【机器学习】线性回归【下】正则化最小二乘估计
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
由于字数限制,分成两篇博客。
【机器学习】线性回归【上】朴素最小二乘估计
【机器学习】线性回归【下】正则化最小二乘估计
2.4. 正则化
正则化是指通过修改学习算法,使模型降低泛化误差而非训练误差。通俗地理解为,凡是能缓解过拟合的方法都称为正则化。
正则化有很多种,常见的有 L1 正则化、L2 正则化、Dropout 正则化等等。下面我们仅介绍 L1、L2 正则化。
式 ( 4 ) (4) (4) 为朴素最小二乘估计对应的目标函数式 ( 1 ) (1) (1) 的解析解。上面提到样本个数为 n n n,样本维度为 p p p,我们知道当 n ≫ p n\gg p n≫p 时,训练出的模型一般会更优质;而如果样本数目不够多或者样本缺少普遍性,体现在线性代数中为过多样本存在线性相关,出现样本向量集合的极大线性无关组数目过少,甚至少于 p p p 的情况,这将会带来一些问题。从计算上来讲,由于式 ( 4 ) (4) (4) 中 p × p p\times p p×p 的矩阵 X T X X^TX XTX 不满秩,无法求逆,导致无法计算出解析解,从现象上来讲对应着过拟合问题,比如可以考虑在一个二维(样本维度)平面中确定过一个点(样本个数)的直线,显然存在无数条,不可能每一条直线都适应测试样本,所以训练出的某条直线大概率只能适应训练样本而无法适应测试样本,即出现过拟合现象。
处理过拟合问题的三种方法:① 增加数据量(数据增强等)②特征选择/特征提取(PCA等降维方法)③正则化
引入正则化项(regularizer)后的目标函数
J ( W ) = L ( W ) + α g ( W ) (8) J(W)=L(W)+\alpha g(W) \tag{8} J(W)=L(W)+αg(W)(8)
其中, α > 0 \alpha>0 α>0。最小化目标函数 ( 7 ) (7) (7) 对应的 W W W 为目标模型参数,即
W ^ = a r g min W J ( W ) = a r g min W L ( W ) + α g ( W ) (9) \hat{W}={\rm arg}\min_W J(W)={\rm arg}\min_W L(W)+\alpha g(W) \tag{9} W^=argWminJ(W)=argWminL(W)+αg(W)(9)
L1 正则化表示正则化项为模型参数的一范数,即 g ( W ) = ∣ ∣ W ∣ ∣ 1 g(W)=||W||_1 g(W)=∣∣W∣∣1;L2 正则化表示正则化项为模型参数的二范数,即 g ( W ) = ∣ ∣ W ∣ ∣ 2 g(W)=||W||_2 g(W)=∣∣W∣∣2 。
L1 正则化回归被称为 Lasso 回归;L2 正则化回归被称为 Ridge 回归(岭回归)。
g ( ⋅ ) g(·) g(⋅) 被称为惩罚项(penalty term)或权重衰减(weight decay)。
2.4.1. L2 正则化
L2 正则化的目的是希望训练出较小的模型参数,以提高模型的泛化能力,防止样本的微小波动导致输出值的剧烈变化。
L2 正则化最小二乘估计目标函数的一般形式
J ( W ) = ∑ i = 1 n ∣ ∣ W T x i − y i ∣ ∣ 2 2 + α ∣ ∣ W ∣ ∣ 2 (10) J(W)=\sum_{i=1}^n||W^Tx_i-y_i||_2^2+\alpha ||W||_2\tag{10} J(W)=i=1∑n∣∣WTxi−yi∣∣22+α∣∣W∣∣2(10)
等价的矩阵形式为
J ( W ) = ( W T X T − Y T ) ( X W − Y ) + α W T W (11) J(W)=(W^TX^T-Y^T)(XW-Y)+\alpha W^TW\tag{11} J(W)=(WTXT−YT)(XW−Y)+αWTW(11)
进而整理为
J ( W ) = W T ( X T X + α I ) W − 2 W T X T Y (12) J(W)=W^T(X^TX+\alpha I)W-2W^TX^TY\tag{12} J(W)=WT(XTX+αI)W−2WTXTY(12)
解释一下从式 ( 10 ) (10) (10) 转换到式 ( 11 ) (11) (11)。 L ( W ) L(W) L(W) 部分的矩阵表示不再重复讲解,主要介绍一下为什么 α ∣ ∣ W ∣ ∣ 2 \alpha ||W||_2 α∣∣W∣∣2 和 α W T W \alpha W^TW αWTW 等价。
根据后续从拉格朗日角度理解正则化的内容(建议先认为已知,按顺序阅读),我们可以知道约束条件等价于 ∣ ∣ W ∣ ∣ 2 ≤ C ||W||_2\le C ∣∣W∣∣2≤C( C C C 为常数), ∣ ∣ W ∣ ∣ 2 = W T W ≤ C ⇒ W T W ≤ C 2 ||W||_2=\sqrt{W^TW}\le C\Rightarrow W^TW\le C^2 ∣∣W∣∣2=WTW≤C⇒WTW≤C2,由于 C C C 是任意常数,那么约束条件 ∣ ∣ W ∣ ∣ 2 ≤ C ||W||_2 \le C ∣∣W∣∣2≤C 与 W T W ≤ C 2 W^TW\le C^2 WTW≤C2 等价,通俗简单地理解为将 ∣ ∣ W ∣ ∣ 2 ||W||_2 ∣∣W∣∣2 替换为 W T W W^TW WTW 。
具体有关拉格朗日的等价变换可以自行学习。
目标参数为
W ^ = a r g min W J ( W ) (13) \hat W={\rm arg}\min_W J(W)\tag{13} W^=argWminJ(W)(13)
L2 正则化对抽象通用的二次代价函数的影响
我们先讨论 L2 正则化对优化一个抽象通用的二次代价函数的影响。简化分析,令 W ∗ W^∗ W∗ 为未正则化的目标函数取得最小训练误差时的权重向量,即 W ∗ = a r g min W L ( W ) W^∗ = {\rm arg} \min_W L(W) W∗=argminWL(W),并在 W ∗ W^∗ W∗ 的邻域对目标函数做二次近似(二阶泰勒展式)。如果目标函数确实是二次的(如以均方误差拟合线性回归模型的情况),则该近似是完美的。 近似的 L ^ ( W ) \hat L(W) L^(W) 如下
