【Hadoop配置】用最短的时间配置伪分布式Hbase(亲身经历)
【Hadoop配置】用最短的时间配置伪分布式Hbase(亲身经历)
目录
- 【Hadoop配置】用最短的时间配置伪分布式Hbase(亲身经历)
- 一、鸣谢
- 二、前言
- 三、从头配置Hbase
-
- (一)下载hbase-1.1.5-bin.tar.gz
- (二)上传hbase-1.1.5-bin.tar.gz到虚拟机
- (三)安装hbase
- (四)配置hadoop环境变量
- (五)配置相关文件完成伪分布
-
- 1.hbase-env.sh
- 2.hbase-site.xml
- (六)启动Hadoop集群
- (七)启动HBase
- 四、创建、操作表进行测试
-
- (一)创建表
- (二)编辑数据
- 五、关闭HBase和Hadoop集群
- 六、结语
一、鸣谢
大家好,我是文章【Hadoop配置】用最短的时间配置伪分布式Hadoop(个人亲身经历)的作者普绿,没有想到我小小的一篇文章居然入选了全站综合热榜(截止我这篇文章的时候热度为4906,排名为49)

☝看见那个关注按钮了吗,快按下去
非常感谢大家的支持,也很感谢关注我的255位粉丝,你们的支持是我持续更新的最大动力,我会坚持下去,为大家带来更多、更简单易学的一系列教程,谢谢大家!
那么话不多说,马上开始今天的内容,用最短的时间配置伪分布式Hbase
二、前言
如果你是新关注我的小伙伴,想要学习这一篇内容的话,那我强烈建议你先去看我的上一篇文章【Hadoop配置】用最短的时间配置伪分布式Hadoop(个人亲身经历),里面有详细的Hadoop伪分布式配置方法,而且有我所使用的虚拟机系统说明以及其他重要说明;如果你已经看过了我的上一篇文章,那就跟着我一起开始Hbase的配置吧。
三、从头配置Hbase
(一)下载hbase-1.1.5-bin.tar.gz
和hadoop安装相关文件同样的,为了帮助大家有一个方便的免费途径下载这些资源,我从官网下载好文件,整理后上传到我自己的百度网盘里了,大家有需要的可以点击链接下载:普绿整理-hbase.zip
(二)上传hbase-1.1.5-bin.tar.gz到虚拟机
同样的,这里我用到finalshell,用于稳定上传文件,如果直接拖动文件到虚拟机上传可能导致压缩包损坏,导致解压缩时产生如下报错
tar: 归档文件中异常的 EOF
tar: Error is not recoverable: exiting now
shell的用法这里不赘述了,有需要的话可以留言,我会单独出一篇文章。
☝上传页面,速度是很快的,不用担心
由于权限不够,所以登录进shell之后一般是不能直接打开hadoop的家目录的,所以这里我先把压缩包放在我的默认用户的家目录的桌面里
su hadoop #进入hadoop账户
sudo mv /home/20201304017/桌面/hbase-1.1.5-bin.tar.gz /home/hadoop/gzpackage
#移动文件到hadoop用户下的gzpackage目录
cd /home/hadoop/gzpackage/ #进入gzpackage目录
ls #检查目录
 ☝检查是否有压缩文件,确保我们前期的准备工作就绪,后面就可以很快完成了~
☝检查是否有压缩文件,确保我们前期的准备工作就绪,后面就可以很快完成了~
(三)安装hbase
tar -zxvf hbase-1.1.5-bin.tar.gz -C ~/softwares/ #解压文件并转移到软件目录
cd ~/softwares #进入软件目录
sudo mv hbase-1.1.5 hbase #重命名,便于后续操作
ls #查看目录

