论文:Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection通过划块的方式进行小目标检测
Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection通过划块的方式进行小目标检测
- 1、看一下过程和最终效果
-
- 1.1、看一下slicing的pitch效果
- 1.2、slicing结合Yolov5最终效果
- 2、论文详解Slicing Aided Hyper Inference (SAHI)
-
- 2.1、Slicing Aided Fine-tuning (SF)
- 2.2、Slicing aided hyper inference
- 3、本论文中的创新( 切片技术) 详解
- 3.1、slicing bbox怎么得到的
-
- 3.2、slice_coco类的完整执行过程
-
- 3.2.1、得到sciling_img_bbox和sciling_annotation
- 2.2.1.1、process_coco_annotations类详解
-
-
- 2.2.1.1.1、annotation_inside_slice与get_sliced_coco_annotation类
-
论文地址:Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
开源代码:https://github.com/obss/sahi
1、看一下过程和最终效果
以下代码在源码的demo文件中的jupyter notebook文件。但是代码有些部分要做一点点添加或修改,可以看我下面的代码 修改。
1.1、看一下slicing的pitch效果
import os
os.getcwd() # os.getcwd() 方法用于返回当前工作目录。
from sahi.slicing import slice_coco
from sahi.utils.file import load_json
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
# Slicing COCO Dataset into Grids
# Visualize original image and annotations:
os.environ['NUMEXPR_MAX_THREADS'] = '16'
coco_dict = load_json("demo_data/terrain2_coco.json")
f, axarr = plt.subplots(1, 1, figsize=(12, 12))
# read image
img_ind = 0
img = Image.open("demo_data/" + coco_dict["images"][img_ind]["file_name"]).convert('RGBA')
# iterate over all annotations
for ann_ind in range(len(coco_dict["annotations"])):
# convert coco bbox to pil bbox
xywh = coco_dict["annotations"][ann_ind]["bbox"]
xyxy = [xywh[0], xywh[1], xywh[0]+xywh[2], xywh[1]+xywh[3]]
# visualize bbox over image
ImageDraw.Draw(img, 'RGBA').rectangle(xyxy, width=5)
axarr.imshow(img)
OUT输出如下:

# 类似于下面我详细讲解的get_slice_bboxes类
coco_dict, coco_path = slice_coco(
coco_annotation_file_path="demo_data/terrain2_coco.json",
image_dir="demo_data/",
output_coco_annotation_file_name="sliced_coco.json",
ignore_negative_samples=False,
output_dir="demo_data/sliced/",
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
min_area_ratio=0.1,
verbose=True
)
# Visualize sliced images:
f, axarr = plt.subplots(4, 5, figsize=(13,13))
img_ind = 0
for ind1 in range(4):
for ind2 in range(5):
img = Image.open("demo_data/sliced/" + coco_dict["images"][img_ind]["file_name"])
axarr[ind1, ind2].imshow(img)
img_ind += 1
OUT:
f, axarr = plt.subplots(4, 5, figsize=(13,13))
img_ind = 0
for row_ind in range(4):
for column_ind in range(5):
# read image
img = Image.open("demo_data/sliced/" + coco_dict["images"][img_ind]["file_name"]).convert('RGBA')
# iterate over all annotations
for ann_ind in range(len(coco_dict["annotations"])):
# find annotations that belong the selected image
if coco_dict["annotations"][ann_ind]["image_id"] == coco_dict["images"][img_ind]["id"]:
# convert coco bbox to pil bbox
xywh = coco_dict["annotations"][ann_ind]["bbox"]
xyxy = [xywh[0], xywh[1], xywh[0]+xywh[2], xywh[1]+xywh[3]]
# visualize bbox over image
ImageDraw.Draw(img, 'RGBA').rectangle(xyxy, width=5)
axarr[row_ind, column_ind].imshow(img)
img_ind += 1
OUT:

1.2、slicing结合Yolov5最终效果
# Install latest version of SAHI and YOLOv5:
!pip install -U torch sahi yolov5 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
import os
os.environ['NUMEXPR_MAX_THREADS'] = '16' # 必须要加,不然报错,源码中并没有这行代码
os.getcwd()
