【2021最新综述】Deep Neural Approaches to Relation Triplets Extraction:A Comprehensive Survey
【2021最新综述】Deep Neural Approaches to Relation Triplets Extraction:A Comprehensive Survey
- 1 Introduction
- 2 Task Description
- 3 Scope of this survey
- 4 Challenges of Dataset Annotation
- 5 Relation Extraction Datasets
- 6 Evaluation Metrics
- 7 Relation Extraction Models(前方高能)
-
- 7.1 Pipline Extraction Approaches
-
- 7.1.2 Feature-Based Models
- 7.1.2 CNN-based Neural Models
- 7.1.3 Attention-Based Neural Models
- 7.1.4 Dependency-Based Neural Models
- 7.1.5 Graph-Based Neural Models
- 7.1.6 Contextualized Embedding-Based Neural Models
- 7.2 Noise Mitigation for Distantly Supervised Data
- 7.3 Zero-Shot and Few-Shot Relation Extraction
- 7.4 Joint Extraction Approaches
- 8 Current State-of-the-art & Trends
- 9 Future Research Directions
- 10 Conclusion
- 参考文献
本文是2021年由Nayak等人所发表的关系抽取综述,主要集中在研究英文语料的关系抽取,为了方便日后的研究工作以及论文写作,将此阅读笔记发表至此,希望也能帮助广大想入坑关系抽取的广大读者。如果文中有表达不妥之处,欢迎留言指正。

为了能更好地帮助未来地研究,本文主要介绍最近在关系抽取上已发表的工作。本文将更多注重于在公开数据集上使用深度学习方法达到前沿效果。本综述中将包括了句子级和文本级的关系抽取、pipline-base的关系抽取和联合抽取、标注语料集到远程监督,以及最近的研究方向,如zero-shot和few-shot关系抽取,远程监督数据集的噪声降低。基于模型结构而言,本文包含了CNN、RNN、注意力机制和图神经网络。
1 Introduction
一个关系三元组由两个实体及其之间的关系组成。关系三元组也可以从公开的知识库中抽取,如Freebase[1]、DBpedia[2]、Wikidata[3]等。关系三元组对许多自然语言处理任务有非凡的意义,如机器阅读理解、文本摘要等等。
以上方法的缺点:
知识库构建的繁杂,一般都是通过众包形式
难以被扩展
知识库的链接并不完备
关系抽取大概可以被分为两大类:Open Information Extraction(Open IE)、Supervised Relation Extraction。在Open IE中,rule-base的抽取方法有:KnowItAll[4]、TEXTRUNNER[5]、REVERB[6]、SRLIE[7]和OLLIE[8],他们从名词中抽取实体、从动词中抽取关系。但这种方法的缺点是:从文本中抽取动词作为关系,就会产生大量不规则的三元组。同样地,同一种关系在不同句子有不同表达,如“live in relation”可以表达为“stays”、“settles”、lodges“、”resident of“等等,但Open IE把他们作为不同的关系类别。
Open IE中的问题在supervised RE中则被得到了解决,因为Supervised RE中我们会设定一个固定的关系分类,但同时也需要大量与之平行的语料集进行训练(就属于这些关系分类的语料集)。另一方面,远程监督可以用于自动化生成大规模训练语料,但这些生成的数据集包含着大量的噪声。
2 Task Description
给定一个句子和关系集合R作为输入,任务的目的是从句子和R中提取有关系三元组。
**Pipline-based的关系抽取方法大概被分为两个子任务:(1)NER;(2)关系分类。**在第一个子任务中,所有在句子中的候选实体被识别出来;第二个子任务中,每一个关系对的关系会被明确——也有可能是“None”不存在。
联合抽取的关系抽取方法中,与之向相反,联合地找到实体和关系。联合抽取只会抽取合法的关系三元组,而不需要“None”关系类别。关系三元组可能会共享一个或者两个实体,然后这种实体重叠(overlapping),会让该任务更加困难,我么们将句子分为三类:
No Entity Overlap (NEO):该类别的同一句子中,包含了一个或者多个三元组,但是他们之并无共享实体;
Entity Pair Overlap(EPO):该类别的同一句子中,有超过一个的三元组,并且至少有两个三元组,他们所有的实体都相同,或者顺序相反。
Single Entity Overlap(SEO):该类别的同一句子中,有超过一个的三元组,并且至少有两个三元组,他们其中一个实体相同。
另外,一个句子可以同时属于EPO和SEO类别,而联合抽取的目标则是抽取所有句子中表示的关系三元组。

3 Scope of this survey
许多研究中做主要集中在特定领域的关系抽取,比如文学、医药、法律、金融等。但本文主要考虑英文的关系抽取。
4 Challenges of Dataset Annotation
已有的知识库,比如Freebase、Wikidata和DBpedia,都是手动进行构建的,消耗了大量的人力和物力,然而这些知识库依然有大量缺失的链接。在另一个方面,我们可以从自由文本中找到大量的关系三元组。如果我们能从文本中自动地抽取出关系三元组,我们就能通过爬取文本建立知识库,或者添加新的三元组到已有的知识库,而不需要人工。但是为了达到这个目标我们需要大量的标注文本,但创造这样的语料集有需要大量的人力。一个可行的方法是:抽取出实体,然后判断是关系集中哪个类型,如果没有,则为None。识别实体比较容易,但从关系集中判定关系比较难的,因为当关系的类型多起来之后就变得很具有挑战性。在大量关系集中标注None类别是比较困难的,标注员必须保证两个实体之间的关系不在关系集中。
为了克服数据集标注问题,远程监督[9-11]被提出来自动化获取文本三元组映射。在远程监督中,在已知数据库中的三元组被映射到自由文本语料,比如维基百科的文章或者纽约时报的文章。远程监督的主要思想:如果一个句子包含数据库中三元组的两个实体,那么该句子就可以被考虑成知识库中的关系三元组的数据源。相反地,如果知识库中包含两个实体,但是两个实体之间并没有任何关系,就会被认为是None类型。当远程监督只考虑了一小部分积极样本,这些None类型的样本非常有用。任何关系集之外的关系都会被判定为None类型。这种方法能给我能大量的三元组到文本的映射,这些映射能帮助我们更好地建立监督模型。监督学习的方法能轻易的扩展到单文本或者多文本的关系抽取任务。
远程监督会带来大量的噪声。噪声分类如下:
正例噪声数据(noisy positive samples):有时候一个句子可能包含的正例的三元组的两个实体(知识库中是有关系的),但在句子中可能并没有表达他们之间的关系。
负例噪声数据(noisy negative samples):该噪声样本集合来自None类别的样本:如果一个句子包含了KB的两个实体,然后在KB中他们之间并没有关系,那么这个句子的实体对会被认为是“None”类别关系,但是KB并不完善,许多实体关系在其中丢失。所以本来句子是表达了实体之间的关系,然后被KB认为他们没有关系。
例子如下:
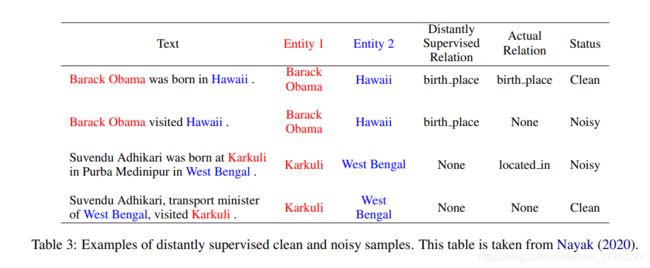
Barack Obama和Hawaii之间是birth place关系;Karkuli和West Bengal之间在KB中没有任何关系,所以认为他们两个之间没有关系。
第一句话正确表达了Barack Obama和Hawaii之间的birth place关系,根据KB分类正确,因此是一个干净的正例数据(clean positive sample);第二句并没有表达birth place关系,但Barack Obama和Hawaii依然根据KB被分类为birth place关系,因此是个正例噪声数据(noisy positive sample);第三句中表达出Karkuli和West Bengal是located in关系,但是由于KB里面不存在这两个实体的关系,因此被误分为None关系类型,因此是一个消极噪声数据(noisy negative sample);最后一句就是干净的消极数据(clean negative sample.)