☝检查是否显示有hbase文件夹,以确保软件安装成功
(四)配置hadoop环境变量
是的你没有看错,这里就是配置hadoop的环境变量,hbase虽然作为一个独立的软件存在,但是需要依赖hdfs完成所有的工作,这也是为什么本文的标题标签为【hadoop配置】
hbase的全称为hadoop database,就是hadoop数据库的意思,所以依赖于hdfs也不奇怪了
cd ~ #回到家目录
sudo vim ~/.bashrc #进入bashrc文件
将如下代码:
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改为:
export HBASE_HOME=~/softwares/hbase
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
保存后输入:
source ~/.bashrc #使文件生效
cd /home/hadoop/softwares/ #进入softwares目录
sudo chown -R hadoop ./hbase #添加hadoop用户访问hbase目录的权限
cd /home/hadoop/softwares/hbase/bin #进入hbase的安装启动目录(不等于安装目录)
hbase version #检查是否安装成功

☝如果显示有HBase版本号1.1.5,则说明环境变量配置成功
注:如果提示如下报错信息,则需要检查环境变量是否配置有误
错误: 找不到或无法加载主类 org.apache.hadoop.hbase.util.VersionInfo
(五)配置相关文件完成伪分布
1.hbase-env.sh
cd ~/softwares/hbase/conf #进入hbase配置目录
vi hbase-env.sh #进入vi编辑器
将如下代码:
# export JAVA_HOME=/usr/java/jdk1.6.0/
修改为:
export JAVA_HOME=~/softwares/jdk
export HBASE_CLASSPATH=~/softwares/hadoop/conf
export HBASE_MANAGES_ZK=true
2.hbase-site.xml
vi hbase-site.xml #进入vi编辑器
找到configuration和/configuration,修改为下述内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
到这里你已经完成了所有的配置,相较hadoop的配置是很简单的
(六)启动Hadoop集群
ssh master #免密登入到hadoop
cd ~/softwares/hadoop #进入hadoop安装目录
./sbin/start-dfs.sh #启动hadoop集群
jps #查看集群进程

☝需要显示不包括jps在内的三个进程,确保hadoop集群正常启动
(七)启动HBase
cd ~/softwares/hbase #进入hbase安装目录
start-hbase.sh #启动hbase
 ☝按照提示输入yes,连接到hbase
☝按照提示输入yes,连接到hbase
jps #查看集群进程

☝如果发现多了“H”开头的这三个进程,恭喜你,你的Hbase已正常运行
bin/hbase shell #进入hbase shell模式,便于后续操纵数据库
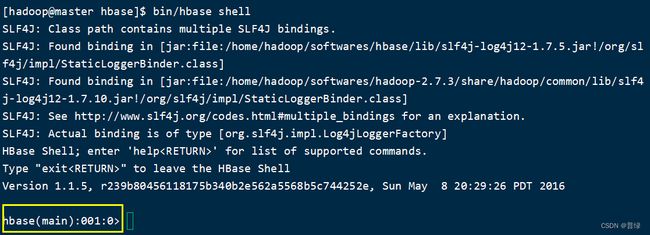
☝有的时候可能等很久都弹不出来这串代码,那可能是你的Hadoop或者HBase配置文件有误,需要仔细检查一下
四、创建、操作表进行测试
(一)创建表
create 'Testname','Testno','Testsex','Testage','Testarea','Testid'

☝HBase会根据第一行生成一张空白表,用行键作为表名
list #查看当前创建的表
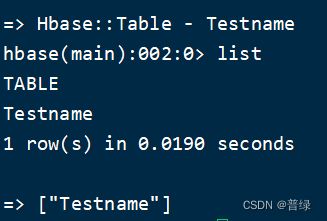
☝可以看到当前创建了一个名为“Testname”的表
describe 'Testname' #查看表的详细信息