# Download a yolov5 model and two test images:
# download YOLOV5S6 model to 'models/yolov5s6.pt'
yolov5_model_path = 'models/yolov5s6.pt'
download_yolov5s6_model(destination_path=yolov5_model_path)
# download test images into demo_data folder
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg', 'demo_data/small-vehicles1.jpeg')
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png', 'demo_data/terrain2.png')
# Standard Inference with a YOLOv5 Model
# Instantiate a detection model by defining model weight path and other parameters:
detection_model = Yolov5DetectionModel(
model_path=yolov5_model_path,
confidence_threshold=0.3,
device="cpu", # or 'cuda:0'
)
# Perform prediction by feeding the get_prediction function with an image path and a DetectionModel instance:
result = get_prediction("demo_data/small-vehicles1.jpeg", detection_model)
# Or perform prediction by feeding the get_prediction function with a numpy image and a DetectionModel instance:
result = get_prediction(read_image("demo_data/small-vehicles1.jpeg"), detection_model)
# Visualize predicted bounding boxes and masks over the original image:
result.export_visuals(export_dir="demo_data/")
Image("demo_data/prediction_visual.png")
用Yolov5模型检测出的结果如下:
# Sliced Inference with a YOLOv5 Model
# To perform sliced prediction we need to specify slice parameters. In this example we will perform prediction over slices of 256x256 with an overlap ratio of 0.2:
result = get_sliced_prediction(
"demo_data/small-vehicles1.jpeg",
detection_model,
slice_height = 256,
slice_width = 256,
overlap_height_ratio = 0.2,
overlap_width_ratio = 0.2
)
# Visualize predicted bounding boxes and masks over the original image:
result.export_visuals(export_dir="demo_data/")
Image("demo_data/prediction_visual.png")
OUT:Sliced Inference with a YOLOv5 Model如下图所示:
由上面两张检测结果图显示:一目了然,加入Slicing方法的Yolov5模型在检测小目标的性能上大大提高。
2、论文详解Slicing Aided Hyper Inference (SAHI)
提出了一个名为切片辅助超推理(SAHI)的开源框架,该框架为小对象检测提供了一个通用的切片辅助推理和微调管道。该技术已与Detectron2、MMDetection和YOLOv5模型集成。

Slicing Aided Hyper Inference (SAHI)和滑动窗口的思想类似,作者将图像分割成多个重叠的切片slices。这样就使得输入网络的图像的小目标占比较高。![]()
2.1、Slicing Aided Fine-tuning (SF)



2.2、Slicing aided hyper inference


3、本论文中的创新( 切片技术) 详解
3.1、slicing bbox怎么得到的
def get_slice_bboxes(
image_height: int,
image_width: int,
slice_height: int = 512,
slice_width: int = 512,
overlap_height_ratio: int = 0.2,
overlap_width_ratio: int = 0.2,
) -> List[List[int]]:
"""Slices `image_pil` in crops.
Corner values of each slice will be generated using the `slice_height`,每个切片的角值将使用“切片高度”。。。生成`
`slice_width`, `overlap_height_ratio` and `overlap_width_ratio` arguments.
Args:
image_height (int): Height of the original image.
image_width (int): Width of the original image.
slice_height (int): Height of each slice. Default 512.
slice_width (int): Width of each slice. Default 512.
overlap_height_ratio(float): Fractional overlap in height of each
slice (e.g. an overlap of 0.2 for a slice of size 100 yields an
overlap of 20 pixels). Default 0.2.(每一层的高度部分重叠切片(例如,尺寸为100的切片重叠0.2会产生重叠20像素)。默认值为0.2。
overlap_width_ratio(float): Fractional overlap in width of each
slice (e.g. an overlap of 0.2 for a slice of size 100 yields an
overlap of 20 pixels). Default 0.2.
Returns:
List[List[int]]: List of 4 corner coordinates for each N slices.(每N个切片的4个角坐标列表).
