Caffe数据集格式——以MNIST为例
1. MNIST下载
MNIST数据集可以在Caffe源码框架的 caffe/data/mnist/ 下使用 get_mnist.sh 脚本进行下载.

train-images-idx3-ubyte: training set images
train-labels-idx1-ubyte: training set labels
t10k-images-idx3-ubyte: test set images
t10k-labels-idx1-ubyte: test set labels
The training set contains 60000 examples, and the test set 10000 examples.
The first 5000 examples of the test set are taken from the original NIST training set.
The last 5000 are taken from the original NIST test set. The first 5000 are cleaner and
easier than the last 5000. get_mnist 脚本代码如下:
#!/usr/bin/env sh
# This scripts downloads the mnist data and unzips it.
DIR="$( cd "$(dirname "$0")" ; pwd -P )"
cd "$DIR"
echo "Downloading..."
for fname in train-images-idx3-ubyte train-labels-idx1-ubyte t10k-images-idx3-ubyte t10k-labels-idx1-ubyte
do
if [ ! -e $fname ]; then
wget --no-check-certificate http://yann.lecun.com/exdb/mnist/${fname}.gz
gunzip ${fname}.gz
fi
done
2. MNIST数据集格式
MNIST官网上是这么进行描述的: 采用大端存储
All the integers in the files are stored in the MSB first (high endian) format used by most non-Intel processors. Users of Intel processors and other low-endian machines must flip the bytes of the header.
train-labels-idx1-ubyte 文件描述如下:
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9. train-images-idx3-ubyte 文件描述如下:
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white),
255 means foreground (black). t10k-labels-idx1-ubyte 文件描述如下:
TEST SET LABEL FILE (t10k-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 10000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9. t10k-images-idx3-ubyte 文件描述如下:
TEST SET IMAGE FILE (t10k-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 10000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white),
255 means foreground (black). 对数据集进行解析,并显示手写体照片,代码如下:
import os
from matplotlib import pyplot as plt
import numpy as np
IMAGE_ROW = 28
IMAGE_COL = 28
IMAGE_SIZE = 28*28
def read_head(fileName):
print("读取文件头: ", os.path.basename(fileName))
dimension = []
print('fileName: ', fileName)
with open(fileName, 'rb') as pf:
# 获取magic number
data = pf.read(4) #读出第一个4字节
magic_num = int.from_bytes(data, byteorder='big')
print('magic_number: ', hex(magic_num))
dimension_cnt = magic_num & 0xff
print('dimension_cnt: %d' % dimension_cnt)
for i in range(dimension_cnt):
data = pf.read(4)
dms = int.from_bytes(data, byteorder='big')
print('dimension %d: %d'%(i, dms))
dimension.append(dms)
print(dimension)
return dimension
def get_head_length(dimension):
return 4 * len(dimension) + 4
def read_image(fileName, head_len, offset):
image = np.zeros((IMAGE_ROW, IMAGE_COL), dtype=np.uint8)
with open(fileName, 'rb') as pf:
pf.seek(head_len + IMAGE_SIZE*offset)
for row in range(IMAGE_ROW):
for col in range(IMAGE_COL):
data = pf.read(1)
pix = int.from_bytes(data, byteorder='big')
if pix > 10:
image[row][col] = 1
print(image)
return image
def read_label(fileName, head_len, offset):
label = None
with open(fileName, 'rb') as pf:
pf.seek(head_len + offset)
data = pf.read(1)
label = int.from_bytes(data, byteorder='big')
print('读到的标签值: ', label)
return label
def get_sample_count(dimension):
return dimension[0]
def read_image_vector(fileName, head_len, offset, amount):
image_mat = np.zeros((amount, IMAGE_SIZE), dtype=np.uint8)
with open(fileName, 'rb') as pf:
# magic_num的长度为4,dimension_cnt单个长度为4,前面的number个长度为28*28*offset
pf.seek(head_len+IMAGE_SIZE*offset)
for ind in range(amount):
image = np.zeros((1, IMAGE_SIZE), dtype=np.uint8)
for row in range(IMAGE_SIZE):
data = pf.read(1)
pix = int.from_bytes(data, byteorder='big')
if pix > 10:
image[0][row] = 1
image_mat[ind, :] = image
