姿态估计之2D人体姿态估计 - SimDR: Is 2D Heatmap Representation Even Necessary for Human Pose Estimation?
转自
[论文阅读:姿态识别] 2107 SimDR: Is 2D Heatmap Representation Even Necessary for Human Pose Estimation?_cheerful090的博客-CSDN博客
告别Heatmap,人体姿态估计表征新方法SimDR - 知乎
来自清华大学、旷视、东南。这篇与上一篇 TokenPose来自同一研究团队。
paper https://arxiv.org/pdf/2107.03332.pdf
github https://github.com/leeyegy/SimDR
SimDR主要研究了关键点坐标表示。将关键点坐标进行解耦坐标表征,将关节位置的x、y坐标分解为两个独立的一维向量,将关键点定位任务视为水平方向和垂直方向的分类子任务。和普通的基于热图或者基于回归的坐标表示方法不一样。 提出了普通SimDR和空间感知的SimDR两个版本。
- Top-down模式 没有复杂的后处理,比如不需要反卷积,利于姿态识别网络的轻量化实现。
- 通用性好。可以和一般的CNN或者Transformer框架结合,优于基于热图的同类算法;在低分辨率情况下,效果很好。
摘要:
二维热图表示由于其高性能,多年来一直主导着人体姿态估计。然而,基于热图的方法也存在一些不足:1)对于现实场景中经常遇到的低分辨率图像,性能急剧下降。2)为了提高定位精度,可能需要多个上样层来恢复由低到高的feature map分辨率,计算成本较高。3)通常需要额外的坐标细化,以减少缩小比例的热图的量化误差。为了解决这些问题,我们提出了一种简单而有前途的关键点坐标解耦表示(a Simple yet promising Disentangled Representation for keypoint coordinate,SimDR),将人体关键点定位重新定义为一种分类任务。具体而言,我们建议将关键点位置的水平和垂直坐标表示进行分解,从而获得一种更有效的方案,而无需额外的上采样和细化。在COCO数据集上进行的综合实验表明,本文提出的无热图方法在所有测试的输入分辨率上都优于基于热图的方法,特别是在较低分辨率下,其性能明显优于基于热图的方法。
1.Introduction
二维人体姿态估计(Human Pose Estimation,HPE)旨在从单个图像中定位人体关节。目前常用的方法是采用编码器-解码器流水线来估计关键点的位置。由于深度卷积神经网络(CNN)具有良好的性能,大多数方法都采用它作为特征编码器。在解码器部分,现有的方法主要分为两大类:基于heatmap的方法和基于回归的方法。大多数情况下采用前者。
直接回归关节的数值坐标是定位关键点最直接的方法。数值回归趋向于简单和计算友好。然而,它缺乏空间泛化,导致在大多数棘手的情况下,预测结果较差。
另一种方法是将关节坐标编码成2D热图。由于其在无约束情况下的显著性能,基于heatmap的方法已经自然成为HPE事实上的标准标签表示。热图由Ground-truth关节点为中心的二维高斯分布生成。基于热图的坐标表示抑制了假正例,并通过为每个位置分配一个概率(不确定性)值,从而使训练过程更加平滑,从而比基于回归的方法实现了显著的改进。
然而,基于热图的方法有几个缺点。首先,要输出2D热图,总是需要进行代价高昂的上采样操作(如SimpleBaselines中的反卷积层)。其次,为了减小热图到GT的投影误差,不可避免地需要额外的后处理来进一步细化结果。最后,基于热图的方法的性能通常会随着输入分辨率的降低而急剧下降。例如,我们观察到,当降低输入分辨率时,如输入像从256x192降为64x64时,HRNet-W48的性能从75.1 AP下降到48.5 AP。在低输入分辨率的情况下,基于热图的方法的优点往往被其量化误差所掩盖,导致性能低下。
因此,我们提出了一个问题: 水平和垂直关键点坐标的联合编码的2D热图表示对于保持卓越的性能是必要的吗?(is the 2D heatmap representation that jointly encodes horizontal and vertical keypoint coordinates necessary for sustaining superior performance?)