L ^ ( W ) = L ( W ∗ ) + 1 2 ( W − W ∗ ) H ( W − W ∗ ) (14) \hat L(W)=L(W^*)+\frac{1}{2}(W-W^*)H(W-W^*)\tag{14} L^(W)=L(W∗)+21(W−W∗)H(W−W∗)(14)
其中 H H H 是 L L L 在 W ∗ W^∗ W∗ 处计算的 Hessian 矩阵(关于 W W W)。因为 W ∗ W^∗ W∗ 被定义为最优,即梯度消失为 0 0 0,所以该二次近似中没有一阶项。同样地,因为 W ∗ W^∗ W∗ 是 L L L 的一个最优点, 我们可以得出 H H H 是半正定的结论。
当 L ^ \hat L L^ 取得最小时,其梯度
∇ L ^ ( W ) = H ( W − W ∗ ) (15) \nabla \hat L(W)=H(W-W^*)\tag{15} ∇L^(W)=H(W−W∗)(15)
为 0 0 0 。
为了研究权重衰减带来的影响,我们在式 ( 15 ) (15) (15) 中添加权重衰减的梯度。根据式 ( 15 ) (15) (15),我们可以得到最小化正则化后的目标函数
J ^ ( W ) = L ^ ( W ) + α W T W \hat J(W)=\hat L(W)+\alpha W^TW J^(W)=L^(W)+αWTW
的梯度为
∇ J ^ ( W ) = α W + H ( W − W ∗ ) \nabla \hat J(W)=\alpha W+H(W-W^*) ∇J^(W)=αW+H(W−W∗)
我们使用变量 W ~ \tilde W W~ 表示引入正则化项后的最优点。令梯度为 0 0 0,得
W ~ = ( H + α I ) − 1 H W ∗ (16) \tilde W=( H+\alpha I)^{-1}HW^*\tag{16} W~=(H+αI)−1HW∗(16)
注意区分 W ~ \tilde W W~ 和 W ∗ W^* W∗,二者分别表示引入正则化项后目标函数的最优解和未引入的最优解。
式 ( 16 ) (16) (16) 确定了二者的直接关系,让我们能够直接对比引入正则化项后相较于引入前发生了怎样的变化。
当 α α α 趋向于 0 0 0 时,正则化的解 W ~ \tilde W W~ 会趋向 W ∗ W^∗ W∗。
接下来探讨 α \alpha α 增加带来的影响。因为 H H H 是实对称的,所以我们可以将其分解为一个对角矩阵 Λ \Lambda Λ 和一组特征向量的标准正交基 Q Q Q,并且有 H = Q Λ Q T H = Q\Lambda Q^T H=QΛQT。将其应用于式 ( 16 ) (16) (16) ,可得:
KaTeX parse error: Undefined control sequence: \notag at position 74: …ambda Q^TW^* \\\̲n̲o̲t̲a̲g̲ ̲&=[Q(\Lambda +\…
我们可以看到权重衰减的效果是沿着由 H H H 的特征向量所定义的轴缩放 W ∗ W^∗ W∗。具体来 说,我们会根据 λ i λ i + α \frac{λ_i}{λ_i+α} λi+αλi 因子缩放与 H H H 第 i i i 个特征向量对齐的 W ∗ W^∗ W∗ 的分量,这样就得到了 W ~ \tilde W W~ 和 W ∗ W^* W∗ 直接关系
w ~ i = λ i λ i + α w i ∗ (18) \tilde w_i=\frac{\lambda_i}{\lambda_i+\alpha} w_i^*\tag{18} w~i=λi+αλiwi∗(18)
沿着 H H H 特征值较大的方向(如 λ i ≫ α λ_i\gg α λi≫α)正则化的影响比较小( W ∗ W^* W∗ 分量的缩放程度比较小),而沿特征值较小的方向(如 λ i ≪ α λ_i\ll α λi≪α)正则化影响比较大( W ∗ W^* W∗ 分量的缩放程度比较大,甚至收缩到几乎为 0 0 0)。
W ~ = Q ( Λ + α I ) − 1 Λ Q T W ∗ \tilde W=Q(\Lambda +\alpha I)^{-1} \Lambda Q^T W^* W~=Q(Λ+αI)−1ΛQTW∗ 相当于先将 W ∗ W^* W∗ 转换为在以长度为特征值的特征向量 Λ Q T \Lambda Q^T ΛQT 为基向量的坐标系中的表示,但是再转化回到原坐标系时,特征值从 Λ \Lambda Λ 变为了 Λ + α I \Lambda+\alpha I Λ+αI。直观上来说,原坐标系中的基向量变长了,那么用变长后的基向量表示一个绝对长度的向量显然每一维度的坐标值会变小,每一维的缩放因子即为 λ i λ i + α \frac{λ_i}{λ_i+α} λi+αλi 。
实在不理解的建议补习一下线性代数的几何意义,大部分高校应该是不讲几何意义的。
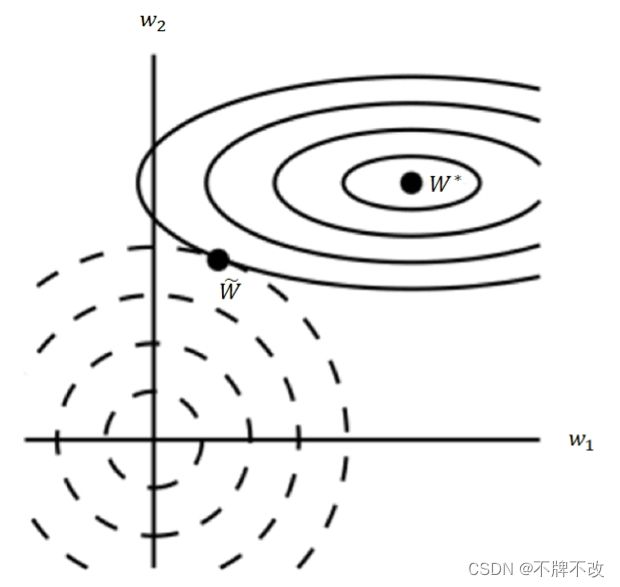
图 3 L2 正则化对最佳 W 的影响例图
图 3 3 3 中实线椭圆表示没有正则化目标的等值线,虚线圆圈表示 L2 正则化项的等值线,这两个竞争目标在 W ~ \tilde W W~ 点达到平衡。可以看出,引入正则化项使得最优解从 W ∗ W^* W∗ 位置变到了 W ~ \tilde W W~ 位置,第一维分量( w 1 w_1 w1)和第二维分量( w 2 w_2 w2)均减小。更细致地看,当从 W ∗ W^* W∗ 分别沿竖直和水平方向移动相同距离时,水平方向的移动导致目标函数的变化比竖直方向的移动导致目标函数的变化小,说明第一维分量( w 1 w_1 w1)的重要程度不及第二维分量( w 2 w_2 w2)。在线性回归时,我们不希望一些相似样本因为在不重要分量上的不同而出现较大的预测差别,因此需要降低不重要分量的权重,对应上图的第一维分量( w 1 w_1 w1)。虚线圆圈(正则化项)的出现确实使得两个分量均减小,且第一维分量由于不重要所以缩放程度更大。反映在 Hessian 矩阵中,第一维分量( w 1 w_1 w1)对应的 Hessian 矩阵特征值 λ 1 \lambda_1 λ1 要比第二维分量( w 2 w_2 w2)对应的 Hessian 矩阵特征值 λ 2 \lambda_2 λ2 小,所以 α \alpha α 的作用越明显,缩放程度越大。
总体的感受就是,只有在显著减小目标函数方向上的参数会保留得相对完好。在无助于目标函数减小的方向(对应 Hessian 矩阵较小的特征值)上改变参数不会显著增加梯度。这种不重要方向对应的分量会在训练过程中因正则化而衰减掉。
L2 正则化对最小二乘估计目标函数的影响
式 ( 2 ) (2) (2) 加上 L2 正则化项后,得到 L2 正则化最小二乘估计目标函数的矩阵表示
KaTeX parse error: Undefined control sequence: \notag at position 69: …+\alpha W^TW \\\̲n̲o̲t̲a̲g̲ ̲&=W^T(X^TX+\alp…
转换为矩阵形式的过程类比式 ( 2 ) (2) (2) 。
对 J ( W ) J(W) J(W) 求导,并令导数为零
∂ J ( W ) ∂ W = 2 ( X T X + α I ) W − 2 X T Y = 0 \frac{\partial J(W)}{\partial W}=2(X^TX+\alpha I)W-2X^TY=0 ∂W∂J(W)=2(XTX+αI)W−2XTY=0
令导数为零,可得解析解
W = ( X T X + α I ) − 1 X T Y (20) W=(X^TX+\alpha I)^{-1}X^TY\tag{20} W=(XTX+αI)−1XTY(20)
其中,矩阵 X T X X^TX XTX 与协方差矩阵 1 m X T X \frac{1}{m}X^TX m1XTX 成正比,且均为半正定矩阵,因为 α > 0 \alpha>0 α>0,所以 X T X + α I X^TX+\alpha I XTX+αI 必然正定。从计算角度来看可逆;从观察到的现象上来讲缓解了过拟合。矩阵 X T X X^TX XTX 的对角项对应每个输入特征的方差。我们可以看到,L2 正则化能让学习算法 ‘‘感知’’ 到具有较高方差的输入 x x x,因此与输出目标的协方差较小(相对增加方差)的特征的权重将会收缩。
拉格朗日乘数法视角下的 L2 正则化
这部分不会深入到拉格朗日乘数法的相关知识中进行讲解。
本质上 L2 正则化项是对 W W W 的一个约束,希望模型参数 W W W 小一点,对应的约束条件(可行域)为 g ( W ) = ∣ ∣ W ∣ ∣ 2 ≤ C g(W)=||W||_2\le C g(W)=∣∣W∣∣2≤C( C C C 为常数)。写成拉格朗日函数为
KaTeX parse error: Undefined control sequence: \notag at position 61: …a(||W||_2-C) \\\̲n̲o̲t̲a̲g̲ ̲&=L(W)+\lambda …
式 ( 21 ) (21) (21) 可以写成更简单的等价形式
J ( W , λ ) = L ( W ) + λ ∣ ∣ W ∣ ∣ 2 (22) J(W,\lambda)=L(W)+\lambda ||W||_2\tag{22} J(W,λ)=L(W)+λ∣∣W∣∣2(22)
之所以说 J ′ ( W ) J'(W) J′(W) 与 J ( W ) J(W) J(W) 等价,是因为最小化两个函数得到的最优解 W ~ \tilde W W~ 相同。两个函数对 W W W 计算偏导可以得到相同的导函数,故令导函数为零可得相同的解。
式 ( 22 ) (22) (22) 中的 λ \lambda λ 为超参数。训练模型时人为给定 λ \lambda λ ,令目标函数关于 W W W 的偏导数为零,找到最优解 W ~ \tilde W W~,在 W ~ \tilde W W~ 处满足 ∇ L \nabla L ∇L 和 ∇ g \nabla g ∇g 共线,且模长 ∣ ∇ L ∣ = − λ ∣ ∇ g ∣ |\nabla L|=-\lambda |\nabla g| ∣∇L∣=−λ∣∇g∣ 。
图 4 4 4 中绿色虚线圈可以理解为 f ( W ) = g ( W ) − C f(W)=g(W)-C f(W)=g(W)−C 的等高线,红色点表示 ∇ L \nabla L ∇L 与 ∇ g \nabla g ∇g 方向相同的位置,绿色箭头表示红点处 f ( W ) f(W) f(W) 的梯度(大小与方向),蓝色箭头表示未加正则化项的目标函数 L ( W ) L(W) L(W) 的梯度(大小和方向)。当给定超参数 λ \lambda λ 后,训练模型就是在找满足 ∣ ∇ L ∣ ∣ ∇ f ∣ = − λ \frac{|\nabla L|}{|\nabla f|}=-\lambda ∣∇f∣∣∇L∣=−λ(亦 ∣ ∇ L ∣ ∣ ∇ g ∣ = − λ \frac{|\nabla L|}{|\nabla g|}=-\lambda ∣∇g∣∣∇L∣=−λ)的红色点。不同的 λ \lambda λ 对应不同的红点集合,相当于间接地限制了可行域的大小,因此调整 λ \lambda λ 也就是在调整可行域大小,与式 ( 21 ) (21) (21) 中调整 C C C 的作用类似。
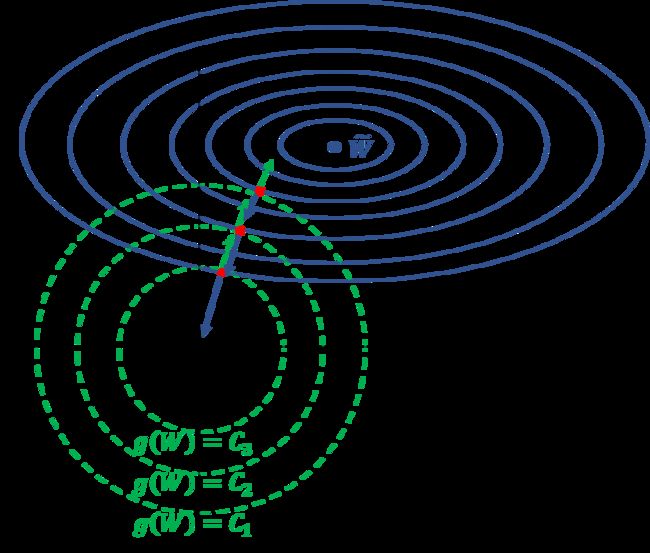
图 4 拉格朗日乘数法视角下的 L2 正则化
同时可见,式 ( 22 ) (22) (22) 与 式 ( 10 ) (10) (10) 完全一致的。这样从拉格朗日的角度很好地解释了 L2 正则化。
sklearn 中关于 L2 正则化的参数 C C C 并非式 ( 21 ) (21) (21) 中的参数 C C C,而是在作用上等价于式 ( 22 ) (22) (22) 中 λ \lambda λ 的倒数。
神经网络视角下的 L2 正则化
在神经网络中,只需要对权重 W W W 正则化,不需要对偏置 b b b 正则化。因为 L 2 L2 L2 正则化的本质是希望通过减小权重的方式,让神经网络拟合出来的曲线更加平滑。只有权重 W W W 会影响曲线平滑(弯曲)程度,偏置 b b b 只会影响曲线的位置,因此在神经网络中仅对权重 W W W 进行正则化。
对于同一个结构的模型,选取不同的权重和偏置,可能对任意同一个样本计算出相同的目标函数值。尽管结算结果相同,但是大权重会对噪声起到过度放大的作用,同类样本的差距也会被放大,导致模型效果不理想,出现过拟合问题。
说明一下“对于同一个结构的模型,选取不同的权重和偏置,可能对任意同一个样本计算出相同的目标函数值”。
我们以简单的多层感知机为例,假设输入样本向量为 x p × 1 x_{p\times 1} xp×1,第 i i i 个层的权重(含偏置)矩阵为 W i W_i Wi ,为了方便处理偏置项,我们认为 x p × 1 x_{p\times 1} xp×1 的第 p p p 维为 1 1 1, W i W_i Wi 的最后一行表示偏置项。采用最简单的 ReLu 函数激活,经过第一层神经元的输出为 W 1 T x W^T_1x W1Tx,经过前两层的输出为 W 2 T ( W 1 T x ) W^T_2(W^T_1x) W2T(W1Tx),那么经过 k k k 层神经元后的输出为 W k T ( … W w T W 1 T x ) W^T_k(\dots W^T_wW^T_1x) WkT(…WwTW1Tx)。
现在让前 k − 1 k-1 k−1 层神经元的权重和偏置均变为 2 2 2 倍,第 k k k 层神经元的权重和偏置变为 1 2 k − 1 \frac{1}{2^{k-1}} 2k−11 倍,那么经过 k k k 层神经元后的输出为 1 2 k − 1 W k T ⋅ 2 k − 1 ( … W w T W 1 T x ) \frac{1}{2^{k-1}}W^T_k·2^{k-1}(\dots W^T_wW^T_1x) 2k−11WkT⋅2k−1(…WwTW1Tx),与权重和偏置变化前的输出值相同。这说明对于相同的模型结构,不同的权重和偏置是可能计算出相同的目标函数值的。
神经网络拟合出的函数 f ( x ) f(x) f(x) 由泰勒展开得到, f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 + ⋯ + 1 n ! f ( n ) ( x 0 ) ( x − x 0 ) n f(x)=f(x_0)+f'(x_0)(x-x_0)+\frac{1}{2}f''(x_0)(x-x_0)^2+\dots+\frac{1}{n!}f^{(n)}(x_0)(x-x_0)^n f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2+⋯+n!1f(n)(x0)(x−x0)n 。一般地,函数的次数越高,对应图像上能够出现更多的弯曲。直观上来说,我们通过为高次项设置小的系数以减少高次项对函数的贡献就可以实现平滑函数曲线。图 5 5 5 表示对两类样本进行分类,紫色曲线表示欠拟合,红色曲线表示过拟合,蓝色曲线为最佳拟合。对于紫色曲线来说,其对应的函数仅包含一次项和常数项,所以无法出现弯曲,导致欠拟合;对于红色曲线来说,由于高次项的出现,使得函数的某个区域内出现大幅度波动,导致过拟合。定性分析(直观感受上), f ( x ) f(x) f(x) 在 x = x 0 x=x_0 x=x0 处的各阶导数值 f ( i ) ( x 0 ) f^{(i)}(x_0) f(i)(x0)与 W W W 有关,尽管不知道二者的具体函数关系,但是可以感受到,当 W W W 趋于 0 0 0 时, f ( i ) ( x 0 ) f^{(i)}(x_0) f(i)(x0) 也趋于 0 0 0。另外, f ( i ) ( x 0 ) f^{(i)}(x_0) f(i)(x0) 趋于 0 0 0 只会惩罚次数大于 1 1 1 的高次项,这是因为一次项的系数变化并不改变曲线的弯曲程度,只有大于 1 1 1 次的高次项的系数发生改变时曲线的弯曲程度才会改变,这与我们不对偏置 b b b 正则化的原因类似。
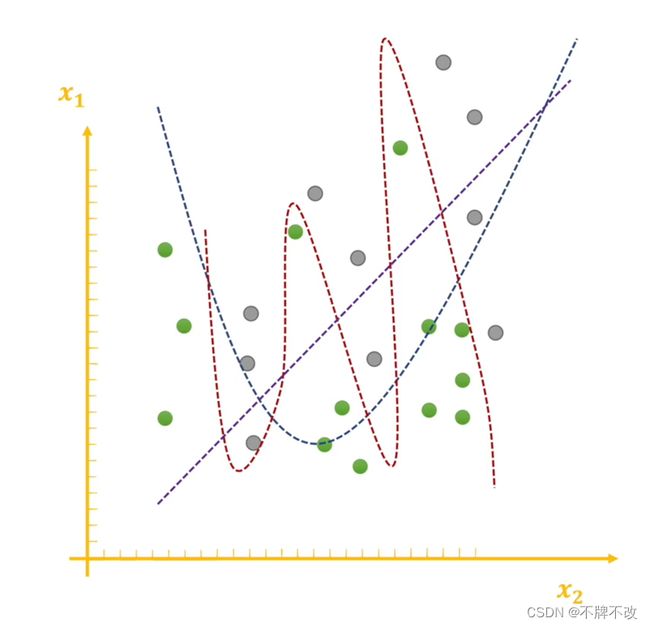
图 5 神经网络对于二分类问题拟合出的不同分界线
“权重衰退”这个名字也是在神经网络中体现的。在训练神经网络时,我们一般采用梯度下降等迭代方法,而非像机器学习那样更多采用直接计算解析解的方法。想要了解“权重衰退”名称的由来,就需要对比在采用 GD 算法更新参数的前提下,向目标函数中引入正则化项和未引入时模型权重的更新公式。
我们首先考虑未正则化项的模型权重更新
W = W − λ ∇ L ( W ) (23) W=W-\lambda \nabla L(W) \tag{23} W=W−λ∇L(W)(23)
其中, λ \lambda λ 为学习率(或步长)。正则化的梯度下降法中,先计算梯度
∇ J ( W ) = ∇ L ( W ) + α W \nabla J(W)=\nabla L(W)+\alpha W ∇J(W)=∇L(W)+αW
权重更新为
KaTeX parse error: Undefined control sequence: \notag at position 58: … + \alpha W) \\\̲n̲o̲t̲a̲g̲ ̲&= (1-\lambda\a…
对比式 ( 23 ) (23) (23) 和式 ( 24 ) (24) (24) 可以看出,式 ( 23 ) (23) (23) 每次用 W W W 进行更新,而式 ( 24 ) (24) (24) 每次不用完整的 W W W 更新,而是使用 ( 1 − λ α ) (1-\lambda \alpha) (1−λα) 倍的 W W W 更新。因为 λ \lambda λ 和 α \alpha α 都是正数,所以 1 − λ α < 1 1-\lambda\alpha\lt 1 1−λα<1,相较于式 ( 23 ) (23) (23),加入正则化项后的每次更新权重都要减少更多,这就是权重衰减名称的由来。当然考虑到 λ ∇ L ( W ) \lambda \nabla L(W) λ∇L(W) 项,更新后的 W W W 值可能增大也可能减小。
概率视角下的 L2 正则化
下面从贝叶斯派学者的角度(MAP)来重新审视 L2 正则化的最小二乘估计。
