David Silver强化学习公开课自学笔记——Lec1强化学习简介
本笔记摘自知乎博主旺财的搬砖历险记和叶强,仅用于自学
1.背景介绍
(1)背景
强化学习是多学科多领域交叉的产物,本质是解决决策问题,即学会自动决策,在各个领域体现不同,但都归结为人类如何且为什么能做出最优决策:
- 计算机科学领域体现为机器学习算法
- 工程领域体现为决定序列行为来进行最优控制
- 在神经科学领域体现为理解人类大脑做出决策,主要研究反馈系统
- 在心理学领域研究动物如何做出决策、动物的行为由什么导致
- 在经济学领域体现博弈论的研究。

(2)原理
- 强化学习作为一个序列决策问题,连续选择一些行为,从这些行为完成后得到最大的收益作为最好的结果。
- 在没有任何标签告诉算法如何做的情况下,先尝试作出一些行为,然后得到一个结果,通过判断这个结果来对之前的行为进行反馈。
- 通过这个反馈来调整之前的行为,通过不断调整算法,学习到在什么情况下选择哪种行为可以得到最好的结果。
(3)强化学习与其他机器学习的区别
1)RL的挑战和考虑
《Reinforcement Learning: An Introduction》书中指出
- RL领域存在一个挑战,即需要在探索未知的领域(exploration)和利用现有的知识(exploitation)之间做权衡
One of the challenges that arise in reinforcement learning, and not in other kinds of learning, is the trade-off between exploration and exploitation.
- RL考虑,以目标为导向的agent,与不确定的环境之间交互的整个问题,其他机器学习更多将大问题分解成子问题,且不考虑它们如何使用,所以存在很多限制。
Another key feature of reinforement learning is that it explicitly considers the whole problem of a goal-directed agent interacting with an uncertain environment.

2)与监督学习的区别
- There is no supervisor, only a reward signal.
- 监督学习有标签告诉算法输入对应何种输出(如分类、回归问题)
- 强化学习没有标签,只有一系列行为后最终反馈回来的reward signal来判断当前行为好坏
- Feedback is delayed, not instantaneous.
- RL的结果反馈有延时,有时需要走好多步才知道之前某步的好坏
- 监督学习的选择好坏立即反馈给算法
- Time really matters (sequential, non i.i.d data)
- RL具有强时间相关性
- 作为序列决策问题,属于非独立同分布数据[[数学基础#7.独立同分布]]
- Agent’s actions affect the subsequent data it receives
- RL的输入总在变化,每当算法做出一个行为,它就影响下一次决策的输入
- 监督学习中的输入是独立分布的
3)与非监督学习的区别
《Reinforcement Learning: An Introduction》书中指出
非监督学习主要是为了挖掘无标签数据之间的内部关联(如聚类问题),RL则是为了最大化奖励
Reinforce learning is also different from what machine learning researchers call unsupervised learning, which is typically about finding structure hidden in collections of unlabeled data.
4)举例
数据:人脸图片
- 监督学习:给定标签(人名),学习这些人脸是谁的脸。监督学习要求带标签的数据,如何标注数据是一门学问。数据较难获得。
- 非监督学习:没有标签,判断哪些图片是同一个人。数据数量庞大容易获得。
- 强化学习:没有标签信号,只有奖励信号。即时奖励:只告诉分对还是分错;延迟奖励:分类完毕以后,得到总分数。
2.RL构成
(1)奖励Rewards
1)RL奖励假设
可以没有观测,但是必须有奖励!!!奖励是RL区别于其他机器学习的标志特征。
- 奖励 R t R_t Rt是一个标量反馈信号
- 反映了agent在时刻t行为的好坏
- agent的目的是最大化累积回报
RL奖励假设:所有的目标都可以表示为最大化期望累计回报
【如果一个问题不满足奖励假设,就不能用强化学习解决!】
2)Rewards举例
| 场景 | +奖励 | -奖励 |
|---|---|---|
| 无人机和无人车控制 | 按预定轨迹运行 | 碰撞或翻车 |
| 下围棋 | 赢了 | 输了 |
| Atari游戏 | 得分增加 | 得分减少 |
| 机械臂控制 | 抓住东西 | 没抓住东西 |
只有正奖励,或只有负奖励,也可以。
(2)序列决策 Sequential Decision Making
- 目标:挑选动作,以最大化将来的累计回报
- 动作可能会产生长期后果
- 奖励会有延迟(eg.下围棋只有在最后才能获得奖励)
- 可能牺牲即时回报来获得长期回报更高,即贪心策略不可行。
(3)智能体和环境

- agent
- 强化学习需要优化的部分,是我们能够精确控制的部分
- environment
- 我们不能直接控制的部分

- 我们不能直接控制的部分
- 在每个步骤 t t t,agent的表现:
- 执行动作 A t A_t At,如决定围棋的落子位置,机器人下一步怎么走
- 接受观察 O t O_t Ot,如摄像头拍摄到一副快照——当前场景
- 接收标量奖励 R t R_t Rt,表明agent在第t步做出的决策有多好/坏
- 注:一开始agent不知道环境会对不同action做出什么反应,环境会通过observation告诉agent当前的环境状态,并根据可能的最终结果反馈给agent一个reward。如,围棋棋面是一个environment,根据当前的棋面估计一下黑白双方输赢的概率。
- 在每个步骤 t t t,环境的表现:
- 接收行为 A t A_t At
- 发出观察 O t O_t Ot
- 发出标量奖励 R t R_t Rt
- t t t在env中递增
- agent→action→environment是唯一一个可以影响环境的chanel
(4)历史和状态 History and State
1)历史
- 历史是一连串观察、动作、奖励的序列: H t = O 1 , R 1 , A 1 , … , A t − 1 , O t , R t H_t=O_1,R_1,A_1,\ldots,A_{t-1},O_t,R_t Ht=O1,R1,A1,…,At−1,Ot,Rt
- 这个序列定义了agent的经验,经验用于加固数据
- 包含了截止到时刻 t t t时的所有观察变量
- 机器人或agent的运动流
- 下一步发生什么取决于历史
- agent选择actions
- environment选择observations/rewards
2)状态
状态是历史的一种表达,用于预测下一步要发生什么。本质上状态是历史的一个函数: S t = f ( H t ) S_t=f(H_t) St=f(Ht)
a)environment状态
环境状态 S t e S_t^e Ste是环境的内部表达
- 包括环境用来决定下一个观测/奖励的所有数据
- 通常对个体并不完全可见
- 即使环境对个体是完全可见的,这些信息也可能包含一些无关信息
b)agent状态
agent状态 S t a S_t^a Sta是agent的内部表达
- 包括agent能使用的决定未来动作的所有信息
- agent状态是强化学习算法可以利用的信息
- 它可以是历史的一个函数 S t a = f ( H t ) S_t^a=f(H_t) Sta=f(Ht)
c)information状态
又称Markov状态,包含所有历史中有用的信息