5 Relation Extraction Datasets
已有许多数据集可被用于关系抽取任务。
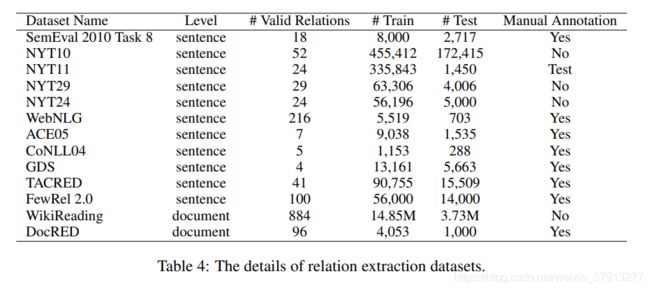
FewRel2.0是用来评估few-shot关系抽取的数据集,WebNLG、NYT24和NYT29近些年用于联合抽取。WikiReading和DocRED是两个文档级的关系抽取数据集,由维基百科的文章和维基百科自己的数据组成。WikiReading是一个slot-filling数据集。这些数据集都没有None类别的实例。Nayak[12]提出一个扩展关系抽取任务到多文档级别,他创造了一个2-hop关系抽取数据集,该数据集是从multi-hop的QA数据集WikiHop创造出来的。
6 Evaluation Metrics
在pipine方法中,已经假定两个实体已经被识别出来,模型只需要判定实体之间的关系或者判定出他们并没有关系。然后由两种方法:(1)句子级别;(2)bag-level。句子级别别的关系抽取,每个句子所包含的实体对都可以被视为是一个测试实例;Bag-level的关系抽取中,一系列包含相同实体对的句子,才能作为测试实例。但不管是哪种方法,都是去除掉None类别的标签数据后,通过Precision、Recall、F1值进行模型的评估。
置信度(confidence threshold):被用于决定一个测试实例的的关系属于关系集R中还是None。如果被分类为None,那么其分类就是None;如果不是,但其softmax分数低于置信度,也依然会被分为None。置信度可以和最高的F1值取得相同效果,因为大多数的测试数据都是远程监督,并且包含很多噪声数据,自动化评估的F1值可能不适合。PR曲线也是用来自动化评估的比较流行的方法。
对于联合抽取来说,模型的评估是基于正确抽取的三元组数量。被抽取的三元组会被看作是一个集合,如果是重复的会被移除。只有对应的实体和关系都正确,关系三元组才会被认为是正确的。Precision、Recall、F1值也都是以这个为基础。然后有两种方法进行匹配实体:第一种是部分匹配,只会匹配实体名字的最后几个字符,另外一种则是完全匹配。
7 Relation Extraction Models(前方高能)
大概分为:(1)pipline的关系抽取;(2)联合抽取
7.1 Pipline Extraction Approaches
在刚开始的关系抽取研究之中,Pipline方法非常的流行,被分为两个步骤:(1)NER;;(2)关系分类。第一个步骤的实体识别被映射到KB的实体之中。有一些前沿NER模型被提出[13-16]。基于上下文的词嵌入模型,如ELMo[17]、BERT[18]、RoBERTa[19]和SpanBERT[20]也被提出用于NER任务,然后就开始进行关系分类了。
7.1.2 Feature-Based Models
Mintz[21]等人提出基于特征的关系分类模型。他们使用文本的特征,如实体之间的单词序列、实体的标注(哪个是实体1、哪个是实体2)、k个实体1左边的字符和k个实体2右边的字符;另外,还有语法特征,如两个实体之间的依存路径、实体的类别。
Riedel[22]等人提出multi-instance learning去解决远程监督中,句子的噪声问题。他们使用factor graph明确模型对于实体之间是否关联、以及他们之间的关系是否被句子提及的判定。另外,他们使用Constraint-driven(约束驱动)的半监督学习来训练模型,而不适用任何能表达句子关系的任何知识。
Hoffmann[23]和Surdeanu[24]等人提出了multi-instance multi-labels(MIML)来解决overlap relation问题。他么使用概率图模型,并将包含两个实体的一系列句子作为输入,找到他们之间最有可能的关系。类似地,Ren[25]等使用了基于特征的模型来联合预测两个实体的关系和他们的细粒度类型。
7.1.2 CNN-based Neural Models
词的分布式表示作为词嵌入,开始转变自然语言处理的方法,如IE。Word2Vec[26]和GloVe[27]是两个大型的公开词向量表示,并被用于许多的自然语言处理任务。大量基于网络模型的信息抽取任务开始使用分布式的词表示作为他们的核心部分。高维度的分布式词表示可以编码重要的语义信息,这能更好的帮助我们识别实体之间的关系。
Zeng[28]等人使用CNN进行关系抽取。他们使用Turian[29]等人提出的预训练模型来表示我文本的字符,使用两个距离向量分别表示每个词到实体之间的距离,然后使用CNN和max-pooling提取句子的语义向量,最后通过一个sotmax层进行分类。
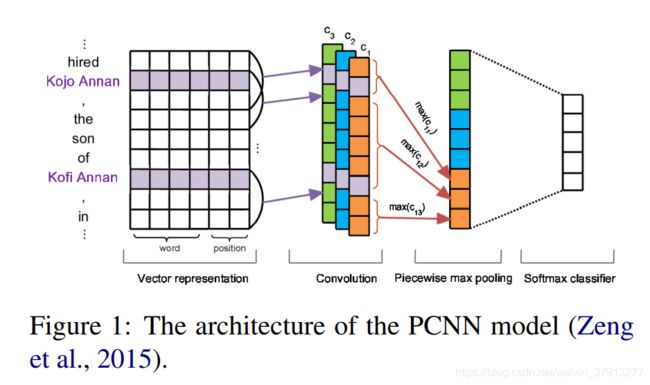
Zeng[30]等提出一个分段的CNN(Piecewise Convolutional Neural Network,PCNN)来改进关系抽取模型。PCNN中,max-pooling不会将所有的句子特征进行池化,而是分为了三部分:从开始到参数第一次出现,从参数第一次出现到参数第二次出现和第二次出现参数到最后。Max-pooling对于这三个部分和对每个卷积核分别作用并获得三个特征值。
7.1.3 Attention-Based Neural Models
最近,注意力网络被证实对于不同的NLP任务都非常有帮助。Shen and Huang等[31]、Wang等[32]、Zhang等[33]和Jat等[34]将词级的注意力模型用于句子级的关系抽取任务中。
Shen and Huang提出一个结合CNN和注意力机制的网络。首先,卷积和池化操作用于提取全部的句子特征;然后注意机制分别基于两个实体,用于句子的文本上。实体最后的一个字符的词表示,和每个词的次表示进行拼接。这个拼接表示通过前馈层到softmax或获得一个注意力分数,该分数表示该实体对于每个单词的注意力分数。词表示基于注意i分数来获取带注意力的特征向量。文本特征向量和两个实体的注意力特征向量通过前馈神经网络层,然后到softmax进行一个分类。
Wang等使用multi-level注意力CNN进行关系抽取,并在SemEval2010 Task8语料集上获得比较高的F1值。

Zhang等在LSTM基础上,提出一个位置意识的注意力机制。比起上述CNN部分所用的位置特征,Zhang的则是在将其用于注意力机制上。
Jet等使用Bi-GRU[35]捕捉长距离的依赖。将字符向量通过Bi-GRU层,然后Bi-GRU的隐藏层向量通过一个bi-linear操作,这个操作是两个前馈神经层并使用softmax进行计算对于每一个词的注意分数。Bi-GRU的隐藏层向量和对应的注意分数进行相乘得到隐藏层向量。
Nayak and Ng等[36]人使用基于距离依赖的多注意模型进行关系抽取任务。
Bowen等[37]人使用的就是segment-level的注意力机制而不是使用传统的字符集的注意力机制。
Zhang等[38]提出使用基于注意力机制的胶囊网络进行关系抽取。
Lin等[39]将注意力模型用于multi-instance关系抽取。他们在一系列包含两个实体的独立的句子上使用注意力机制,来抽取关系。首先,基于CNN的模型将句子编码到一个bag。然后一个bi-linear attention层用于确定bag中每个句子的重要性。注意力机制能帮助解决远程监督中的噪声问题,该方法会给予重要句子较高的注意力分数,给噪声句子较低的分数。Bag中句子的向量,基于他们的注意力分数,使用一种加权平均的方式进行结合。然后将得到的向量通过前馈神经网络,然后通过softmax进行分类。这种bag-level只能用于积极关系,而不能用于像None这种消极关系,因为None关系类别的bag表示经常是不同的,他们的很难去计算一个合适的权重值。
Ye and Ling等[40]使用intra-bag和inter-bag网络到multi-instance关系抽取任务中。他们使用了和Lin相似的注意力机制。在这个基础上,他们使用inter-bag注意机制之去解决噪声问题。他们将不同类的bag分到多个组,同一个组中每个bag的注意力分数,时候基于bag直接的相似度获得的。Inter-bag的注意力机制只用于训练,模拟在测试期间并不知道他们之间的关系。类似的,Yuan等[41]提出cross-relation和cross-bag注意机机制,用于multi-instance的关系抽取任务。Li等[42]提出entity-aware embedings和在Self-attention模型来提升PCNN。
7.1.4 Dependency-Based Neural Models
先前的一些研究工作将句子的依存信息融合到神经网络模型进行关系抽取。
Xu等[43],融合最短依存路径(shortest dependency path,SDP)和LSTM[44]进行关系抽取。在SDP上的每个字符有四个嵌入表示:预训练词向量、词性标注、SDP中字符和它的孩子的依存关系。他们把SDP分为两个子路径:(1)左边的SDP——entity1到公共的祖先节点;(2)右边的SDP——entity2到公共的祖先节点。这个公共祖先节点就是两个实体之间最低的公共节点。然后这两个部分分别地通过LSTM层,然后经过池化层从左SDP到右SDP来抽取特征向量。这两个向量拼接后经过分类层获得向量。
Liu等[45]利用两个实体之间的SDP和依附于路径的子树进行关系抽取。每个字符的在SDP中,通过预训练语言模型和子树进行表示。每个字符的子树表示,是通过依存句法树的子树获得的。每个子树的字符节点的信息来源于他的孩子,包括他们之间的依存关系。子树的表示,是以当前字符作为根节点,然后从他的叶子节点自低向上的过程;然后在字符序列向量和SDP中的依存关系使用CNN和池化操作。最后max-pooling的输出在经过分类器得到最终分类。
Miwa and Bansal[46]则使用树形LSTM网络的SDP。他们使用自底向上的树形LSTM和自上而下的树形LSTM。
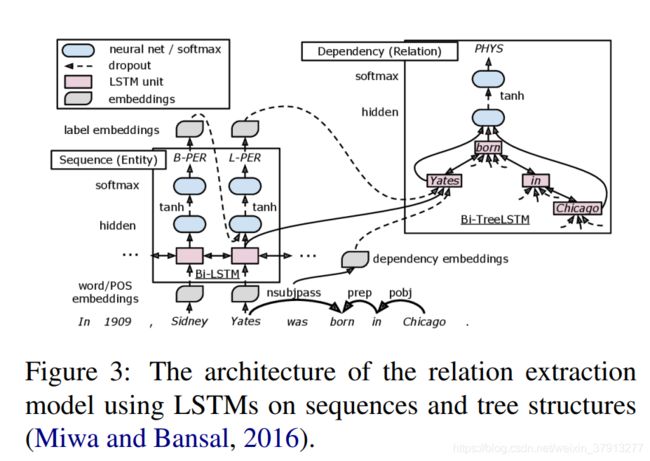
在自底向上的树形LSTM中,而每个节点的的信息都来源于它所有的孩子节点。自底向上的树形LSTM的root节点的隐藏层表示,用来作为最终的输出;自上而下的树形LSTM中,每个节点的信息都是从他的父母节点来的,两个实体的头字符的隐含表示作为该模型最终的输出。然后这两个输出通过拼接,再经过分类器进行分类。
这些成果表示使用SDP tree能够很有效的忽略不重要的词语。Beysehet等[47]提出了一个ON-LSTM[48]关系抽取模型来保护该模型中的语义一致性。
7.1.5 Graph-Based Neural Models
图模型再许多非线性结构的NLP任务中非常受欢迎。
Quirk and Poon[49]提出使用图模型进行cross-setence的关系抽取。每个单词作为图的节点,邻接词、依存关系、话语关系作为边,来构建图。提取两个实体之间的所有路径,每条路径都由特征进行表示,如词法、词根、词性标注等。他们使用所有的路径特征来定位两实体之间的关系。
Peng等[50]和Song等[51]使用相似的N-ary cross-sentence关系抽取方法。比起确切的路径,他们再图上使用LSTM。图LSTM是线性LSTM和树形LSTM更一般化的模型。如果图LSTM上只包含词的邻接边,那么此时的图LSTM就会变成线性LSTM。如果图所包含的边来自依存句法树,则是一个树形的LSTM。一般的图结构都会存在环。所以Peng将图分离成两个有向图。每个节点对其各个邻居节点都有单独的遗忘门,它从邻居节点接收信息,并通过LSTM公式进行更新隐藏状态。如果我们只考虑词的邻接边,这个图LSTM变成了一个双向的线性LSTM。Song就没有将图分为两个方向,而是直接地使用他的图结构进行更新节点。对于第t个时间步,每个节点接收到的信息从他的上一个时间步的邻居节点,然后使用LSTM公式进行更新,然后上述过程重复k的次数倍。其中k是一个超参数。
Kipf和Welling[52]、Velickovi等[53]人提出一个图卷积神经网络(GCN),该网络使用普通的线性变换来更新节点的状态,不像图LSTM。Kipf和Welling给每条边赋予相同的权重,而Velickovi等则使用注意力机制分配不同权重给每一条边。
Vashishth等[54]、Zhang等[55]和Guo等[56]再句子级的关系抽取任务上使用GCN。他们把句子中每个字符作为节点,使用依存句法树构建图结构。Vashishth使用GCN到一个多实例的情况之下。他们在依存句法树之上,使用Bi-GRU层和一个GCN层进行编码。Bag中的句子表示进行汇总并通过分类器进行分类。
随着Miwa and Bansal[57]、Zhang等[58]只使用SDP树建立图的邻接矩阵,沿着SDP树,他们包括了距离SDP为K的边,K是一个超参数。
Guo等则在Zhang提出的GCN基础上提出软剪枝的策略。他们考虑依存句法树的所有信息来构建邻接矩阵,但他们呢使用一个多头注意力机制的软剪枝,他可以识别图中重要的和不重要的边。
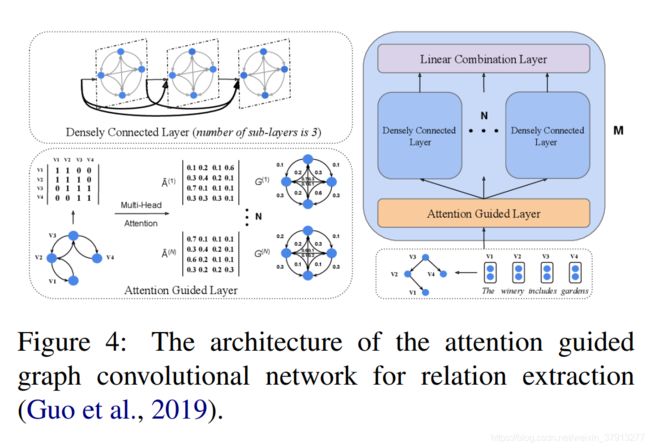
Mandya等[59]在多个子图上使用GCN进行关系抽取任务。让门篡改见了基于子图的最短依存路径和实体相关的字符。
Sahu等[60]、Christopoulou等[61]、Nan等[62]则使用GCN进行文档级的关系抽取任务。Sahu考虑文档的每一个字符作为图中的节点。它使用语法反恶习树的边、邻接词边、指代关系边来制造节点之间的链接。Christopoulou讲实体的提及、实体、句子作为图中的节点。他们使用基于规则的启发式方法来建立节点之间的边。在他们的图中,每个节点和每条边都能被表示成向量。GCN用于更新节点和边的向量。最后,两个关注的实体之间的边向量通过分类器进行分类。Nan等则考虑实体的提及、实体、最短依存路径的字符,将它们作为图的节点。他们使用归纳模块学习潜在的文档级图结构。一种多条的可解析性模块经常被用于推导潜在归纳结构,而节点的更新信息则是基于information aggregation scheme。
Zeng等[63]提出的用于文档及关系抽取的聚焦和推断网络。他们构建了一个entity-mention级别的图去捕捉它们在文档中的相互作用,并且entity-mention级别的图能够更好地聚焦到entity-mention级别的信息上。
Wang等[64]在文档中使用完整地图,并使用多头注意力机制网络去聚焦到相关地信息。
Zhou等[65]提出多轴注意力机制引导的GCN,同时Li等[66]提出基于GCN的双重注意力网络用于文档及关系抽取。
7.1.6 Contextualized Embedding-Based Neural Models
语境词嵌入模型,比如ELMo、BERT、SpanBERT,都是能够进行关系抽取任务的。语境词嵌入能够加入关系抽取的嵌入层来优化关系抽取的效果。SpandBERT已经被证实可以很有效地提升关系抽取地效果,并在TACRED数据集得到验证。
Joshi等[67],使用实体1地类型和SUBJ替换了实体一,如PER-SUBJ;用实体2地类型和OBJ替换了实体2 ,如LOC-OBJ,;以此来训练模型。最后使用线性分类器在CLS字符向量上进行分类。
Baldini Soares[68]也使用了BERT模型,他们也在句子使用特别的标记,标记了实体1和实体2,然后使用实体首字符地向量进行关系分类。
Wang等[69]提出了两步地微调BERT模型,用于文档级关系抽取。首先,使用BERT识别出是否具有关系;然后使用BERT进行关系分类。
Nan等[70]在他们的模型上使用BERT,表现了它在DocRED数据集上与GloVe词向量的优劣。
Han and Wang[71]使用BERT进行识别实体对中所有可能的关系。他们在每次遍历中,使用实体类型和特别的标记,标记文档中所有entity mention。文档经过预训练的BERT模型,一个entity mention向量可以通过平均BERT的输出向量获得。一个entity mention向量可以通过平均这个实体的entity mention向量获得。然后使用一个双线性分类器进行关系分类。
Tang等[72]提出分层推断网络进行文档级关系抽取,他们也展示了使用BERT来提升模型效果。
7.2 Noise Mitigation for Distantly Supervised Data
噪声数据的存在影响了模型的效果。许多学者使用不同的技术来缓解噪声数据的影响,来增强模型的健壮性。Riedel[22]、Hoffmann[11]、Lin[39]、Yaghoobzadeh[73]、Vashishth[54]、
Wu[74]还有Ye and Ling[40]使用多实例学习机型关系抽取。对于每个实体对,他们使用所有包含这两个实体的句子来抽取关系。目的是为了通过多实例的情景来缓解噪声。他们使用了不同的句子选择机制,给与不同句子根据特定关系、关键词的相关重要性。
Ren等[25]和Yaghoobzadeh使用多任务学习方法来缓解噪声。他们使用细粒度的实体类型作为额外的任务。
Wu等使用对立训练方法达到相同目标,他们把噪声都加到词向量上,来增强远程监督模型的健壮性。Qin等[75]使用了一个对抗生成网络(Generative adversarial Network,GAN)解决关系抽取中噪声样本的问题。他们对每个正类的关系,使用分离的二元分类器作为生成器来识别关系类别中的True Posities(TP)类别,并过滤掉噪声样本。
Qin[76]等使用强化学习来识别积极关系类别中的噪声样本。
Jia[77]等则使用基于规则的注意力机制唉解决远程监督中的噪声问题。他们使用注意力机制来识别句子中的关系模板、如果句子中补办还这样的patterns就认为他们是噪声样本。
He等[78]使用强化学习来识别正类的噪声数据,然后使用噪声数据作为无标签数据输入模型。
Shang等[79]使用clustering方法识别噪声,他们在噪声数据中指出正确的类型,并以此作为附加的训练数据。
7.3 Zero-Shot and Few-Shot Relation Extraction
远程监督数据集包含了KB的关系子集。已有的KB包含成千上万的关系,由于无法匹配KB和文本中的实体,导致远程监督不能找到足够多的训练样本。这回导致远程监督模型不能填充这些未被覆盖的丢失的链接。Zero-shot或者Few-shot关系抽取能解决这一问题。这类模型可以用一个关系集数据进行训练,但可用于推断其他关系集。
Levy[80]和Li[81]等人将RE任务便便成一个QA任务,并使用MRC方法进行zero-shot的关系抽取。这个方法中,实体1和关系被用于作为问题,如果实体2存在,则作为答案。Levy使用BiDAF模型[82]作为在WikiReading数据集中进行关系抽取的输出层的新增的NIL节点。他们使用一个关系集合进行训练,再用另一个集合进行测试。
Li等人使用模板、实体1和关系来制造问题(questions),他们修正MRC模型作为一个序列标注任务,以至于让他们能够找出一个问题的多个答案。虽然他们的方法没有用于zero-shot的经验,但这个方法能用于Zero-shot的关系抽取。
FewRel2.0是用于few-shot关系抽取的数据集,再few-shot关系抽取中,训练和测试的关系类型是不同的,和Zero-shot一样。但是在测试部分,只有少量样本提供给模型进行更好的预测。
7.4 Joint Extraction Approaches
联合抽取就是不需要提前提供实体,并且让实体抽取和分类更一体化。最近的一些工作,如Katiyar and Cardie[3]、Miwa and Bansal[57]、Bekoulis[84]、Nguyen and Verspoor等[85]他们想通过共享参数,进行一起优化,达到联合抽取。但是他们依旧是先进行NER再分类,更类似Pipline方法的扩展。
Zheng等[86]首次提出真正的联合抽取模型。他使用序列标注模式进行联合抽取.他们从实体标签和关系标签做笛卡尔积,定义出一个标签机和。这些新的标签能狗编码实体信息和关系信息。但是当实体被三元组共享,这个方法就并不奏效,因为一个字符只有一个标签。
Zeng[87]则提出一个带copy机制的encodr-decoder模型进行联合抽取。他们的模型使用copy network对被复制的字符进行关系分类。但是他们的模型并不能捕捉所有的三元组实体。他们表现最好的模型使用了一个分开的编码器进行抽取三元组。训练期间,他们需要确定最大的decoder数量;推理期间,他们的模型只能抽取固定数量的三元组。因此他们对每个三元组使用分开的解码器,他们的模型缺失了撒按元组之间的相互影响。
Takanobu等[88]提出了一个层次强化学习模型用于联合抽取。高级的强化学习被用于确定基于relation-specific tokens的关系。确定关系之后,低级的强化学习模型通过使用序列标注方法来抽取两个实体和关系之间的联系。以上了流程将重复多次来抽取关系三元组。
Fu等[89]人使用GCN进行联合抽取。
Trisedya等[90]在encoder-decoder模型中使用N-gram注意力机制,通过监督语料完善KB。
Chen等[91]使用encoder-decoder框架,该框架还时使用了基于CNN的多标签分类器先找到所有的关系,再使用多头注意力机制抽取每个实体对应的关系。
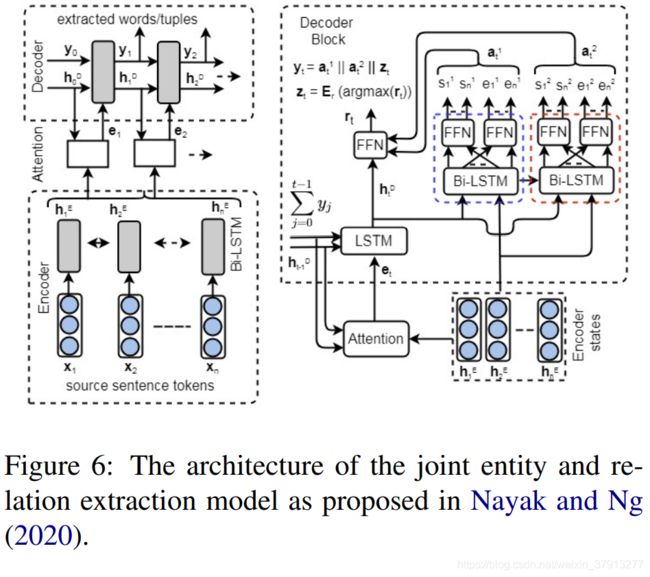
Nayak and Ng[92]也使用encoder-decoder框架。他们提出一个词级解码框架和一个pointer network-based解码框架。
CopyMTL模型[93]被提出用于解决CopyR[87]模型的问题。CopyR模型只能提取实体最后的token,而CopyMTL使用序列标注方法能完整地提取实体名字。
Bowen等人[86]则将联合抽取分解成两个子任务(1)头实体抽取;(2)尾实体和关系抽取。他们使用序列标注放你发解决这两个子任务。类似的,Wei等[94]人也使用了类似地方法,就加入了BERT来改善他们的性能。
Yuan等[95]人在序列标注的联合抽取模型上,使用了relation-specific的注意力机制。
Wang等[96]使用single-stage的联合抽取模型,该模型使用实体对链接。他们使用笛卡尔积对齐句子的token,目的是为了能让前实体和后实体的边界能够对齐。他们使用一个分类器对每个类别的token-pair分别进行标注,然后将其作为实体头、实体尾、主体头、主体尾。该防范能有有效地区别多个三元组享有共同的实体的实体重叠问题。
Sui等[97]提出在Encoder-decoder网络上,提出将关系三元组看成是集合而不是序列的二分匹配损失。
Ye等[98]使用基于transformer的生成式模型。他们在trastive settings下,使用消极样本训练transformer。
Wang and Lu[99]提出table-sqeuence encoder模型。序列编码器捕捉实体相关的信息;table-encoder不做特定关系的信息。
Sun等[100]提出递归多任务学习架构,捕捉实体识别任务和关系分类任务之间的相互关系。
Ji等[101]提出span-base的多头注意力网络,每个text span是一个候选实体,每个text span pairs是一个候选的三元组。
8 Current State-of-the-art & Trends
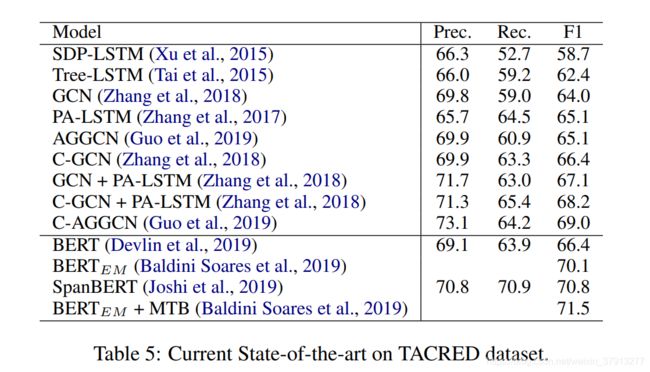
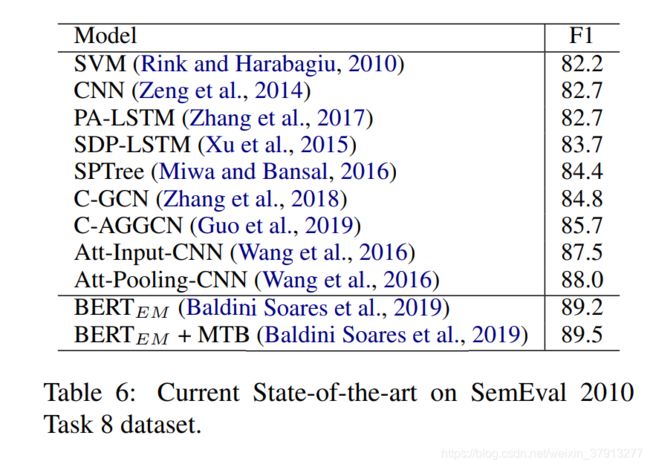
NYT在pipline-base方法中使用较多,TACRED和SemEval 2010 Task 8语料也被大量用于评估模型;联合抽取领域,NYT24语料、NYT29和WebNLG语料集使用较为广泛。然后列举了目前前沿的方法在这些数据集上的效果:
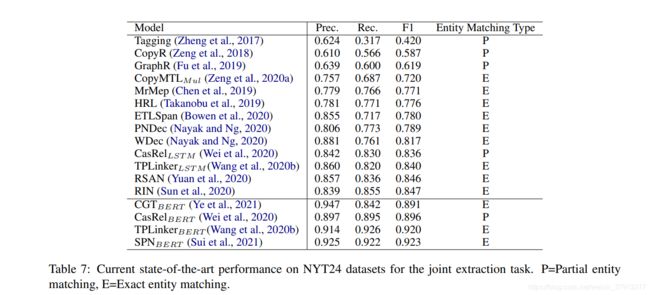

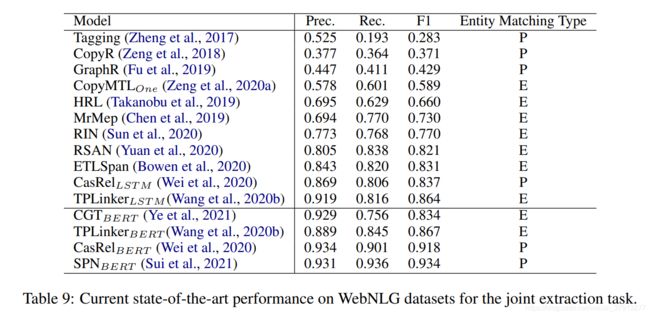
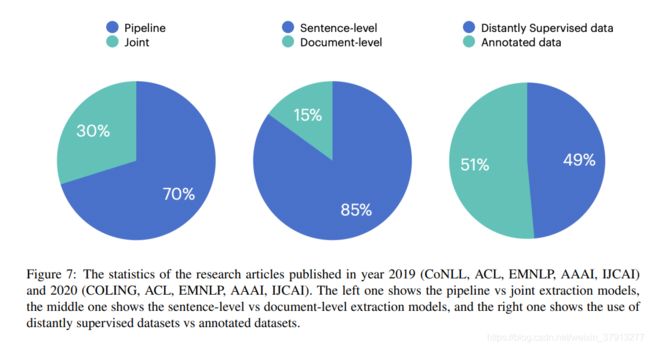
然后还有统计了2019 (CoNLL, ACL, EMNLP, AAAI, IJCAI) 和 2020 (COLING, ACL, EMNLP, AAAI, IJCAI)的论文发表情况,发现大部分研究都集中在pipline-base的关系抽取。
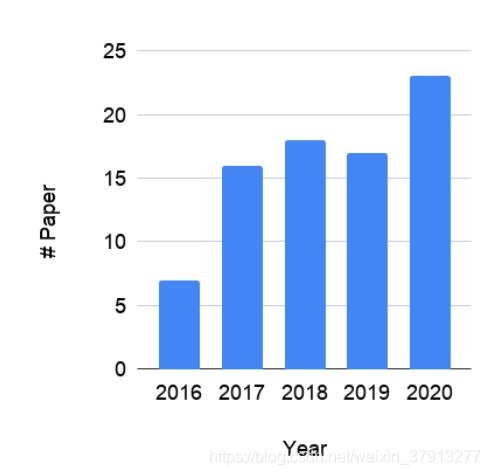
最后是关系抽取的研究成果在近五年的发表趋势
9 Future Research Directions
Pipline方法:
存在非常多的None类别的实例,但这些None类别有些知识超出了目前的关系集;
None类别实例的错误检测,提高模型精度;
联合抽取方法:
NYT24数据集是在NYT10和NYT11的基础上,去掉None类别,也就是去掉不存在实体关系的句子样本形成。在未来的联合抽取方法,应该能够确定该本文中实体之间不存在任何关系。
另外,目前的关系抽取类别较少,而知识库的构建需要大量的关系类别。未来应该更关注文档级别的关系抽取,甚至是跨文档的关系抽取。但扩展到文档级别必定又会引入新的噪声。除此之外,我们也需要继续研究few-shot的关系抽取来解决训练样本不足的问题。
10 Conclusion
废话,略
参考文献
[1]Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: A collaboratively created graph database for structuring human knowledge. In SIGMOD.
[2]Christian Bizer, Jens Lehmann, Georgi Kobilarov, Soren Auer, Christian Becker, Richard Cyganiak, ¨ and Sebastian Hellmann. 2009. DBpedia-A crystallization point for the web of data. Web Semantics: Science, Services and Agents on the World Wide Web.
[3]Denny Vrandeciˇ c and Markus Kr ´ otzsch. 2014. Wiki- ¨ data: A free collaborative knowledge base. Communications of the ACM.
[4]Oren Etzioni, Michael Cafarella, Doug Downey, Stanley Kok, Ana-Maria Popescu, Tal Shaked, Stephen Soderland, Daniel S Weld, and Alexander Yates. 2004. Web-scale information extraction in KnowItAll:(preliminary results). In WWW
[5]Alexander Yates, Michael Cafarella, Michele Banko, Oren Etzioni, Matthew Broadhead, and Stephen Soderland. 2007. TEXTRUNNER: Open information extraction on the web. In NAACL-HLT.
[6]Oren Etzioni, Anthony Fader, Janara Christensen, Stephen Soderland, and Mausam. 2011. Open information extraction: The second generation. In IJCAI.
[7]Janara Christensen, Mausam, Stephen Soderland, and Oren Etzioni. 2011. An analysis of open information extraction based on semantic role labeling. In K-CAP
[8]Mausam, Michael Schmitz, Stephen Soderland, Robert Bart, and Oren Etzioni. 2012. Open language learning for information extraction. In EMNLP-CoNLL.
[9]Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In ACL and IJCNLP.
[10]Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In ECML and KDD.
[11]Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer, and Daniel S Weld. 2011. Knowledgebased weak supervision for information extraction of overlapping relations. In ACL.
[12]Tapas Nayak. 2020. Deep neural networks for relation extraction. NUS Scholar Bank
[13]Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF models for sequence tagging. ArXiv.
[14]Xuezhe Ma and Eduard H. Hovy. 2016. End-to-end sequence labeling via bi-directional LSTM-CNNsCRF. In ACL.
[15]Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. In NAACL-HLT.
[16]Jason Chiu and Eric Nichols. 2016. Named entity recognition with bidirectional LSTM-CNNs. In TACL.
[17]Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In NAACL-HLT.
[18]Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT.
[19]Y. Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, M. Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. ArXiv
[20]Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, and Omer Levy. 2019. SpanBERT: Improving pre-training by representing and predicting spans. TACL
[21]Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. 2009. Distant supervision for relation extraction without labeled data. In ACL and IJCNL
[22]Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In ECML and KDD.
[23]Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer, and Daniel S Weld. 2011. Knowledgebased weak supervision for information extraction of overlapping relations. In ACL.
[24]Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati, and Christopher D. Manning. 2012. Multiinstance multi-label learning for relation extraction. In EMNLP and CoNLL.
[25]Xiang Ren, Zeqiu Wu, Wenqi He, Meng Qu, Clare R Voss, Heng Ji, Tarek F Abdelzaher, and Jiawei Han. 2017. CoType: Joint extraction of typed entities and relations with knowledge bases. In WWW.
[26]Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In NIPS.
[27]Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global vectors for word representation. In EMNLP.
[28]Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In COLING.
[29]Joseph Turian, Lev Ratinov, and Yoshua Bengio. 2010. Word representations: A simple and general method for semi-supervised learning. In ACL.
[30]Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In EMNLP.
[31]Yatian Shen and Xuanjing Huang. 2016. Attentionbased convolutional neural network for semantic relation extraction. In COLING.
[32]Linlin Wang, Zhu Cao, Gerard de Melo, and Zhiyuan Liu. 2016. Relation classification via multi-level attention CNNs. In ACL
[33]Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D. Manning. 2017. Positionaware attention and supervised data improve slot filling. In EMNLP.
[34]Sharmistha Jat, Siddhesh Khandelwal, and Partha Talukdar. 2017. Improving distantly supervised relation extraction using word and entity based attention. In AKBC.
[35]Kyunghyun Cho, Bart Van Merrienboer, Dzmitry Bah- ¨ danau, and Yoshua Bengio. 2014. On the properties of neural machine translation: Encoder-decoder approaches. In Workshop on Syntax, Semantics and Structure in Statistical Translation.
[36]Tapas Nayak and Hwee Tou Ng. 2019. Effective attention modeling for neural relation extraction. In CoNLL.
[37]Yu Bowen, Zhenyu Zhang, Tingwen Liu, Bin Wang, Sujian Li, and Q. Li. 2019. Beyond word attention: Using segment attention in neural relation extraction. In IJCAI.
[38]Xinsong Zhang, P. Li, W. Jia, and Zhao Hai. 2019. Multi-labeled relation extraction with attentive capsule network. In AAAI.
[39]Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances. In ACL.
[40]Zhi-Xiu Ye and Zhen-Hua Ling. 2019. Distant supervision relation extraction with intra-bag and inter-bag attentions. In NAACL-HLT.
[41]Y. Yuan, Liyuan Liu, Siliang Tang, Zhongfei Zhang, Y. Zhuang, S. Pu, Fei Wu, and Xiang Ren. 2019. Cross-relation cross-bag attention for distantlysupervised relation extraction. In AAAI
[42]Yang Li, Guodong Long, Tao Shen, Tianyi Zhou, L. Yao, Huan Huo, and Jing Jiang. 2020b. Selfattention enhanced selective gate with entity-aware embedding for distantly supervised relation extraction. In AAAI.
[43]Yuning Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, and Zhi Jin. 2015. Classifying relations via long short term memory networks along shortest dependency paths. In EMNLP.
[44]Sepp Hochreiter and Jurgen Schmidhuber. 1997. Long ¨ short-term memory. Neural Computation.
[45]Yang Liu, Furu Wei, Sujian Li, Heng Ji, Ming Zhou, and Houfeng Wang. 2015. A dependency-based neural network for relation classification. In ACL and IJCNLP.
[46]Makoto Miwa and Mohit Bansal. 2016. End-to-end relation extraction using LSTMs on sequences and tree structures. In ACL.
[47]Amir Pouran Ben Veyseh, Franck Dernoncourt, D. Dou, and T. Nguyen. 2020. Exploiting the syntax-model consistency for neural relation extraction. In ACL.
[48]Yikang Shen, Shawn Tan, Alessandro Sordoni, and Aaron C. Courville. 2019. Ordered neurons: Integrating tree structures into recurrent neural networks. In ICLR.
[49]Chris Quirk and Hoifung Poon. 2017. Distant supervision for relation extraction beyond the sentence boundary. In EACL.
[50]Nanyun Peng, Hoifung Poon, Chris Quirk, Kristina Toutanova, and Wen-tau Yih. 2017. Cross-sentence n-ary relation extraction with graph LSTMs. TACL.
[51]Linfeng Song, Yue Zhang, Zhiguo Wang, and Daniel Gildea. 2018. N-ary relation extraction using graph state LSTM. In EMNLP.
[52]Thomas Kipf and Max Welling. 2017. Semisupervised classification with graph convolutional networks. In ICLR.
[53]Petar Velickovi , Guillem Cucurull, Arantxa Casanova, ´ Adriana Romero, Pietro Lio, and Yoshua Bengio. ` 2018. Graph attention networks. In ICLR.
[54]Shikhar Vashishth, Rishabh Joshi, Sai Suman Prayaga, Chiranjib Bhattacharyya, and Partha Talukdar. 2018. RESIDE: Improving distantly-supervised neural relation extraction using side information. In EMNLP.
[55]Xinsong Zhang, P. Li, W. Jia, and Zhao Hai. 2019. Multi-labeled relation extraction with attentive capsule network. In AAAI.
[56]Zhijiang Guo, Yan Zhang, and Wei Lu. 2019. Attention guided graph convolutional networks for relation extraction. In ACL.
[57]Makoto Miwa and Mohit Bansal. 2016. End-to-end relation extraction using LSTMs on sequences and tree structures. In ACL.
[58]Yuhao Zhang, Peng Qi, and Christopher D. Manning. 2018. Graph convolution over pruned dependency trees improves relation extraction. In EMNLP.
[59]Angrosh Mandya, Danushka Bollegala, and F. Coenen. 2020. Graph convolution over multiple dependency sub-graphs for relation extraction. In COLING
[60]Sunil Kumar Sahu, Fenia Christopoulou, Makoto Miwa, and Sophia Ananiadou. 2019. Inter-sentence relation extraction with document-level graph convolutional neural network. In ACL.
[61]Fenia Christopoulou, Makoto Miwa, and Sophia Ananiadou. 2019. Connecting the dots: Document-level neural relation extraction with edge-oriented graphs. In EMNLP and IJCNLP.
[62]Guoshun Nan, Zhijiang Guo, Ivan Sekulic, and Wei Lu. 2020. Reasoning with latent structure refinement for document-level relation extraction. In ACL.
[63]Shuang Zeng, Runxin Xu, Baobao Chang, and Lei Li. 2020b. Double graph based reasoning for document-level relation extraction. In ACL.
[64]D. Wang, Wei Hu, E. Cao, and Weijian Sun. 2020a. Global-to-local neural networks for document-level relation extraction. In EMNLP.
[65]Huiwei Zhou, Yibin Xu, W. Yao, Zhe Liu, Chengkun Lang, and H. Jiang. 2020. Global context-enhanced graph convolutional networks for document-level relation extraction. In COLING.
[66]Bo Li, Wei Ye, Zhonghao Sheng, Rui Xie, Xiangyu Xi, and Shikun Zhang. 2020a. Graph enhanced dual attention network for document-level relation extraction. In COLING
[67]Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, and Omer Levy. 2019. SpanBERT: Improving pre-training by representing and predicting spans. TACL
[68]Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. Matching the blanks: Distributional similarity for relation learning. In ACL.
[69]Hong Wang, Christfried Focke, Rob Sylvester, Nilesh Mishra, and William W. J. Wang. 2019. Fine-tune BERT for DocRED with two-step process. ArXiv.
[70]Guoshun Nan, Zhijiang Guo, Ivan Sekulic, and Wei Lu. 2020. Reasoning with latent structure refinement for document-level relation extraction. In ACL.
[71]Xiaoyu Han and Lei Wang. 2020. A novel documentlevel relation extraction method based on BERT and entity information. IEEE Access.
[72]Hengzhu Tang, Yanan Cao, Zhenyu Zhang, Jiangxia Cao, Fang Fang, Shigang Wang, and Pengfei Yin. 2020. HIN: Hierarchical inference network for document-level relation extraction. Advances in Knowledge Discovery and Data Mining.
[73]Yadollah Yaghoobzadeh, Heike Adel, and Hinrich Schutze. 2017. Noise mitigation for neural entity ¨ typing and relation extraction. In EACL.
[74]Shanchan Wu, Kai Fan, and Qiong Zhang. 2019. Improving distantly supervised relation extraction with neural noise converter and conditional optimal selector. In AAAI
[75]Pengda Qin, Weiran Xu, and William Yang Wang. 2018a. DSGAN: Generative adversarial training for distant supervision relation extraction. In ACL.
[76]Pengda Qin, Weiran Xu, and William Yang Wang. 2018b. Robust distant supervision relation extraction via deep reinforcement learning. In ACL.
[77]Wei Jia, Dai Dai, Xinyan Xiao, and Hua Wu. 2019. ARNOR: Attention regularization based noise reduction for distant supervision relation classification. In ACL.
[78]Zhengqiu He, Wenliang Chen, Yuyi Wang, Wei Zhang, Guanchun Wang, and Min Zhang. 2020. Improving neural relation extraction with positive and unlabeled learning. In AAAI.
[79]Yuming Shang, He-Yan Huang, Xian-Ling Mao, Xin Sun, and Wei Wei. 2020. Are noisy sentences useless for distant supervised relation extraction? In AAAI.
[80]Omer Levy, Minjoon Seo, Eunsol Choi, and Luke S. Zettlemoyer. 2017. Zero-shot relation extraction via reading comprehension. In CoNLL.
[81]Xiaoya Li, Fan Yin, Zijun Sun, Xiayu Li, Arianna Yuan, Duo Chai, Mingxin Zhou, and Jiwei Li. 2019. Entity-relation extraction as multi-turn question answering. In ACL.
[82]injoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. 2017. Bidirectional attention flow for machine comprehension. In ICLR.
[83]Arzoo Katiyar and Claire Cardie. 2016. Investigating LSTMs for joint extraction of opinion entities and relations. In ACL.
[84]Giannis Bekoulis, Johannes Deleu, Thomas Demeester, and Chris Develder. 2018. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Systems with Applications.
[85]Dat Quoc Nguyen and Karin Verspoor. 2019. End-toend neural relation extraction using deep biaffine attention. In ECIR
[86]Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. 2017. Joint extraction of entities and relations based on a novel tagging scheme. In ACL.
[87]Xiangrong Zeng, Daojian Zeng, Shizhu He, Kang Liu, and Jun Zhao. 2018. Extracting relational facts by an end-to-end neural model with copy mechanism. In ACL.
[88]Ryuichi Takanobu, Tianyang Zhang, Jiexi Liu, and Minlie Huang. 2019. A hierarchical framework for relation extraction with reinforcement learning. In AAAI.
[90]Bayu Distiawan Trisedya, Gerhard Weikum, Jianzhong Qi, and Rui Zhang. 2019. Neural relation extraction for knowledge base enrichment. In ACL.
[91]Jiayu Chen, Caixia Yuan, Xiao-Jie Wang, and Ziwei Bai. 2019. MrMep: Joint extraction of multiple relations and multiple entity pairs based on triplet attention. In CoNLL.
[92]Tapas Nayak and Hwee Tou Ng. 2020. Effective modeling of encoder-decoder architecture for joint entity and relation extraction. In AAAI.
[93]Daojian Zeng, Haoran Zhang, and Qianying Liu. 2020a. CopyMTL: Copy mechanism for joint extraction of entities and relations with multi-task learning. In AAAI.
[94]Zhepei Wei, Jianlin Su, Yue Wang, Yuan Tian, and Yi Chang. 2020. A novel cascade binary tagging framework for relational triple extraction. In ACL.
[95]Yue Yuan, Xiaofei Zhou, Shirui Pan, Qiannan Zhu, Zeliang Song, and Li Guo. 2020. A relation-specific attention network for joint entity and relation extraction. In IJCAI.
[96]Yucheng Wang, Bowen Yu, Y. Zhang, Tingwen Liu, Hongsong Zhu, and L. Sun. 2020b. Tplinker: Single-stage joint extraction of entities and relations through token pair linking. In COLING
[97]Dianbo Sui, Yubo Chen, Kang Liu, Jun Zhao, Xiangrong Zeng, and Shengping Liu. 2021. Joint entity and relation extraction with set prediction networks. In AAAI.
[98]Hongbin Ye, Ningyu Zhang, Shumin Deng, M. Chen, Chuanqi Tan, Fei Huang, and Huajun Chen. 2021. Contrastive triple extraction with generative transformer. AAAI.
[99]Jue Wang and Wei Lu. 2020. Two are better than one: Joint entity and relation extraction with tablesequence encoders. In EMNLP.
[100]Kai Sun, Richong Zhang, Samuel Mensah, Yong yi Mao, and Xudong Liu. 2020. Recurrent interaction network for jointly extracting entities and classifying relations. In EMNLP.
[101]Bin Ji, Jie Yu, Shasha Li, Jun Ma, Q. Wu, Yusong Tan, and Huijun Liu. 2020. Span-based joint entity and relation extraction with attention-based spanspecific and contextual semantic representations. In COLING.