[
[slice_0_left, slice_0_top, slice_0_right, slice_0_bottom],
...
[slice_N_left, slice_N_top, slice_N_right, slice_N_bottom]
]
"""
slice_bboxes = []
y_max = y_min = 0
y_overlap = int(overlap_height_ratio * slice_height)
x_overlap = int(overlap_width_ratio * slice_width)
while y_max < image_height:
x_min = x_max = 0
y_max = y_min + slice_height
while x_max < image_width:
x_max = x_min + slice_width
if y_max > image_height or x_max > image_width:
xmax = min(image_width, x_max)
ymax = min(image_height, y_max)
xmin = max(0, xmax - slice_width)
ymin = max(0, ymax - slice_height)
slice_bboxes.append([xmin, ymin, xmax, ymax])
else:
slice_bboxes.append([x_min, y_min, x_max, y_max])
x_min = x_max - x_overlap # 使前后两张切片的
y_min = y_max - y_overlap
return slice_bboxes
执行的过程中的参数详情如下:
 最后由一张原始图片 682 × 1024 682\times1024 682×1024图片经过get_slice_bboxes得到的20个slice_bboxes如下:
最后由一张原始图片 682 × 1024 682\times1024 682×1024图片经过get_slice_bboxes得到的20个slice_bboxes如下:
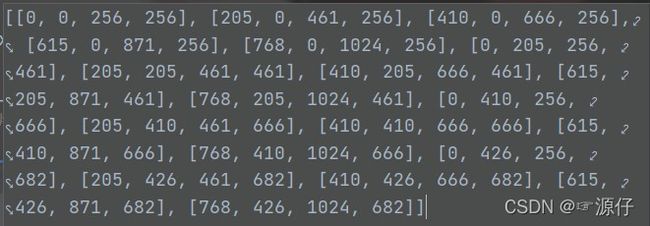
我把上述get_slice_bboxes过程,用图详细的把过程画了出来。如下图所示:
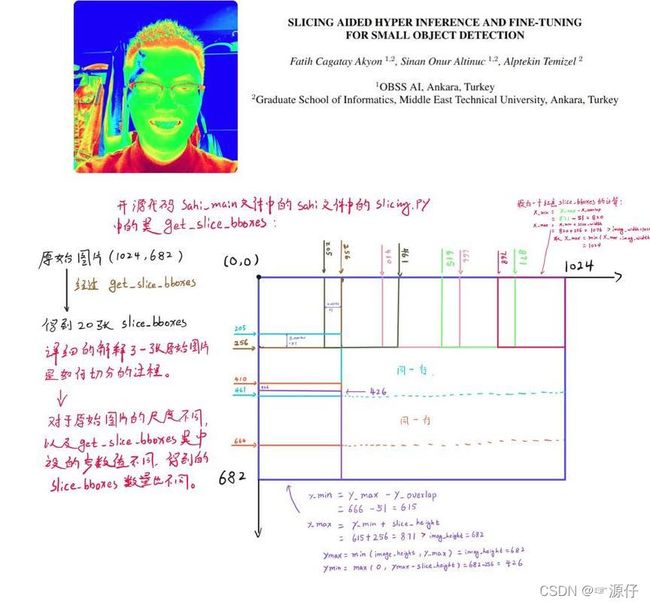
3.2、slice_coco类的完整执行过程
通过slice_coco得到coco_dict, coco_path,具体代码流程由三部分组成
我们先看一下生成的coco_dict, coco_path分别是什么?
