数据预处理的几种方法
目录
1、缺失值
2、异常值
3、数值型处理
3.1 无量纲化处理
3.2 数值型转换成类别
3.3 数值的二值化
4、类别型
4.1 独热编码(one-hot encoding)
4.2哑编码(dummy encoding)
4.3 Histogram映射
5、时间型
6、文本型
6.1 词袋
6.2 把词袋中的词扩充到n-gram
6.3 使用TF-IDF特征
——————————————————————————————
1、缺失值
- 直接删除,可能数据损坏
- 替换缺失值(平均数、中位数——连续,众数——离散,一定范围的随机值)
- 其他特征预测:
根据前后数据补全,如时间序列值,前后的均值+扰动
根据相似数据补全,如KNN算法
根据其他特征建立模型进行预测
- 作为第三特征,如人可以分成好人,坏人,未知
- EM方法最大似然估计缺失值
- 有些算法如随机森林、GBDT(梯度提升树)等,可以自动处理缺失值:https://blog.csdn.net/qq_19446965/article/details/81637199
由于IRIS数据集没有缺失值,故对数据集新增一个样本,4个特征均赋值为NaN,表示数据缺失。
使用preproccessing库的Imputer类对数据进行缺失值计算的代码如下:
from numpy import vstack, array, nan
from sklearn.preprocessing import Imputer
#缺失值计算,返回值为计算缺失值后的数据
#参数missing_value为缺失值的表示形式,默认为NaN
#参数strategy为缺失值填充方式,默认为mean(均值)
Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data)))2、异常值
2.1 处理方法
异常值对模型的影响极大。
- 按照缺失值处理
- 直接删除(异常值少时)
- 用对异常值不敏感的模型或者方法,如随机森林。
2.2 异常值检测方法
经验统计分析,如知道长度的范围,超出此范围为异常值
- 基于标准差的
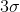 原则
原则 - 基于聚类的方法
- 基于距离的方法,KNN方法,某点周围点平均距离远大于其他点
- 基于密度的方法,某点的近邻密度远低于其他点
3、数值型处理
3.1 无量纲化处理
3.1.1 为什么要无量纲化?
- 不同量纲的数据统一为相同无量纲处理
- 提高算法精度,对基于距离的算法有效
- 梯度下降法能很快收敛
3.1.2 处理方法:
(1)标准化(正态分布),
标准化即为概率论与数理统计中常见的Z-score标准化。在特征值的均值(mean)和标准差(standard deviation)的基础上计算得出。标准化是依照特征矩阵的列处理数据,其通过求Z-score的方法,将样本的特征值转换到同一量纲下。
![]()
两种方法实现:
- 使用sklearn.preprocessing.StandardScaler类对数据进行标准化,优点在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据
- 使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(x_train) #标准化,将特征值映射到负无穷到正无穷
x_trainScaler = scaler.transform(x_train)
x_testScaler = scaler.transform(x_test)应用场景:数据存在较多异常值或者噪声时候
(2)区间缩放(Rescaling)
常见的区间缩放为 Min-Max Rescaling,对数据进行线性变换,将特征值映射将特征值映射到区间[0,1]中。
![]()
使用preproccessing库的MinMaxScaler类对数据进行区间缩放:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler().fit(x_train) #线性变换,将特征值映射到区间[0,1]中
x_trainScaler = scaler.transform(x_train)
x_testScaler = scaler.transform(x_test)(3)归一化(Normalization)
归一化是将每个样本缩放为单位范数(每个样本的范数为1)。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。 L2范数下的归一化为

Sklearn中的preproccessing库的Normalizer实现代码如下
from sklearn.preprocessing import Normalizer
scaler = Normalizer().fit(x_train)#归一化
x_trainScaler = scaler.transform(x_train)
x_testScaler = scaler.transform(x_test) 应用场景:
- 数据平稳,不受极值的影响
- 输出范围有要求时候
3.2 数值型转换成类别
例如衣服的尺码,M、S、L、XL、XXL...
3.3 数值的二值化
![]()
如,某项体检指标为0.44,小于0.44为健康,大于0.44为患病
Sklearn中的preproccessing库的Binarizer实现代码如下
from sklearn.preprocessing import Binarizer
scaler = Binarizer(threshold=3).fit(x_train) #threshold为设定的阀值
x_trainScaler = scaler.transform(x_train)
x_testScaler = scaler.transform(x_test) 4、类别型
4.1 独热编码(one-hot encoding)
4.1.1 基本概念:
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就需要5位来表示(1-5).
为了进行算法训练,需要
4.1.2 onehot的优点:
- 能够处理非连续型数值特征;
- 在一定程度上扩充了特征(例如:性别本身是一个特征,经过one hot编码以后,就变成了男或女两个特征;
- 将离散特征的取值扩展到了欧式空间(离散特征的某个取值就对应欧式空间的某个点,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。);
- 将离散型特征使用one-hot编码,可以让特征之间的距离计算更加合理,相当于做了归一化处理;
4.2哑编码(dummy encoding)
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了(0-4)。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,只需要4位就够了.
