在公共服务器上使用非root用户离线安装tensorflow-gpu 2.x (简便方法)
摘要:非root用户还是离线安装tensorflow-gpu很少有这么苛刻的条件。本文借助虚拟机搭建好tensorflow-gpu虚拟环境后,将其迁移至公共服务器上,再离线安装cuda和cudnn。
@[TOC](在公共服务器上使用非root用户离线安装tensorflow-gpu 2.x (简便方法))
非root用户还是离线安装tensorflow-gpu很少有这么苛刻的条件,这偏偏被我遇上了。。。
场景是这样的,老师给了我一个超算的用户,这种学校的公共服务器肯定是不会给root权限的,而偏偏这台机器只连学校内网,这就很郁闷。。。
在网上查了查很少有这样场景下的安装教程,于是我就来写一篇。
一、寻常做法
因为离线,所以寻常做法是通过命令复制现有的base环境
conda create tf_gpu -clone base
在自己电脑里下载python、tensorflow-gpu,以及所有依赖库,把它们都上传到服务器上一个一个安装,不出所料我吐了。
于是经过我百般摸索,使出了浑身解数,终于给我发现了一个神奇的方法。
二、借助虚拟机安装
这起源于,我从百度上得知conda创建的虚拟环境可以直接复制到另一台机器上使用。
我在我自己的笔记本上创建了一个和服务器ubuntu版本一样的虚拟机(虚拟机的安装过程我这里就不叙述了)。在服务器上,通过conda-V命令我得到了服务器上conda的版本是4.10.3,我在虚拟机上也同样安装了一个conda4.10.3。于是我在虚拟机上,按照寻常安装tensorflow的步骤:
创建虚拟环境。
conda create -n tf_gpu Python=3.9
激活虚拟环境。
activate tf-gpu
安装tensorflow-gpu,这样所需要的依赖就可以自动安装。
conda install tensorflow-gpu
网上说要使用gpu加速,需要另外装cuda和cudnn两个工具,而cuda和cudnn有很严格的版本对应关系,因为担心会冲突,我先用conda安装cudatoolkit、cudnn
conda install cudatoolkit
conda install cudnn
这样我就得到了cuda版本11.3.1和cudnn版本8.2.1(不知道我这样是否多此一举,但我确是这样做了),后续下载相应的版本进行安装。
![]()
注意:以上安装过程均未使用root权限。
把前面这些能在虚拟机中安装好的完成之后,开始将tf_gpu打包,使用cd命令切换至虚拟环境目录,打包虚拟环境tf_gpu
tar -zcvf tf_gpu.tar.gz tf_gpu
将tf_gpu.tar.gz复制上传至服务器。
将tf_gpu.tar.gz解压至服务器conda的虚拟环境目录
tar -zxvf tf_gpu.tar.gz -C ~/.conda/envs
这里每个人的conda虚拟环境目录可能会不同,请根据自己的实际情况而定。
解压之后,在终端中输入conda info -e就会发现tf_gpu已经迁移到服务器中了。

