Python常见问题与解决方案
常见问题与解决方案
- 问题目录:
-
- 1. 时间变量的操作
- 2. 索引的重建与设置
- 3. 数据的排序
- 4. 数据类型的转化
- 5. 异常处理 -跳过异常继续执行
- 6. CSV 与 Excel的 批量转换
- 7. 文件操作
- 8. 数据读入与写入
- 9. 缺失值问题 np.nan,None,NaT
- 10. 使用Python输出回归表格
- 11. 特殊结构数据整理
- 12. 估计系数联合检验(Wald tests via statsmodels)
- 13. Python 与 STATA 时间日期转换问题
- 14. Python执行面板数据的Hausman检验
- 15. Fama Macbeth回归、滚动回归等等
- 16. 事件研究法 event study
- 生
- 创
- 创
- 如
- 注
- K
- 新
- U
- F
- 导
-
- 导出
- 导入
问题目录:
Python,作为当今主流的编程语言,受到全世界爱好者的追捧。如果你是一名科研小白,导师也许要求你使用它来完成一些任务。确实,入门容易,看看市面上种类繁多的教科书就行,但是,能够做到灵活运用又是谈何容易,Python语句编写的灵活性常常让很多的文科生想死的感觉都有。以下的内容就是鄙人在讲授相关课程时学生容易产生疑问的知识点,不是很全面,还在持续的更新之中… 。
1. 时间变量的操作
我们从在线API接口、外部Excel 都可以获得数据,读入到pandas之后,时间变量的操作对于后续的计算工作十分重要。
主要的时间模块有包括time、datetime和calendar。
在Python中表示时间的方式:
- 时间戳:10位整数位和若干小数位,例如 1551153156.6358607
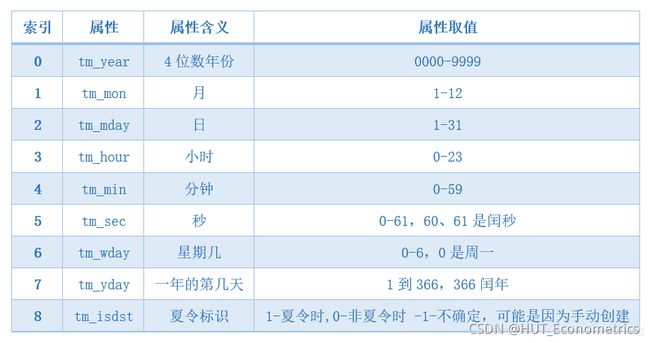
- 元组(struct_time): 含有9个元素的元组,例如 (tm_year=2011, tm_mon=9, tm_mday=28, tm_hour=10, tm_min=0, tm_sec=0, tm_wday=2, tm_yday=271, tm_isdst=-1)
- 格式化字符串: 格式化的时间字符串, 例如 ‘2019-02-26 12:45:46’
- time模块,以元组(struct_time)为核心实现时间戳和格式化时间字符串的相互转换。
- datetime模块,以datetime类实例对象为核心实现时间戳和格式化时间字符串的相互转换。
import time
#1.时间戳------->时间元组:
time1 = time.time() #显示的是时间戳
tuple = time.gmtime(time1) # UTC时间 时间元组
print(tuple)
#time.struct_time(tm_year=2021, tm_mon=11, tm_mday=3, tm_hour=16, tm_min=9, tm_sec=20, tm_wday=2, tm_yday=307, tm_isdst=0)
tuple1 = time.localtime(time1) # UTC + 8 时间 时间元组
print(tuple1)
#time.struct_time(tm_year=2021, tm_mon=11, tm_mday=4, tm_hour=0, tm_min=9, tm_sec=20, tm_wday=3, tm_yday=308, tm_isdst=0)
#2.时间元组-------->时间戳:
tuple2 = time.localtime()
time2 = time.mktime(tuple2)
print(time2)
#1635955760.0
#3.时间元组--------->字符串:
tuple = time.localtime()
strTime = time.strftime("%Y-%m-%d %H:%M:%S",tuple)
print(strTime)
#2021-11-04 00:09:20
strTime1 = time.strftime("%Y{y}%m{m}%d{d} %H{h}%M{m1}%S{s}",tuple).format(y="年",m="月",d="日",h="时",m1="分",s="秒") #'2021年11月02日 23时49分53秒'
print(strTime1)
#2021年11月04日 00时11分49秒
#4.字符串---------->时间元组:
tupleTime = time.strptime("2018年01月05日","%Y{y}%m{m}%d{d}".format(y="年",m = "月",d="日"))
print(tupleTime)
#time.struct_time(tm_year=2018, tm_mon=1, tm_mday=5, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=5, tm_isdst=-1)
- 时间元组(time.struct_time)
时间元组是一个比较重要的类型,通过时间元组我们可以获取,年月日时分秒,星期几,一年中的第几天等信息。
- 时间格式化
时间格式化是非常常用的一个功能,不管是从字符串到struct_time、date、datetime,还是从struct_time、date、datetime到字符串都需要用到。
格式化主要涉及到2个函数:
strftime:str表示字符串,f是format,time是时间,就是时间格式化为字符串
strptime:str表示字符串,p是parse,time是时间,就是字符串解析为时间
time和datetime都有这2个函数。

参考文献:
python 之 时间戳
Python中的时间元组与时间日期
Python3 日期和时间
Python日期时间(详细)
在实战中,数据常常存储在DataFrame之中,时间 date变量 可以是 作为index存在的,也可以是作为一个单独的变量存在的。格式为:2021-11-10 或者 20211110 或者2021/11/10 或者2021-11-10 00:00:00 等等样子。
首先,我们在 IPYTHON的命令窗口 In 1: 输入 df.dtypes(假设数据对象是df) 或者输入 df.info(),查看各个变量的个数,以及各个变量的属性。
如果date是字符型则显示为 object,
如果是数字型则显示为 int64 或者 float64,
如果是日期型则显示为 datetime64[ns]。
a.如果时间 date变量 是 作为index存在的(一般情况下通过 API提取的数据存在这样的情况,并且这时的date是时间型datetime64[ns]),下面我们要提取它的年月日。
df[‘year’] = df.index.year
df[‘month’] = df.index.month
df[‘day’] = df.index.day
b.如果是date是 数字型变量(20101203),显示为 int64 或者 float64。
df[“year”] = df[“date”].apply(lambda x: int(str(x)[:4])) #year 数字型
df[“year2”] = df[“date”].apply(lambda x: str(x)[:4]) #year2字符型
df[“month”] = df[“date”].apply(lambda x: int(str(x)[4:6]))
df[“day”] = df[“date”].apply(lambda x: int(str(x)[6:]))
c.如果是date是 字符型变量(“20101203”),显示为 object。
方法一:
import pandas as pd
from datetime import datetime
df[“date2”]=pd.to_datetime(df[“date”]) #字符型转化为时间型 datetime64[ns]
df[“year”] =pd.to_datetime(df[“date”]).dt.year #year数字型
df[“month”] =pd.to_datetime(df[“date”]).dt.month
df[“day”] =pd.to_datetime(df[“date”]).dt.day
方法二:
df[“year”] = df[“date”].apply(lambda x: int(x[:4])) #year数字型
df[“month”] = df[“date”].apply(lambda x: int(x[4:6]))
df[“day”] = df[“date”].apply(lambda x: int(x[6:]))
方法三:使用astype
df[‘date’].astype('datetime’64)
方法使四:用datetime
df[‘date’] = df[‘date’].apply(lambda x: datetime.strptime(x,’%Y-%m-%d’))
将日期转换为月份M、季度Q
df[‘period’] = df[‘date’].dt.to_period(‘M’)
d.如果date是日期型,则显示为 datetime64[ns]。
df[“year”] =pd.to_datetime(df[“date”]).dt.year #year数字型
df[“month”] =pd.to_datetime(df[“date”]).dt.month
df[“day”] =pd.to_datetime(df[“date”]).dt.day
e.如果date是python将excel读取的日期文本数字 转为日期(5位数字时间戳)。
如果时间戳是很长的位数,则:
- df[‘gtime’]=pd.to_datetime(df[‘gtime’],unit=‘s’))
#以上以默认1970-01-01为0点位
或者:
- df[‘time_stamp’]=pd.to_datetime(df[‘time_stamp’],unit=‘s’,origin=pd.Timestamp(‘2018-07-01’))
#这个的意思是将time_stamp这列的时间戳转换为日期格式,单位是秒(unit=‘s’),计算的日期是从2018年的7月1号开始,即从2018年的7月1号开始加上时间戳的那么多秒。
下面以excel读入时间数据(时间变为看似浮点型的数字了,并且是5位数字时间戳,开始的时候确实有点懵逼-^^-)为例来讲解:
#这列fin46本来在excel中是日期,读入Python后变为数字了,并且还有很多的缺失值nan
#如果直接使用时间转换函数,可能转不了,需要先将nan转为数值0
df_final['fin462']=df_final['fin46'].fillna(0)
from datetime import datetime
#以下是时间转换函数
def date_change(stamp):
delta = pd.Timedelta(str(stamp)+'D')
real_time = pd.to_datetime('1899-12-30') + delta
return real_time
#套用以上函数,转为 2021-11-16 00:00:00 字符型格式