print('read_image_vector: 当前进度%.2f%%' %(ind*100.0 / amount), end='\r')
print()
return image_mat
def read_label_vector(fileName, head_len, offset, amount):
label_list = []
with open(fileName, 'rb') as pf:
pf.seek(head_len+offset)
for ind in range(amount):
data = pf.read(1)
label = int.from_bytes(data, byteorder='big')
label_list.append(label)
print('read_label_vector: 当前进度%0.2f%%'% (ind*100.0 / amount), end='\r')
print()
return label_list
def read_image_label_vector(image_file, label_file, offset, amount):
image_dim = read_head(image_file)
label_dim = read_head(label_file)
image_amount = get_sample_count(image_dim)
label_amount = get_sample_count(label_dim)
if image_amount != label_amount:
print('Error: 训练集image 和 label 数量不相等')
return None
if offset + amount > image_amount:
print('Error: 请求的数据超出样本数量')
return None
# 获取样本image和label的头文件长度
image_head_len = get_head_length(image_dim)
label_head_len = get_head_length(label_dim)
# 得到image和label的向量
image_mat = read_image_vector(image_file, image_head_len, offset, amount)
label_mat = read_label_vector(label_file, label_head_len, offset, amount)
return image_mat, label_mat
if __name__ == '__main__':
print('\n\n')
train_image_file = './data/train-images-idx3-ubyte'
train_label_file = './data/train-labels-idx1-ubyte'
offset = 40000
number = 10
image_mat, label_list = read_image_label_vector(train_image_file, train_label_file, \
offset, number)
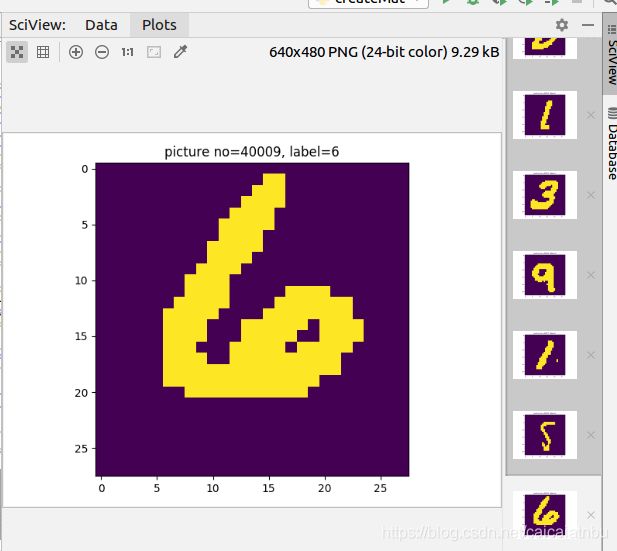
for index in range(number):
image = np.zeros((IMAGE_ROW, IMAGE_COL), dtype=np.uint8)
for row in range(IMAGE_ROW):
for col in range(IMAGE_COL):
image[row][col] = image_mat[index][row*IMAGE_ROW+col]
label = label_list[index]
print('LABEL: ', label)
print(image)
plt.imshow(image)
plt.title('picture no=%d, label=%d' %(offset+index, label))
plt.show()运行结果:
3. 转换格式
下载得到的MNIST数据集是二进制文件,需要转换为LEVELDB 或者 LMDB 才能被Caffe识别. 可以通过Caffe框架的 /caffe/example/mnsit/create_mnist.sh 将原始数据转换为lmdb/leveldb 格式.
执行完脚本代码,转换后的数据集保存在 /caffe/examples/mnist/mnist_train_lmdb 和 /caffe/examples/mnist/minst_test_lmdb 文件中

create_mnist.sh 脚本代码如下:
#!/usr/bin/env sh
# This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
set -e
# 生成路径
EXAMPLE=examples/mnist
# 原始数据路径
DATA=data/mnist
# 二进制文件路径
BUILD=build/examples/mnist
# 后端类型,lmdb/leveldb
BACKEND="lmdb"
echo "Creating ${BACKEND}..."
# 如果已经存在lmdb/leveldb,则先删除
rm -rf $EXAMPLE/mnist_train_${BACKEND}
rm -rf $EXAMPLE/mnist_test_${BACKEND}
# 创建训练集db
$BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
# 创建测试集db
$BUILD/convert_mnist_data.bin $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND}
echo "Done."从creat_mnist.sh 脚本中可以发现调用了 build/examples/mnist/convert_mnist_data.bin 这个可执行程序, 其对应的源码为
examples/mnist/conver_mnist_data.cpp, 这里我们分析这个源码.
// This script converts the MNIST dataset to a lmdb (default) or
// leveldb (--backend=leveldb) format used by caffe to load data.
// Usage:
// convert_mnist_data [FLAGS] input_image_file input_label_file
// output_db_file
// The MNIST dataset could be downloaded at
// http://yann.lecun.com/exdb/mnist/
#include
#include
#include
#if defined(USE_LEVELDB) && defined(USE_LMDB)
#include
#include
#include
#endif
#include
#include
#include // NOLINT(readability/streams)
#include
#include "boost/scoped_ptr.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/db.hpp"
#include "caffe/util/format.hpp"
#if defined(USE_LEVELDB) && defined(USE_LMDB)
using namespace caffe; // NOLINT(build/namespaces)
using boost::scoped_ptr;
using std::string;
// GFLAGS 工具定义命令行选项backend, 默认值为 lmdb, 即 --backend=lmdb
DEFINE_string(backend, "lmdb", "The backend for storing the result");
// 大小端转换. MNIST 原始文件中32位整型值为大端存储,
// C/C++变量为小端存储, 需要进行大小端转换.