激活tf_gpu虚拟环境
activate tf_gpu
进入python环境
python
import tensorflow as tf
a = tf.constant(1)
print(a)
可以正常输出,但会报一堆警告,这是因为还需要安装cuda和cudnn。
三、cuda安装
到NVIDIA官网 [CUDA Toolkit Archive | NVIDIA Developer]选择对应版本的cuda,这里选择11.3.1。
然后再选对应的系统型号和installer type
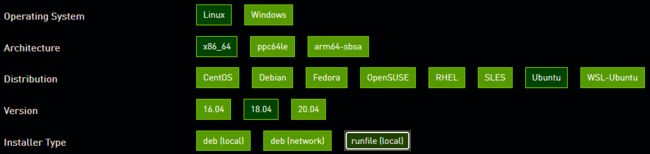
将“Base Installer”里面的下载链接复制到下载器中,或者也可以自己复制链接地址用wget下载,然后安装
wget https://developer.download.nvidia.com/compute/cuda/11.3.1/local_installers/cuda_11.3.1_465.19.01_linux.run
# sh后的文件名以实际下载文件名为准
sh cuda_11.3.1_465.19.01_linux.run
因为是非root用户,所以安装过程中所以需要root权限的操作都要避免掉。
接受协议
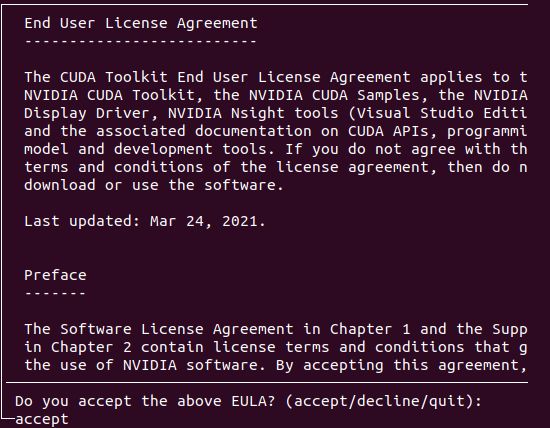
取消cuda安装驱动程序

进入Options

不更新和安装驱动
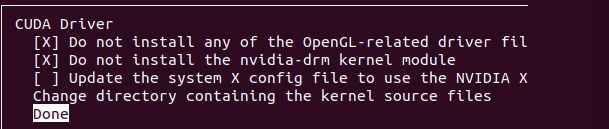
不创建链接和文档
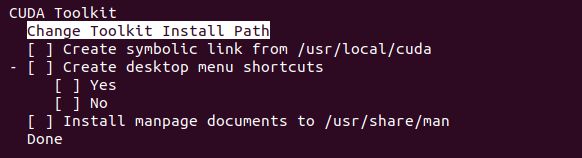
更改cuda的安装路径为用户目录

更改完这些选项就可以安装了。
四、cudnn安装
cuDNN Archive | NVIDIA Developer
下载cudnn需要NVIDIA账号,注册一个即可。
选择对应cuda版本号的cudnn版本(8.2.1)。

选择cuDNN Library for Linux,因为下载cudnn是需要登录的,所以在自己电脑上下载后,再传到服务器上。
下载完 cuDNN,发现后缀是 .tgz ,使用命令解压至用户目录
tar -zxvf cudnn-11.3-linux-x64-v8.2.1.32.tgz -C ~/
解压后发现cudnn总共分两个目录,复制 cuDNN 文件到 CUDA 安装目录:(cuDNN 解压到 ~/cuda 目录了,~/cuda-11.3 为自己设定的 CUDA 安装目录,~ 代表用户目录),并且给所有用户添加读的权限
cp ~/cuda/include/cudnn.h ~/cuda-11.3/include
cp ~/cuda/lib64/lib* ~/cuda-11.3/lib64
chmod a+r ~/cuda-11.3/include/cudnn.h ~/cuda-11.3/lib64/libcudnn*
建立软连接
cd ~/cuda-11.3/lib64
ln -sf libcudnn.so.8.2.1 libcudnn.so.8
ln -sf libcudnn.so.8 libcudnn.so
ldconfig -v
五、配置用户环境变量
修改 ~/.bashrc 文件,将下面两行加进去:(将xxx 改成自己的用户名)
export PATH=/home/xxx/cuda-11.3/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/home/xxx/cuda-11.3/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存 ~/.bashrc 文件后,source ~/.bashrc 使其生效。
到这一步tensorflow-gpu的环境搭建就完成了,我们可以验证一下是否启动了GPU加速。在python中运行下面代码,打印结果若是true,则成功启动GPU加速,反之。
import tensorflow as tf
print(tf.test.is_gpu_available())
温馨提示: 使用公共服务器的同学可以在安装自己的cuda和cudnn后,最好删除安装文件,为自己和别人节省公共空间。(安装其他包也是一样,及时清理安装缓存文件)
reference
Linux服务器中非 root 用户安装(多版本) CUDA 和 cuDNN - 简书 (jianshu.com)