df_final['fin463']=df_final['fin462'].apply(date_change)
#去掉时分秒
df_final["fin463"] = df_final["fin463"].dt.date
#或者代码
df_final["fin4633"] = df_final["fin463"][0].strftime("%Y-%m-%d")
#将日期 fin463 转换为月份、季度
df_final['period'] = df_final['fin463'].dt.to_period('M')
df_final['period2'] = df_final['fin463'].dt.to_period('Q')
#把一些本来是缺失的时间变为 空值
df_final.loc[df_final['fin462'] == 0,'fin463'] = None
#字符型转化为时间型 datetime64[ns]
df_final["date2"]=pd.to_datetime(df_final['fin463'])
#删除中间变量,因为他们已经无用武之地
del df_final['fin462']
del df_final['fin463']
#生成三列:年月日
df_final["year"] =pd.to_datetime(df_final["date2"]).dt.year #year数字型
df_final["month"] =pd.to_datetime(df_final["date2"]).dt.month
df_final["day"] =pd.to_datetime(df_final["date2"]).dt.day
参考文章:
https://blog.csdn.net/weixin_41261833/article/details/104839119
https://vimsky.com/examples/usage/python-pandas-period-strftime.html
https://vimsky.com/zh-tw/examples/usage/python-pandas-datetimeindex-strftime.html
https://www.cnblogs.com/shadow1/p/10951979.html
https://www.cnblogs.com/nxf-rabbit75/p/10660317.html
https://blog.csdn.net/u010591976/article/details/104253489?ivk_sa=1024320u

参考文章:
a = "44042"
import pandas as pd
def date(stamp):
delta = pd.Timedelta(str(stamp)+'D')
real_time = pd.to_datetime('1899-12-30') + delta
return real_time
print(str(date(a)).split(" ")[0])
原文链接:https://blog.csdn.net/qq_57173722/article/details/121030038

io = "中国数据.xlsx"
dt = pd.read_excel(io, sheet_name = 0)
dt1 = pd.read_excel(io, sheet_name = 1)
def date(para):
if type(para) == int:
delta = pd.Timedelta(str(int(para))+'days')
time = pd.to_datetime('1899-12-30') + delta
return time
else:
return para
dt['日期'] = dt['日期'].apply(date)
dt

还有这种时间显示的格式,pandas 读excel,日期变成了数字,pandas方法解决:

import pandas as pd
data = pd.read_excel('文件路径')
data['发货日期'] = data['发货日期'].fillna(method='ffill') # 因为有合并单元格,
data
def date(para):
delta = pd.Timedelta(str(int(para))+'days')
time = pd.to_datetime('1899-12-30') + delta
return time
data['发货日期'] = data['发货日期'].apply(date)
data

计算两个日期的时间(天数)间隔。
import time
def demo(day1, day2):
time_array1 = time.strptime(day1, "%Y-%m-%d")
timestamp_day1 = int(time.mktime(time_array1))
time_array2 = time.strptime(day2, "%Y-%m-%d")
timestamp_day2 = int(time.mktime(time_array2))
result = (timestamp_day2 - timestamp_day1) // 60 // 60 // 24
return result
day1 = "2018-07-09"
day2 = "2020-09-26"
day_diff = demo(day1, day2)
print("两个日期的间隔天数:{} ".format(day_diff))
#或者:
def is_leap_year(year):
if (year % 4 == 0 and year % 100 != 0) or year % 400 == 0:
return 1
else:
return 0
def get_days(year, month, day):
days = 0
month_days = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
if is_leap_year(year):
month_days[1] = 29
for i in range(1, year):
year_day = 365
if is_leap_year(i):
year_day = 366
days += year_day
for m in range(month - 1):
days += month_days[m]
days += day
return days
def get_result(start_time, end_time):
res = end_time - start_time
return res
year1, month1, day1 = 2018, 7, 9
year2, month2, day2 = 2020, 9, 26
days1 = get_days(year1, month1, day1)
days2 = get_days(year2, month2, day2)
day_diff = get_result(days1, days2)
print("两个日期的间隔天数:{} ".format(day_diff))
2. 索引的重建与设置
关键词:reset_index
reset_index可以还原索引,重新变为默认的整型索引。
df.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
常用的是:
df.reset_index(drop=False, inplace=True)
level控制了具体要还原的那个等级的索引;
drop为False则索引列会被还原为普通列,否则会丢失(True);
inplace=True时表示当前操作对原数据生效.
a.如果数据框df 索引 和 变量 都存在一个 date, 重建索引时要使用:
df.reset_index(drop=True,inplace=True)
这样date就能够顺利从index角色变为 普通变量的角色,方便 再次重新编制索引了。
b.如果数据框df 索引 与变量不存在重复, 重建索引时要使用:
df.reset_index( inplace=True) #索引变为普通变量
df.reset_index(drop=True, inplace=True) #原索引被删除了
当然,前期在重建索引时,最好不要删除原索引,后期可以随时删除:
df.drop(“date”,axis=1,inplace=True)
或者:
del df[“date”] #都能够删除这个原来的索引date.
关键词:set_index
DataFrame可以通过set_index方法,可以设置单索引和复合索引。
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
常用的是:
df.set_index(“code”,drop=False, inplace=True)
append添加新索引,
drop默认为False,True代表不删除作为新索引的列(变量),就是说一个字段 同时出现在 index 和 普通变量(列)之中。
inplace为True时,表示当前操作对原数据生效。
3. 数据的排序
要对pandas.DataFrame和pandas.Series进行排序,可以使用sort_values()和sort_index()方法。
a.按元素排序sort_values()(如果要更改原始对象,则参数inplace=True)
df_s = df.sort_values(‘state’) #按照一个变量排序
df_s = df.sort_values(‘state’, ascending=False)#按照一个变量排序,降序排
df_s = df.sort_values([‘age’, ‘state’], ascending=[True, False]))#按照多个变量排序,降或升序排都可以设置
df_d .sort_values(by=1, axis=1, ascending=False, inplace=True)#按照列来排序
b. 按索引排序(行名/列名)sort_index()
与sort_values()一样,默认值为升序。如果要使用降序,请将升序参数设置为False。
df_s = df.sort_index(ascending=False)
按列名列排序(参数axis),意义不大。
df.sort_index(axis=1, ascending=False, inplace=True)
c.多层索引的取值
loc使用的是标签索引,iloc使用的是位置索引。但是,iloc的取值并不会受多层索引影响,只会根据数据的位置索引进行取值。
s.loc[‘张三’]
s.loc[‘张三’,‘期中’]
s.loc[:,‘期中’]
s.iloc[0]
df.loc[‘张三’].loc[‘期中’]
df.loc[(‘张三’,‘期中’)]
多层索引的排序:
DataFrame按行索引排序的方法是sort_index(),df.sort_index()中的level参数可以指定是否按照指定的层级进行排列,第一层级索引值为0,第二层级索引值为1。df.sort_index(level=0,ascending=False).