1、先初始化slice_coco类
coco_dict, coco_path = slice_coco(
coco_annotation_file_path="demo_data/terrain2_coco.json",
image_dir="demo_data/",
output_coco_annotation_file_name="sliced_coco.json",
ignore_negative_samples=False,
output_dir="demo_data/sliced/",
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
min_area_ratio=0.1,
verbose=True
)
2、slice_coco具体类的过程代码如下:
def slice_coco(
coco_annotation_file_path: str,
image_dir: str,
output_coco_annotation_file_name: str,
output_dir: Optional[str] = None,
ignore_negative_samples: bool = False,
slice_height: int = 512,
slice_width: int = 512,
overlap_height_ratio: float = 0.2,
overlap_width_ratio: float = 0.2,
min_area_ratio: float = 0.1,
out_ext: Optional[str] = None,
verbose: bool = False,
) -> List[Union[Dict, str]]:
# read coco file
coco_dict: Dict = load_json(coco_annotation_file_path)
# create image_id_to_annotation_list mapping
coco = Coco.from_coco_dict_or_path(coco_dict)
# init sliced coco_utils.CocoImage list
sliced_coco_images: List = []
# iterate over images and slice
for coco_image in tqdm(coco.images):
# get image path
image_path: str = os.path.join(image_dir, coco_image.file_name)
# get annotation json list corresponding to selected coco image获取与所选coco图像对应的注释json列表
# slice image
try:
slice_image_result = slice_image(
image=image_path,
coco_annotation_list=coco_image.annotations,
output_file_name=Path(coco_image.file_name).stem,
output_dir=output_dir,
slice_height=slice_height,
slice_width=slice_width,
overlap_height_ratio=overlap_height_ratio,
overlap_width_ratio=overlap_width_ratio,
min_area_ratio=min_area_ratio,
out_ext=out_ext,
verbose=verbose,
)
# append slice outputs
sliced_coco_images.extend(slice_image_result.coco_images)
except TopologicalError:
logger.warning(f"Invalid annotation found, skipping this image: {image_path}")
# create and save coco dict
coco_dict = create_coco_dict(
sliced_coco_images,
coco_dict["categories"],
ignore_negative_samples=ignore_negative_samples,
)
save_path = ""
if output_coco_annotation_file_name and output_dir:
save_path = Path(output_dir) / (output_coco_annotation_file_name + "_coco.json")
save_json(coco_dict, save_path)
return coco_dict, save_path
3、上述代码中的包含的slice_image类代码具体如下:
def slice_image(
image: Union[str, Image.Image],
coco_annotation_list: Optional[CocoAnnotation] = None,
output_file_name: Optional[str] = None,
output_dir: Optional[str] = None,
slice_height: int = 512,
slice_width: int = 512,
overlap_height_ratio: float = 0.2,
overlap_width_ratio: float = 0.2,
min_area_ratio: float = 0.1,
out_ext: Optional[str] = None,
verbose: bool = False,
) -> SliceImageResult:
# define verboseprint
verboselog = logger.info if verbose else lambda *a, **k: None
def _export_single_slice(image: np.ndarray, output_dir: str, slice_file_name: str):
image_pil = read_image_as_pil(image)
slice_file_path = str(Path(output_dir) / slice_file_name)
# export sliced image
image_pil.save(slice_file_path)
verboselog("sliced image path: " + slice_file_path)
# create outdir if not present
if output_dir is not None:
Path(output_dir).mkdir(parents=True, exist_ok=True)
# read image
image_pil = read_image_as_pil(image)
verboselog("image.shape: " + str(image_pil.size))
image_width, image_height = image_pil.size
if not (image_width != 0 and image_height != 0):
raise RuntimeError(f"invalid image size: {image_pil.size} for 'slice_image'.")