我们受到了最近基于transformer的人体姿态估计方法的启发[TokenPose 17, Transpose 38],这些方法也采用了2D heatmap作为输出。然而,与典型的全卷积网络(Fully Convolutional Network, FCN)架构不同的是,它们并没有在整个管道中始终保持特征图的2D结构。特别是,TokenPose[17]使用一个共享的MLP来预测2D热图,其中每种类型的关键点热图都是从关键点tokens (1D向量)转换而来的。此外,[7]还提出了压缩体积热图,它可以在压缩代码中编码多人关键点位置,并通过解码器恢复它们的位置。这些结果表明,具有显式空间结构的热图表示可能不是编码位置信息的必要条件。

**表1:heatmap与SimDR的比较。**H和W分别表示输入图像的高度和宽度。λ是下采样比,通常设为4。K(≥1)为分裂因子(splitting factor)。
为了进一步研究关键点表示的有效性,我们提出了一种用于**人体姿态估计的简单解耦坐标表示(SimDR)**方法。SimDR将关键点的(x, y) 坐标编码成两个独立的1D向量,且量化等级与输入图像相同或更高。不同坐标表示方案之间的比较如图1所示。

图1:不同坐标表示方案的比较。H,W为原始输入图像的高度和宽度。λ(∈{1,2,4,…})是二维热图的下采样比,在SimpleBaseline、Hourglass或HRNet等常用方法中,通常设置为4。k(≥1)为SimDR的分裂因子。
我们将SimDR应用于典型的基于CNN或基于Transformer的人体姿态估计模型,在各种输入分辨率条件下,特别是在低分辨率输入下,获得了比二维热图表示更好的结果。我们希望这个简单的基线能够激励大家重新思考二维人体姿态估计的坐标表示设计。我们的贡献总结如下:
Contributions
-
提出了一种新的关键点位置表示方法,该方法将关键点的x、y坐标表示分解为两个独立的一维向量。它将关键点定位任务视为水平方向和垂直方向分类的两个子任务。与基于热图的方法相比,我们的方法的优点如表1所示。
-
提出的SimDR允许人们去除一些方法中耗时的上采样模块。应用SimDR并去除反卷积模块,SimBa-Res50[37]的GFLOPs大大减少了55%以上,并获得了更高的模型性能(见表4)。
-
在COCO关键点检测数据集[18]、CrowdPose[14]和MPII[1]三个数据集上进行了综合实验。提出的SimDR首次将无热图方法达到和基于热图方法的竞争性能水平,在低输入分辨率情况下大大优于后者。
2. 相关工作
基于回归的2D姿态识别 基于回归的方法在二维人体姿态估计的早期阶段进行了探索。不同于依赖于二维网格状热图,这条工作线直接在一个计算友好的框架中回归关键点坐标。然而,基于回归的方法缺乏空间泛化能力[23]。因此,基于回归的方法和基于热图的方法之间存在着巨大的(精度)差距,这限制了它的实际应用。
基于热图的2D姿态识别 另一条工作线采用二维高斯分布(即heatmap)表示关节坐标。热图上的每个位置都有一个概率赋值为Ground Truth。作为heatmap最早的应用之一,thompson et al.[33]提出了一个由深度卷积网络和马尔可夫随机场组成的混合架构。Stacked Hourglass将沙漏式结构引入HPE。Papandreou et al.[26]提出将热图和偏移量预测进行聚合,以提高定位精度。SimpleBaselines提出了一个简单的基线,利用ResNet Backbone进行特征提取,之后使用三个反卷积层进行上采样来获得最终的预测热图。HRNet提出了一种新颖的网络,在整个过程中保持高分辨率的表示,取得了显著的改进。此外,DARK引入了分布感知的坐标表示来处理降尺度热图的量化误差。由于空间不确定性的介入,这种学习模式具有对抖动错误的容忍度。当后处理进行坐标迁移优化后,假正例减少。因此,基于热图的方法多年来保持稳定的最先进的性能。然而,量化误差仍然是基于热图的方法的一个重要问题,特别是在低输入分辨率的情况下。此外,在实际的部署场景中,额外的后处理是复杂和昂贵的。相比之下,本文提出的SimDR很好地解决了这些问题,并在各种输入分辨率上取得了显著的提高。
3. 框架总览
在本节中,我们首先回顾基于热图的坐标表示。然后,我们举例说明提出的**简单解纠缠坐标表示(SimDR)**的人关键点坐标。本文主要研究了多人姿态估计的自顶向下(Top-down)范式。