噪声假设服从正态分布 ϵ ∼ ( 0 , σ 2 ) \epsilon\sim (0,\sigma^2) ϵ∼(0,σ2) ,标签 Y Y Y 可以表示为噪声形式 Y = Y ^ + ϵ = W T X + ϵ Y=\hat Y + \epsilon= W^TX+\epsilon Y=Y^+ϵ=WTX+ϵ,因此 Y ∣ X , W ∼ N ( W T X , σ 2 ) Y\mid X,W\sim N(W^TX, \sigma^2) Y∣X,W∼N(WTX,σ2) ,这部分与频率派学者的假设一样。贝叶斯派学者观点与其的不同之处在于贝,叶斯派学者认为模型参数也是随机变量,而不是未知常量,所以模型参数同样服从一定的分布。假设模型参数 W W W 的每一个维度均服从正态分布 ( 0 , σ 0 2 ) (0,\sigma_0^2) (0,σ02),即 w i ∼ ( 0 , σ 0 2 ) w_i\sim(0,\sigma_0^2) wi∼(0,σ02)( i = 1 , 2 , … , p i=1,2,\dots,p i=1,2,…,p),即先验分布。
根据这两个分布,我们可以写出具体的概率分布函数
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ P(Y\mid W) &= …
从意义上来讲, Y ∣ W Y\mid W Y∣W 和 Y ∣ X , W Y\mid X,W Y∣X,W 是等价的。可以从多种角度理解,这里不再解释。
最大后验概率估计(MAP)的定义目标函数
KaTeX parse error: Undefined control sequence: \notag at position 42: …g P(W\mid Y) \\\̲n̲o̲t̲a̲g̲ ̲&=\log \frac{P(…
最大化目标函数 ( 27 ) (27) (27) 对应的 W W W 为目标模型参数,即
KaTeX parse error: Undefined control sequence: \notag at position 50: … \max_W L(W) \\\̲n̲o̲t̲a̲g̲ ̲&={\rm arg} \ma…
一般认为式 ( 28 ) (28) (28) 为 MAP 的目标参数计算公式。
将式 ( 25 ) (25) (25) 和式 ( 26 ) (26) (26) 代入到式 ( 28 ) (28) (28) 中得
KaTeX parse error: Undefined control sequence: \notag at position 65: …Y\mid W)P(W) \\\̲n̲o̲t̲a̲g̲ ̲&={\rm arg} \ma…
式 ( 29 ) (29) (29) 化为矩阵形式
W ^ = a r g min W ( W T X T − Y T ) ( X W − Y ) + 2 σ 2 2 σ 0 2 W T W (30) \hat W={\rm arg} \min\limits_W (W^TX^T-Y^T)(XW-Y) +\frac{2\sigma^2}{2\sigma_0^2}W^TW \tag{30} W^=argWmin(WTXT−YT)(XW−Y)+2σ022σ2WTW(30)
当式 ( 13 ) (13) (13) 中的 α = 2 σ 2 2 σ 0 2 \alpha=\frac{2\sigma^2}{2\sigma_0^2} α=2σ022σ2 时,式 ( 30 ) (30) (30) 与式 ( 13 ) (13) (13) 完全一致。可见,以贝叶斯派学者的角度理解 L2 正则化的 LSE 可以推导出与其一般定义下相同的目标函数和目标参数。因此,我们可以认为 L2 正则化的最小二乘估计与噪声和先验均为高斯分布的最大后验概率估计是等价的。
上面提到了朴素最小二乘估计等价于噪声为高斯分布的最大似然估计,这里讲到 L2 正则化的最小二乘估计等价于噪声和先验均为高斯分布的最大后验概率估计。
整体上来理解概率视角下的正则化项。观察 MLE 和 MAP 的目标参数公式 W ^ = a r g max W log P ( Y ∣ X , W ) \hat W={\rm arg} \max_W \log P(Y\mid X,W) W^=argmaxWlogP(Y∣X,W) 和 W ^ = a r g max W log P ( Y ∣ X , W ) + log P ( W ) \hat W={\rm arg} \max_W \log P(Y\mid X,W)+\log P(W) W^=argmaxWlogP(Y∣X,W)+logP(W) 可以发现,二者仅仅相差了一个 log P ( W ) \log P(W) logP(W) 项,也就是 MAP 比 MLE 多考虑了先验,当数据充足时考虑先验能够达到更好的效果。再对比 MLE 和 MAP 的目标函数,MAP 比 MLE 多了正则化项,目标参数公式是由目标函数得到的,因此可以认为,MAP 中正则化项起到了先验的作用。
2.4.2. L1 正则化
对于 L1 正则化,我们着重探讨 L1 正则化项为朴素最小二乘估计带来了哪些变化。
后面会对比一下 L1 正则化和 L2 正则化的区别和适用场景。
L1 正则化的目的是希望训练出稀疏的模型参数,以提高模型的特征选择的能力,进而缓解过拟合问题。
L1 正则化的最小二乘法对应的目标函数为
KaTeX parse error: Undefined control sequence: \notag at position 46: …lpha ||W||_1 \\\̲n̲o̲t̲a̲g̲ ̲&=L(W)+\alpha \…
对应的梯度(实际上是次梯度)为
∇ J ( W ) = ∇ L ( W ) + α s i g n ( W ) (32) \nabla J(W) = \nabla L(W)+\alpha {\rm sign}(W)\tag{32} ∇J(W)=∇L(W)+αsign(W)(32)
其中, s i g n ( W ) {\rm sign}(W) sign(W) 只是简单地取 W W W 各个元素的正负号。
由于绝对值函数不是处处可导,所以 L1 正则化不像 L2 正则化一样在解析解,故一般采用迭代法或近似求解。