☝可以看到表中每行的详细设置,这里简单做一下解释
NAME:表名
BLOOMFILTER:列族配置属性,分为ROW扫描和ROWCOL扫描
VERSIONS:当前版本,文件更新时版本数增加
IN_MOMERY:载入缓存,启动时可保证读取行时被缓存读到
KEEP_DELETED_CELLS:内存保留,启动时删除行后,数据仍然在内存中
DATA_BLOCK_ENCODING:压缩编码格式
TTL:过期数据删除时间,设置后版本过期数据将在特定时间被删除
COMPRESSION:压缩算法
MIN_VERSIONS:最小版本号
BLOCKCACHE:块缓存机制,开启后提升数据库性能
BLOCKSIZE:数据块大小,默认为64K
REPLICATION_SCOPE:跨集群复制范围
(二)编辑数据
put 'Testname','Zhangsan','Testno','123' #添加一个单元格数据
注:put只支持添加一个单元格的数据,如果一次想要添加多个数据,则会报错如下
ERROR: wrong number of arguments (12 for 6)
Here is some help for this command:
Put a cell ‘value’ at specified table/row/column and optionally
timestamp coordinates. To put a cell value into table ‘ns1:t1’ or ‘t1’
at row ‘r1’ under column ‘c1’ marked with the time ‘ts1’, do:
hbase> put ‘ns1:t1’, ‘r1’, ‘c1’, ‘value’
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, ts1
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, {ATTRIBUTES=>{‘mykey’=>‘myvalue’}}
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, ts1, {ATTRIBUTES=>{‘mykey’=>‘myvalue’}}
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, ts1, {VISIBILITY=>‘PRIVATE|SECRET’}
The same commands also can be run on a table reference. Suppose you had a referencet to table ‘t1’, the corresponding command would be:
hbase> t.put ‘r1’, ‘c1’, ‘value’, ts1, {ATTRIBUTES=>{‘mykey’=>‘myvalue’}}
put 'Testname','Zhangsan','Testsex','male'
put 'Testname','Zhangsan','Testage','30'
put 'Testname','Zhangsan','Testarea','Beijing'
put 'Testname','Zhangsan','Testid','ZS123'
put 'Testname','Xiaoming','Testno','999'
put 'Testname','Xiaoming','Testsex','male'
put 'Testname','Xiaoming','Testage','15'
put 'Testname','Xiaoming','Testarea','Shanghai'
put 'Testname','Xiaoming','Testid','XM999'
#添加多个单元格数据
get 'Testname','Xiaoming' #查看'Testname'为'Xiaoming'的行数据

☝读取结果
scan 'Testname' #扫描查看'Testname'表的所有行数据

☝以列的方式全部读取数据,共两行
delete 'Testname','Zhangsan','Testsex' #删除'Testname'表中'Testsex'列的数据
deleteall 'Testname','Xiaoming' #删除'Testname'表中'Xiaoming'整行的数据

☝删除数据后结果
disable 'Testname' #让'Testname'表不可用
drop 'Testname' #删除'Testname'表

☝再次查看已创建的表,发现表已删除
如果上述的操作你和我一样顺利进行下来,那么就说明你的hbase功能正常,恭喜!
五、关闭HBase和Hadoop集群
exit #退出hbase shell模式
cd ~/softwares/hbase #进入hbase安装目录
bin/stop-hbase.sh #关闭hbase
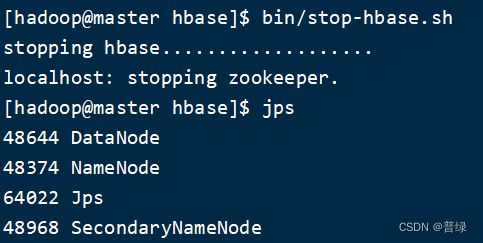
☝HBase相关进程已经被关闭
cd ~/softwares/hadoop #进入hadoop安装目录
./sbin/stop-dfs.sh #关闭hadoop集群
exit #登出master账户

☝Hadoop集群服务也关闭成功,这下你可以放心关闭你的虚拟机了
六、结语
本篇文章到这里就结束了,如果你在配置过程中发现有和我不一样的地方,欢迎评论提问,后续我将持续更新计算机网络相关的实验操作和NoSQL数据库配置等文章,喜欢的话就持续关注吧
普绿
2022.10.30