flink1.12.2实现kafka流数据与hive动态维表信息关联
上次发的是1.10的flink,当时版本的flink不支持hive数据更新后依然以最新数据和kafka关联。
本次以1.12.2版本,java代码形式实现“动态”关联。下方是这个tiny demo的依赖和代码。
依赖:
org.apache.flink flink-clients_2.12 1.12.2 org.apache.flink flink-streaming-java_2.12 1.12.2 org.apache.flink flink-connector-kafka_2.12 1.12.2 org.apache.flink flink-table-api-scala_2.12 1.12.2 org.apache.flink flink-table-api-java-bridge_2.12 1.12.2 org.apache.flink flink-table-planner_2.12 1.12.2 org.apache.flink flink-table-planner-blink_2.12 1.12.2 org.apache.flink flink-table-api-scala-bridge_2.12 1.12.2 org.apache.flink flink-connector-hive_2.12 1.12.2 org.apache.hive hive-exec 3.1.0 org.apache.flink flink-csv 1.12.2 org.apache.flink flink-cep-scala_2.12 1.12.2 org.apache.flink flink-table-common 1.12.2 org.apache.hadoop hadoop-mapreduce-client-core 2.7.2 org.apache.hadoop hadoop-common 2.7.2 org.apache.hadoop hadoop-mapreduce-client-common 2.7.2 org.apache.hadoop hadoop-mapreduce-client-jobclient 2.7.2
代码:
package StreamBatch_fh;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
//import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.types.Row;
/**
* FLINK 1.12.2
* HIVE 3.1.2
* KAFKA 2.4
* target: kafka流和hive关联后sink 到另一个topic中
*/
public class FlinkHiveMain {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool para = ParameterTool.fromArgs(args);
String host = para.get("host");
Integer port = para.getInt("port");
String topic = para.get("topic");
String hivedir = para.get("hivedir");
/**
创建EnvironmentSettings 和 tableEnv
*/
EnvironmentSettings envSet = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(env, envSet);
// tableEnv里添加hive相关的参数
streamTableEnvironment.getConfig().getConfiguration().setString("table.dynamic-table-options.enabled", "true");
/**
创建kafkasource
注意1.11后开始不再用tableEnv..connect 创建表
注意:kafka表和hive表 创建后都会在hive侧生成一个新表
*/
String name = "myhive";
String defaultDatabase = "flink01";
// String hiveConfDir = "D:\\ocspx_20210616\\flink0810\\flink12hive\\src\\main\\resources";
String hiveConfDir = hivedir;
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
//注册catalog
streamTableEnvironment.registerCatalog("myhive", hive);
//使用catalog
streamTableEnvironment.useCatalog("myhive");
String dropoldkafkatable = String.format("DROP table if exists UserScores");
streamTableEnvironment.executeSql(dropoldkafkatable);
String createKafkaTable = String.format(
"CREATE TABLE UserScores (name1 STRING,scoure DOUBLE,zoneCode STRING,proctime as PROCTIME())\n" +
"WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'test_in1',\n" +
" 'properties.bootstrap.servers' = '10.1.236.92:6667',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'format' = 'csv',\n" +
//" 'scan.startup.timestamp-millis' = '1605147648000',\n" +
// " 'csv.field-delimiter' = '\t',\n" +
" 'scan.startup.mode' = 'latest-offset'\n" +
")");
//创建表 也就是上方那一段sql
TableResult tableResult = streamTableEnvironment.executeSql(createKafkaTable);
//
Table table1 = streamTableEnvironment.sqlQuery("select * from UserScores");
//把表转为流 再打印
DataStream gg = streamTableEnvironment.toAppendStream(table1, Row.class);
gg.print("kafka源数据");
// String createHiveTable = String.format("");
/**
* 引入hive
* hive-conf-dir: xxx # contains hive-site.xml
*/
// 方言改为hive
streamTableEnvironment.getConfig().setSqlDialect(SqlDialect.HIVE);
// ??table.exec.hive.fallback-mapred-reader=true
/**
* hive表的第一种方式 “从现有的hive表整 诞生一个用来和kafka关联的表”
* 20211122
*
*/
// Table table2 = streamTableEnvironment.sqlQuery(
// "select * from dis_users_1118a /*+ OPTIONS('streaming-source.enable'='false','streaming-source.partition.include' = 'all','streaming-source.monitor-interval'='2 min','lookup.join.cache.ttl'='2 min') */" ); /*('scan.startup.mode'='earliest-offset',)*/
// String hive1 = String.format("select * from dis_users_1118a /*+ OPTIONS('streaming-source.enable'='false','streaming-source.partition.include' = 'all','streaming-source.monitor-interval'='2 min','lookup.join.cache.ttl'='2 min') */");
//下方where条件里 仿佛左右两个表不能有重复的字段
// Table tableJoin = table1.join(table2).where("name1 = name");
// streamTableEnvironment.toAppendStream(table2, Row.class).print("当前hive数据");
// streamTableEnvironment.toAppendStream(tableJoin, Row.class).print("关联后");
// DataStream gg2 = streamTableEnvironment.toAppendStream(table2, Row.class);
// gg2.print("hive中创建的users表");
/**
* hive表的第二种方式 “create一个hive没有的表再和kafka进行关联”
*/
String dropoldHivetable = String.format("DROP table if exists dimension_table");
streamTableEnvironment.executeSql(dropoldHivetable);
/** 去掉的时间字段 可以根据具体场景判断要不要 有没有都不影响关联hive维表 " update_time TIMESTAMP(9),\n" +
'lookup.join.cache.ttl' = '2 min'这个参数非常重要 到点就重新把hive表数据全部缓存到slot里 所以数据量大的时候需要考虑这个值 或者考虑“最新分区”更新形式
下方hive里的维表dimension_table 没有完全和官网样例一样 不算商品页面pv那些 只是用来测试关联 所以值长什么样子是乱写的 -_-
*/
//
String hive_create = String.format("CREATE TABLE dimension_table (\n" +
" product_id STRING,\n" +
" user_name STRING,\n" +
" unit_price DECIMAL(10, 4),\n" +
" pv_count BIGINT,\n" +
" like_count BIGINT,\n" +
" comment_count BIGINT,\n" +
" update_user STRING\n" +
") TBLPROPERTIES (\n" +
" 'streaming-source.enable' = 'false', \n" +
" 'streaming-source.partition.include' = 'all', \n" +
" 'lookup.join.cache.ttl' = '1 min'\n" +
")");
streamTableEnvironment.executeSql(hive_create);
/**插入数据样例 可以省略 即假设hive表每次都是随着作业重新运行而删除并新建 再插入一行初始数据
* insert
*/
String Insert = String.format(" INSERT INTO dimension_table values('Bill','Bill',9.22,20211122,1122,2021,'hh')");
streamTableEnvironment.executeSql(Insert);
/**常规 JOIN 无法实现hive里数据更新后也能被flink获取并随kafka数据关联出
*/
// String join = String.format("select * from UserScores join dimension_table ON UserScores.name1 = dimension_table.product_name");
// streamTableEnvironment.sqlQuery(join).printSchema();
/**Temporal JOIN
*/
String join2 = String.format("select * from UserScores join dimension_table FOR SYSTEM_TIME AS OF UserScores.proctime ON UserScores.name1 = dimension_table.user_name");
Table t = streamTableEnvironment.sqlQuery(join2);
streamTableEnvironment.toAppendStream(t, Row.class).print("输出关联结果");
try {
env.execute("hive test01");
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 注意kafka流表和hive维表,都会在对应catalog下创建出各自hive表
*/
运行效果:
打包好后提交到yarn上:
/usr/hdp/3.1.0.0-78/flink/bin/flink run -c StreamBatch_fh.FlinkHiveMain -m yarn-cluster -yt /data/hh/app_jar/hive_join/resources /data/hh/app_jar/hive_join/flink12hive-1.0-SNAPSHOT.jar --port 6667 --host 10.***.92 --topic test_in1 --hivedir /data/hh/app_jar/hive_join/resources
提交作业后,给hive维表插入1条数据,加上代码里默认插入的1条,共2条数据:

此时给一条对应hive中存在的数据:
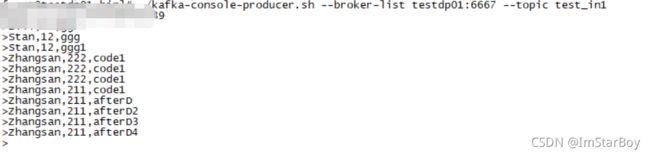
输出为:
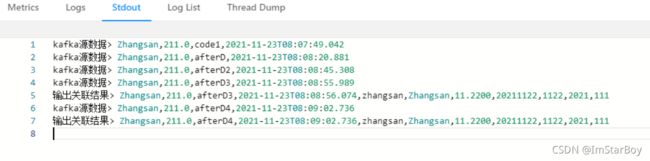
因为hive更新后,要等一个ttl的时间,所以并不是立即就能带出关联到的维表数据。