图2. 将SimDR与给定的神经网络相结合的示意图。当使用像SimpleBaseline或HRNet这样的神经网络作为编码器时,关键点嵌入(Embedding),![]() ,通过将feature map的形状重新排列成
,通过将feature map的形状重新排列成![]() ,其中n为关键点类型的个数。然后,SimDR head作为一个共享的线性投影层(linear projection),将每个嵌入(Embedding)转化为两个长度为W·k和H·k的一维向量(
,其中n为关键点类型的个数。然后,SimDR head作为一个共享的线性投影层(linear projection),将每个嵌入(Embedding)转化为两个长度为W·k和H·k的一维向量(![]() )。
)。
3.1. 基于热图的坐标表示
作为人体姿态估计中事实上的标准坐标表示,heatmap采用空间置信度分布来表示关键点坐标。得到的热图按照二维高斯分布设计:
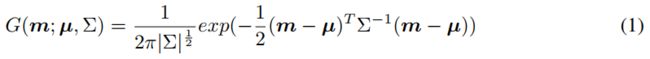
其中m为位置 ![]() 的热图像素,µ为目标关节位置。Σ是一个预定义的对角协方差矩阵。请注意,每个输出的热图都表示一个特定关键点的空间分布。最终的坐标由预测热图的最大值索引求得。
的热图像素,µ为目标关节位置。Σ是一个预定义的对角协方差矩阵。请注意,每个输出的热图都表示一个特定关键点的空间分布。最终的坐标由预测热图的最大值索引求得。
3.2. SimDR:从分类的角度重新进行关节点定位
在SimDR中,x坐标和y坐标分别解耦成一维向量,而不是联合编码。
坐标编码 给定一张输入图像(尺寸为HxWx3),我们将第p类的ground truth关节点坐标表示为![]() 。为了增强定位精度,我们引入了一个splitting factor缩放因子k(>=1),并且重新放缩Groung truth坐标为一个新的坐标:
。为了增强定位精度,我们引入了一个splitting factor缩放因子k(>=1),并且重新放缩Groung truth坐标为一个新的坐标:
关键点的x和y坐标通过两条独立的一维向量来进行表征,通过一个缩放因子k(>=1),得到的一维向量长度也将大于等于图片边长。对于第p个关键点,其编码后的坐标将表示为:
![]()
其中round(.)是舍入函数。缩放因子k能够增强亚像素(sub-pixel)水平的定位精度。此外,监督信息被定义为
![]()
![]()

其中![]() ,
,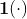 表示指示函数(为0或为1),
表示指示函数(为0或为1), ![]() 都是一维向量, 其维度分别为
都是一维向量, 其维度分别为 ![]() ,其中W,H为输入图像的长宽,k是缩放因子splitting factor。缩放因子k的作用是将定位精度增强到比单个像素更小的级别
,其中W,H为输入图像的长宽,k是缩放因子splitting factor。缩放因子k的作用是将定位精度增强到比单个像素更小的级别
坐标解码 对于某一个关键点,模型输出为2个一维向量 ![]() ,最终预测坐标
,最终预测坐标![]() 计算如下所示:
计算如下所示:
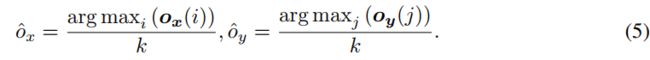
即,一维向量上最大值点所在位置除以缩放因子还原到图片尺度。
经历了lambda次下采样的高斯热图,量化误差级别为![]() ,而本文的方法级别为
,而本文的方法级别为![]() 。
。
其中 是热图的将采样率
是热图的将采样率
网络架构 如图2所示,SimDR表示要求神经网络架构输出n个关键点嵌入(n是关键点类型的数量),并附加一个线性层,将每个关键点嵌入投影到两个固定长度的1D向量中。因此,该方法可以与任何常见的基于CNN或基于Transformer的神经网络相结合,学习强大的特征表示。
在清楚了原理后,SimDR的头部结构也就非常直观了,n个关键点对应n个embedding,也就是网络输出n条一维向量,再通过线性投影(MLP等)为n个SimDR表征。
具体地讲,对于CNN-based模型,可以将输出的特征图拉直为d维的一维向量,再通过线性投影把d维升高到W*k维和H*k维。而对于Transformer-based模型,输出则已经是一维向量,同样地进行投影即可。
