【论文笔记1_超分辨】(RDN)Residual Dense Network for Image Super-Resolution
文章目录
- Abstract
- 1. Introduction
-
- 1.1 部分现有方法:
- 1.2 存在的问题:
- 1.3 解决方法
- 1.4 主要贡献
- 2. Related Work
-
- 2.1 插值LR作为输入的网络
- 2.2 直接将LR作为输入的网络
- 2.3 引入Dense
- 3. Residual Dense Network
-
- 1. 浅层特征提取网络(SFENet)
- 2. 残差密集块(RDBs)
- 3. 密集特征融合(DFF)
- 4. 上采样网络(UPNet)
- 4. Discussion
-
- 4.1 RDN与DenseNet的区别
- 4.2 RDN与SRDenseNet的区别
- 4.3 RDN与MemNet的区别
- 5 数据集
- 6 Conclusions
-
-
- 【其他超分辨方向论文】
-
文章链接:(CVPR 2018)Residual Dense Network for Image Super-Resolution
代码链接:
https://github.com/yulunzhang/RDN(torch)
https://github.com/hengchuan/RDN-TensorFlow
Abstract
深层CNN拥有提取多层次特征的能力,最近在图像超分辨(SR)领域取得了不错的进展。然而,大多数CNN-based的SR模型不能很好地利用这些来自LR的各级特征,导致相对较低的性能。在本篇文章中,我们提出了一种全新的残差密集网络(Residual Dense Network,RDN)以解决图像SR中的这一问题。RDN能够充分利用所有卷积层中的各个层次信息。
具体地,我们提出了残差密集块(Residual Dense Block,RDB),通过将卷积层密集连接的方式提取丰富的局部特征。RDB还允许从先前所有RDB的状态直接连接到当前RDB中的所有层,从而形成了连续记忆(contiguous memory,CM)机制。
RDB中的局部特征融合的使用可以减少多余的特征,使网络训练更稳定。在充分得到稠密的局部特征后,采用全局特征融合的方法对全局多层次特征进行联合自适应学习。在具有不同退化模型的基准数据集上的实验表明,与现有的state-of-the art方法相比,RDN取得了更佳的性能。
1. Introduction
单图像超分辨(SISR)旨在通过低分辨图像(LR)生成视觉效果更好的高分辨图像(HR)。SISR能用在安防、监控图像、医学影像、图像生成等计算机视觉任务。实际上SR是一个病态的问题,因为对于任何LR输入都有多种解决方案(一对多)。
已有的SR方法主要有三种:
- 基于插值[40]
- 基于重建[37]
- 基于学习[28, 29, 20, 2, 21, 8, 10, 31, 39]
1.1 部分现有方法:
- Dong 等人在ECCV2014提出的SRCNN(DL应用在SR领域的开山之作);
- Kim 等人根据SRCNN的不足在CVPR2016分别提出了VDSR(增大感受野、残差学习和高学习率、mutil-scale)和DRCN(递归),使网络更好训练;
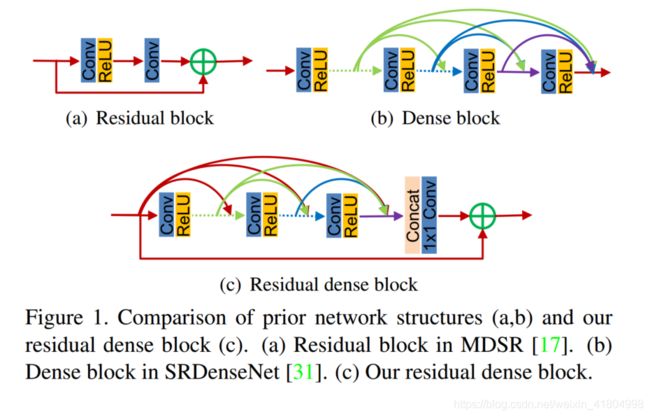
- Lim 等人在CVPR2017中,使用残差块 (图1(a)) 构建了EDSR(very wide)和MDSR(very deep),该方法还赢得了当年CVPR Workshops的超分辨比赛——NTIRE2017的冠军;
- Tai 等人提出了包含递归单元和门控单元的记忆模块,构建了MemNet。
1.2 存在的问题:
问题1:这些方法都没有充分利用每一个卷积层中的信息。
尽管MemNet中的门控单元可以提供短期记忆,但是局部卷积层不能直接访问后续层,很难说记忆模块充分利用了里面所有层的信息。
问题2:忽视了多层次特征(hierarchical features)。
图像中的物体有不同的尺寸、视角、纵横比,一个非常深的网络的多层次特征(hierarchical features)能为重建提供更多线索。然而,大多数当前的DL方法(VDSR、LapSRN、EDSR等)都忽视了这种多层次特征。
尽管记忆模块能够从之前的记忆块中获得信息,但这些多级信息不是从原始LR中得到的——MemNet将LR插值到目标SR的尺寸作为输入,而不是直接输入LR。这一步骤使得:
- 增加了计算复杂度——计算量是直接输入LR的四倍;
- 丢失了LR中的一些细节。
Tong等人在图像 SR 中引入了密集块 (图1(b)),并采用了相对较低的增长率。根据实验,更高的增长率能更进一步提升网络的性能。
1.3 解决方法
为了解决以上问题,本文提出了残差密集网络(Residual Dense Network, DRN)。通过残差密集块RDB (图1(c)),RDN网络能够充分利用所有的多级特征。
1.4 主要贡献
文章的主要贡献如下:
- 提出了统一的框架RDN,以解决不同退化模型下的高分辨SR任务。该网络能够充分利用原始LR的所有多级特征。
- 提出了残差密集块(RDB),不仅可以通过连续记忆(CM)机制获取先前的RDB的状态,还可以通过局部密集连接充分利用所有的卷积层。最后,通过局部特征融合(LFF)自适应地保留累积的特征。
- 采用全局特征融合(GFF),将所有RDB块的输出( F 1 F_1 F1~ F d F_d Fd)都与经浅层特征提取的LR(即 F − 1 F_{-1} F−1)进行融合。
2. Related Work
2.1 插值LR作为输入的网络
- SRCNN(2014): Dong 等人在ECCV2014提出的SRCNN(DL应用在SR领域的开山之作),在经过插值的LR和对应的HR之间建立了一个端到端的映射。该网络通过增加网络的深度、共享权重从而提升了效果;
- VDSR(2016)、IRCNN(2017): Kim 等人在CVPR2016提出的VDSR、Zhang等人在CVPR2017提出的IRCNN,通过堆叠更多带有残差学习的卷积层提升了网络的深度;
- DRCN(2016): Kim等人(也就是上面VDSR的作者)在CVPR2016提出的DRCN,首次在SR问题中引入了递归学习,用于深度网络中的参数共享;
- DRRN(2017)、MemNet(2017): Tai等人分别在CVPR2017和ICCV2017提出的DRRN和MemNet,同样使用了递归块用于构建更深的网络。
以上的网络都是将LR插值到目标HR的尺寸作为网络输入的,这种预处理步骤:
- 一方面增加了计算复杂度(×4);
- 另一方面使原始输入过度光滑、模糊,丢失了一些细节信息。
2.2 直接将LR作为输入的网络
- FSRCNN(2016): Dong等人在ECCV2016提出的SRCNN,直接将原始LR作为网络的输入,并且引入了反卷积层,用于上采样到目标分辨率。(SRCNN的作者,香港中文大学Dong Chao本人对SRCNN进行的改进)。
- ESPCN(2016): She等人在CVPR2016提出的ESPCN,使用子像素卷积(sub-pixel convolution) upscale到HR。
- SRResNet(2017)、EDSR(2017): Ledig等在CVPR2017提出的SRResNet(也就是SRGAN)、Lim等人在CVPR Workshops 2017提出的EDSR(NTIRE2017冠军),也都使用了子像素卷积以及残差学习;
