机器学习如何正确调参之学习曲线
利用学习曲线让你的机器学习模型效果更好
我们知道,很多时候我们的机器学习或者深度学习的模型一开始效果并不是很好,当训练出来结果不是很好时,通常有下列几种方法:
- 增加数据量
- 尝试减少的特征
- 尝试增加特征
- 减小正则化参数 λ \lambda λ
- 增大正则化参数 λ \lambda λ
那么什么时候用那种方法呢?如果只凭直觉胡乱尝试,很多时候只会是浪费时间,模型效果也没有得到多大提升。
这篇博客会告诉你用如何用学习曲线来根据机器模型的结果正确调参,让你把时间花在刀刃上!
下面先介绍学习曲线:
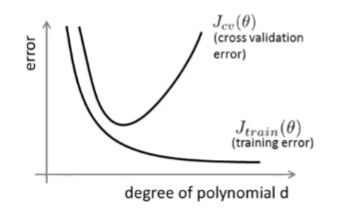
上图中J c v _{cv} cv为验证集的损失,J t r a i n _{train} train为训练集的损失,横轴的d可以理解为机器模型中参数的数量,或者说模型的复杂度。
可以看到当模型越复杂时,训练集的损失越来越少,而验证集的损失先是减少,然后过了某个结点之后损失开始增加,这就是大家熟知的过拟合现象。
最开始训练集和验证集损失都很大,这时称模型具有高偏差(high bias),之后验证集的损失远大于训练集的损失,这时称模型具有高方差(high variance)。
所以当你针对自己的机器学习模型画出这样的图像之后,就可以判断如何调整模型的复杂度了。比如你训练的神经网络过拟合了,就可以适当减少每层的神经元的数量或者减少网络层数。
如何你不想减少你的模型复杂度,还可以增大你的正则化参数 λ \lambda λ,一般来说选择复杂模型+增大 λ \lambda λ的效果比减小模型复杂度的效果要好。
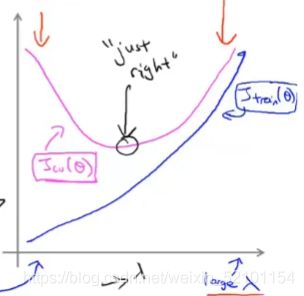
两条曲线分别是验证集和训练集的损失,横轴表示正则化参数 λ \lambda λ的大小。
正则化这个方法其实就是在损失函数里面加一个式子,这个式子包含了除了偏置项之外所有参数的平方和,然后在平方和之前乘上一个正则化参数 λ \lambda λ。
正则化的原理:损失函数中加入参数平方和,主要是惩罚某些参数数值过大,当参数数值很大时,损失函数也就会变大,而模型为了让损失函数尽可能地小,会尽可能时参数变小。
至于为什么要让参数变小,这是因为一般模型曲线越光滑,这个模型一般就越稳定,效果就越好,而小数值的参数能让模型曲线变光滑。试想一下,如果某些参数很大,在数轴上原本两个很近的点,因为参数很大,所以他们经过参数计算过后的数值差距可能非常大,直观来看就是曲线跳动太大,不光滑,这样的模型一般是过拟合的,所以正则化可以防止过拟合。
好的,初步了解了正则化的原理和作用,就可以看懂这张图了,当 λ \lambda λ很小时,可以看做 λ \lambda λ非常接近0,相当于没有正则化,所以模型会呈现过拟合的现象,即高方差,随着 λ \lambda λ越来越大,由于损失函数要尽可能地小,所以除了偏置项参数外,别的参数全都很小,可以看做为0,所以最终训练出来的模型曲线基本接近一条直线,这条直线的值就等于偏置项的值,毫无疑问,这时模型肯定是误差很大,具有高偏差的特点。
所以我们就可以画出自己的机器学习模型关于 λ \lambda λ的学习曲线,选择最佳的正则化参数 λ \lambda λ。

上图横轴表示数据量的大小,曲线意义和上面两图一样。
在我们的印象中只要数据量越多,模型训练效果一定更好,但有时候你就算加再多的数据,模型效果也不能得到提升哦,比如当模型出现高偏差的情况,如下图:
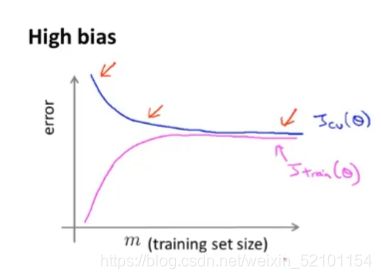
图中训练集一开始能够很好地拟合所有的数据点,所以损失非常少,但是随着数据越来越多,模型开始越来越难以拟合所有的数据点,所以损失会增加;相应地,一开始训练样本少,模型泛化能力差,所以验证集一开始的损失比较大,随着数据增多,模型泛化能力有了一定提升,验证集损失开始减少。但是到了某一个结点之后,模型训练集和验证集的损失都接近水平,此时无论加多少数据,模型效果也得不到提升。
主要原因就是:模型复杂度不够了,模型难以拟合如此多的数据,所以你加再多的数据,再怎么训练,模型也无能为力。所以此时应该增加模型的复杂度。
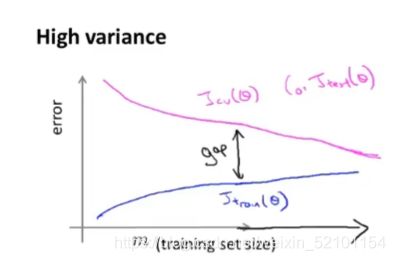
上图为高方差下的情况,高方差的特点就是,训练集和验证集的损失曲线之间有一个很大的gap,即有一段很大的缺口。
在有很大gap的时候,表示训练集误差较小,但验证集误差比较大,这时候你的数据量太少,模型过拟合了,所以泛化效果不是很好。
正如图中所画的那样,延伸你的横轴,让数据量m继续增大,此时训练集损失略微增大,但数值很小,而验证集损失继续减小,直到小到和验证集差不多。
好啦,以上就是学习曲线的内容。了解了学习曲线之后,大家应该知道如何根据自己的机器模型结果来选择适当的方法了。
回到最初的问题:
- 当你发现自己的模型具有高偏差的特点时,可以选择:增加特征数、减小正则化参数 λ \lambda λ
- 当你的模型具有高方差的特点时,可以选择:增加数据量、减少特征数、增大正则化参数 λ \lambda λ