如果紧扣梯度下降算法中“梯度”概念的话,L1 正则化,甚至是 ReLu 激活函数、max 函数等等一些列非处处可导的函数均无法使用梯度下降算法,因为这些函数在某些点是没有梯度的,也就无法保证一定可以计算出梯度,并用梯度更新模型参数。但是在实际的神经网络中,在这些无梯度的点会默认使用其“次梯度”代替梯度进行反向传播,这一部分也是被各种库完美地隐藏到我们看不见的底层了,所以认为 L1 正则化无法使用梯度下降进行更新有道理,认为可以更新也有道理。更严谨地将,L1 正则化确实无法直接使用梯度下降算法。但是有学者提出近端梯度下降(Proximal Gradient Desent,PGD)来实现 L1 正则化的梯度更新算法,具体可以参考”周志华的《机器学习》第十一章第四节 嵌入式选择与 L1 正则化“。
当然,L1 正则化可以使用不用梯度更新的迭代算法,比如坐标下降法等。另外,还可以通过泰勒展式对 L1 正则化目标函数进行二次近似,再进一步处理。
我们从近似求解的角度来理解 L1 正则化。类似于 L2 正则化中对 J ( W ) J(W) J(W) 在未引入正则化项时的最优解 W ∗ W^* W∗ 处进行泰勒展开,对式 ( 31 ) (31) (31) 进行二阶展开,结合式 ( 14 ) (14) (14),我们可以更容易地写出 L1 正则化目标函数
J ^ ( W ) = L ( W ∗ ) + 1 2 ( W − W ∗ ) H ( W − W ∗ ) + α ∣ ∣ W ∣ ∣ 1 (33) \hat J(W)=L(W^*)+\frac{1}{2}(W-W^*)H(W-W^*)+\alpha ||W||_1 \tag{33} J^(W)=L(W∗)+21(W−W∗)H(W−W∗)+α∣∣W∣∣1(33)
其中, W ∗ W^* W∗ 和 W ~ \tilde W W~ 仍然分别表示未正则化和引入正则化后目标函数的最优解。我们的目的是找到式 ( 33 ) (33) (33) 的最值,进而确定 W ~ \tilde W W~ 与 W ∗ W^* W∗ 的关系,从而理解 L1 正则化的作用。
由于 L1 正则化项在完全一般化的 Hessian 的情况下,无法得到直接清晰的代数表达式,因此我们将进一步简化假设 Hessian 是对角的,即 H = d i a g ( H 1 , 1 , … , H n , n ) H = {\rm diag}(H_{1,1}, \dots , H_{n,n}) H=diag(H1,1,…,Hn,n), 其中每个 H i , i > 0 H_{i,i} > 0 Hi,i>0。如果线性回归问题中的数据已被预处理(如可以使用 PCA),去除了输入特征之间的相关性,那么这一假设成立。
那么式 ( 33 ) (33) (33) 可以化为
J ^ ( W ) = L ( W ∗ ) + ∑ i = 1 p ( 1 2 H i , i ( w i − w i ∗ ) 2 + α ∣ w i ∣ ) (34) \hat J(W)=L(W^*)+\sum_{i=1}^p\left(\frac{1}{2}H_{i,i}(w_i-w^*_i)^2+\alpha |w_i|\right) \tag{34} J^(W)=L(W∗)+i=1∑p(21Hi,i(wi−wi∗)2+α∣wi∣)(34)
现计算式 ( 34 ) (34) (34) 的最值。创建新函数
f ( w i ) = 1 2 H i , i ( w i − w i ∗ ) + α ∣ w i ∣ (35) f(w_i)=\frac{1}{2} H_{i,i} (w_i-w_i^*)+\alpha |w_i| \tag{35} f(wi)=21Hi,i(wi−wi∗)+α∣wi∣(35)
那么式 ( 34 ) (34) (34) 可以简化表示为
J ^ ( W ) = L ( W ∗ ) + ∑ i = 1 p f ( w i ) (36) \hat J(W)=L(W^*)+\sum_{i=1}^p f(w_i)\tag{36} J^(W)=L(W∗)+i=1∑pf(wi)(36)
令 J ^ \hat J J^ 关于 W W W 的梯度等于零。 L ( W ∗ ) L(W^*) L(W∗) 与 W W W 无关,故 ∇ L ( W ∗ ) = 0 \nabla L(W^*)=0 ∇L(W∗)=0,根据式 ( 35 ) (35) (35) 可知 f ( w i ) ≥ 0 f(w_i)\ge 0 f(wi)≥0,由于 ∇ J ^ ( W ) = 0 \nabla \hat J(W)=0 ∇J^(W)=0,所以 ∇ f ( w i ) = 0 \nabla f(w_i)=0 ∇f(wi)=0( u = 1 , 2 , … , p u=1,2,\dots,p u=1,2,…,p)。令 f ( w i ) f(w_i) f(wi) 梯度为零,得
w ~ i = w i ∗ − α s i g n ( w ~ i ) H i , i (37) \tilde w_i=w_i^*-\frac{\alpha {\rm sign}(\tilde w_i)}{H_{i,i}} \tag{37} w~i=wi∗−Hi,iαsign(w~i)(37)
这里在对绝对值函数在 0 0 0 处的梯度取次梯度,故计算出的梯度表达式为 s i g n ( ⋅ ) {\rm sign}(·) sign(⋅) 。
直接表示为 w ~ i \tilde w_i w~i 关于 w i ∗ w_i^* wi∗ 的分段函数为
w ~ i = s i g n ( w i ∗ ) max { ∣ w i ∗ ∣ − α H i , i , 0 } (38) \tilde w_i={\rm sign}(w^*_i)\max\{|w_i^*|-\frac{\alpha}{H_{i,i}}, 0\} \tag{38} w~i=sign(wi∗)max{∣wi∗∣−Hi,iα,0}(38)
式 ( 38 ) (38) (38) 详细表示为