上面的方法都是在LR空间内提取特征,然后将最终的LR特征经反卷积或子像素卷积上采样到目标分辨率的。这样一来这些网络具有了实时SR(例如FSRCNN、ESPCN)的能力,或者能够构建更深/更宽的网络(例如SRGAN、EDSR)。
2.3 引入Dense
以上的网络都都是线性地堆叠Conv层或Res块,没有充分利用每个Conv层中的信息(因为仅采用LR空间中最后一层的Conv进行上采样)。
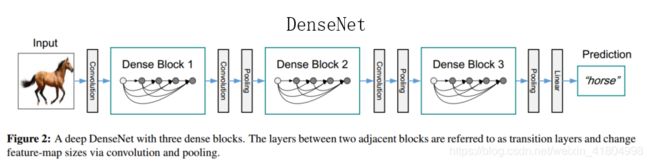
- DenseNet(2017): Huang等人在CVPR2017上提出了DenseNet,允许同一个密集块内的任意两个卷积层直接进行连接。
以上的DL-based SR方法都取得的成果都十分重要,但是它们都没有从LR中充分获得有用的多层级特征(Hierarchical features)。本文提出的residual dense network(RDN)能够高效地提取并自适应地融合LR空间中所有层的特征。
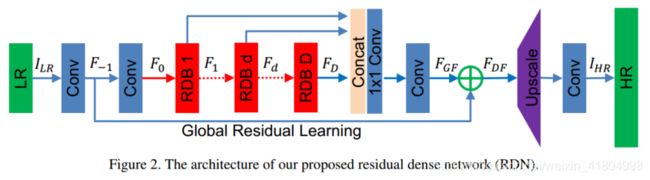
3. Residual Dense Network
网络结构:
RDN主要由四部分组成:
1. 浅层特征提取网络(SFENet)
这部分没什么好说的,就是网络最开始的那两个卷积层。
2. 残差密集块(RDBs)

【残差密集块RDB = 密集连接层 + 局部特征融合(LFF)+ 局部残差】,形成了连续记忆机制(Contiguous Memory)。
Dense: 所谓连续记忆机制,个人理解其实就是可以将第 d − 1 d-1 d−1个RDB块的输出直接输入到第 d d d个RDB块中的每一层去(见上图dense部分的红线所示),经过dense的作用,可以将 F d − 1 F_{d-1} Fd−1, F d , 1 F_{d,1} Fd,1, F d , c F_{d,c} Fd,c, F d , C F_{d,C} Fd,C的特征都利用起来。
局部特征融合(Local feature fusion) 即RDB中的那个concat,能够将前一个RDB的输出 F d − 1 F_{d-1} Fd−1、当前RDB F d F_{d} Fd 中每一层得到的状态融合通过concat在一起。然后,再利用 1 × 1 1×1 1×1卷积对concat降低通道数,简化数据。
局部残差学习(Local residual learning) 由于RDB中存在多个卷积层,因此引入局部残差学习以进一步改善信息流。
3. 密集特征融合(DFF)
通过一系列RDBs提取了局部密集特征后,进一步提出密集特征融合(DFF),从全局的角度挖掘多层次特征(hierarchical features)。
DFF由全局特征融合(GFF)和全局残差学习(GRL)两部分组成。
全局特征融合(Global Feature Fusion)
如上面Figure 2. 所示,全局特征融合即:
- 把多个RDBs的输出( F 1 , F d , … , F D F_1, F_d, \dots, F_D F1,Fd,…,FD)concat在一起;
- 再经过一个 1 × 1 1\times1 1×1 Conv层,将这一系列不同level的特征自适应地融合在一起;
- 再通过 3 × 3 3\times3 3×3 Conv层,进一步提取特征得到 F G F F_{GF} FGF,用接下来的全局残差学习(GRL)。
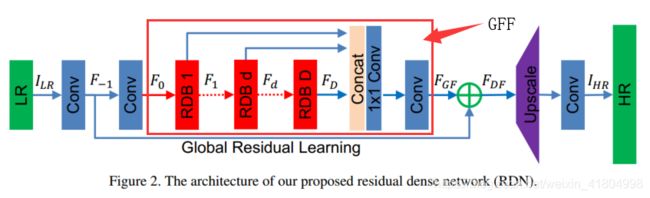
全局残差学习(Global Residual Learning)
