wps两列数据分别作为xy轴_【python实战】用KNN算法实现数据分类和数据预测
导语:数据挖掘,又译为数据采矿,是指从大量的数据中通过算法搜索隐藏于其中信息的过程。本篇内容主要向大家讲述如何使用KNN算法进行数据分类和数据预测。
1、数据分类基础概念
数据分类就是相同内容、相同性质的信息以及要求统一管理的信息集合在一起,把不同的和需要分别管理的信息区分开来,然后确定各个集合之间的关系,形成一个有条理的分类系统。
举个最简单的例子:我们定义K线为三类:“上涨”:涨幅超过1%,“下跌”:跌幅超过1%,“震荡”涨跌幅不超过1%,获取沪深300指数过去250个交易日的K线,将数据进行分类:
p=get_price('000300.SH', None, '20180125', '1d', ['quote_rate'], True, None, 250, is_panel=1)n1=len(p[p['quote_rate']>1])n2=len(p[p['quote_rate']n3=len(p)-n1-n2print('上涨K线:{},下跌K线:{},震荡K线:{}'.format(n1,n2,n3))代码运行输出:
上涨K线:18,下跌K线:12,震荡K线:220
数据预测即用数据分类得出的模型对未知变量的预言。预言其目的是对未来未知变量的预测。假设我们用历史数据发现上涨股票平均比例,所有个股平均量比,这二个指标可以用来定义当天市场是上涨、下跌还是震荡。其特征如下:
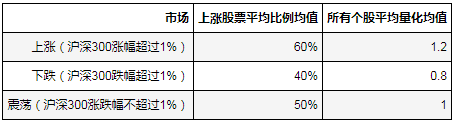
详细数据分布如下:
import matplotlib.pyplot as pltfig_size = plt.rcParams["figure.figsize"]fig_size[0] = 15fig_size[1] = 10x1 = np.random.uniform(0.5, 0.7 ,200)y1 = np.random.uniform(1.4, 1, 200)plt.scatter(x1,y1,c='b',marker='s',s=50,alpha=0.8)x2 = np.random.uniform(0.3,0.5,200)y2 = np.random.uniform(0.6,1,200)plt.scatter(x2,y2,c='r', marker='^', s=50, alpha=0.8)x3 = np.random.uniform(0.4,0.6,200)y3 = np.random.uniform(0.8, 1.2, 200)plt.scatter(x3,y3, c='g', s=50, alpha=0.8)代码运行输出:
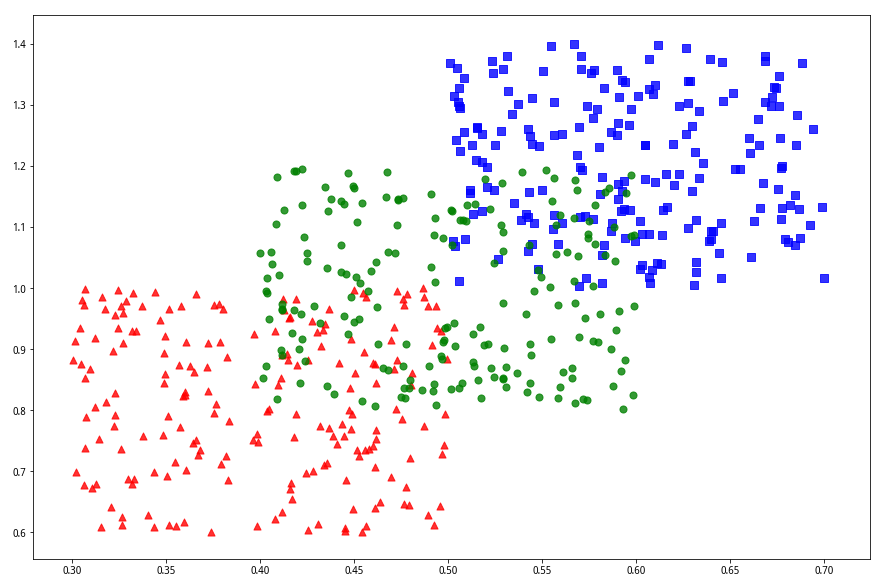
在我们完成分类模型后的下一个交易日,只给你们二个指标的具体数值:上涨股票比例为55%,所有个股平均量比1。请问当天的沪深300指数是上涨、下跌还是震荡?
2、KNN算法
我们需要解决上述分类和预测的问题,就需要依赖于数据挖掘的算法,本篇文章主要介绍KNN算法,一个常用又简单的数据分类和预测算法。
KNN算法核心函数:neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n-jobs=1),函数内n_neighbors参数是做分类时选取参考的数据量,默认为5个。其余参数选取为默认,课外自行了解原理。
开始之前,我们先导入KNN算法模块
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn import neighbors回到之前的详细数据分布
fig_size = plt.rcParams["figure.figsize"]fig_size[0] = 15fig_size[1] = 10x1 = np.random.uniform(0.5, 0.7 ,200)y1 = np.random.uniform(1.4, 1, 200)plt.scatter(x1,y1,c='b',marker='s',s=50,alpha=0.8)x2 = np.random.uniform(0.3,0.5,200)y2 = np.random.uniform(0.6,1,200)plt.scatter(x2,y2,c='r', marker='^', s=50, alpha=0.8)x3 = np.random.uniform(0.4,0.6,200)y3 = np.random.uniform(0.8, 1.2, 200)plt.scatter(x3,y3, c='g', s=50, alpha=0.8)代码运行输出:
在创建了一个 KNeighborsClassifier 类之后,需要给它数据来进行学习并分类。需要使用 fit() 拟合功能:neighbors.KNeighborsClassifier.fit(X,Y)
X 是一个 list 或 array 的数据,每一组数据可以是 tuple 也可以是 list 或者一维 array,但要注意所有数据的长度必须一样。当然,也可以把 X 理解为一个矩阵,其中每一横行是一个样本的特征数据。
Y 是一个和 X 长度相同的 list 或 array,其中每个元素是 X 中相对应的数据的分类标签。
KNeighborsClassifier 类在对训练数据执行 fit()后会根据函数内的algorithm参数,依据训练数据生成一个 kd_tree 或者 ball_tree。其中第一类是上涨,第二类
x_val = np.concatenate((x1,x2,x3))y_val = np.concatenate((y1,y2,y3))x_diff = max(x_val)-min(x_val)y_diff = max(y_val)-min(y_val)x_normalized = x_val/x_diffy_normalized = y_val/y_diffxy_normalized = list(zip(x_normalized,y_normalized))labels = [1]*200+[2]*200+[3]*200clf = neighbors.KNeighborsClassifier(30)clf.fit(xy_normalized, labels)代码运行输出:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=30, p=2,
weights='uniform')
注意:在分类时,我们对数据进行了标准化,主要是使得X轴和Y轴的数据间隔具有可比性,比如我们的上涨股票比例恒小于等于1,而量比甚至可能大于2,这样的话两个坐标轴没有可比性,间距不一致,因此我们需要进行标准化;具体标准化公式:最终值=初始值/(最大值-最小值)。
至此我们完成了数据分类,让我们来尝试数据预测!
1.近邻数据获取
我们尝试来获取(0.55,1)这个数据点周围的10个数据点
nearests = clf.kneighbors([(0.55/x_diff, 1/y_diff)], 10, False)nearests代码运行输出:
array([[565, 551, 557, 506, 174, 474, 503, 58, 401, 561]])结果显示:第[565, 551, 557, 506, 174, 474, 503, 58, 401, 561]个数据点
2.数据预测:
继续回答上述问题:上涨股票比例为55%,所有个股平均量比1。请问当天的沪深300指数是上涨、下跌还是震荡。
prediction = clf.predict([(0.55/x_diff, 1/y_diff)])prediction代码运行输出:
array([3])结果显示:该天沪深300指数属于第三类,震荡。
3.数据预测概率
prediction_proba = clf.predict_proba([(0.55/x_diff, 1/y_diff)])prediction_proba代码运行输出:
array([[ 0.33333333, 0. , 0.66666667]])结果显示:(0.55,1)属于第一和第三类的概率分别为33.33%与66.67%。
我们再来试试(0.9,1.2)预测概率
prediction_proba = clf.predict_proba([(0.9/x_diff, 1.2/y_diff)])prediction_proba代码运行输出:
array([[ 1., 0., 0.]])结果显示,(0.9,1.2)属于第一类的概率为100%。
4.KNN算法学习准确性打分
我们将上述数据分类2组,一组用于KNN学习,一组用于测试。
#构建测试组x1_test = np.random.uniform(0.5, 0.7 ,100)y1_test = np.random.uniform(1.4, 1, 100)x2_test = np.random.uniform(0.3,0.5,100)y2_test = np.random.uniform(0.6,1,100)x3_test = np.random.uniform(0.4,0.6,100)y3_test = np.random.uniform(0.8, 1.2, 100)xy_test_normalized = list(zip(np.concatenate((x1_test,x2_test,x3_test))/x_diff,np.concatenate((y1_test,y2_test,y3_test))/y_diff))labels_test = [1]*100+[2]*100+[3]*100#测试组打分score = clf.score(xy_test_normalized, labels_test)score代码运行输出:
0.85333333333333339
#修改n_neighbors参数,继续观察 clf1 = neighbors.KNeighborsClassifier(1)clf1.fit(xy_normalized, labels)clf1.score(xy_test_normalized, labels_test)代码运行输出:
0.81333333333333335结果显示:该模型的学习准确性达到85%左右,参考数据量的参数改变并未导致准确度出现大幅变化。
---精选内容,推荐阅读---