4. 数据类型的转化
在实际的数据处理中,常见的数据类型包括了:numpy中的array、list、tuple、dict、pandas中的series、pandas中的dataframe。我们在套用他人的代码的时候,很多同学经常出错,原因就是别人代码输入端的规定数据类型和你的数据类型不一样,对象不一样,对象的属性和方法就出现了很大的差异,那程序当然运行不了呀。所以,你需要理解别人的代码,然后把我们自己的数据转化为 合格的数据类型。
a. DataFrame 转化为 List 类型
import pandas as pd
import numpy as np
from pandas import DataFrame
data_file = ‘d:/Users/qiguan/Downloads/data.xlsx’ #data_file 数据文件路径
data = pd.read_excel(data_file, index_col=None)#读取文件数据
data_array = np.array(data)#首先将pandas读取的数据转化为array
data_list =data_array.tolist() #然后转化为list形式
b. 把DataFrame转成Series类型,改变列中值的类型方法
b1. 使用 pd.Series把dataframe转成Series
import pandas as pd
df_series = pd.Series(df[‘Value’].values, index=df[‘Date’])
b2.使用astype改变列中的值的类型,注意前面要有np
import numpy as np
df[‘列名’] = df[‘列名’].astype(np.int64)
c. DataFrame类型转换成Numpy中array类型
import numpy as np
import pandas as pd
df=pd.DataFrame({‘A’:[1,2,3],‘B’:[4,5,6],‘C’:[7,8,9]})
c1.使用DataFrame中的values方法
np1 = df.values #type(np1) 查看类型为 numpy.ndarray
c2.使用Numpy中的array方法
np2 = np.array(df) #type(np2) 查看类型为 numpy.ndarray
2种方法效果相同,都能实现DataFrame到array的转换
5. 异常处理 -跳过异常继续执行
python一般使用try…except…处理异常,这样子的话,保障程序在遇到意外情况的时候,能够继续执行下去。当然,这个办法也有缺陷,就是丢失掉了一些数据,失去了改正的机会。要是想改正,我们就必须让程序返回错误的信息是什么才好下手去找错。

比如,很多时候代码只要有一个异常,程序就不继续执行了。异常情况是有很多的,有的你想也想不到。那么,当循环中出现异常时,如何跳过循环中的异常继续执行。比如当我move一个文件的时候,如果目标文件不存在,程序可跳过异常,继续执行,下面是一种可行的方法:
import pandas as pd
dates=range(20161010,20161114)
pieces=[]
for date in dates:
try:
data=pd.read_csv('A_stock/overview-push-%d/stock overview.csv' %date, encoding='gbk')
pieces.append(data)
except Exception as e:
pass #存有异常,但是跳过现在的错误的当前循环,继续执行下一步循环。
continue #无论是否有异常,都将继续执行 continue后面的命令,但是这里没有了后续命令,所以这儿的pass continue结构可以修改,即 pass改为continue,不过,如果原始的continue后面有语句则不同了。
data=pd.concat(pieces)
下面的代码相对完善一点:
try:
#x=1/0 #这个错误对应于 except Exception as e:
print('========>1')
name
print('==========>2')
l = [1, 2, 3]
# l[100]
print('==========>3')
d={ }
d['name']
print('=============>4')
except NameError as e:
print('----------->', e)
print(1)
except IndexError as e:
print('----------->', e)
print(2)
except KeyError as e:
print('----------->', e)
print(3)
except Exception as e:#异常不是上面的几种类型,但仍存有异常,则执行这个语句
print('统一的处理方法',333)
else: #所有的异常都没有用发生,则执行下面的语句
print('在被监测的代码块没有发生异常时执行')
finally: #不管上面的语句是否正确,都能执行下面的语句。
print('不管被监测的代码块有无发生异常都会执行')
print('执行接下去的代码')
try except 与pass continue结合编写代码:
- (1)为了跳过for循环里的某次循环,以下代码当某次循环发生错误时,执行except代码块,continue跳过该次循环:
x=5
for i in range(x):
try:
i += 1
print(i)
except:
pass #这儿pass可以换为 continue
print("kk:",i)
1
kk: 1
2
kk: 2
3
kk: 3
4
kk: 4
5
kk: 5
- (2)还可以写成这样,遇到错误执行except代码块,pass忽略错误并继续往下运行,略有不同的就是无论程序错误与否都会运行到continue这一行代码:
x=5
for i in range(x):
try:
i += 1
print(i)
except:
pass
continue
1
2
3
4
5
如果continue后面有语句情况就不一样了。
x=5
for i in range(x):
try:
i += 1
print(i)
except:
pass
continue
print("kk:",i)
continue不管程序是否出现异常,都将屏蔽后面的语句。
1
2
3
4
5
修改一下:
x=5
for i in range(x):
try:
i += 1
print(i)
except:
continue
print("kk:",i)
1
kk: 1
2
kk: 2
3
kk: 3
4
kk: 4
5
kk: 5
- (3)还有一种用法就是遇到错误时直接中断整个for循环:
try:
for i in range(x):
i += 1
print(i)
except:
pass
pass, continue 与条件语句的结合:
var = 10
while var > 0:
var = var -1
if var == 5:
pass
print ('当前变量值 :', var)
print( "Good bye!")
当前变量值 : 9
当前变量值 : 8
当前变量值 : 7
当前变量值 : 6
当前变量值 : 5
当前变量值 : 4
当前变量值 : 3
当前变量值 : 2
当前变量值 : 1
当前变量值 : 0
Good bye!
var = 10 # 第二个实例
while var > 0:
var = var -1
if var == 5:
continue
print ('当前变量值 :', var)
print( "Good bye!")
当前变量值 : 9
当前变量值 : 8
当前变量值 : 7
当前变量值 : 6
当前变量值 : 4
当前变量值 : 3
当前变量值 : 2
当前变量值 : 1
当前变量值 : 0
Good bye!
- 综上,continue 终止本次循环功能不变,pass无所事事的功能不变,但continue在与 pass结合起来,并与条件语句、循环语句使用的时候,要看清楚程序的结构层次,注意不同写法的差异。
6. CSV 与 Excel的 批量转换
在实际生活工作中,我们经常Csv文件与Excel文件,但是这两类文件通常情况下不能直接转换,Csv是逗号分隔数据的纯文本文件,可以保存任何文本类型数据,但不能保存格式、公式、宏等),需要手动另存对应格式文件。文件数量少还好,一旦涉及文件数量较多时,重复“另存为”操作很繁锁,而且往往会因编辑后未及时保存而丢失加工后的数据。
- 6.1 Excel转换为Csv
(1)读取当前目录下Excel文件
(2)读取Excel文件内容
(3)转换为Csv文件
#excel文件转化为csv文件
def excel_to_csv(in_path,out_path):
#获取当前目录下所有的excel文件
file_list=[file for file in os.listdir(in_path) if os.path.splitext(file)[1][1:]=='xlsx' or os.path.splitext(file)[1][1:]=='xls' ]
#遍历每个文件
for file in file_list:
#读取文件数据
df=pd.read_excel(os.path.join(in_path,file),index_col=0)
#转换为csv文件,不保存索引
df.to_csv(os.path.join(out_path,os.path.splitext(file)[0]+'.csv'),index=False)
#输出提示信息
print('转换完成')
- 6.2 Csv转换为Excel
(1)读取当前目录下Csv文件
(2)读取Csv文件内容
(3)转换为Excel文件
#csv文件转化为excel文件
def csv_to_excel(in_path,out_path):
#获取当前目录下所有的csv文件
file_list=[file for file in os.listdir(in_path) if os.path.splitext(file)[1][1:]=='csv']
#遍历每个文件
for file in file_list:
#读取文csv件数据
df=pd.read_csv(os.path.join(in_path,file),index_col=0)
#转换为excel文件,不保存索引
df.to_excel(os.path.join(out_path,os.path.splitext(file)[0]+'.xlsx'),index=False)
#输出提示信息
print('转换完成')
#读者可自己运行观察结果
7. 文件操作
参考文献:
Python文件操作,看这篇就足够
python 读写、创建 文件
python 文件操作,最全的一个(转)
Python文件操作
8. 数据读入与写入
参考文献:
读写Excel文件第三方库汇总
9. 缺失值问题 np.nan,None,NaT
文献1
文献2
https://blog.csdn.net/sinat_26811377/article/details/103216680
https://blog.csdn.net/laicikankna/article/details/106881864
10. 使用Python输出回归表格
https://github.com/divinites/stargazer-1 使用Stargazer模块
https://lost-stats.github.io/Presentation/Tables/Regression_Tables.html
https://qiita.com/huda_1629/items/d47d023936003ccf3fd1
https://cloud.tencent.com/developer/news/273282 利用python输出规范的回归结果,可惜百度网盘共享的 代码不见了。
https://cloud.tencent.com/developer/article/1739458 可以参考一下
https://github.com/YangShuangjie/summary3 原来可以运行,现在依赖包升级了,这个用不了了,希望哪个大神也升级一下这个程序。
from stargazer.stargazer import Stargazer
model1_stargazer = Stargazer([model1])
model1_stargazer
import os
os.chdir("d:\\") #设置一下HTML输出的目录地址
import pandas as pd
from sklearn import datasets
import statsmodels.api as sm
from stargazer.stargazer import Stargazer
from IPython.core.display import HTML
diabetes = datasets.load_diabetes()
df = pd.DataFrame(diabetes.data)
df.columns = ['Age', 'Sex', 'BMI', 'ABP', 'S1', 'S2', 'S3', 'S4', 'S5', 'S6']
df['target'] = diabetes.target
est = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[0:4]])).fit()
est2 = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[0:6]])).fit()
est3 = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[[2,4]]])).fit()
est4 = sm.OLS(endog=df['target'], exog=sm.add_constant(df[df.columns[3:6]])).fit()
stargazer = Stargazer([est, est2, est3, est4])
HTML(stargazer.render_html()) #网页上显示表格
#stargazer.render_html() #展示HTML原始代码
#或者如下代码可以帮我们去存储结果,然后在Excel里面去编辑完美一点:
stargazer_tab = Stargazer([est, est2, est3, est4])
stargazer_tab
open('regression.html', 'w').write(stargazer_tab.render_html()) # for html
'
\n| Dependent variable:target | ||||
| (1) | (2) | (3) | (4) | |
| ABP | 416.674*** | 397.583*** | 670.157*** | |
| (69.495) | (70.870) | (71.217) | ||
| Age | 37.241 | 24.704 | ||
| (64.117) | (65.411) | |||
| BMI | 787.179*** | 789.742*** | 921.169* | |
| (65.424) | (66.887) | (64.409) | ||
| S1 | 197.852 | 113.167 | 202.038 | |
| (143.812) | (64.409) | (158.070) | ||
| S2 | -169.251 | -23.728 | ||
| (142.744) | (156.064) | |||
| Sex | -106.578 | -82.862 | ||
| (62.125) | (64.851) | |||
| const | 152.133*** | 152.133*** | 152.133*** | 152.133*** |
| (2.853) | (2.853) | (2.967) | (3.277) | |
| Observations | 442 | 442 | 442 | 442 |
| R2 | 0.400 | 0.403 | 0.349 | 0.207 |
| Adjusted R2 | 0.395 | 0.395 | 0.346 | 0.201 |
| Residual Std. Error | 59.976 (df=437) | 59.982 (df=435) | 62.367 (df=439) | 68.901 (df=438) |
| F Statistic | 72.913*** (df=4; 437) | 48.915*** (df=6; 435) | 117.417*** (df=2; 439) | 38.032 (df=3; 438) |
| Note: | \n p<0.1;\n p<0.05;\n ***p<0.01\n | |||
以上代码在notebook中运行代码,结果贴在CSDN中后有点小瑕疵,应该是CSDN编译的问题,在notebook中没有问题。
https://github.com/YangShuangjie/summary3
# Load the data and fit
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
# ols
dat = sm.datasets.get_rdataset("Guerry", "HistData").data
res_ols = smf.ols('Lottery ~ Literacy + np.log(Pop1831)', data=dat).fit()
#glm
data = sm.datasets.scotland.load()
data.exog = sm.add_constant(data.exog)
gamma_model = sm.GLM(data.endog, data.exog, family=sm.families.Gamma())
res_glm = gamma_model.fit()
# gee
data = sm.datasets.get_rdataset('epil', package='MASS').data
fam = sm.families.Poisson()
ind = sm.cov_struct.Exchangeable()
mod = smf.gee("y ~ age + trt + base", "subject", data, cov_struct=ind, family=fam)
res_gee = mod.fit()
# logit
spector_data = sm.datasets.spector.load()
spector_data.exog = sm.add_constant(spector_data.exog)
logit_mod = sm.Logit(spector_data.endog, spector_data.exog)
res_logit = logit_mod.fit()
# load panel data and fit the model
from linearmodels.datasets import wage_panel
data = wage_panel.load()
year = pd.Categorical(data.year)
data = data.set_index(['nr', 'year'])
data['year'] = year
from linearmodels.panel import PooledOLS
exog_vars = ['black','hisp','exper','expersq','married', 'educ', 'union', 'year']
exog = sm.add_constant(data[exog_vars])
mod = PooledOLS(data.lwage, exog)
res_pooled = mod.fit()
from linearmodels.panel import PanelOLS
exog_vars = ['expersq','union','married']
exog = sm.add_constant(data[exog_vars])
mod = PanelOLS(data.lwage, exog, entity_effects=True, time_effects=True)
res_fe_re = mod.fit()
from linearmodels.panel import FirstDifferenceOLS
exog_vars = ['exper','expersq', 'union', 'married']
exog = data[exog_vars]
mod = FirstDifferenceOLS(data.lwage, exog)
res_fd = mod.fit()
exog_vars = ['black','hisp','exper','expersq','married', 'educ', 'union']
exog = sm.add_constant(data[exog_vars])
mod = PooledOLS(data.lwage, exog)
res_robust = mod.fit(cov_type='robust')
res_clust_entity = mod.fit(cov_type='clustered', cluster_entity=True)
res_clust_entity_time = mod.fit(cov_type='clustered', cluster_entity=True, cluster_time=True)
#我看了一下summary3的源代码,作者添加了 to_excel 和 to_csv 等函数。现在不能用了
from summary3 import summary_col
# summary_col(res_ols)
summary_col([res_ols])
print(summary_col([res_ols,res_glm,res_gee,res_logit],more_info=['df_model','scale']))
print(sumary_col([res_fe_re,res_fd,res_robust,res_clust_entity,res_clust_entity_time],
regressor_order=['black'],show='se',title='Panel Results Summary Table'))
summary_col([res_glm,res_logit]).to_excel()
summary_col([res_clust_entity,res_fd]).to_csv('your path\\filename.csv')
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 5 22:10:44 2021
@author: Administrator
"""
import pandas as pd
import numpy as np
from statsmodels.datasets import grunfeld
data = grunfeld.load_pandas().data
data.year = data.year.astype(np.int64)
# MultiIndex, entity - time
data = data.set_index(['firm','year'])
from linearmodels import PanelOLS
mod = PanelOLS(data.invest, data[['value','capital']])
fe_res_VS = mod.fit(cov_type='clustered', cluster_entity=True)
pd.set_option('precision', 4)
pd.options.display.float_format = '{:,.4f}'.format
Reg_Output_FAmount= pd.DataFrame()
#1)
Table1 = pd.DataFrame(fe_res_VS.params)
Table1['id'] = np.arange(len(Table1))#create numerical index for pd.DataFrame
Table1 = Table1.reset_index().set_index(keys = 'id')#set numercial index as new index
Table1 = Table1.rename(columns={"index":"parameter", "parameter":"coefficient 1"})
P1 = pd.DataFrame(fe_res_VS.pvalues)
P1['id'] = np.arange(len(P1))#create numerical index for pd.DataFrame
P1 = P1.reset_index().set_index(keys = 'id')#set numercial index as new index
P1 = P1.rename(columns={"index":"parameter"})
Table1 = pd.merge(Table1, P1, on='parameter')
Table1['significance 1'] = np.where(Table1['pvalue'] <= 0.01, '***',\
np.where(Table1['pvalue'] <= 0.05, '**',\
np.where(Table1['pvalue'] <= 0.1, '*', '')))
Table1.rename(columns={"pvalue": "pvalue 1"}, inplace=True)
SE1 = pd.DataFrame(fe_res_VS.std_errors)
SE1['id'] = np.arange(len(SE1))#create numerical index for pd.DataFrame
SE1 = SE1.reset_index().set_index(keys = 'id')#set numercial index as new index
SE1 = SE1.rename(columns={"index":"parameter", "std_error":"coefficient 1"})
SE1['parameter'] = SE1['parameter'].astype(str) + '_SE'
SE1['significance 1'] = ''
SE1 = SE1.round(4)
SE1['coefficient 1'] = '(' + SE1['coefficient 1'].astype(str) + ')'
Table1 = Table1.append(SE1)
Table1 = Table1.sort_values('parameter')
Table1.replace(np.nan,'', inplace=True)
del P1
del SE1
fe_res_CVS = mod.fit(cov_type='clustered', cluster_entity=True)
#2)
Table2 = pd.DataFrame(fe_res_CVS.params)
Table2['id'] = np.arange(len(Table2))#create numerical index for pd.DataFrame
Table2 = Table2.reset_index().set_index(keys = 'id')#set numercial index as new index
Table2 = Table2.rename(columns={"index":"parameter", "parameter":"coefficient 2"})
P2 = pd.DataFrame(fe_res_CVS.pvalues)
P2['id'] = np.arange(len(P2))#create numerical index for pd.DataFrame
P2 = P2.reset_index().set_index(keys = 'id')#set numercial index as new index
P2 = P2.rename(columns={"index":"parameter"})
Table2 = pd.merge(Table2, P2, on='parameter')
Table2['significance 2'] = np.where(Table2['pvalue'] <= 0.01, '***',\
np.where(Table2['pvalue'] <= 0.05, '**',\
np.where(Table2['pvalue'] <= 0.1, '*', '')))
Table2.rename(columns={"pvalue": "pvalue 2"}, inplace=True)
SE2 = pd.DataFrame(fe_res_CVS.std_errors)
SE2['id'] = np.arange(len(SE2))#create numerical index for pd.DataFrame
SE2 = SE2.reset_index().set_index(keys = 'id')#set numercial index as new index
SE2 = SE2.rename(columns={"index":"parameter", "std_error":"coefficient 2"})
SE2['parameter'] = SE2['parameter'].astype(str) + '_SE'
SE2['significance 2'] = ''
SE2 = SE2.round(4)
SE2['coefficient 2'] = '(' + SE2['coefficient 2'].astype(str) + ')'
Table2 = Table2.append(SE2)
Table2 = Table2.sort_values('parameter')
Table2.replace(np.nan,'', inplace=True)
del P2
del SE2
#Merging Tables and adding Stats
Reg_Output_FAmount= pd.merge(Table1, Table2, on='parameter', how='outer')
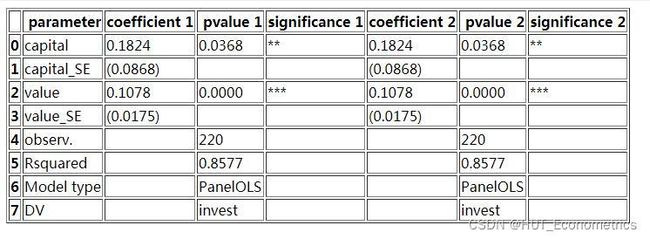
Reg_Output_FAmount = Reg_Output_FAmount.append(pd.DataFrame(np.array([["observ.", fe_res_VS.nobs, '', fe_res_CVS.nobs, '']]), columns=['parameter', 'pvalue 1', 'significance 1', 'pvalue 2', 'significance 2']), ignore_index=True)
Reg_Output_FAmount = Reg_Output_FAmount.append(pd.DataFrame(np.array([["Rsquared", "{:.4f}".format(fe_res_VS.rsquared), '', "{:.4f}".format(fe_res_CVS.rsquared), '']]), columns=['parameter', 'pvalue 1', 'significance 1', 'pvalue 2', 'significance 2']), ignore_index=True)
Reg_Output_FAmount= Reg_Output_FAmount.append(pd.DataFrame(np.array([["Model type", fe_res_VS.name, '', fe_res_CVS.name, '']]), columns=['parameter', 'pvalue 1', 'significance 1', 'pvalue 2', 'significance 2']), ignore_index=True)
Reg_Output_FAmount = Reg_Output_FAmount.append(pd.DataFrame(np.array([["DV", fe_res_VS.model.dependent.vars[0], '', fe_res_CVS.model.dependent.vars[0], '']]), columns=['parameter', 'pvalue 1', 'significance 1', 'pvalue 2', 'significance 2']), ignore_index=True)
Reg_Output_FAmount.fillna('', inplace=True)
Reg_Output_FAmount.to_html()
open('d://ss5.html', 'w').write(Reg_Output_FAmount.to_html()) # for html
11. 特殊结构数据整理
https://www.cnpython.com/qa/560110
import numpy as np
from scipy.stats import norm, gaussian_kde
import matplotlib.pyplot as plt
import pandas as pd
from linearmodels.panel.data import PanelData
from linearmodels.panel import PanelOLS, PooledOLS, RandomEffects, compare
from collections import OrderedDict
import wooldridge
from statsmodels.formula.api import ols
import warnings
warnings.filterwarnings("ignore")
wagepan = wooldridge.data('wagepan')
wooldridge.data('wagepan', description=True)
np.random.seed(123)
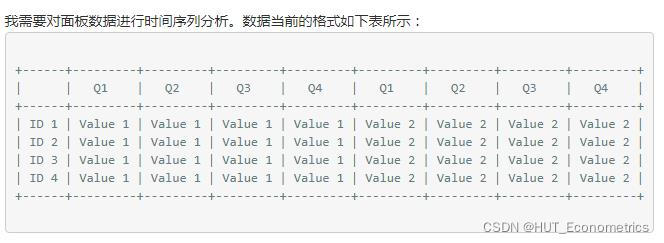
df = pd.DataFrame(np.random.randint(1,10,(4,12)),
index=['ID 1', 'ID 2', 'ID 3', 'ID 4'])
df.columns = ['Q1', 'Q2', 'Q3', 'Q4']*3
df.columns = [
df.columns.to_series().groupby(level=0).cumcount().map({0: 'X', 1: 'Y',2:'Z'}),
df.columns
]
df2=df.stack().rename_axis(['ID', 'T']).reset_index()
https://stackoverflow.com/questions/32835498/pandas-python-describe-formatting-output
这是典型的 纵向结构(类似于面板数据)的数据 转换为 横向排列的数据。
#这个是将描述性统计 与 相关系数表输出,很简单。
df=df_final
temp = df.groupby('firm')['fin0'].describe().reset_index()
aaa=temp.stack(level=-1) #unstack(),unstack(level=-1) level can be -1, 0
temp = df.corr().reset_index()
# 模拟数据
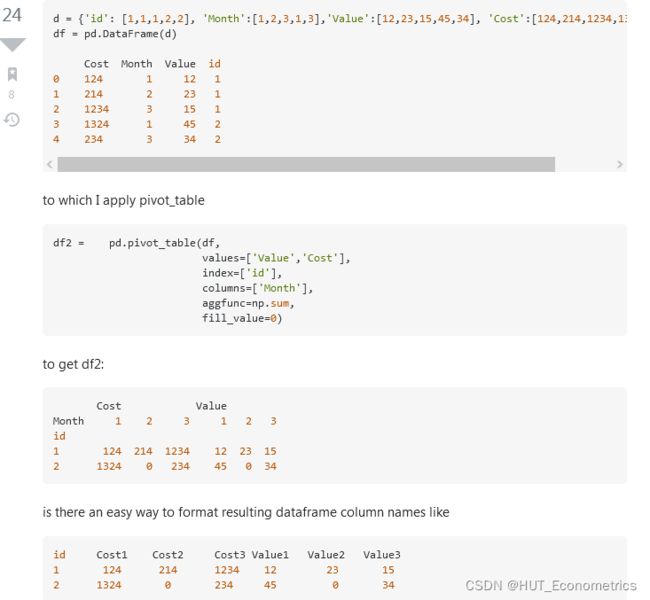
d = {'id': [1,1,1,2,2], 'Month':[1,2,3,1,3],'Value':[12,23,15,45,34], 'Cost':[124,214,1234,1324,234]}
df = pd.DataFrame(d)
df2 = pd.pivot_table(df,
values=['Value','Cost'],
index=['id'],
columns=['Month'],
aggfunc=np.sum,
fill_value=0)
df2.columns =[s1 + str(s2) for (s1,s2) in df2.columns.tolist()]
df2.reset_index(inplace=True)
df2.columns = [' '.join(col).strip() for col in df2.columns.values]
df2.index.name = None
12. 估计系数联合检验(Wald tests via statsmodels)
系数联合相等,联合等于0,任意两个系数之差 检验,等等,诸如此类,都可以执行 wald 检验。
https://andrewpwheeler.com/2021/06/18/wald-tests-via-statsmodels-python/
https://github.com/apwheele/ 作者主页
Often times interventions are general and may be expected to reduce multiple crime types, e.g. hot spots policing may reduce both violent crimes and property crimes. But we do not know for sure – so it makes sense to fit models to check if that is the case.
For crimes that are more/less prevalent, this is a case in which fitting Poisson/Negative Binomial models makes alot of sense, since the treatment effect is in terms of rate modifiers. The crossvalidated post shows an example in R. In the past I have shown how to stack models and do these tests in Stata, or use seemingly unrelated regression in Stata for generalized linear models. Here I will show an example in python using data from my dissertation on stacking models and doing Wald tests.
The above link to github has the CSV file and metadata to follow along. Here I just do some upfront data prep. The data are crime counts at intersections/street segments in DC, across several different crime types and various aspects of the built environment.