uint32_t swap_endian(uint32_t val) {
val = ((val << 8) & 0xFF00FF00) | ((val >> 8) & 0xFF00FF);
return (val << 16) | (val >> 16);
}
void convert_dataset(const char* image_filename, const char* label_filename,
const char* db_path, const string& db_backend) {
// Open files
// 用C++输入文件流以二进制形式打开文件
std::ifstream image_file(image_filename, std::ios::in | std::ios::binary);
std::ifstream label_file(label_filename, std::ios::in | std::ios::binary);
CHECK(image_file) << "Unable to open file " << image_filename;
CHECK(label_file) << "Unable to open file " << label_filename;
// Read the magic and the meta data
// 读取魔数和基本信息
uint32_t magic;
uint32_t num_items;
uint32_t num_labels;
uint32_t rows;
uint32_t cols;
// 读取image文件 魔数 4字节
image_file.read(reinterpret_cast(&magic), 4);
// 大小端转换
magic = swap_endian(magic);
// 校验魔数是不是2051,不是则报错
CHECK_EQ(magic, 2051) << "Incorrect image file magic.";
// 读取label文件 魔数 4字节
label_file.read(reinterpret_cast(&magic), 4);
// 大小端转换
magic = swap_endian(magic);
// 校验魔数是不是2049,不是则报错
CHECK_EQ(magic, 2049) << "Incorrect label file magic.";
// 读取image文件的 文件包含的数据量 此处60000
image_file.read(reinterpret_cast(&num_items), 4);
num_items = swap_endian(num_items);
// 读取label文件的 文件包含的数据量 此处60000
label_file.read(reinterpret_cast(&num_labels), 4);
num_labels = swap_endian(num_labels);
// 校验图像数量与标签数量是否相等
CHECK_EQ(num_items, num_labels);
// 读取image文件的 图像的行数
image_file.read(reinterpret_cast(&rows), 4);
rows = swap_endian(rows);
// 读取image文件的 图像的列数
image_file.read(reinterpret_cast(&cols), 4);
cols = swap_endian(cols);
// 智能指针的创建方式类似泛型的格式,上面通过db.cpp内定义的命名的子命名空间中db的
// “成员函数”GetDB函数来初始化db对象
scoped_ptr db(db::GetDB(db_backend));
// argv[3]的文件夹下创建并打开lmdb的操作环境
db->Open(db_path, db::NEW);
// 创建lmdb文件的操作句柄
scoped_ptr txn(db->NewTransaction());
// Storing to db
// 读取数据保存到db
char label;
char* pixels = new char[rows * cols];
int count = 0;
string value;
// 把数据转换为Datum格式
Datum datum;
// MNIST是单通道图片,所以置为1
datum.set_channels(1);
// 图片高度
datum.set_height(rows);
// 图片宽度
datum.set_width(cols);
// 打印LOG信息
LOG(INFO) << "A total of " << num_items << " items.";
LOG(INFO) << "Rows: " << rows << " Cols: " << cols;
for (int item_id = 0; item_id < num_items; ++item_id) {
// 读取整张图片
image_file.read(pixels, rows * cols);
// 读取图片对应的标签
label_file.read(&label, 1);
// 将图片信息保存到Datum中
datum.set_data(pixels, rows*cols);
// 将图片的标签保存到Datum中
datum.set_label(label);
// 序列化键
string key_str = caffe::format_int(item_id, 8);
// datum数据,序列化到字符串中
datum.SerializeToString(&value);
// 把键值对放入到数据库
txn->Put(key_str, value);
if (++count % 1000 == 0) {
txn->Commit(); // 保存到lmdb类型的文件
}
}
// write the last batch
// 写入最后一个batch
if (count % 1000 != 0) {
txn->Commit();
}
LOG(INFO) << "Processed " << count << " files.";
// 释放指针
delete[] pixels;
db->Close();
}
int main(int argc, char** argv) {
#ifndef GFLAGS_GFLAGS_H_
namespace gflags = google;
#endif
// gflags库中为main函数设置usage信息
FLAGS_alsologtostderr = 1;
// 用于设置命令行帮助信息
gflags::SetUsageMessage("This script converts the MNIST dataset to\n"
"the lmdb/leveldb format used by Caffe to load data.\n"
"Usage:\n"
" convert_mnist_data [FLAGS] input_image_file input_label_file "
"output_db_file\n"
"The MNIST dataset could be downloaded at\n"
" http://yann.lecun.com/exdb/mnist/\n"
"You should gunzip them after downloading,"
"or directly use data/mnist/get_mnist.sh\n");
// 解析命令行参数
gflags::ParseCommandLineFlags(&argc, &argv, true);
// 获取--backend参数
const string& db_backend = FLAGS_backend;
// argc为统计main函数接受的参数个数,正常地调用argc=4,argv为对应的参数值,
// argv[1]=原始数据路径, argv[2]=标签数据路径, argv[3]=保存lmdb的路径
if (argc != 4) {
gflags::ShowUsageWithFlagsRestrict(argv[0],
"examples/mnist/convert_mnist_data");
} else {
google::InitGoogleLogging(argv[0]);
// 把原始数据装换成backend型数据,并保存在制定的路径中
convert_dataset(argv[1], argv[2], argv[3], db_backend);
}
return 0;
}
#else
int main(int argc, char** argv) {
LOG(FATAL) << "This example requires LevelDB and LMDB; " <<
"compile with USE_LEVELDB and USE_LMDB.";
}
#endif // USE_LEVELDB and USE_LMDB