训练和损失函数 由于SimDR将关键点定位任务视为一种分类任务,因此可以利用通用的分类损失函数来代替二维热图表示中均方误差(MSE)损失。我们使用交叉熵损失来训练模型。(标签的平滑化被采用以帮助模型训练)
训练target和目标函数
很自然地可以发现,本文的方法将关键点定位问题转化为了分类问题,因而目标函数可以使用相较于L2(MSE) Loss 性质更优的分类loss,简单起见本文使用了交叉熵。
一点私货:将定位问题转化为分类问题其实之前已经有大量的工作,比如Generalized Focal Loss工作中提出的Distribution Focal Loss,便是利用向量分布来表征bbox坐标点的位置,在轻量和精度上均取得了优异的成绩,也衍生出了有名的开源项目Nanodet。
3.3. 先进的空间感知的SimDR
上面所述的SimDR存在一个问题,即作为分类问题标签是one-hot的,除了正确的那一个点外其他错误坐标是平等,会受到同等的惩罚,但实际上模型预测的位置越接近正确坐标,受到的惩罚应该越低才更合理。因此,本文进一步提出了升级版SimDR,通过1D高斯分布来生成监督信号,使用KL散度作为损失函数,计算目标向量和预测向量的KL散度进行训练:
如上所示,SimDR对假标签的处理是平等的,忽略了关键点定位任务中相邻标签的空间相关性。为了解决这个问题,我们提出了SimDR的高级变体,称为SimDR∗,它以一种空间感知的方式生成监督信号: 同样使用了高斯函数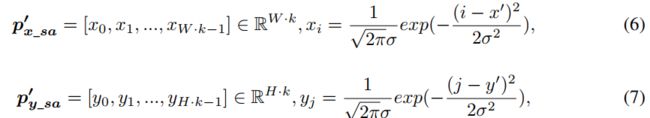
其中σ是标准差。我们使用KL散度(Kullback–Leibler divergence)进行模型训练。
4. 实验结果
在下面的章节中,我们将实证地研究提出的SimDR对于二维人体姿态估计的有效性。我们在三个基准数据集上进行了实验:COCO [18], CrowdPose[14]和MPII[1]。在CrowdPose和MPII上的结果在附录中。
4.1. COCO关键点检测
使用COCO数据集,Object Keypoint Similarity(OKS)作为评价指标。
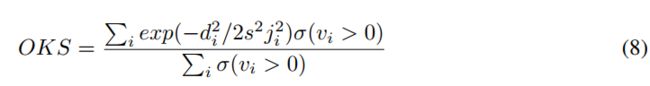
Baselines 有许多基于cnn和最近基于Transformer的HPE方法。为了展示提出的SimDR的优越性,我们从前者中选择了两种最先进的方法(即SimpleBaseline[37]和HRNet[29]),从后者中选择了一种(即TokenPose[17])作为我们的基线
实现细节 对于选定的Baselines,我们按照他们论文中的原始设置。具体来说,对于SimpleBaseline[37],设置基础学习率为1e−3,在90和120时分别降为1e−4和1e−5。对于HRNet[29],设置基础学习率为1e−3,在第170和200个epoch时降低为1e−4和1e−5。对于SimpleBaseline[37]和HRNet[29],总训练过程分别在140和210个epoch内终止。注意,TokenPose-S的训练过程遵循[29]。
在本文中,我们使用两阶段的自顶向下人体姿态估计:首先检测人体实例,然后估计关键点。对于COCO验证集,我们采用[37]提供的AP率为56.4%的人体检测器。实验在8个NVIDIA Tesla V100 gpu上进行。

表2. 在COCO验证集上比较heatmap和提出的SimDR,使用相同的人体检测器。Extra post. =额外的后处理,以细化预测的关键点坐标。 (所以这个额外的后处理指的是什么?
4.1.1 2D heatmap vs. 1D SimDR
在这一部分中,我们对使用SimDR作为坐标表示方案与热图表示方案相比的优越性进行了全面的研究。这些比较是从复杂性、性能和速度的角度进行的。

表3. 在COCO验证集上具有更高输入分辨率的结果。与基于热图的方法不同,基于SimDR的方法不需要额外的后处理来细化预测坐标。SimDR∗是SimDR的高级空间感知变体。
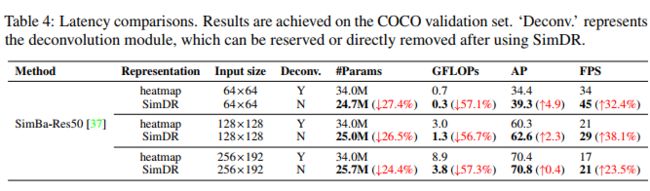
表4. 延迟比较。结果在COCO验证集上实现。“Deconv.'表示反卷积模块,使用SimDR后可保留或直接删除。
算了下计算量的确降了这么多,但(疑问:为什么GFLOPs能降这么多呀?难道不是只去除了3层反卷积层嘛,前面的ResNet50 Backbone不是不变的嘛?