# python code to stack models and estimate wald tests
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
import patsy
import itertools
# Use dissertation data for multiple crimes
#https://github.com/apwheele/ResearchDesign/tree/master/Week02_PresentingResearch
data = pd.read_csv(r'd://DC_Crime_MicroPlaces.csv', index_col='MarID')
# only keep a few independent variables to make it simpler
crime = ['OffN1','OffN3','OffN5','OffN7','OffN8','OffN9'] #dropping very low crime counts
x = ['CFS1','CFS2'] #311 calls for service
data = data[crime + x].copy()
data.reset_index(inplace=True)
# Stack the data into long format, so each crime is a new row
data_long = pd.wide_to_long(data, 'OffN',i='MarID',j='OffCat').reset_index()
data_long.sort_values(by=['MarID','OffN'],inplace=True)
# Fit a model with clustered standard errors
covp = {'groups': data_long['MarID'],'df_correction':True}
nb_mod = smf.negativebinomial('OffN ~ C(OffCat) + CFS1:C(OffCat) ',data_long).fit(cov_type='cluster',cov_kwds=covp)
print(nb_mod.summary())
# Conduct a Wald test for equality of multiple coefficients
x_vars = nb_mod.summary2().tables[1].index
wald_str = ' = '.join(list(x_vars[6:-1]))
print(wald_str)
wald_test = nb_mod.wald_test(wald_str) # joint test
print(wald_test)
# Or can do test all join equal 0
nb_mod.wald_test_terms()
# To replicate what wald_test_terms is doing yourself
all_zero = [x + '= 0' for x in x_vars[6:-1]]
nb_mod.wald_test(','.join(all_zero))
# Pairwise contrasts of coefficients
# To get the actual difference in coefficients
wald_li = []
for a,b in itertools.combinations(x_vars[6:-1],2):
wald_li.append(a + ' - ' + b + ' = 0')
wald_dif = ' , '.join(wald_li)
dif = nb_mod.t_test(wald_dif)
print(dif)
# c's correspond to the wald_li list
res_contrast = dif.summary_frame()
res_contrast['Test'] = wald_li
res_contrast.set_index('Test', inplace=True)
print(res_contrast)
# Nicer function to print out the actual tests it interprets as
# ends up being 1 - 3, 3 - 5, etc.
def nice_lab_tests(test_str,mod):
# Getting exogenous variables
x_vars = mod.summary2().tables[1].index
# Patsy getting design matrix and constraint from string
di = patsy.DesignInfo(x_vars)
const_mat = di.linear_constraint(test_str)
r_mat = const_mat.coefs
c_mat = list(const_mat.constants)
# Loop over the tests, get non-zero indices
# Build the interpreted tests
lab = []
for i,e in enumerate(c_mat):
lm = r_mat[i,:] #single row of R matrix
nz = np.nonzero(lm)[0].tolist() #only need non-zero
c_vals = lm[nz].tolist()
v_labs = x_vars[nz].tolist()
fin_str = ''
in_val = 0
for c,v in zip(c_vals,v_labs):
# 1 and -1 drop values and only use +/-
if c == 1:
if in_val == 0:
fin_str += v
else:
fin_str += ' + ' + v
elif c == -1:
if in_val == 0:
fin_str += '-' + v
else:
fin_str += ' - ' + v
else:
if in_val == 0:
fin_str += str(c) + '*' + v
else:
if c > 0:
sg = ' + '
else:
sg = ' - '
fin_str += sg + str(np.abs(c)) + '*' + v
in_val += 1
fin_str += ' = ' + str(e[0]) #set equality at end
lab.append(fin_str)
return lab
#任意组合的变量组,联合系数检验。
# Wald string for equality across coefficients
# from earlier
lab_tests = nice_lab_tests(wald_str,nb_mod)
print(lab_tests)
dif4 = nb_mod.t_test(lab_tests)
print(dif4)
# Additional test to show how nice_lab_tests function works
str2 = 'CFS2:C(OffCat)[1] = 3, CFS2:C(OffCat)[7] = CFS2:C(OffCat)[5]'
nice_lab_tests(str2,nb_mod)
dif3 = nb_mod.t_test(nice_lab_tests(str2,nb_mod))
print(dif3)
13. Python 与 STATA 时间日期转换问题
参考文献:STATA时间格式
Python的时间常常是下面的样子:
±--------------------------+
| datetime year |
|---------------------------|
1. | 09sep1943 00:00:00 1943 |
±--------------------------+
将其输出到stata之中后,怎么样获取年月日等数据呢?
到了stata之后,格式显示为 %tc double。
首先是显示为年月日的形式:
gen eventdate=dofc(datetime) #dofc是将函数格式转化为日期
format eventdate=%td
gen year = yofd(dofc(datetime)) 显示年月等等
gen day = dofy(dofc(datetime))
gen year = yofd(dofc(datetime)) //由天数数据计算年份
gen halfyear=hofd(dofc(datetime)) //由天数数据计算半年
format %thCCYY!hh halfyear
gen quarter=qofd(dofc(datetime)) //由天数数据计算季度数
format %tqCCYY!qq quarter
gen month=mofd(dofc(datetime)) //由天数数据计算月度数
format %tmCCYY-NN month
or. format month %tmCY_N
gen week=wofd(dofc(datetime)) //由天数数据计算周数
format %twCCYY!www week
14. Python执行面板数据的Hausman检验
参考文献:https://py4etrics.github.io/17_Panel.html 日本学者教学网站
#首先使用 PanelOLS 模块来进行 个体固定效应、时间固定效应 估计
formula_fe = 'lwage ~ married + union + expersq \
+d81+d82+d83+d84+d85+d86+d87 + EntityEffects'
mod_fe = PanelOLS.from_formula(formula_fe, data=wagepan)
est1 = mod_fe.fit()
print(est1)
#同学们,这个wald检验有很多种,我们现在需要的是所有系数均=0的联合检验
restriction = 'married = union = expersq = d81=d82=d83=d84=d85=d86=d87=0'
est1.wald_test(formula=restriction)
#下面,我们将要进行hausman检验,进而确定是采用 随机效应还是 固定效应模型,
# 注意,这个检验的 原假设是 支持采用随机效应 模型。
# 第一步 应用固定效应模型 进行拟合
formula_fe = 'lwage ~ married + union + expersq \
+d81+d82+d83+d84+d85+d86+d87 + EntityEffects'
mod_fe = PanelOLS.from_formula(formula_fe, data=wagepan)
fe_res = mod_fe.fit()
print(fe_res)
# 第二步 应用随机效应模型 进行拟合
formula_re = 'lwage ~ married + union + expersq \
+d81+d82+d83+d84+d85+d86+d87 '
model_re = RandomEffects.from_formula(formula_re, data=wagepan)
re_res = model_re.fit()
print(re_res)
# 第三步,运用计量书本上的公式,自编函数, 因为目前 Python里面没有现成的模块
import numpy.linalg as la
from scipy import stats
import numpy as np
def hausman(fe, re):
b = fe.params
B = re.params
v_b = fe.cov
v_B = re.cov
df = b[np.abs(b) < 1e8].size
chi2 = np.dot((b - B).T, la.inv(v_b - v_B).dot(b - B))
pval = stats.chi2.sf(chi2, df)
return chi2, df, pval
# 第四步,将 1 2 步的结果带入自编函数之中。
hausman_results = hausman(re_res, fe_res)
print('chi-Squared: ' + str(hausman_results[0]))
print('degrees of freedom: ' + str(hausman_results[1]))
print('p-Value: ' + str(hausman_results[2]))
# 第五步,看结果,如果这儿的 p-Value 小于 10%,则支持 固定效应 模型。
# 不过,我们的作业,只是一个练习, 不管这个 p-Value 等于多少,我们只提供固定效应结果。
# 计量的路很长,理论与软件操作 缺一不可。
15. Fama Macbeth回归、滚动回归等等
https://fin-library.readthedocs.io/en/latest/BYU FIN 585 Library Documentation 这个上面提供了多个有用的包。https://pypi.org/project/finance-byu/#files
还有一些网页也介绍了这个算法:
https://www.cnblogs.com/jungsee/p/8448156.html我原来的主页
https://www.kevinsheppard.com/teaching/python/notes/notebooks/example-fama-macbeth/数据也在这个教授的主页上
https://randlow.github.io/posts/finance-economics/asset-pricing-regression/
相关讨论的网页:
https://stackoverflow.com/questions/24074481/fama-macbeth-regression-in-python-pandas-or-statsmodels
https://www.e-learn.cn/topic/1620028

from finance_byu.fama_macbeth import fama_macbeth, fama_macbeth_parallel, fm_summary, fama_macbeth_numba
import pandas as pd
import time
import numpy as np
n_jobs = 5
n_firms = 1.0e2
n_periods = 1.0e2
def firm(fid):
f = np.random.random((int(n_periods),4))
f = pd.DataFrame(f)
f['period'] = f.index
f['firmid'] = fid
return f
df = [firm(i) for i in range(int(n_firms))]
df = pd.concat(df).rename(columns={0:'ret',1:'exmkt',2:'smb',3:'hml'})
df.head()
result = fama_macbeth(df,'period','ret',['exmkt','smb','hml'],intercept=True)
result.head()
fm_summary(result)
%timeit fama_macbeth(df,'period','ret',['exmkt','smb','hml'],intercept=True)
%timeit fama_macbeth_parallel(df,'period','ret',['exmkt','smb','hml'],intercept=True)