一个状态 S t S_t St是Markov当且仅当: P [ S t + 1 ∣ S t ] = P [ S t + 1 ∣ S 1 , … , S t ] \mathbb{P}[S_{t+1}\vert S_t]=\mathbb{P}[S_{t+1}\vert S_1,\ldots,S_t] P[St+1∣St]=P[St+1∣S1,…,St],即随机过程的某事件只取决于它的上一事件,与初始状态无关
- 相对于给定的现在,未来是独立的 H 1 : t → S t → H t + 1 : ∞ H_{1:t}\rightarrow S_t\rightarrow H_{t+1:\infty} H1:t→St→Ht+1:∞
- 一旦 t t t时刻的信息状态已知,历史信息可以丢弃不用
- 状态是对未来的充分统计
- 环境状态 S t e S_t^e Ste是Markov的
- 历史 H t H_t Ht是Markov的
d)环境状态和智能体状态的区别
| 场景环境 | 环境状态 | 智能体状态 |
|---|---|---|
| 机器人控制 | 所有机械零件的参数、状态等 | 传感器获得的数据 |
| 3D游戏 | 所有游戏参数和对手信息 | 玩家能看到的观测 |
- 对于智能体来说,环境状态是未知的,智能体状态是已知的
- 智能体通过自身状态做出相应动作
(5)环境
1)完全可观测的环境
Fully Obserable Environment
完全可观测性:agent直接观察环境状态 O t = S t a = S t e O_t=S_t^a=S_t^e Ot=Sta=Ste
- 智能体对环境的观测=环境状态=智能体状态
- 这是强化学习的主要研究问题——马尔科夫决策过程(MDP)
2)部分可观测的环境
Partially Observable Environments
部分可观测性:智能体间接观察环境状态
- 举例
- 一个可拍照的机器人不知道它的绝对位置
- 一个交易员只能看到当前的交易价格
- 一个扑克牌玩家只能看到场上已经出过的牌和自己的牌
- 智能体状态≠环境状态
- 这是部分马尔科夫决策过程(POMDP)
- 智能体必须构建它自己的状态呈现形式 S t a S_t^a Sta,比如:
- 记住完整的历史 S t a = H t S_t^a=H_t Sta=Ht
- 不推荐
- Beliefs of environment state: S t a = P [ S t e = s 1 ] , … , P [ S t e = s n ] S_t^a=\mathbb{P}[S_t^e=s^1],\ldots,\mathbb{P}[S_t^e=s^n] Sta=P[Ste=s1],…,P[Ste=sn]
- 利用已有的经验数据,采用各种个体已知状态的概率分布作为当前时刻的个体状态
- Recurrent neural network: S t a = σ ( S t − 1 a W s + O t W o ) S_t^a=\sigma(S_{t-1}^aW_s+O_tW_o) Sta=σ(St−1aWs+OtWo)
- 无需概率,只根据当前的个体状态和个体观测,送入循环神经网络RNN中得到一个当前个体状态的呈现
- 记住完整的历史 S t a = H t S_t^a=H_t Sta=Ht
(6)动作
action是智能体主动和环境交互的媒介。action必须对环境起到一定的控制作用,尤其是对奖励。动作序列要能够影响agent的奖励值。
- action需要能够改变未来获得的奖励。
- 无效动作不能改变环境。有效动作才可以。
- 奖励的设置要能够被动作改变。
- 时间的流逝是不受改变的。
- 如果上述两点不满足,强化学习问题无解
3.RL Agent
(1)智能体
一个RL智能体由以下一个或几个部分组成:
- 策略Policy
- 智能体的动作函数
- 值函数Value function
- 状态或动作的评价
- 模型Model
- agent对环境的表示
1)策略Policy
策略是智能体的行动,也是智能体的核心
- 策略是从state到action的映射
- 表达形式
- 确定策略: a = π ( s ) a=\pi(s) a=π(s)
