【PyTorch】【segmentation_models_pytorch】【Unet】源码解析 - 【Encoder】
目的
- Ok,先来说说为什么有这篇文章。
- 作为一个才入门的小白,在使用unet训练model时遇到各种问题,看过论文,查过资料,在github上找过大佬复现的unet,最终再使用pytorch自己提供的unet模型时,效果稍稍好了些,但还是存在问题,于是下定决心查看segmentation_models_pytorch中Unet是怎么实现的。话不多说,现在开始。
首先看见的是如何调用
- 如下图,我是这么写的
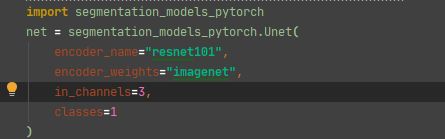
- 我使用的编辑器是pycharm,所以同时按下Ctrl + 鼠标左键,即可进入源码
于是,点击进入Unet
- 进来之后你可以看见如下内容
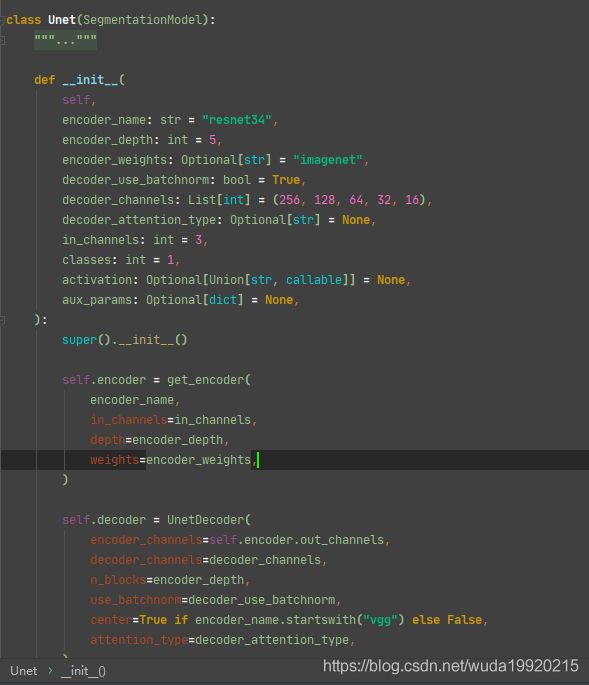
- 这里我们先看encoder,如图所示可以看见
self.encoder = get_encoder(...) - 其参数即为我开始初始化的设置
encoder_name = "resnet101"
in_channels = 3
depth = encoder_depth # 默认值5
weights = "imagenet"
下一步查看get_encoder怎么实现的
- 再次进入查看源码,如下图

- 在这里已经可以看见
Encoder = encoders[name]["encoder"]- 首先看
name, 根据上一步传入的参数可以知道name = encoder_name = "restnet101" - 那么
encoders是什么呢?可以猜测得到他是一个dict,根据encoder_name取值 - 写在这里: 我个人习惯是先不往下看,后面看到需要什么参数了,再回来找
- 首先看
让我们来看看Encoder到底是什么
- 首先,我们得找到
encoders 
- 这些参数是提前提供好的,在上方
import中导入 - 而我使用的是
resnet101, 于是大胆推测我需要的就是第一行的resnet_encoders - 这是我个人习惯,有点鲁莽,个人建议还是仔细查看认真核对,以防出错
- 接下来看一下
resnet_encoders到底是什么? 
- 可以看见他是一个
dict - 在里面找到我所需要的
resnet101 
- 可以根据之前
get_encoder里面的代码Encoder = encoders[name][encoder]得到这个Encoder = ResNetEncoder - 晒出
ResNetEncoder源码 
- 以程序的思维,先找到入口
forward然后逐行执行- 1.传入参数
x,这里其实就是输入的特征 - 2.然后实例化
stages = self.get_stages() 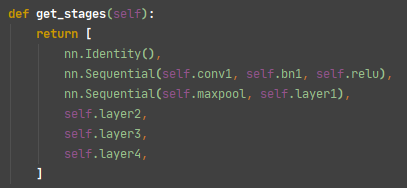
- 可以看见他是一系列的网络层
- 然后就是一个
for循环,循环次数_depth默认为5,也可自动传入,先做个记号A,待会会用到这里 - 在这里可以看见
stages的实际长度为6,如果你输入的depth > 5就会出错哦 - 然后查看
stages- 第一个:
nn.Identity()实际就是一个输入层 - 第二个:
nn.Sequential(self.conv1, self.bn1, self.relu),这一层需要执行三个操作,继续看着三个操作是什么 
- 第三个:
nn.Sequential(self.maxpool, self.layer1), 这里一看就是一个最大池化层,那self.layer1是什么呢?还有下面的self.layer2,self.layer3,self.layer4 - 继续看看
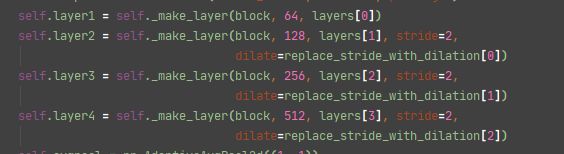
- 他们都是执行的一个方法
self._make_layer,只是传入的参数不同 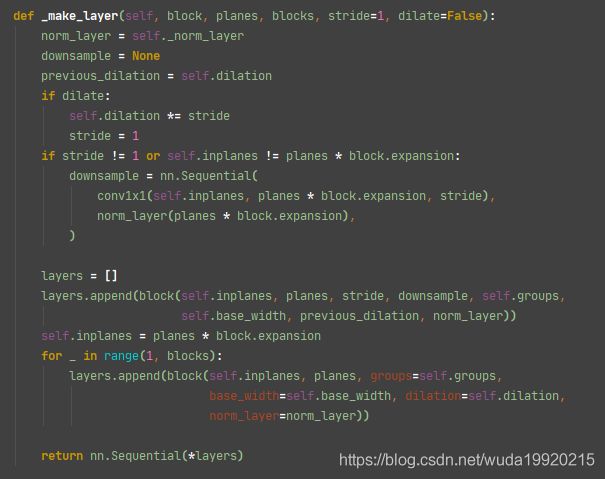
- 可以结合前面一步的
self.layer1...self.layer4看出来,其实主要就是block和blocks,根据形参和实参位置对应,得到blocks = layers[*], 也就是说主要的就是block和layers - 那么这两个参数是在哪里传入的呢?
- 仔细回想,我们之前的操作只执行到了
Encoder = encoders[name]["encoder"], 只是初始化了类,还并未实例化,更不用说调用了,那么,问题就容易解决了,去看看在哪里实例化的。直接回到初始位置get_encoder可以发现下图 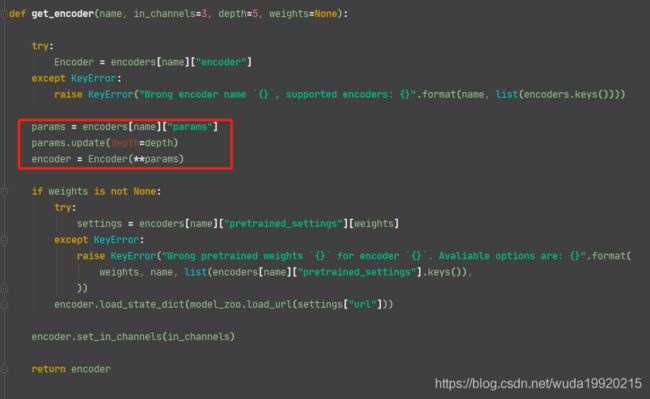
- 那么
params是什么?这里也可以看见传入的之前记号Adepth - 继续看

- 问题解决,
block = Bottleneck以及layers=[3, 4, 23, 3] - 先看
Bottleneck 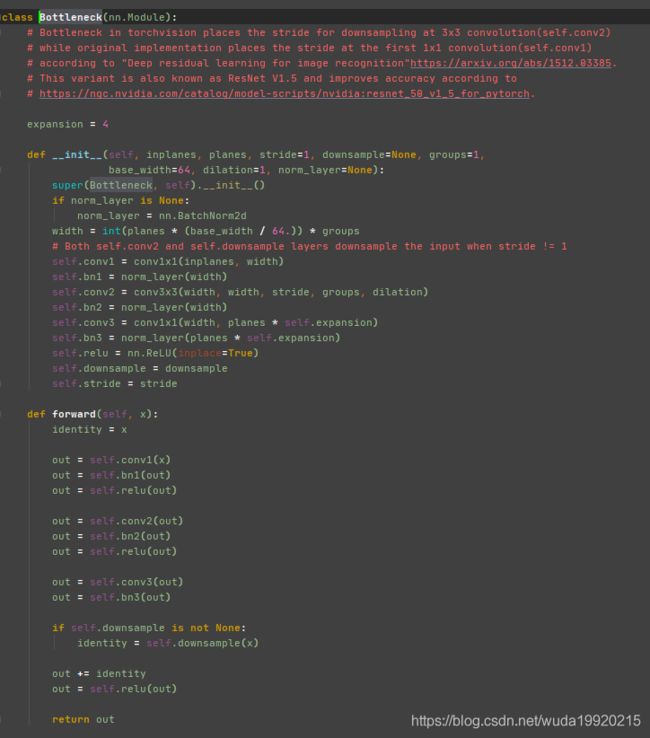
- 再结合之前
self._make_layer(...) 
- 可以看见
block主要是对传入的特征进行如下操作:省略参数conv1: conv1x1BatchNorm2dReLUconv2: conv3x3BatchNorm2dReLUconv3: conv1x1BatchNorm2d- 如果需要
downsample则执行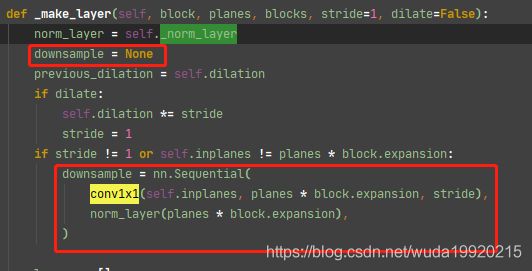
conv1x1+BatchNorm2d
- 这里的
conv1x1和conv3x3分别为:主要差别是kernel_size不同 
- 在经过
downsample之后再次进行ReLU
- 第一个:
- 1.传入参数
到这里就已经基本上可以清楚了解了 Unet.encoder是如何组成的,其实可以画个图更加直观,但是由于时间优先,这里暂时先不加,后续画完了我再添加上来,另外写这篇文章,其实主要目的是帮我自己梳理思路,边分析编写可以记得更真切。同时如果能帮助到跟我一样有迷惑的人,那就更好了。
——<未完待续>