%timeit fama_macbeth_numba(df,'period','ret',['exmkt','smb','hml'],intercept=True)
from finance_byu.statistics import GRS
import numpy as np
import pandas as pd
n_periods = 1.0e2
df = pd.DataFrame(np.random.random((int(n_periods),6)))
df = df.rename(columns={0:'port1',1:'port2',2:'port3',3:'exmkt',4:'smb',5:'hml'})
grsstat,pval,tbl = GRS(df,['port1','port2','port3'],['exmkt','smb','hml'])
grsstat
pval
from tabulate import tabulate
print(tabulate(tbl.render(),tablefmt='github',headers=tbl.render().columns))
from finance_byu.summarize import summary
n_periods = 1.0e2
df = pd.DataFrame(np.random.random((100,3))/10.,columns=['Port 1','Port 2','Port 3'])
summary(df)
# -*- coding: utf-8 -*-
from numpy import mat, cov, mean, hstack, multiply,sqrt,diag, \
squeeze, ones, array, vstack, kron, zeros, eye, savez_compressed
from numpy.linalg import inv
from scipy.stats import chi2
from pandas import read_csv
import statsmodels.api as sm
import os
os.chdir("d://")
data =read_csv('FamaFrench.csv')
# Split using both named colums and ix for larger blocks
dates = data['date'].values
factors = data[['VWMe', 'SMB', 'HML']].values
riskfree = data['RF'].values
portfolios = data.iloc[:, 5:].values
# Use mat for easier linear algebra
factors = mat(factors)
riskfree = mat(riskfree)
portfolios = mat(portfolios)
# Shape information
T,K = factors.shape
T,N = portfolios.shape
# Reshape rf and compute excess returns
riskfree.shape = T,1
excessReturns = portfolios - riskfree
# Time series regressions
X = sm.add_constant(factors)
ts_res = sm.OLS(excessReturns, X).fit()
alpha = ts_res.params[0]
beta = ts_res.params[1:]
avgExcessReturns = mean(excessReturns, 0)
# Cross-section regression
cs_res = sm.OLS(avgExcessReturns.T, beta.T).fit()
riskPremia = cs_res.params
# Moment conditions
X = sm.add_constant(factors)
p = vstack((alpha, beta))
epsilon = excessReturns - X @ p
moments1 = kron(epsilon, ones((1, K + 1)))
moments1 = multiply(moments1, kron(ones((1, N)), X))
u = excessReturns - riskPremia[None,:] @ beta
moments2 = u * beta.T
# Score covariance
S = mat(cov(hstack((moments1, moments2)).T))
# Jacobian
G = mat(zeros((N * K + N + K, N * K + N + K)))
SigmaX = (X.T @ X) / T
G[:N * K + N, :N * K + N] = kron(eye(N), SigmaX)
G[N * K + N:, N * K + N:] = -beta @ beta.T
for i in range(N):
temp = zeros((K, K + 1))
values = mean(u[:, i]) - multiply(beta[:, i], riskPremia)
temp[:, 1:] = diag(values)
G[N * K + N:, i * (K + 1):(i + 1) * (K + 1)] = temp
vcv = inv(G.T) * S * inv(G) / T
vcvAlpha = vcv[0:N * K + N:4, 0:N * K + N:4]
J = alpha @ inv(vcvAlpha) @ alpha.T
J = J[0, 0]
Jpval = 1 - chi2(25).cdf(J)
vcvRiskPremia = vcv[N * K + N:, N * K + N:]
annualizedRP = 12 * riskPremia
arp = list(squeeze(annualizedRP))
arpSE = list(sqrt(12 * diag(vcvRiskPremia)))
print(' Annualized Risk Premia')
print(' Market SMB HML')
print('--------------------------------------')
print('Premia {0:0.4f} {1:0.4f} {2:0.4f}'.format(arp[0], arp[1], arp[2]))
print('Std. Err. {0:0.4f} {1:0.4f} {2:0.4f}'.format(arpSE[0], arpSE[1], arpSE[2]))
print('\n\n')
print('J-test: {:0.4f}'.format(J))
print('P-value: {:0.4f}'.format(Jpval))
i = 0
betaSE = []
for j in range(5):
for k in range(5):
a = alpha[i]
b = beta[:, i]
variances = diag(vcv[(K + 1) * i:(K + 1) * (i + 1), (K + 1) * i:(K + 1) * (i + 1)])
betaSE.append(sqrt(variances))
s = sqrt(variances)
c = hstack((a, b))
t = c / s
print('Size: {:}, Value:{:} Alpha Beta(VWM) Beta(SMB) Beta(HML)'.format(j + 1, k + 1))
print('Coefficients: {:>10,.4f} {:>10,.4f} {:>10,.4f} {:>10,.4f}'.format(a, b[0], b[1], b[2]))
print('Std Err. {:>10,.4f} {:>10,.4f} {:>10,.4f} {:>10,.4f}'.format(s[0], s[1], s[2], s[3]))
print('T-stat {:>10,.4f} {:>10,.4f} {:>10,.4f} {:>10,.4f}'.format(t[0], t[1], t[2], t[3]))
print('')
i += 1
betaSE = array(betaSE)
savez_compressed('fama-macbeth-results', alpha=alpha, beta=beta,
betaSE=betaSE, arpSE=arpSE, arp=arp, J=J, Jpval=Jpval)
from numpy import savez
savez('fama-macBeth-results.npz', arp=arp, beta=beta, arpSE=arpSE,
betaSE=betaSE, J=J, Jpval=Jpval)
16. 事件研究法 event study
https://www.lianxh.cn/news/90de95e42e8ff.html
http://fmwww.bc.edu/repec/bocode/e/
https://zhuanlan.zhihu.com/p/348125854
前期准备:使用eventstudy2命令需要先安装用户编写的程序moremata、nearmrg、distinct、_gprod、rmse和parallel。
ssc install moremata
ssc install nearmrg
ssc install distinct
ssc install _gprod
ssc install rmse
ssc install parallel
注:moremata可能存在安装不成功的问题,这时可以选择手动安装。下载moremata.zip并解压缩到指定文件夹路径(例如E:\moremata),运行如下命令
net install moremata, from(E:\moremata)
eventstudy2 执行事件研究程序,并允许用户指定设定已在金融领域和相关文献中建立的几个模型,例如原始收益率、市场模型、多因子模型和买入-持有异常收益率(BHAR)。估计窗口和事件窗口可以被自由选择,可以计算多达10个窗口的累积(平均)异常(买入-持有)收益率。当前eventstudy2的输出结果提供了下列检验统计量,它们均使用Mata编程语言:
eventstudy2 Security_id Date using Security_returns if Ea > 0.05, ///
ret(Return) car1LB(-1) car1UB(1) mod(FM) marketfile(Factor_returns) ///
mar(MKT) idmar(Market_reference)
#市场模型,需要三个数据集支持这个算法模块
import pandas as pd
import tushare as ts
token = '第一步准备阶段的接口复制到此处'
pro = ts.pro_api('2f4f20d8b2fb57e033a820d04954b6f8a33f5a44c18b806189a802adsee')
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')#画图风格
#获取深交所指数列表,找创业板指数的代码
dfzs = pro.index_basic(market='szse')
#获取深证综合指数基本信息
df = pro.index_daily(ts_code='399107.SZ', start_date='20130101', end_date='20 211225')
#h获取深证综合指数的交易日和日涨幅列
df_index = df[['trade_date', 'pct_chg']]
#df_index1 = df[['trade_date', 'pct_chg']]
#调整日期格式并按照日期进行排序
df_index['trade_date'] = pd.to_datetime(df_index['trade_date'])
df_index = df_index.sort_values("trade_date")
#reset_index()重置索引,0,1,2,3
#删除index列
df_index = df_index.reset_index().drop("index", axis=1)
#将涨跌幅转化为百分数对应的小数
df_index['pct_chg'] = df_index['pct_chg'] / 100
d2= pro.daily(ts_code='000333.SZ', start_date='20110121', end_date='20211225')
d0 = d2[['trade_date', 'pct_chg']]
d0.columns = ['trade_date', 'return']
#df_index1 = df[['trade_date', 'return']]
#调整日期格式为pandas格式,并按照日期进行排序
d0['trade_date'] = pd.to_datetime(d0['trade_date'])
d0 = d0.sort_values("trade_date")
#reset_index()重置索引,0,1,2,3
#删除index列
d0 = d0.reset_index().drop("index", axis=1)
#将涨跌幅转化为百分数对应的小数
d0['return'] = d0['return'] / 100
#获取美的集团2013-01-01至2020-02-20的日涨幅数据
d1= d0[(d0['trade_date'] >= '2013-01-01') & (d0['trade_date'] <= '2021-12-25')].copy()
#股票涨跌幅和市场涨跌幅
#以左侧为基础,交易日为关键值进行合并,df_index没有的值填充nan
df_final = d1.merge(df_index, on='trade_date', how='left')
df_final.to_excel("整理数据.xlsx")
#事件发生日
events = [ '2017-03-29','2018-03-29','2020-01-03','2020-02-03']
from sklearn.linear_model import LinearRegression#机器学习中的线性回归
# 以 f开头表示在字符串内支持大括号内的python 表达式
#round四舍六入五留双
#预期收益率的计算函数
def get_OLS(X, y, pre_X):
linear_m = LinearRegression().fit(X, y)#基于数组x和y建立回归模型
r_2 = linear_m.score(X, y)#值越接近1越好,拟合优度越好。
print(f"构建模型,拟合优度为{round(r_2*100, 2)}%")
print(f"y = {round(linear_m.intercept_,3)} + {round(linear_m.coef_[0],3)}Rm + e")
return linear_m.predict(pre_X)
#linear_m.predict(pre_X)利用数据回归出的归线性函数,预测预期的回报率,pre_X为窗口期的市场回报率即创业板指数的窗口期
#观测值x,观测值y
''' R² =(1-u/v)
u=((y_true - y_pred) ** 2).sum() v=((y_true - y_true.mean()) ** 2).sum()
其中y_pred已经在score方法中通过predict()方法得到,即通过线性回归预测的数据,再与y_true(观测值)进行比对。
u是损失函数,u越大损失越多,其与v的比值越小越好
R2的值就越大越好!'''