- 随机策略: π ( s ∣ a ) = P [ A t = a ∣ S t = s ] \pi(s\vert a)=\mathbb{P}[A_t=a\vert S_t=s] π(s∣a)=P[At=a∣St=s]
2)值函数Value function
v π ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … ∣ S t = s ] v_\pi(s)=\mathbb{E}_\pi[R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots\vert S_t=s] vπ(s)=Eπ[Rt+1+γRt+2+γ2Rt+3+…∣St=s]
- 值函数预测了当前状态下未来可能获得的奖励的期望
- 用来评价状态的好坏
- 用于选择action
3)模型Model
模型用于预测环境的表现,主要包含两部分
- P \mathcal{P} P预测下一个状态,状态转移模型: P S S ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] \mathcal{P}_{SS^{\prime}}^a=\mathbb{P}[S_{t+1}=s^{\prime}\vert S_t=s,A_t=a] PSS′a=P[St+1=s′∣St=s,At=a]
- R \mathcal{R} R预测下一个奖励(即时奖励),奖励模型: R S a = R [ R t + 1 ∣ S t = s , A t = a ] \mathcal{R}_{S}^a=\mathbb{R}[R_{t+1}\vert S_t=s,A_t=a] RSa=R[Rt+1∣St=s,At=a]
注: P \mathcal{P} P和 R \mathcal{R} R的预测可能是不精确的
(2)强化学习个体的分类
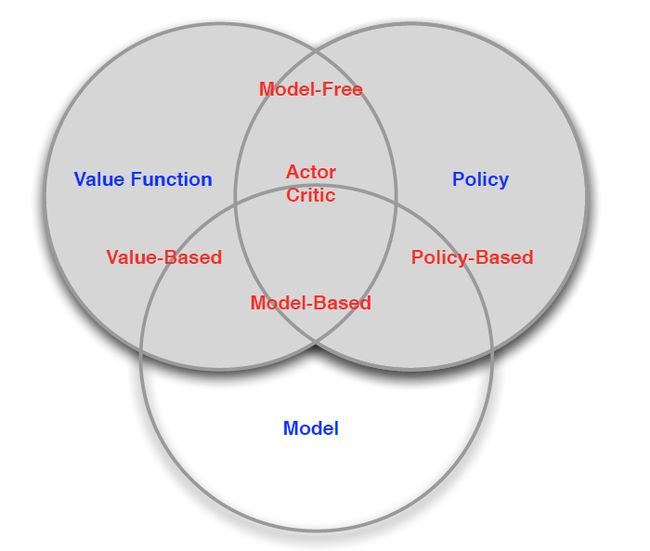
- 按环境分类
- 全观测环境下的RL
- 部分可观测环境下的RL
- 按智能体的成分分类
- 基于价值函数的Value Based
- 有值函数,没有直接的策略函数,策略函数由值函数间接得到
- 基于策略的Policy Based
- 无值函数,action直接由策略函数产生
- 演员-评判家形式的Actior-Critic
- 有值函数,也有策略函数,两者结合解决问题
- 基于价值函数的Value Based
- 按模型的有无分类
- 不基于模型的个体Model Free
- 没有模型,agent不试图了解环境如何工作,仅聚焦于价值和策略函数
- 基于模型的个体Model Based
- agent尝试建立一个描述环境运作过程的模型,以此来指导价值或策略函数的更新
- 不基于模型的个体Model Free
- 按使用的手段分类
- 传统强化学习
- 深度强化学习
4.RL里的问题
(1)学习和规划
制定序列决策的两类主要问题:
- 学习——reinforcement learning
- 环境初始时是未知的,个体不知道环境如何工作
- agent与环境交互
- agent改进自己的策略
- 规划——planning
- 环境模型已知
- agent无需与外部环境交互,使用模型进行计算
- agent改进自己的策略
常用的强化学习问题解决思路:先学习环境如何工作,学习得到一个模型后,利用这个模型进行规划。
举例
学习:玩游戏,最开始不知道规则,通过选择动作,看到像素和分数,从中学习。
规划:已知游戏规则,思考怎样玩分数最高。
(2)探索和利用
- RL是一种试错的学习方式,即trial-and-error
- 最开始不知道环境的工作方式,不清楚什么样的行为是对的,什么样的行为是错的。因此agent需要从不断尝试的经验中发现一个好的策略,并在这个过程中获得更多的奖励
- 在学习中,会有探索和利用之间的权衡
- 探索会放弃一些已知的reward信息,而尝试新的选择,即时新的选择可能reward不高
- 利用根据已知的信息最大化reward
(3)预测和控制
在RL里,需要先解决关于预测的问题,再在此基础上解决关于控制的问题。
- 预测:给定一个策略,评估未来
- 可以看成求解给定策略下的价值函数的过程
- 控制:找到一个最好的策略,最大化未来的奖励