建立gz压缩包目录,名称为gzpackage
mkdir softwares #建立软件安装目录,名称为softwares
ls #查看所建的目录
![]()
☝显示为gzpackage和softwares
8.上传hadoop-2.7.3.tar.gz和jdk-8u271-linux-x64.tar.gz到虚拟机
这里我用到finalshell,用于稳定上传文件,如果直接拖动文件到虚拟机上传可能导致压缩包损坏,导致解压缩时产生如下报错
tar: 归档文件中异常的 EOF
tar: Error is not recoverable: exiting now
注:其他的shell软件如Xshell也是可以的,有关shell的用法这里也不赘述了,有需要的话可以留言,我会单独出一篇文章。

☝需要注意的是,由于权限不够,所以登录进shell之后一般是不能直接打开hadoop的家目录的,所以这里我先把两个压缩包放在我的默认用户的家目录的桌面里
注:为方便操作,后续代码输入统一用shell来完成
sudo mv /home/20201304017/桌面/jdk-8u271-linux-x64.tar.gz /home/hadoop/gzpackage
sudo mv /home/20201304017/桌面/hadoop-2.7.3.tar.gz /home/hadoop/gzpackage
#移动文件到hadoop用户下的gzpackage目录
9.安装java
cd gzpackage #进入安装包目录
tar -zxvf jdk-8u271-linux-x64.tar.gz -C ~/softwares/ #解压文件并转移到软件目录
cd ~/softwares #进入软件目录
ls #查看目录

☝需要显示jdk1.8.0_271
ln -s jdk1.8.0_271 jdk 创建快捷方式
ls #查看目录

☝需要额外显示jdk
10.配置java环境变量
cd ~ #回到家目录
sudo vi ~/.bashrc #进入bashrc文件
在文件的最下面加入如下代码
#JAVA_HOME
export JAVA_HOME=~/softwares/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc #使文件生效
java -version #检查是否安装成功

☝如图显示则为安装成功
11.安装hadoop
cd gzpackage #进入安装包目录
tar -zxvf hadoop-2.7.3.tar.gz -C ~/softwares/ #解压文件并转移到软件目录
cd ~/softwares #进入软件目录
ls #查看目录

☝需要显示hadoop-2.7.3
ln -s hadoop-2.7.3 hadoop 创建快捷方式
ls #查看目录

☝需要额外显示hadoop
12.配置hadoop环境变量
cd ~ #回到家目录
sudo vi ~/.bashrc #进入bashrc文件
在文件的最下面加入如下代码
#HADOOP_HOME
export HADOOP_HOME=~/softwares/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc #使文件生效
hadoop version #检查是否安装成功
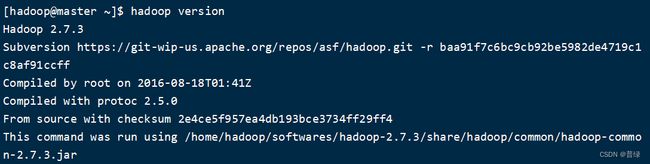
☝如图显示则为安装成功
12.配置ssh免密登录
ssh-keygen -t rsa #设置密钥
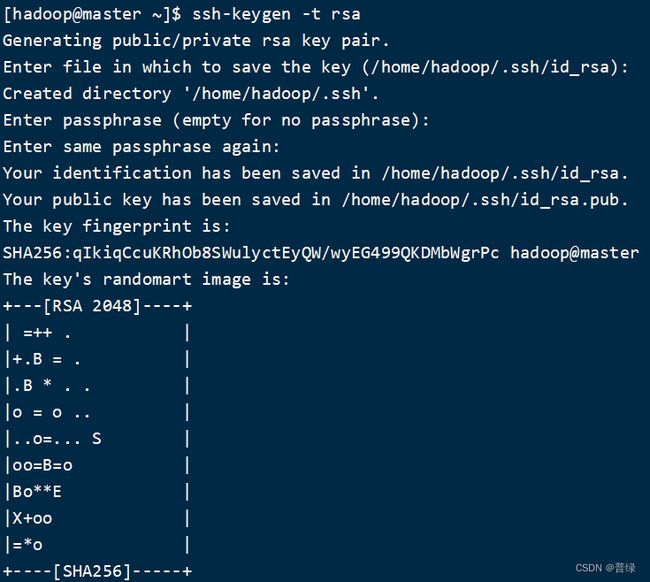
☝输完代码后按三次回车,出现如图所示结果即可
ssh-copy-id master #设置公钥
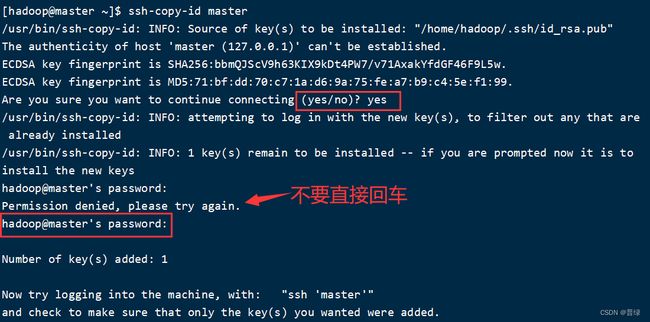
☝输完代码后等待提示,输入yes,此时可能需要输入密码,注意输入的是hadoop用户密码,不能直接回车,否则就会有try again的提示,输入完毕后如图所示结果即可
ls ~/.ssh/ #检查认证文件

☝出现如图所示结果即可
cat ~/.ssh/authorized_keys #查看认证文件
cat ~/.ssh/id_rsa.pub #查看公钥文件

☝核对两次打印结果,发现是一致的
ssh master #检查是否设置成功
exit #退出登录
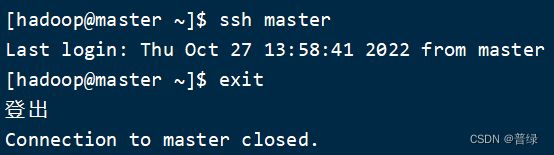
☝能正常登录登出即为配置成功
注:如在配置ssh过程中出现以下报错信息,则是网络配置有问题,需要检查ens33、hosts、hostname等文件
ssh: connect to host hadoop port 22: Connection timed out
13.配置相关文件完成伪分布
cd ~/softwares/hadoop-2.7.3/etc/hadoop #进入hadoop配置目录
(1)hadoop-env.sh
vi hadoop-env.sh #进入vi编辑器
找到export JAVA_HOME,修改路径如下:
export JAVA_HOME=/home/hadoop/softwares/jdk
(2)core-site.xml
vi core-site.xml #进入vi编辑器
找到configuration和/configuration,修改为下述内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/softwares/hadoop/tmp</value>
</property>
</configuration>
(3)hdfs-site.xml
vi hdfs-site.xml #进入vi编辑器
找到configuration和/configuration,修改为下述内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(4)mapred-site.xml
cp mapred-site.xml.template mapred-site.xml #复制出mapred-site.xml
vi mapred-site.xml #进入vi编辑器
找到configuration和/configuration,修改为下述内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)yarn-site.xml
vi yarn-site.xml #进入vi编辑器
找到configuration和/configuration,修改为下述内容
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)slaves
vi slaves #进入vi编辑器
将localhost改为master
(7)进行格式化
hdfs namenode -format

☝格式化完成后看到Exiting with status 0即为配置成功
注:只能格式化一次,如果第一次格式化后没有出现Exiting with status 0,则需要重头开始配置
14.启动hadoop集群
启动hadoop集群,如果出现需要输入yes的情况,输入即可
start-all.sh
注:该命令再后续版本中已经被弃用,也可以使用 start-dfs.sh 和 start-yarn.sh命令
jps #查看集群进程

☝如果这里显示了六个进程,恭喜你已经成功配置好伪分布式的Hadoop
四、上传文件测试
现在已经配置好hadoop了,现在上传一个文件来测试一下是否能正常使用
cd ~ #回到家目录
vi ./test.txt #生成新文件并打开
在文件内写入测试语句
This is a test for hadoop checking.
hdfs dfs -mkdir /input #在hdfs中创建input文件夹
hdfs dfs -put ./test.txt /input #上传测试文件到input文件夹
hdfs dfs -cat /input/test.txt #打印测试文件内容

☝当你看到这段话的时候,恭喜你,hdfs功能正常,你的配置没有问题!
五、结语
本篇文章到这里就结束了,如果你在配置过程中发现有和我不一样的地方,欢迎评论提问,同时后续我会根据留言考虑更新虚拟机的使用方法、shell的操作方法、Hadoop的全分布式配置等文章,有需要的话欢迎留言~
普绿
2022.10.27