坐标表示复杂度 给定一幅大小为H ×W× 3的图像,基于heatmap的方法旨在获得大小为![]() 的二维热图,其中 λ 是下采样率,是个常数。因此,heatmap表示的尺度复杂度为O(H×W)。相反,基于SimDR的方法旨在生成两个大小分别为H·k和W·k的一维向量。考虑到k是一个常数,SimDR表示的复杂度为O(H + W),比heatmap的效率高得多。特别是,SimDR允许一些方法直接去除额外的独立反卷积模块,从而显著降低了模型参数和GFLOPs。
的二维热图,其中 λ 是下采样率,是个常数。因此,heatmap表示的尺度复杂度为O(H×W)。相反,基于SimDR的方法旨在生成两个大小分别为H·k和W·k的一维向量。考虑到k是一个常数,SimDR表示的复杂度为O(H + W),比heatmap的效率高得多。特别是,SimDR允许一些方法直接去除额外的独立反卷积模块,从而显著降低了模型参数和GFLOPs。
通用性和多尺度鲁棒性 我们通过实验研究提出的SimDR在COCO验证集上的通用性和鲁棒性(各种模型和输入分辨率)。我们选择一些性能最好的基于CNN和基于Transformer的方法作为我们的基线。表2给出了二维热图和一维SimDR的比较,表明所提出的方法始终能够提供显著的性能增益,特别是在低分辨率输入情况下。
需要注意的是,与基于heatmap的方法不同,基于SimDR的方法不需要额外的后处理(如经验性的第二高值移除策略[Stacked hourglass 22])来提高预测关节位置的精度。本文以目前最先进的HRNet-W48[29]为例,说明了该方法的优越性。在64×64的输入大小下,SimDR比基于heatmap的具有额外后处理的SimDR分别提高了11.2 AP和22.8 AP。128×128和256×192的输入大小分别改进为3.1/8.7 AP和0.8/2.8 AP。
推理延时分析 我们讨论了我们提出的SimDR对**SimpleBaseline[37]、TokenPose-S[17]和HRNet-W48[29]**推理延迟的影响。这里的“推理延迟”指的是模型前馈的平均时间消耗(我们计算了300个batchsize=1的样本)。我们采用FPS来定量地说明推理延迟。CPU实现结果在同一台机器(Intel® Xeon® Gold 6130 CPU @ 2.10GHz)上呈现。
SimpleBaseline[37]采用上采样模块获得分辨率为1/4的2D热图,包含三个耗时的反卷积层(反卷积部分竟然占用了这么多计算量)。由于使用SimDR作为坐标表示而不使用热图表示,上采样模块可以被删除。表4显示了SimpleBaseline在COCO验证集上的结果。我们可以看到,采用SimDR可以去除SimpleBaseline中代价高昂的反卷积层。通过这种方式,SimDR贡献4.9 AP增益,显著降低了模型参数和GFLOPs (27.4%;57.1%),在输入大小为64 x 64时,速度提高了32%。表4说明了SimDR可以一致地降低不同输入分辨率的计算成本。
由于SimpleBaseline[37]使用编码器-解码器体系结构,我们可以用SimDR的线性投影头替换其解码器部分(反卷积)。但对于HRNet[29]和TokenPose[17],它们没有额外的独立模块作为解码器。为了对它们应用SimDR,我们直接在原来的HRNet上附加一个额外的线性层,并用一个线性层替换TokenPose的MLP头部。这些都是对原始架构的微小改变,因此只给HRNet[29]带来了少量的计算开销,甚至降低了TokenPose[17]的计算开销(见模型参数)。因此,SimDR对HRNet或TokenPose的推理延迟只有轻微的影响。例如,使用heatmap或SimDR的HRNet-W48在输入大小为256×192时的FPS几乎相同(4.5/4.8)。
4.1.2 与SOTA比较
COCO验证集上的结果。我们在COCO验证集上进行了大量的实验来比较基于heatmap和提出的SimDR,如表2所示。在各种最先进的模型和输入分辨率中,SimDR显示了与基于热图的模型相比一致的性能优势,无需额外的后处理来细化预测的关键点坐标。你可以在4.1.1节中看到更多的细节和讨论。
