数据挖掘——数据可视化
数据可视化
-
- 1.数据可视化
-
- 第一关 数据可视化的内涵
-
- 1>数据可视化是什么?
- 2>为什么需要数据可视化?
- 3>历史演变
- 4>习题
- 第二关 初识数据
- 第三关 柱状图
- 第四关 散点图
- 第五关 直方图
- 2.数据可视化进阶
-
- 第一关 热图
-
- 1>热图的作用?
- 2>习题
- 第二关 文本可视化
-
- 1>文本可视化之wordcloud
- 2>wordcloud参数
- 3>习题
- 第三关 文本调整和美化(主要运用seaborn)
1.数据可视化
第一关 数据可视化的内涵
1>数据可视化是什么?
数据可视化是将数据和信息通过用图来表示展示其价值。直观来讲,常见画图的目的有:
1.按区间划分的数据,进行比较;
2.展现变量间的关系或分布;
3.展现网络结果的节点、边、集群,寻找路径,找到影响力大的节点;
4.表示关系,将相关性等属性用不同颜色展示;
5.用字词大小展示频率、重要性;
6.在 3D 空间上展示变量关系、分布。
可视化在数据科学中的地位:

数据可视化的位置虽然靠后,但是十分重要,因为它往往是最后呈现结果的,且本身具有交叉学科属性:信息技术、自然科学、统计分析、图形学、交互、地理信息。
2>为什么需要数据可视化?
哪种数据的表示形式更让人容易接受,是以文字形式还是以图形化呢?“人类有五官,能通过 5 种渠道感受这个物质世界,那么为什么单单要青睐可视化的方式来传递信息呢?这是因为人类利用视觉获取的信息量巨大,人眼结合大脑构成了一台高带宽巨量视觉信号输入的并行处理器。具有超强模式识别能力,有超过 50% 功能用于视觉感知相关处理的大脑。大量视觉信息在潜意识阶段就被处理完成,人类对图像的处理速度比文本快得多。所以数据可视化是一种高带宽的信息交流方式。面对复杂数据,图形化表示更容易让人脑接受,方便挖掘数据中的规律和价值。
3>历史演变
当今世界,数据量猛增,对于如何理解数据提出了更高要求,催生了数据可视化技术的发展。数据表示精细化,高维度化,时序化:
 这些进步和演变得益于数据可视化工具,新兴数据可视化工具提高了作图效率
这些进步和演变得益于数据可视化工具,新兴数据可视化工具提高了作图效率
:
Matplotlib :功能全,可定制性好;
Pandas Visualization :基于 Matplotlib ,接口设计好;
Seaborn :高级作图语言,默认样式精美。
4>习题

第二关 初识数据
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def student():
# ********* Begin *********#
print("""
id name host_id host_name neighbourhood_group neighbourhood latitude longitude room_type price minimum_nights number_of_reviews last_review reviews_per_month calculated_host_listings_count availability_365
0 2818 Quiet Garden View Room & Super Fast WiFi 3159 Daniel NaN Oostelijk Havengebied - Indische Buurt 52.36575 4.94142 Private room 59 3 262 2019-06-28 2.09 1 107
1 20168 Studio with private bathroom in the centre 1 59484 Alexander NaN Centrum-Oost 52.36509 4.89354 Private room 80 1 279 2019-07-08 2.45 2 140
2 25428 Lovely apt in City Centre (w.lift) near Jordaan 56142 Joan NaN Centrum-West 52.37297 4.88339 Entire home/apt 125 14 3 2019-05-11 0.17 2 106
3 27886 Romantic, stylish B&B houseboat in canal district 97647 Flip NaN Centrum-West 52.38673 4.89208 Private room 150 2 195 2019-07-01 2.14 1 74
4 28871 Comfortable double room 124245 Edwin NaN Centrum-West 52.36719 4.89092 Private room 75 2 277 2019-07-02 2.56 3 138
""")
# ********* End *********#
第三关 柱状图
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("Agg")
def student():
# ********* Begin *********#
# 读入数据为DataFrame
df = pd.read_csv('Task3/listings.csv', index_col=0)
# 绘图:图像大小10×10,
fig = plt.figure(figsize=[10, 10])
# 设置绘图样式
# sns.set(style = 'whitegrid')
# 绘制图形
sns.countplot(x='room_type',
data=df,
# 对room_type列的字段进行统计并排序并取前5个
order=df['room_type'].value_counts(ascending=False).head(5).index)
# 旋转x轴90度
plt.xticks(rotation=90)
# 保存并显示图像
plt.savefig("Task3/img/T1.png")
plt.show()
# ********* End *********#
第四关 散点图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
matplotlib.use("Agg")
def student():
# ********* Begin *********#
# 读入数据为DataFrame
df = pd.read_csv('Task4/listings.csv')
# 绘图:图像大小10×10,
plt.figure(figsize=(10, 10))
# 散点图
sns.scatterplot(x="longitude",
y="latitude",
s=10,
data=df)
# 保存并显示图像
plt.savefig("Task4/img/T1.png")
plt.show()
# ********* End *********#
第五关 直方图
import warnings
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
matplotlib.use("Agg")
warnings.filterwarnings('ignore')
def student(data, x, y):
'''
根据输入数据将直方图与线形图绘制在同一面板中
:param data: 绘制直方图数据,类型为list
:param x,y: 绘制线形图数据,类型为list
:return: None
'''
# ********* Begin *********#
# 绘图:图像大小10×10,
plt.figure(figsize=(10, 10))
# 直方图
sns.distplot(data, kde=False, color="blue")
# 折线图
sns.lineplot(x=x, y=y, color="orange")
# 保存并显示图像
plt.savefig("Task5/img/T1.png")
plt.show()
# ********* End *********#
2.数据可视化进阶
第一关 热图
1>热图的作用?
热图可通过色块颜色展示变量相关性的强弱,能够方便的展示各个属性之间的相关度强弱,通过颜色变化找到一些值得观察的数据。
2>习题
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("Agg")
def student():
# ********* Begin *********#
# 读入数据为DataFrame
df = pd.read_csv('Task1/listings.csv', index_col=0)
# 绘图:图像大小10×10,
fig = plt.figure(figsize=[10, 10])
# 绘制图形
sns.heatmap(
df[['price', 'minimum_nights', 'availability_365',
'reviews_per_month', 'number_of_reviews']].corr(),
annot=True
)
# 保存并显示图像
plt.savefig("Task1/img/T1.png")
plt.show()
# ********* End *********#
第二关 文本可视化
1>文本可视化之wordcloud
数据很多时候是自然语言信息,如何从中进行可视化也是有用的一个问题。
字云:用字词大小形象化字词频率的图形。
如何画一个字云呢?用 wordcloud 插件。
安装 wordcloud 作图插件:https://anaconda.org/conda-forge/wordcloud
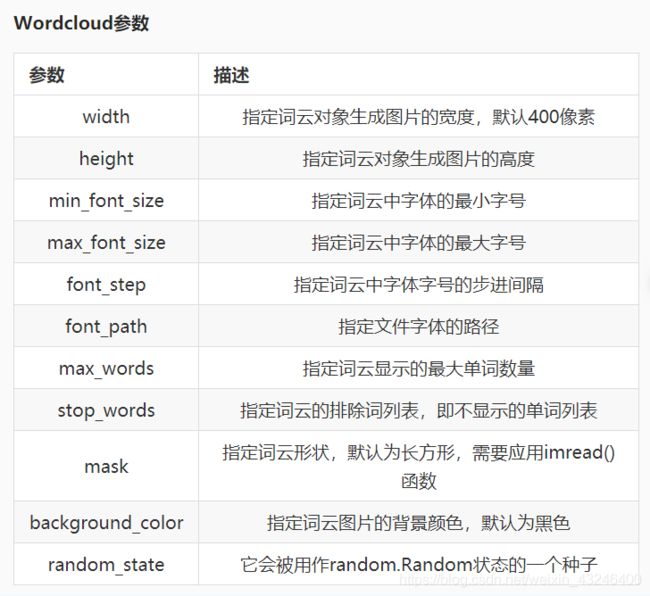
2>wordcloud参数
3>习题
import pandas as pd
import numpy as np
import requests
from PIL import Image
import seaborn as sns
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("Agg")
def student():
# ********* Begin *********#
# 补全所有None的部分
df = pd.read_csv("Task2/listings.csv")
# 获取图形形状
mask = np.array(Image.open(requests.get(
'http://www.clker.com/cliparts/O/i/x/Y/q/P/yellow-house-hi.png', stream=True).raw))
# 填充的单词
filtered_words = {"Amsterdam", "apartment",
"room", "bedroom", "studio", "city"}
# 生成词云
wordcloud = WordCloud(
background_color="white", # 设置背景色
stopwords=set(STOPWORDS).union(filtered_words), # 过滤词
max_words=100, # 最大显示字数
max_font_size=40, # 最大字体
mask=mask, # mask的形状
random_state=2019
).generate(str(df.name)) # 基于mask生成字云
# 绘图
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig("Task2/img/T1.png")
plt.show()
# ********* End *********#
第三关 文本调整和美化(主要运用seaborn)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("Agg")
def student():
# ********* Begin *********#
df = pd.read_csv("Task3/listings.csv")
plt.figure(figsize=[10, 10])
sns.set(style='whitegrid')
sns.barplot(x='room_type', y='price', data=df, ci=None,
order=df.room_type.value_counts(ascending=False).head(5).index)
plt.xticks(rotation=90)
plt.savefig("Task3/img/T1.png")
plt.show()
# ********* End *********#
@date: 2021.04.04
@author: zkinglin
(完)