全局残差学习就是上面的Figure 2. 中,将通过第一个Conv层得到的浅层特征图 F − 1 F_{-1} F−1,与上面全局特征融合GFF得到的 F G F F_{GF} FGF作element-wise的相加,得到 F D F F_{DF} FDF。
4. 上采样网络(UPNet)
这部分就没什么好说的了,就是一个上采样+卷积操作,最终输出HR结果 I H R I_{HR} IHR。
4. Discussion
4.1 RDN与DenseNet的区别
- DenseNet主要应用在目标检测等high-level的CV任务中,而RDN是专为相对low-level的SR任务设计的。所以相比于DenseNet,RDN拿掉了batch nomalization (BN) 层,降低了计算量;
- RDN同样拿掉了DenseNet中的pooling层,因为池化会丢失一些像素级的信息;
- 在DenseNet中,相邻的两个Dense Block之间是有Conv+Pooling组成的过渡层的,而在RDN中,则是利用局部残差学习将dense连接层与LFF结合在一起。
4.2 RDN与SRDenseNet的区别
- SRDenseNet使用的是DenseNet中的传统dense block,而RDB从3个方面进行了改进: ①连续记忆机制(CM)可以使先前的状态直接与当前RDB中的所有层直接连接;②得益于局部特征融合(LFF),RDB可以使用更大的学习率;③局部残差学习(LRL)的应用增大了信息和梯度的流动。
- 在RDB之间没有密集连接。 由于RDBs已经很好地提取了局部特征,所以没有在块直接采用密集连接,取而代之的是全局特征融合(GFF)和全局残差学习(GRL)。
- SRDenseNet使用的是 L 2 L_2 L2 loss,而RDN使用的是 L 1 L_1 L1loss。
4.3 RDN与MemNet的区别
- (MemNet用的 L 2 L_2 L2 loss。)
- MemNet需要将bicubic 插值后的LR作为输入,而RDN不用,降低了计算量,提升了性能;
- MemNet中的记忆block由递归和门控单元组成。记忆block中的大多数层都不能接收先前block的输出信息,而RDBs之间则有信息流交互;
- MemNet中的记忆block不能充分利用中间block的信息。
5 数据集
训练:
采用的数据集为2K的高清RGB图像数据集——DIV2K,该数据集的训练集有800张图片,验证集有100张图片,测试集有100张图片。
测试:
使用了5组标准benchmark数据集:Set5,Set14,B100,Urban100,Manga109。
Degradation Models
分别使用了3种降阶模型对HR的DIV2K进行处理,来模拟LR图片。
- BI: 用Matlab的imresize函数进行bicubic下采样,缩小比例为x2,x3,x4;
- BD: 采用高斯核大小为 7 × 7 7\times7 7×7、标准差为1.6的高斯滤波处理,下采样的比例为x3;
- BN: 先bicubic下采样,再加30%的高斯噪声。
6 Conclusions
DRN在SR任务上取得了很好的效果,性能超越了目前(2018)的state-of-the-art方法。
【其他超分辨方向论文】
【1】(RCAN)Image Super-Resolution Using Very Deep Residual Channel Attention Networks
【2】(IDN)Fast and Accurate Single Image Super-Resolution via Information Distillation Network
【3】(DRN)Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution