CVPR 2022 | GEN-VLKT:基于预训练知识迁移的HOI检测方法

近日,阿里巴巴大淘宝技术多媒体算法团队与计算机视觉青年学者刘偲教授团队合作论文:《GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection》 被CVPR 2022接收。
CVPR全称为IEEE国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition)。作为计算机视觉领域最负盛名的顶级学术会议,CVPR每年吸引大量研究机构及高校等参与其中。今年CVPR共收到8161篇有效论文投稿,录用2067篇,录用率为25.33%。
本文在业界首次将大规模预训练模型的海量数据中蕴含的丰富信息知识迁移到HOI检测任务,单模型刷新了通用(Regular)和零样本(Zero-Shot)双任务的SOTA指标。
动机
人物交互关系检测(Human-Object Interaction Detection, HOI)存在两个核心问题:人-物关联(human-object association)和关系理解(interaction understanding)。我们分别在这两个核心问题上设计方案,整体如图1所示。
在人-物关联方面,传统两分支(two-branch)方法需要复杂且耗时的后处理,而单分支(single-branch)方法采用的统一特征造成了多任务的相互干扰。我们提出了GEN(Guided-Embedding Network)结构,通过引入位置引导(position Guided Embedding,p-GE)和实体引导(instance Guided Embedding, i-GE),实现了避免后处理的特征解耦的两分支结构。
在关系理解方面,传统方法受数据长尾分布影响严重,也缺乏零样本(Zero-Shot)发现能力。我们设计了VLKT(Visual-Linguistic Knowledge Transfer)训练策略,通过迁移大规模图文数据预训练模型CLIP中蕴含的知识,增强对交互关系的理解,提升零样本理解能力。

图 1:整体流程示意图
方法
在人-物关联方面,图2显示了我们设计的GEN结构框架。我们采用基于transformer的HOI检测器来实现我们的设计,并使用了DETR [1]的基础模型结构。在这个结构中,N层解码器把视觉编码器输出的特征和一系列可学习的输入查询query向量作为输入。我们设计了实体解码器和关系解码器并行的两分支结构。
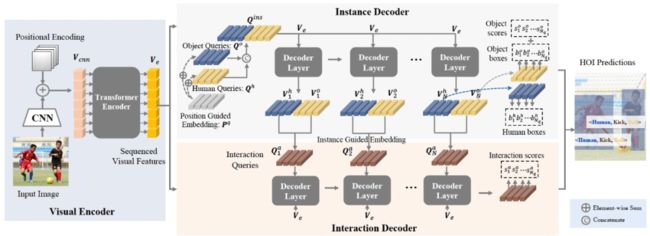
图2:Guided-Embedding Network (GEN)框架图
对于实体解码器,每个实体查询向量![]() 由人体查询向量
由人体查询向量![]() 和物体查询向量
和物体查询向量![]() 组合而成,并引入了一个位置引导向量
组合而成,并引入了一个位置引导向量![]() ,用来把相同位置的人体和物体向量关联成一个匹配对。
,用来把相同位置的人体和物体向量关联成一个匹配对。![]() 可以表示为:
可以表示为:

对于关系解码器,我们逐层采用实体查询向量的解码特征![]() 来指导关系查询向量,
来指导关系查询向量,![]() 表示第k个关系解码器decoder layer的输入查询向量,表示为:
表示第k个关系解码器decoder layer的输入查询向量,表示为:
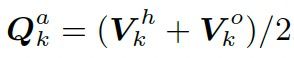
这样,实体解码器和关系解码器的解码特征一一匹配,可以在没有后处理条件下预测HOI三元组。
在关系理解方面,如图3所示,我们引入了大规模预训练模型CLIP[2],提出了VLKT训练策略用于增强关系理解。

图3:用于解码器的Visual-Linguistic Knowledge Transfer (VLKT)框架图
首先,我们引入CLIP文本编码器来增强关系分类。我们构造了物体和关系的prompt模板,把HOI三元组label转成完整语句,在使用CLIP文本编码器提取语句特征,用来初始化关系分类器的权重参数。即,视觉特征![]() 与CLIP文本特征
与CLIP文本特征![]() 计算相似度,作为关系分类分数输出
计算相似度,作为关系分类分数输出![]() :
:

其次,我们引入了CLIP视觉编码器用来蒸馏关系解码器的视觉特征。我们把图像输入到CLIP视觉编码器,提取全局特征![]() ,作为知识蒸馏的教师(teacher)监督,学生(student)特征为交互解码器输出的视觉特征的平均池化。我们采用
,作为知识蒸馏的教师(teacher)监督,学生(student)特征为交互解码器输出的视觉特征的平均池化。我们采用![]() 损失函数来计算这个全局知识蒸馏损失:
损失函数来计算这个全局知识蒸馏损失:
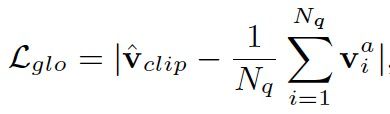
最后,训练过程采用了基于集合匹配的方式,匹配过程对实体解码器和关系解码器统一端到端匹配。损失函数如下,包含检测框回归![]() ,检测框交并比
,检测框交并比![]() 和类别损失
和类别损失![]() :
:

最终的损失函数由这部分损失函数和VLKT的知识蒸馏损失一起构成,表示为:

实验
如表1,我们在HICO-DET数据集[3]上验证了三种参数量的GEN-VLKT,效果超过了全部已知的“从底到上”和“自顶而下”方法,在不使用人体关键点和语言特征等额外特征的情况下,最高指标达到了34.95 mAP。
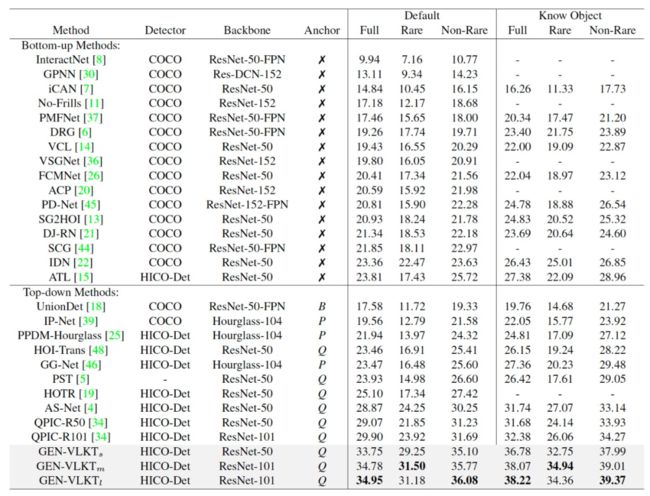
表1:HICO-Det数据集Regular任务实验结果
如表2,GEN-VLKT在V-COCO数据集[4]上同样达到了SOTA效果,Scenario 1的role mAP为63.91,Scenario 2的role mAP为65.89。

表2:V-COCO数据集Regular任务实验结果
如表3,GEN-VLKT在多种设置的Zero-Shot任务上,都取得了大幅领先以往SOTA的结果。得益于VLKT的知识迁移训练策略,我们在类别不可见(Unseen)部分的评估中,获得了较强的零样本发现能力。

表3:HICO-Det数据集Zero-Shot任务实验结果
表4展示了消融实验结果。GEN结构中的p-GE和i-GE提升了人-物关联,进而提升了指标。VLKT中的CLIP文本编码器来分别初始化交互分类器和物体分类器,以及CLIP视觉编码器来知识蒸馏视觉特征,都促进了对关系交互的理解。知识蒸馏在损失函数下获得了最佳性能。

表4:消融实验
图4显示了GEN-VLKT的可视化特征。特征图显示了human query,object query和interaction query实现了很好的特征解耦,特征分别集中在了人体边缘、物体边缘和人-物动作交互区域。
图4:可视化特征图
总结
本文从人-物关联和关系理解两方面优化人-物关系检测HOI任务,提出了GEN-VLKT架构,通过特征引导机制来实现没有后处理的特征解耦的并行两分支结构,通过引入大规模预训练模型CLIP的海量知识迁移来实现对交互关系的增强理解,使得模型具备更好的零样本发现能力。本文以单模型刷新了HOI领域的通用(Regular)和零样本(Zero-Shot)双任务的SOTA指标。相关算法在大淘宝内容理解业务中落地应用,如点淘种草标签、直播类目标签等。
Reference
[1] End-to-end object detection with transformers. In ECCV, 2020.
[2] Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[3] Learning to detect human-object interactions. In WACV, 2018.
[4] Visual semantic role labeling. arXiv preprint arXiv:1505.04474, 2015.
[5] Mining the benefits of two-stage and one-stage hoi detection. In NIPS, 2021.
团队介绍
大淘宝技术-内容算法–内容理解团队,依托大淘宝数⼗亿级的视频数据,业务上支持淘宝直播、逛逛和点淘等淘系核心业务,团队成员近两年参加CVPR、ICCV等顶会竞赛获得6项冠军,技术累积在计算机视觉顶会期刊如NIPS、CVPR、TPAMI、TIP、MM等发表论文10余篇。
✿ 拓展阅读


作者|少麟
编辑|橙子君