使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
from sklearn.preprocessing import OneHotEncoder
#哑编码,对IRIS数据集的目标值,返回值为哑编码后的数据
OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))python常用库
对离散型数据进行onehot编码处理,常见的处理方法有两种:
- pandas:使用pandas库中的函数pd.dummies()或pd.factorize()进行独热编码;
- sklearn:使用sklearn库中的OneHotEncoder()方法进行独热编码。
总结:
| 学历 | 标签编码 | 独热编码 | 亚热编码 |
| 博士 | 0 | 10000 | 0000 |
| 硕士 | 1 | 01000 | 1000 |
| 大学 | 2 | 00100 | 0100 |
| 中学 | 3 | 00010 | 0010 |
| 小学 | 4 | 00001 | 0001 |
注意:当类别相当多时,独热编码和亚热编码的维度会很高
4.3 Histogram映射
把每一列的特征拿出来,根据target内容做统计,把target中的每个内容对应的百分比填到对应的向量的位置。优点是把两个特征联系起来。
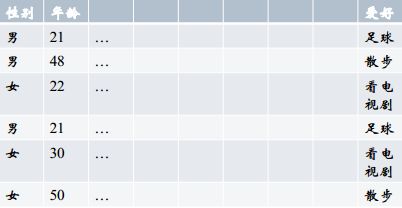
上表中,我们来统计“性别与爱好的关系”,性别有“男”、“女”,爱好有三种,表示成向量 [散步、足球、看电视剧],分别计算男性和女性中每个爱好的比例得到:男[1/3, 2/3, 0],女[0, 1/3, 2/3]。即反映了两个特征的关系。
python中没有包封装Histogram映射,需要手动
5、时间型
时间型特征的用处特别大,既可以看做连续值(持续时间、间隔时间),也可以看做离散值(星期几、几月份)。
数据挖掘中经常会用时间作为重要特征,比如电商可以分析节假日和购物的关系,一天中用户喜好的购物时间等。
5.1连续值
- 持续时间(单页浏览时长)
- 间隔时间(上次购买/点击离现在的时间)
5.2离散值
- 一天中哪个时间段(hour_0-23)
- 一周中星期几(week_monday...)
- 一年中哪个星期
- 一年中哪个季度
- 工作日/周末
6、文本型
6.1 词袋
文本数据预处理后,去掉停用词,剩下的词组成的list,在词库中的映射稀疏向量。Python中用CountVectorizer处理词袋.
以下是Gutenberg项目中Charles Dickens的《双城记》一书中的前几行文字。
“It was the best of times,
it was the worst of times,
it was the age of wisdom,
it was the age of foolishness,”
现在我们可以列出我们的模型词汇表中的所有单词:“it”、“was”、“the”、“best”、“of”、“times”、“worst”、“age”、“wisdom”、“foolishness”
这是一个由包括24个词组成的语料库中其中包含10个词汇。
作为二进制向量,如下所示:
"It was the best of times" = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
"it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
"it was the age of foolishness" = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]来自:https://www.jianshu.com/p/97862a7e3740
缺点:
- 不能表达相关或相似向量,不易求解文档相似性任务
- 当词库非常大时,存在维数灾难
6.2 把词袋中的词扩充到n-gram
n-gram代表n个词的组合。N-gram 算法采用固定长度为 N 的滑动窗口进行切分,目前常用 N-gram 模型是二元的 Bi-gram 和三元的 Tri-gram 模型。对两种模型的切分方法进行比较,比如 “北京 欢迎 你的 到来”,Bi-gram 切分就是 “北京欢迎 欢迎你的 你的到来”,Tri-gram 切分就是 “北京欢迎你的 欢迎你的到来”。
6.3 使用TF-IDF特征
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。自然语言处理中经常会用到。
- TF表示词频,IDF用来表示这个词的重要性,进而修正仅仅用词频表示的词特征值
- IDF反映了一个词在所有文档中出现的频率,如果一个词在很多文本中出现,那么他的IDF值很低,相反如果还很少在文本中出现,那么他的IDF就很高,例如专有名词“Deep Learning”,它的IDF就很低。


![]()
注意:IDF分母加1的目的是防止分分母为0,确定不为零可以不加1
——————————————————
参考:
https://blog.csdn.net/u010916338/article/details/81117744
https://blog.csdn.net/weixin_42782150/article/details/98478780
https://www.cnblogs.com/YSPXIZHEN/p/11439234.html
https://blog.csdn.net/qq_32023541/article/details/80089020
https://yq.aliyun.com/articles/224321