.describe() python_Python数据分析:探索性分析
写在前面
如果你忘记了前面的文章,可以看看加深印象:
Python数据处理
Python数据分析实战(2):缺失值处理
Python实战分析:获取数据
然后可以进入今天的正文
一、描述性统计分析
Excel里可以用【数据分析】功能里的【描述统计】功能来查看数据集常用的统计指标,但这里只能是对数值型的数据进行统计。

pandas里可以用describe方法对整个数据集做一个描述性统计分析,当然这里也只是对数值型数据才可以出结果,非数值型数据不在统计范围内。
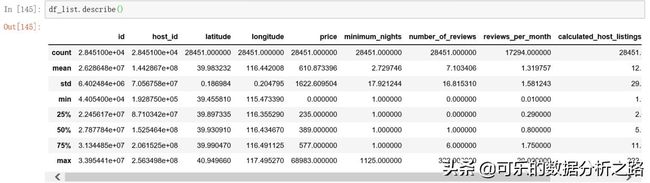
# 描述性统计分析df_list.describe()得到结果如下,可以看到count(计数)、mean(均值)、std(标准差)、min(最小值)、max(最大值)、25%、50%、75%分别表示3/4位数、中位数和1/4位数。
行列转置
由于字段太多了,所以这里可以转置一下,方便查看,用.T转置
# 行列转置df_list.describe().T结果如图,更符合一个表格的习惯,可以看到能够被统计出来的只有数值型数据,字符型的数据是统计不出来的。

观察到最小入住天数(minimum_nights)这个字段最小值、1/4位数、中位数、3/4位数都是1,说明大部分房源对最小入住天数的要求都是1天。同样的结论适用于每月评论数(reviews_per_month)这个字段
二、分组分析
Excel里用数据透视表可以实现数据分组计算的功能。
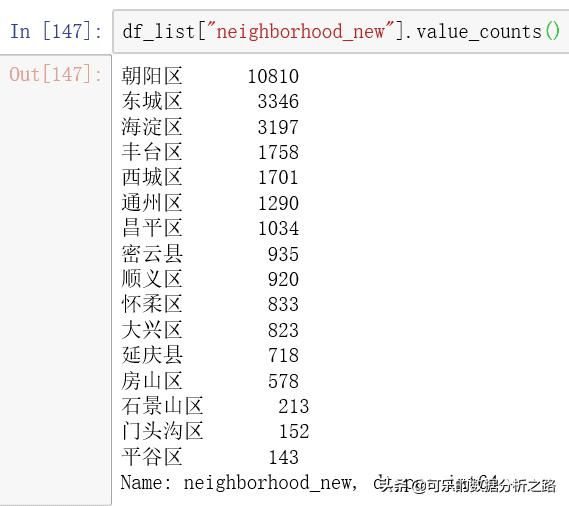
看下neighborhood_new字段都有哪些值,用value_counts方法对出现次数计数
# 数值计数df_list["neighborhood_new"].value_counts()结果可以看到neighborhood_new字段下总共有多少个区县分类及其出现的次数按降序排列下来了,可以看到朝阳区的房源最多,平谷区的房源最少。
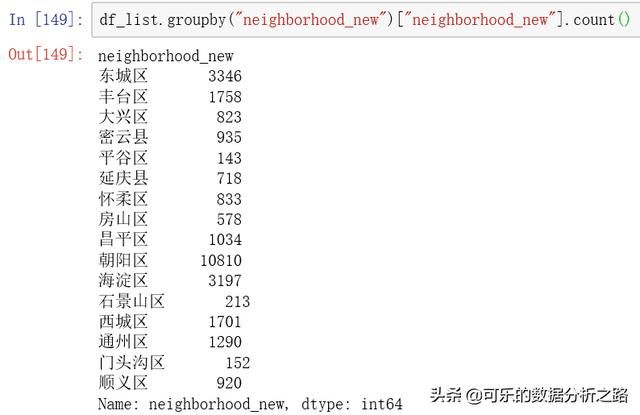
还可以用groupby方法实现分组计数
# 分组df_list.groupby("neighborhood_new")["neighborhood_new"].count()得到的结果是一样的
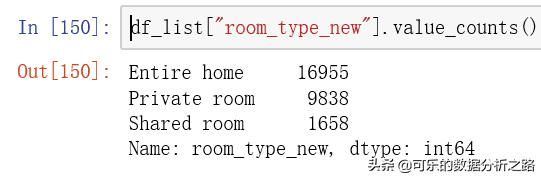
对room_type_new一列也可以分组看下结果
df_list["room_type_new"].value_counts()可以看到房间类型上有3种分类,整套房源(Entire home)最多,合租型的房源(Shared room)最少。
三、交叉分析
分组
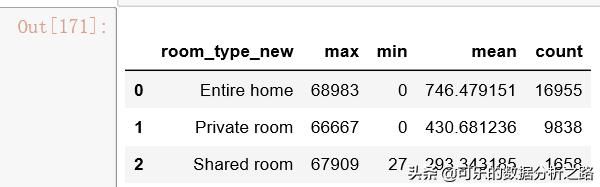
对区域分组,统计不同区域房价的水平,同样用groupby方法分组,但是可以用agg方法一次使用多种汇总方式。
df_list.groupby("neighborhood_new")["price"].agg(["max","min","mean","count"])结果如图,对neighborhood_new字段分组,对分组后的价格求最大最小平均值并计数,可以看到怀柔区的房价平均值最高,丰台区最低。

对房间类型分组,并将结果按均值降序排列
r_p = df_list.groupby("room_type_new")["price"].agg(["max","min","mean","count"]).reset_index()r_p.sort_values("mean",ascending = False)结果如图,整租的房价均值最高,合租最低,很合理的结果。
透视
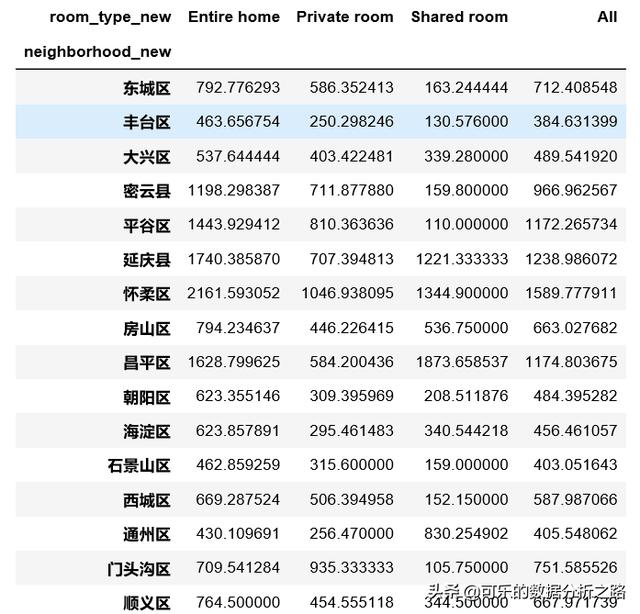
对房间类型和区域做一个透视,使用pivot_table方法,和Excel里的数据透视表是一种类型的操作,第一个参数是要透视的数据,values参数是Excel透视表中的值区域,即要进行汇总的字段,index参数是Excel透视表中的行区域,columns参数是列区域,aggfuc参数是要对values进行汇总的类型。
pd.pivot_table(df_list,values = "price",index = "neighborhood_new", columns = "room_type_new",aggfunc = "mean",margins = True)结果如图,可以看到整租、合租、单间在各个区域中的价格分布。
四、相关性分析
相关性分析是用来描述变量之间相关关系的结果,用相关系数r来表示,r>0表示正相关,r<0表示负相关,r的绝对值越接近1,表示越高度相关。 Excel里用【数据分析】工具里的【相关系数】功能可以直接计算出各个字段的相关系数。
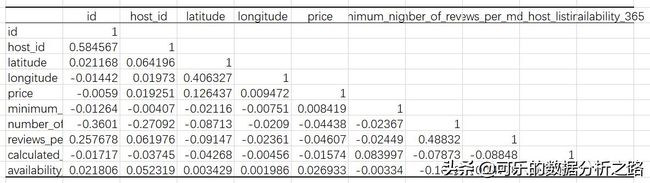
python里可以用corr函数计算数据间的相关系数,对整个数据表计算,并对结果取小数点后4位
# 计算相关系数df_list.corr().round(4)结果如下,就可以得到各个列之间的相关系数。
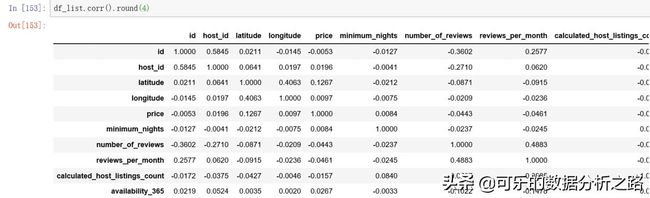
但是这里我们其实最关注的是他们同价格之间的相关性,也就是图中标红的部分,可以对这列的数值排个序。

数值排序
数值排序就是让整个数据表按照指定列升序或降序排列,用到sort_values方法。对求完相关系数后的数据框选择其price列进行降序,第一个参数是对哪一列进行排序,第二个参数ascending = False是降序排列,默认是True升序。
# 数值排序corr_p = df_list.corr().round(4)corr_p["price"].sort_values(ascending = False)结果如下,可以看到,房价和经纬度(latitude、longitude)的相关性是最高的,除此以外相比其他变量,可预定天数(availability_365)和价格最正相关的,其次每月评论数量(reviews_per_month)和价格呈负相关。

@ 作者:可乐
@ 公众号/知乎专栏/头条/简书:可乐的数据分析之路
@ 个人微信:data_cola