w ~ i = { w i ∗ + α H i , i w i ∗ < − α H i , i 0 − α H i , i ≤ w i ∗ ≤ α H i , i w i ∗ − α H i , i w i ∗ > α H i , i (39) \tilde w_i=\left\{\begin{matrix} w^*_i+\frac{\alpha}{H_{i,i}} & w^*_i\lt -\frac{\alpha}{H_{i,i}} \\ 0 & -\frac{\alpha}{H_{i,i}} \le w^*_i\le \frac{\alpha}{H_{i,i}} \\ w^*_i-\frac{\alpha}{H_{i,i}} & w^*_i\gt\frac{\alpha}{H_{i,i}} \\ \end{matrix}\right.\tag{39} w~i=⎩⎪⎨⎪⎧wi∗+Hi,iα0wi∗−Hi,iαwi∗<−Hi,iα−Hi,iα≤wi∗≤Hi,iαwi∗>Hi,iα(39)
对每个 i i i,考虑 w i ∗ > 0 w^∗_i > 0 wi∗>0 的情形,会有两种可能结果:
① ∣ w i ∗ ∣ ≤ α H i , i |w_i^*|\le \frac{\alpha}{H_{i,i}} ∣wi∗∣≤Hi,iα 的情况。正则化后目标中的 w i w_i wi 最优值是 w i = 0 w_i = 0 wi=0。这是因为在方向 i i i 上 L ( W ) L(W) L(W) 对 J ^ ( W ) \hat J(W) J^(W) 的贡献被抵消,L1 正则化项将 w i w_i wi 推至 0 0 0。
② ∣ w i ∗ ∣ > α H i , i |w_i^*|\gt \frac{\alpha}{H_{i,i}} ∣wi∗∣>Hi,iα 的情况。在这种情况下,正则化不会将 w i w_i wi 的最优值推至 0 0 0,而仅仅在那个方向上移动 α H i , i \frac{\alpha}{H_{i,i}} Hi,iα 的距离。
从式 ( 37 ) (37) (37) 到式 ( 39 ) (39) (39) 的推导过程,供参考。下面过程参考了各方面的资料,但是还是感觉不严谨,也可能是我数学太差。
观察到式 ( 37 ) (37) (37) 中存在符号函数,因此不可避免的要对 w ~ i \tilde w_i w~i 的符号进行讨论:
当 w ~ i > 0 \tilde w_i >0 w~i>0 时
w ~ i = w i ∗ − α H i , i > 0 w i ∗ > α H i , i \tilde w_i=w_i^*-\frac{\alpha}{H_{i,i}}>0\\ w_i^*\gt \frac{\alpha}{H_{i,i}} w~i=wi∗−Hi,iα>0wi∗>Hi,iα
当 w ~ i < 0 \tilde w_i<0 w~i<0 时
w ~ i = w i ∗ + α H i , i < 0 w i ∗ < − α H i , i \tilde w_i=w_i^*+\frac{\alpha}{H_{i,i}}<0\\ w_i^*\lt -\frac{\alpha}{H_{i,i}} w~i=wi∗+Hi,iα<0wi∗<−Hi,iα
由于我们希望得到的是 w ~ i \tilde w_i w~i 的值,因此我们将 w i ∗ w_i^* wi∗ 看作自变量, w ~ i \tilde w_i w~i 看作因变量。得到不完整的分段函数
w ~ i = { w i ∗ + α H i , i w i ∗ < − α H i , i 0 w i ∗ = 0 w i ∗ − α H i , i w i ∗ > α H i , i \tilde w_i=\left\{\begin{matrix} w^*_i+\frac{\alpha}{H_{i,i}} & w^*_i\lt -\frac{\alpha}{H_{i,i}} \\ 0 & w^*_i=0 \\ w^*_i-\frac{\alpha}{H_{i,i}} & w^*_i\gt\frac{\alpha}{H_{i,i}} \\ \end{matrix}\right. w~i=⎩⎨⎧wi∗+Hi,iα0wi∗−Hi,iαwi∗<−Hi,iαwi∗=0wi∗>Hi,iα
但是没有考虑到区间 − α H i , i ≤ w i ∗ ≤ α H i , i -\frac{\alpha}{H_{i,i}} \le w^*_i\le \frac{\alpha}{H_{i,i}} −Hi,iα≤wi∗≤Hi,iα ,在这个区间上使用刚才的讨论方法是无解的。我们重新审视 f ( w i ) f(w_i) f(wi),我们希望获得的 w i w_i wi 其实是 f ( w i ) f(w_i) f(wi) 的极小值点,所以我们可以通过讨论 ∇ f ( w i ) \nabla f(w_i) ∇f(wi) 的符号来寻找极小值点。当 w i > 0 w_i>0 wi>0 时,由于 w i ∗ ≤ α H i , i w_i^*\le\frac{\alpha}{H_{i,i}} wi∗≤Hi,iα,所以 α − H i , i w i ∗ ≥ 0 \alpha-H_{i,i}w_i^*\ge0 α−Hi,iwi∗≥0,又有 H i , i w i > 0 H_{i,i}w_i\gt 0 Hi,iwi>0,故
KaTeX parse error: Undefined control sequence: \notag at position 61: …_i^*)+\alpha \\\̲n̲o̲t̲a̲g̲ ̲&=H_{i,i}w_i - …
当 w i < 0 w_i<0 wi<0 时,由于 w i ∗ ≥ − α H i , i w_i^*\ge-\frac{\alpha}{H_{i,i}} wi∗≥−Hi,iα,所以 α + H i , i w i ∗ ≥ 0 \alpha+H_{i,i}w_i^*\ge0 α+Hi,iwi∗≥0,又有 H i , i w i < 0 H_{i,i}w_i\lt 0 Hi,iwi<0,故
KaTeX parse error: Undefined control sequence: \notag at position 61: …_i^*)+\alpha \\\̲n̲o̲t̲a̲g̲ ̲&=H_{i,i}w_i - …
通过上面的推导我们可以知道 w i = 0 w_i=0 wi=0 是 f ( w i ) f(w_i) f(wi) 的极小值,所以完整的分段函数为式 ( 39 ) (39) (39) 所示,进一步简化得到式 ( 38 ) (38) (38) 。
相比 L2 正则化,L1 正则化会产生更稀疏(sparse)的解。此处稀疏性指的是最优值中的一些参数为 0 0 0。和 L2正则化相比,L1 正则化的稀疏性具有本质的不同。式 ( 17 ) (17) (17) 给出了 L2 正则化的解 W ~ \tilde W W~。如果我们使用 Hessian 矩阵 H H H 为对角正定矩阵的假设(与 L1 正则化分析时一样),重新考虑这个等式,我们发现 w ~ i = H i , i H i , i + α w i ∗ \tilde w_i=\frac{H_{i,i}}{H_{i,i}+\alpha}w_i^* w~i=Hi,i+αHi,iwi∗ 。如果 w i ∗ w^∗_i wi∗ 不是零,那么 w ~ i \tilde w_i w~i 也会保持非零。这表明 L2 正则化不会使参数变得稀疏,而 L1 正则化有可能通过足够大的 α α α 实现稀疏。
常用图 6 6 6 直观上来对比理解 L1 正则化和 L2 正则化。黑色实线内为可行域,彩色椭圆实线为未正则化目标函数等值线(未画出继续外延的等值线)。L1 正则化倾向于将权重的某些维度缩放至 0 0 0,而 L2 正则化更倾向于将权重缩小,而非缩放至 0 0 0,且初始非零的维度一定不会被缩放到 0 0 0。
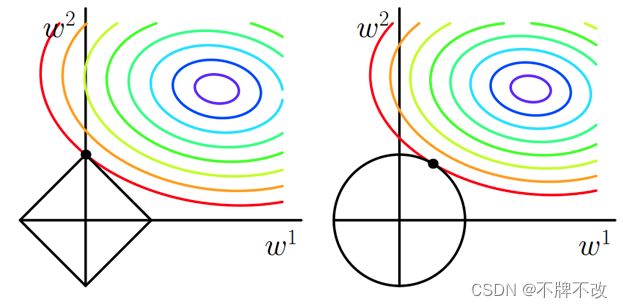
图 6 L1 正则化(左)和 L2 正则化(右)的图线理解例图
由 L1 正则化导出的稀疏性质已经被广泛地用于特征选择(feature selection)机制。特征选择从可用的特征子集选择出有意义的特征,化简机器学习问题。著名的 LASSO(Least Absolute Shrinkage and Selection Operator)模型将 L1 惩罚和线性模型结合,并使用最小二乘代价函数。L1 惩罚使部分子集的权重为零,表明相应的特征可以被安全地忽略。
在概率视角下的 L2 正则化可以认为是先验为高斯分布的 MAP,而 L1 正则化可认为是先验为拉普拉斯分布的 MAP。一般拉普拉斯分布为
L a p l a c e ( x ; α , β ) = 1 2 β e − ∣ x − α ∣ β {\rm Laplace}(x;\alpha, \beta)=\frac{1}{2\beta}e^{-\frac{|x-\alpha|}{\beta}} Laplace(x;α,β)=2β1e−β∣x−α∣
假设 w i ∼ L a p l a c e ( 0 , 1 α ) w_i\sim {\rm Laplace}(0,\frac{1}{\alpha}) wi∼Laplace(0,α1),那么先验对目标函数的贡献为
KaTeX parse error: Undefined control sequence: \notag at position 87: …c{1}{\alpha})\\\̲n̲o̲t̲a̲g̲ ̲&=\sum_{i=1}^p …
因为是关于 W W W 最大化进行学习,我们可以忽略 log α − log 2 \log α − \log 2 logα−log2 项,因为它们与 W W W 无关。
2.4.3. 总结与对比
- 添加正则化相当于参数的解空间添加了约束,限制了模型的复杂度;正则化参数 α \alpha α 越大,约束越严格,太大容易产生欠拟合。正则化参数 α \alpha α 越小,约束宽松,太小起不到约束作用,容易产生过拟合。
- L1 正则化的形式是添加参数的绝对值之和作为结构风险项,L2 正则化的形式添加参数的平方和作为结构风险项。
- 从稀疏性上来讲,L1 正则化鼓励产生稀疏的权重,即使得一部分权重为零,用于特征选择;L2 正则化鼓励产生小而分散的权重,让模型做决策的时候考虑更多的特征,而不是仅仅依赖强依赖某几个特征,可以增强模型的泛化能力,防止过拟合。 稀疏的解除了计算量上的好处之外,更重要的是更具有可解释性。如果不是为了进行特征选择,一般使用L2正则化模型效果更好。
- 从计算效率上来讲,L1 正则化没有一个解析解(analytical solution),但是 L2 正则化有,这使得 L2 正则化可以被高效的计算。可是,L1 正则化的解有稀疏的属性,它可以和稀疏算法一起用,这可以使计算更加高效。
- 从鲁棒性上来讲,概括起来就是 L1 正则化对异常点不太敏感,而 L2 正则化则会对异常点存在放大效果。最小绝对值偏差(LAD)的方法应用领域很广(L1 正则化),相比最小均方的方法(L2 正则化),它的鲁棒性更好,最小绝对偏差能对数据中的异常点有很好的抗干扰能力,异常点可以安全的和高效的忽略,这对研究帮助很大。如果异常值对研究很重要,最小均方误差则是更好的选择。对于 L2 正则化,由于是均方误差,如果误差 > 1 >1 >1 的话,那么平方后,相比 L1 正则化而言,误差就会被放大很多。因此模型会对样例更敏感。如果样例是一个异常值,模型会调整最小化异常值的情况,以牺牲其它更一般样例为代价,因为相比单个异常样例,那些一般的样例会得到更小的损失误差。
另外,正则化除了 L1、L2 之外,还有神经网络中的 Dropout 正则化和 Batch Normalization 正则化,感兴趣的读者可以自行学习。
REF
[1] 《统计学习方法(第二版)》李航著
[2] Deep Learning 中文版
[3] 【机器学习】左逆、右逆、伪逆和广义逆的概念理解 - CSDN博客
[4] 机器学习-白板推导系列(三)-线性回归(Linear Regression) 笔记 - 知乎
[5] 机器学习-白板推导系列-线性回归 - bilibili
[6] “L1和L2正则化”直观理解 - bilibili
[7] 线性回归详解 - CSDN博客
[8] 频率派与贝叶斯派_强强学习的博客 - CSDN博客
[9] 拉格朗日乘法和L1、L2正则化 - CSDN博客
[10] 正则化为什么可以防止过拟合 - CSDN博客
[11] Chap 7深度学习中的正则化——L1正则化公式推导 - CSDN博客
[12] 花书教我明白伤痛——L1正则 (miracledave.com)
[13] 正则化详解 - 早起的小虫子 - 博客园