''' coef_ 数组型变量, 形状为(n_features,)或(n_targets, n_features)
说明:对于线性回归问题计算得到的feature的系数,即权重向量。
如果输入的是多目标问题,则返回一个二维数组(n_targets, n_features);如果是单目标问题,返回一个一维数组 (n_features,)。
intercept_ 数组型变量
说明:线性模型中的独立项,即b值。截距项
'''
#计算累计异常收益率car的函数
def get_data(event):
print("事件日为: ", event)
q, h = df_final[df_final['trade_date'] == event].index[0] - 5, df_final[df_final['trade_date'] == event].index[0] + 5
#event为事件发生日的日期,此处为以事件发生日的索引前后+10设定前后十天的窗口期
target = df_final.loc[q:h].copy()
#窗口期
estimate_df = df_final.loc[q-160:q]
#估计期
X = estimate_df[['pct_chg']]
#估计期深证综合指数涨幅
y = estimate_df['return']
#估计期美的集团涨幅
predict_X = target[['pct_chg']]
#窗口期的深证综合指数涨幅,作用是在预测中当做自变量来使用,加个predict把我弄糊涂了
target['E(Rt)'] = get_OLS(X, y, predict_X)
#预期收益率的计算
target['ARt'] = target['return'] - target['E(Rt)']
#异常收益率 = 实际收益率 -预期收益率
target['CARt'] = target['ARt'].cumsum()
#累计异常收益率 = 异常收益率在窗口期的求和
return target
#对异常收益率和累计异常收益率进行作图
def main(e):
a = get_data(e)
plt.rcParams['savefig.dpi'] = 600 #图片像素
plt.rcParams['figure.dpi'] = 600 #分辨率
a.set_index('trade_date')[['ARt', 'CARt']].plot()
for e in events:
main(e)
print("-"*10)
# bug: 1.同一个公司 有多个事件;2.事件日 不在交易日。
import os
os.chdir("d://")
import pandas as pd
df = pd.read_excel('eventdates.xlsx').drop_duplicates(['code'],keep='last')
df0 = df[['code','date']].reset_index().drop("index", axis=1)
# dfcode = df0[['code']]
lcode = list( df0['code'])
df0['date'] = pd.to_datetime(df0['date'])
# print(df.loc[0]['code'])
# 调用具体位置的数据
# 返回的是dataframe类型
# a = df0[df0['code']=='002317.SZ']
# a = df0['code']返回的是series类型
'''a = pd.DataFrame()
for i in lcode:
ldf = df0[df0['code']==i].reset_index().drop('index',axis=1)
#添加新列时,series类型自动填充空值
a[i] = ldf['date']'''
# a.loc[0]['002317.SZ'] = 123 错误做法,key=0
# print(a.loc[0]['002317.SZ'])
event = list(df0['date'])
# for i in lcode:
# ldf = df0[df0['code']==i]
# event.append(list(ldf['date']))
# del event[0]
import tushare as ts
token = '2f4f20d8b2fb57e033a820d04954b6f8a33f5a44c18b806189a802adsee'
pro = ts.pro_api(token)
'''全指医药指数的日期及对应的日收益率'''
dfzs = pro.index_basic(market='SSE')
#获取000991全指医药(263)指数
dfyy = pro.index_daily(ts_code='000991.SH', start_date='20130101', end_date='20211630')
df_index = dfyy[['trade_date', 'pct_chg']]
df_index['trade_date'] = pd.to_datetime(df_index['trade_date'])
#sort_value
df_index = df_index.sort_values("trade_date")
#reset_index()重置索引,0,1,2,3
#删除index列
df_index = df_index.reset_index().drop("index", axis=1)
#将涨跌幅转化为百分数对应的小数
df_index['pct_chg'] = df_index['pct_chg'] / 100
# df_index.to_excel('医药指数.xlsx')
'''函数作用:
获取某一只股票的交易日期及对应的日涨幅d0;
选出该股票对应日期的日涨幅d1
将d1与df_index合并为df_final
'''
def getdf_final(cd):
d2= pro.daily(ts_code=cd, start_date='20190101', end_date='20210630')
d0 = d2[['trade_date', 'pct_chg']]
d0.columns = ['trade_date', 'return']
#df_index1 = df[['trade_date', 'return']]
#调整日期格式为pandas格式,并按照日期进行排序
d0['trade_date'] = pd.to_datetime(d0['trade_date'])
d0 = d0.sort_values("trade_date")
#reset_index()重置索引,0,1,2,3
#删除index列
d0 = d0.reset_index().drop("index", axis=1)
#将涨跌幅转化为百分数对应的小数
d0['return'] = d0['return'] / 100
#获取美的集团2013-01-01至2020-02-20的日涨幅数据
d1= d0[(d0['trade_date'] >= '2014-01-01') & (d0['trade_date'] <= '2021-06-30')].copy()
#股票涨跌幅和市场涨跌幅
#以左侧或d1为基础,交易日为关键值进行合并,df_index没有的值填充nan
df_final0 = d1.merge(df_index, on='trade_date', how='left')
return df_final0
from sklearn.linear_model import LinearRegression#机器学习中的线性回归
'''函数作用:
计算预期报酬率,CAPM资本市场定价模型,线性回归
x,y为预测期的指数日回报率和个股日回报率,线性回归出相应的函数
pre_X是窗口期的指数日回报率
最终带入回归函数算出预测指数回报率
'''
def get_OLS(X, y, pre_X):
linear_m = LinearRegression().fit(X, y)#基于数组x和y建立回归模型
# r_2 = linear_m.score(X, y)#值越接近1越好,拟合优度越好。
# print(f"构建模型,拟合优度为{round(r_2*100, 2)}%")
# print(f"y = {round(linear_m.intercept_,3)} + {round(linear_m.coef_[0],3)}Rm + e")
return linear_m.predict(pre_X)
'''
异常收益率的计算
'''
def get_data(event):
# print("事件日为: ", event)
q, h = df_final[df_final['trade_date'] == event].index[0] -3, df_final[df_final['trade_date'] == event].index[0] +3
target = df_final.loc[q:h].copy()
#窗口期
estimate_df = df_final.loc[q-110:q-11]
#估计期
X = estimate_df[['pct_chg']]
#估计期深证综合指数涨幅
y = estimate_df['return']
#估计期个股的涨幅
predict_X = target[['pct_chg']]
#窗口期的全职医药指数涨幅
target['E(Rt)'] = get_OLS(X, y, predict_X)
#预期收益率的计算
target['ARt'] = target['return'] - target['E(Rt)']
#异常收益率 = 实际收益率 -预期收益率
target['CARt'] = target['ARt'].cumsum()
#累计异常收益率 = 异常收益率在窗口期的求和
target = target.reset_index().drop('index',axis=1)
return target
# df_final = getdf_final('002950.SZ')
# car = get_data(event[0])
# m = car.loc[11:20]['CARt']
car = pd.DataFrame()
ar_car=pd.DataFrame()
for i in range(len(lcode)):
df_final = getdf_final(lcode[i])
car0 = get_data(event[i])
car0["firm"]=lcode[i]
car0["event_date"]=event[i]
car0["interval_days"]=(car0["trade_date"]-car0["event_date"])
car0["interval"]=pd.Series(range(-3,4))
ar_car=ar_car.append(car0)
car[lcode[i]] = car0.loc[0:6]['CARt']
plt.rcParams['savefig.dpi'] = 600 #图片像素
plt.rcParams['figure.dpi'] = 600 #分辨率
car0.set_index('interval')[['ARt', 'CARt']].plot()


================== 持续更新中 ==================
生
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创
创
如
注
K
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新
U
F
导
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。