SimDR的性能边界在哪里? 为了探索提出的SimDR及其高级变体空间感知SimDR*的性能边界,我们比较了它们在更高输入分辨率下的结果,如表3所示。对于SimpleBaseline-Res50 [37], SimDR比基于热图的表示提供0.8分的增益(更多结果见附录A)。而对于输入大小为384 x 288的HRNet-W48[29],朴素SimDR会导致性能下降。结果表明,在朴素SimDR模型中,对假标签进行同等处理是次优的,这可能会导致在非常大的输入大小下,对容量较大的模型进行过拟合。如表3所示,我们可以看到这个问题被提出的空间感知SimDR解决了,该SimDR考虑了相邻标签的空间相关性。具体来说,在输入大小为384 x 288时,SimDR比基于heatmap的HRNet-W48[29]提高了0.6点。从朴素SimDR向空间感知SimDR的转变可能表明,通过使用更精心设计的损失函数或监督信号,SimDR的性能边界仍有进一步提升的空间。
COCO test-dev set上的结果。我们在表5中报告了我们的方法和其他最先进的方法的结果。根据对heatmap的依赖程度,我们进一步将现有的方法分为基于heatmap的方法、混合表示方法和无heatmap的方法。同时使用热图表示和坐标(或偏移等)表示作为监督信号的方法[25,24,32,36,DERK 9,TFPose 20]被认为是“混合表示”方法。
表5的结果表明,本文提出的SimDR首次弥合了基于heatmap和无heatmap方法之间的差距。具体来说,作为一种无热图的方法,SimDR∗在输入尺寸384×288上获得了76.0 AP,大大超过了PRTR[15] (↑3.9)。此外,即使与基于热图的对应版本相比,SimDR∗仍然在384×288的输入大小上显示了0.5个点的改进。

表5. COCO test-dev set的结果。’‘Trans.’’ 代表Transformer的缩写。“Hybrid representation”表示同时使用二维热图和绝对坐标(或偏移量等)作为监督信号的方法。
4.2. 消融实验
分析分裂因子k。回顾3.2节,优化SimDR时只有一个超参数,即分裂因子k。我们指出,k控制着SimDR中联合位置的亚像素精度水平。其中,k越大,SimDR的量化误差越小。然而,当k增加时,模型训练变得更加困难。因此,在量化误差和模型性能之间存在权衡。
我们基于SimpleBaseline[37]和HRNet[29]在各种输入分辨率下测试k∈{1,2,3,4}。如图3所示,随着k的增大,模型性能呈现先增大后减小的趋势。对于HRNet-W32 [29], 128×128和256×192输入大小的推荐设置为k = 2。对于SimBa-Res50 [37], 128×128和256×192输入大小的推荐设置分别为k = 3和k = 2。
5. 讨论
SimDR允许人们直接删除一些方法中耗时的上采样模块,这可能会导致HPE的轻量级架构。我们在各种神经网络上的大量实验也反映了姿态估计模型可以被看作两个部分: 一个编码器学习良好的嵌入,一个头将嵌入转换成关键点坐标编码。这可能鼓励未来的研究探索更有效的设计神经网络作为编码器和更多潜在的坐标编码方案。
另一个方向是将SimDR应用于自底向上(bottom-up)的多人姿态估计,由于多人的存在,从两个解纠缠向量中解码联合候选位置时产生了识别模糊。未来的工作很可能会引入x和y维度之外的新维度来解决这个问题。
6. 结论
在本文中,我们探索了一种简单而有前途的坐标表示(即SimDR)。该方法将关节位置的x、y坐标分解为两个独立的一维向量,将关键点定位任务视为水平方向和垂直方向的分类子任务。实验结果表明,二维结构可能不是坐标表示的关键因素,以维持优越的性能。提出的SimDR在模型性能和后处理步骤的简单性方面比基于热图的表示具有优势。同时,也为HPE轻量化模型设计提供了新的思路。我们证明了SimDR可以很容易地与任何基于CNN或基于Transformer的普通神经网络集成。综合实验表明,所提出的SimDR是通用的,在所有情况下都优于基于热图的同类算法,特别是在低输入分辨率的情况下。
附录
具体内容可以查看原文 https://arxiv.org/pdf/2107.03332.pdf
A Results on Higher Input Resolution
B Results on CrowdPose
C Results on MPII Human Pose Estimation
D Analysis on the Quantisation Error
- D.1 SimDR-based Representation
- D.2 Heatmap-based Representation