slice_bboxes = get_slice_bboxes(
image_height=image_height,
image_width=image_width,
slice_height=slice_height,
slice_width=slice_width,
overlap_height_ratio=overlap_height_ratio,
overlap_width_ratio=overlap_width_ratio,
)
t0 = time.time()
n_ims = 0
# init images and annotations lists
sliced_image_result = SliceImageResult(original_image_size=[image_height, image_width], image_dir=output_dir)
# iterate over slices 迭代切片
for slice_bbox in slice_bboxes:
n_ims += 1
# extract image 提取图像
image_pil_slice = image_pil.crop(slice_bbox)
# process annotations if coco_annotations is given 如果给出coco——annotation,则处理annotation
if coco_annotation_list is not None:
sliced_coco_annotation_list = process_coco_annotations(coco_annotation_list, slice_bbox, min_area_ratio)
# set image file suffixes设置图像文件后缀
slice_suffixes = "_".join(map(str, slice_bbox)) # 0_0_256_256
if out_ext:
suffix = out_ext
else:
try:
suffix = Path(image_pil.filename).suffix
except AttributeError:
suffix = ".jpg"
# set image file name and path
# 如output_file_name = terrain2 ,slice_suffixe = 0_0_256_256, suffix = .jpg
# 所以slice_file_name = terrain2_0_0_256_256.jpg
slice_file_name = f"{output_file_name}_{slice_suffixes}{suffix}"
# create coco image
slice_width = slice_bbox[2] - slice_bbox[0]
slice_height = slice_bbox[3] - slice_bbox[1]
coco_image = CocoImage(file_name=slice_file_name, height=slice_height, width=slice_width)
# append coco annotations (if present) to coco image将coco注释(如果存在)附加到coco图像
if coco_annotation_list:
for coco_annotation in sliced_coco_annotation_list:
coco_image.add_annotation(coco_annotation)
# create sliced image and append to sliced_image_result创建切片图像并附加到切片图像结果
sliced_image = SlicedImage(
image=np.asarray(image_pil_slice),
coco_image=coco_image,
starting_pixel=[slice_bbox[0], slice_bbox[1]],
)
sliced_image_result.add_sliced_image(sliced_image)
# export slices if output directory is provided
if output_file_name and output_dir:
conc_exec = concurrent.futures.ThreadPoolExecutor(max_workers=MAX_WORKERS)
conc_exec.map(
_export_single_slice,
sliced_image_result.images,
[output_dir] * len(sliced_image_result),
sliced_image_result.filenames,
)
verboselog(
"Num slices: " + str(n_ims) + " slice_height: " + str(slice_height) + " slice_width: " + str(slice_width),
)
return sliced_image_result
3.2.1、得到sciling_img_bbox和sciling_annotation
n_ims = 0
# init images and annotations lists
# 获得到原始图片的路径,以及宽高
sliced_image_result = SliceImageResult(original_image_size=[image_height, image_width], image_dir=output_dir)
# iterate over slices 迭代切片
for slice_bbox in slice_bboxes:
n_ims += 1
# extract image 提取图像
# 也就是把对应坐标的sciling bbox从原图中裁剪出来
image_pil_slice = image_pil.crop(slice_bbox)
# process annotations if coco_annotations is given 如果给出coco——annotation,则处理annotation
#
if coco_annotation_list is not None:
sliced_coco_annotation_list = process_coco_annotations(coco_annotation_list, slice_bbox, min_area_ratio)
# set image file suffixes设置图像文件后缀
slice_suffixes = "_".join(map(str, slice_bbox)) # 0_0_256_256
if out_ext:
suffix = out_ext
else:
try:
suffix = Path(image_pil.filename).suffix
except AttributeError:
suffix = ".jpg"
# set image file name and path
# 如output_file_name = terrain2 ,slice_suffixe = 0_0_256_256, suffix = .jpg
# 就是添加slicing bbox在原图中裁剪出对应坐标的图形的名子。
# 以文中size=(682,1024)原始图片为例,会产生20个这个名字。
# 所以slice_file_name = terrain2_0_0_256_256.jpg
slice_file_name = f"{output_file_name}_{slice_suffixes}{suffix}"
# create coco image
# 把上面在原图裁剪的20 个slicing bbox的坐标类型转化为coco数据集的格式。
slice_width = slice_bbox[2] - slice_bbox[0]
slice_height = slice_bbox[3] - slice_bbox[1]
coco_image = CocoImage(file_name=slice_file_name, height=slice_height, width=slice_width)
#
# append coco annotations (if present) to coco image将coco注释(如果存在)附加到coco图像
if coco_annotation_list:
for coco_annotation in sliced_coco_annotation_list:
coco_image.add_annotation(coco_annotation)
# create sliced image and append to sliced_image_result创建切片图像并附加到切片图像结果
sliced_image = SlicedImage(
image=np.asarray(image_pil_slice),
coco_image=coco_image,
starting_pixel=[slice_bbox[0], slice_bbox[1]],
)
sliced_image_result.add_sliced_image(sliced_image)
2.2.1.1、process_coco_annotations类详解
首先我们记住两个名称:
- coco_annotation_list:原始图片的annotation中的gt_box,如下图所示:

- sliced_coco_annotation_list:就是sciling box中所对应的annotation,是通过上述 coco_annotation_list与slice_bbox经过process_coco_annotations得到的。
- sliced_coco_annotation_list = process_coco_annotations(coco_annotation_list, slice_bbox, min_area_ratio)
process_coco_annotations代码如下:
def process_coco_annotations(coco_annotation_list: List[CocoAnnotation], slice_bbox: List[int], min_area_ratio) -> bool:
"""Slices and filters given list of CocoAnnotation objects with given
'slice_bbox' and 'min_area_ratio'.
Args:
coco_annotation_list (List[CocoAnnotation])
slice_bbox (List[int]): Generated from `get_slice_bboxes`.
Format for each slice bbox: [x_min, y_min, x_max, y_max].
min_area_ratio (float): If the cropped annotation area to original
annotation ratio is smaller than this value, the annotation is
filtered out. Default 0.1.
Returns:
(List[CocoAnnotation]): Sliced annotations.
"""
sliced_coco_annotation_list: List[CocoAnnotation] = []
for coco_annotation in coco_annotation_list:
if annotation_inside_slice(coco_annotation.json, slice_bbox): # 检查原始图片中的annotation坐标是否有位于切片bbox坐标内
sliced_coco_annotation = coco_annotation.get_sliced_coco_annotation(slice_bbox)
if sliced_coco_annotation.area / coco_annotation.area >= min_area_ratio:
sliced_coco_annotation_list.append(sliced_coco_annotation)
return sliced_coco_annotation_list
2.2.1.1.1、annotation_inside_slice与get_sliced_coco_annotation类
检查原始图片中的annotation坐标是否位于切片bbox坐标内
annotation_inside_slice类:
def annotation_inside_slice(annotation: Dict, slice_bbox: List[int]) -> bool:
"""Check whether annotation coordinates lie inside slice coordinates.检查注释坐标是否位于切片坐标内
Args:
annotation (dict): Single annotation entry in COCO format.COCO格式的单个注释条目
slice_bbox (List[int]): Generated from `get_slice_bboxes`.
Format for each slice bbox: [x_min, y_min, x_max, y_max].
Returns:
(bool): True if any annotation coordinate lies inside slice.如果任何注释坐标位于切片内,则为True。
"""
# 提取原始图片(coco数据集格式)的 annotation 中的标注狂坐标。
# coco中的标注坐标指的是左上角坐标,以及宽和高。
left, top, width, height = annotation["bbox"]
right = left + width
bottom = top + height
if left >= slice_bbox[2]:
return False
if top >= slice_bbox[3]:
return False
if right <= slice_bbox[0]:
return False
if bottom <= slice_bbox[1]:
return False
return True
get_sliced_coco_annotation类
get_intersection函数:是指求出原图中annotation与sciling bbox相交的部分.
注意:return:
intersection_shapely_annotation
category_id=self.category_id,
category_name=self.category_name 原annotation的类别
iscrowd=self.iscrowd
def get_sliced_coco_annotation(self, slice_bbox: List[int]):
shapely_polygon = box(slice_bbox[0], slice_bbox[1], slice_bbox[2], slice_bbox[3])
intersection_shapely_annotation = self._shapely_annotation.get_intersection(shapely_polygon)
return CocoAnnotation.from_shapely_annotation(
intersection_shapely_annotation,
category_id=self.category_id,
category_name=self.category_name,
iscrowd=self.iscrowd,
)
上述process_coco_annotations类详解过程可能比较抽象,可以看以下本人手工制图能更清晰的了解:
