CenterNet算法代码剖析
目录
一、图片预处理
1、cv读取原始图片
2、读取图片的中心点
3、计算仿射变化2*3的矩阵
4、基于双线性插值的仿射变化,将原始图片映射到dst图片
5、将原始图片的值归一化到0~1之间
6、使用样本集的mean和std再进行z-score归一化
7、计算特征图的大小(128*128)
8、计算原始图片到特征图的2*3仿射变化矩阵
9、初始化结果字段
10、获取原始图片中物体的bbox并映射到特征图中
11、在特征图中构造heatmap
12、ind计算
13、中心点偏移reg计算
14、预处理之后数据结果汇总
二、Loss值计算
1、loss概述
2、FocalLoss计算流程
3、L1Loss计算流程
4、最终loss值汇总
三、预测推理过程之图像预处理
四、预测推理过程之预测结果解析
1、获取模型的输出
2、heatmap通过sigmoid映射到0~1之间
3、nms在heatmap中寻找中心点
4、取topK的中心点的分数、索引、分类、特征图中的中心点坐标值
五、预测推理过程之原始图标记
1、将bbox的2个点仿射变化到原图中(比如800* 1200)
2、将top100个点按照分类class_id放到不同的key中
3、最终返回值
六、小结
1、几种维度图片的关系
2、特征图中topK处理说明
一、图片预处理
本功能作用于dataloader阶段,读取输入图片,预处理之后获取target目标数据的各项值,后续算法预测的值与上述值进行对比从而计算loss再进行反向传播。
1、cv读取原始图片
img = cv2.imread(img_path)
2、读取图片的中心点
center = np.array([img.shape[1] / 2., img.shape[0] / 2.], dtype=np.float32)
3、计算仿射变化2*3的矩阵
需要在原始src图片和目标dst图片中分别找到对应的3个点,然后通过两边3个点的映射计算得到仿射变换矩阵。Dst图片大小为512*512。
(1)第1个点就是中心点
(2)第2个点是中心点左直width一半距离的点
(3)第3个点是第2个点下直width一半距离的点
(4)src图片和dst图片中分别通过如上操作得到3个点,然后通过如下操作计算变换矩阵。cv2.getAffineTransform(np.float32(src), np.float32(dst))
trans_input = get_affine_transform(center, s, 0, [input_w, input_h])
4、基于双线性插值的仿射变化,将原始图片映射到dst图片
inp = cv2.warpAffine(img, trans_input,
(input_w, input_h),
flags=cv2.INTER_LINEAR)
5、将原始图片的值归一化到0~1之间
inp = (inp.astype(np.float32) / 255.)
6、使用样本集的mean和std再进行z-score归一化
inp = (inp - self.mean) / self.std
7、计算特征图的大小(128*128)
output_h = input_h // self.down_ratio
output_w = input_w // self.down_ratio
8、计算原始图片到特征图的2*3仿射变化矩阵
trans_output = get_affine_transform(center, s, 0, [output_w, output_h])
9、初始化结果字段
Heatmap大小为class_num * height * weight大小
Wh和reg大小都为max_objs(128) * 2,max_objs指的是算法最多同时预测多少个目标,如果只有1个目标,则wh和reg的值为1*2。所以max_objs(128) * 2表示每个目标存放2个值,对应wh即为weight和height,对应reg即为x和y各自的偏移量
Ind为max_objs,中心点在特征图中的索引值信息,每个目标存放1个索引值即可
Reg_mask为max_objs
10、获取原始图片中物体的bbox并映射到特征图中
Bbox为矩形,打标时只有左上角和右下角的信息,则将这两个点分别映射到特征图中。
(1)在第8步中得到了仿射变化矩阵,分别将左上角和右下角的点通过该矩阵单点映射到特征图中。变化公式为:
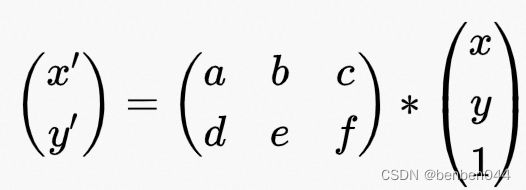
(2)对变换后的两个点做校验,保证点位置在特征图中。
11、在特征图中构造heatmap
虽然centernet是将一个物体当作一个keypoint去预测,但是如果只预测一个点则要求过于严格且难易训练,所以围绕着中心点构造一定宽度的高斯分布,目标keypoint落在这些点上都是可接受的。
(1)计算高斯分布的半径radius
根据IOU进行计算,根据如下三种情况可以分别得到3个r,然后取其中的最小值。
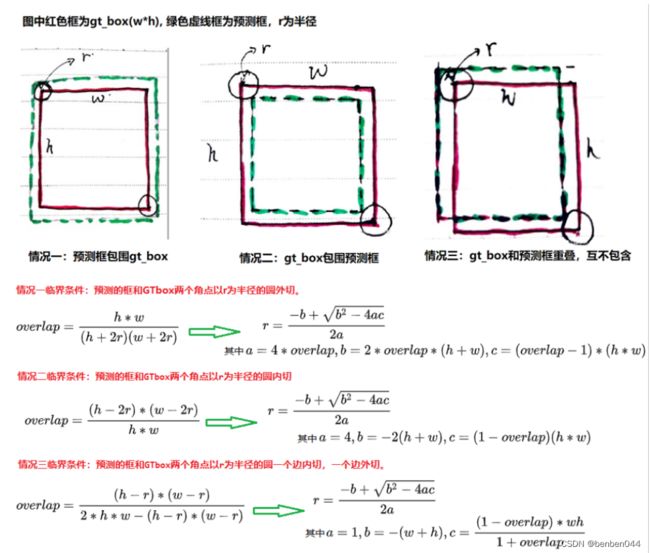
代码如下:
height, width = det_size
# 对应情况三
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2
# 对应情况二
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
# 对应情况一
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
(2)上一步的半径值取整
radius = max(0, int(radius))
最终高斯分布的sigma为radius / 3。
(3)计算128*128特征图中物体的中心点,并取整
ct = np.array( [(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2], dtype=np.float32) ct_int = ct.astype(np.int32)
(4)根据中心点、radius在heatmap中构建矩形的高斯分布
首先,画高斯分布的矩形,对应gaussian2D方法,此时不考虑是否全部涵盖在heatmap中。
y, x = np.ogrid[-m:m+1,-n:n+1]
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
然后,在heatmap中计算高斯分布矩形,需要根据中心点的位置对高斯分布做适当的裁剪
需要计算基于中心点的左、右、上、下的距离。
left, right = min(x, radius), min(width - x, radius + 1)
假如中心点的x为1,radius为2,所以left=1。
假如中心点的x为5,width=6,radius=1,则right=1。
即left,right需要考虑中心点的实际位置。
接着,在heatmap的中心点附近,基于上一步计算出来的left/right/top/bottom,从第一步高斯分布矩形中扣出相同的大小的值 赋给 heatmap中相同大小矩形的值。
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius + bottom, radius - left:radius + right]
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
heatmap的值并不是clone()给masked_heatmap,所以对masked_heatmap的修改就是对heatmap的修改。
12、ind计算
计算中心点的索引ind在heatmap(128*128特征图)中的位置,从上到下,从左到右的顺序的一维索引值。
13、中心点偏移reg计算
中心点-中心点取整 之后的偏移量
14、预处理之后数据结果汇总
{'input': inp, 'hm': hm, 'reg_mask': reg_mask, 'ind': ind, 'wh': wh, 'reg': reg}
Inp为原始图仿射变化到512*512的图像数据
Hm为128*128特征图中的中心点相关的值信息
Reg_mask[k]=1
Ind为中心点在特征图中的一维索引值
Wh为bbox在特征图中对应的width和height
Reg为特征图中的中心点跟取整后小数点的偏移量。
二、Loss值计算
最外层代码:
outputs = self.model(batch['input'])
output = outputs[-1]
loss, loss_stats = self.loss(outputs, batch)
1、loss概述
针对heatmap、wh、reg分别各自使用一种loss计算方式,最后加权获得最终的loss值。
其中heatmap使用FocalLoss计算方式,wh和reg使用L1Loss计算方式。
2、FocalLoss计算流程
计算公式如下:
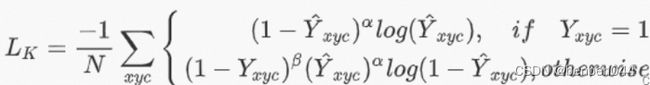
Xyc表示在某个class_id下的xy值。
计算过程在_neg_loss中,步骤如下:
(1)找出正负样例的索引值
正样例:ground truth中的heatmap中keypoint的值,即为1
负样例:ground truth的heatmap中小于1的值,即非keypoint的位置
通过正负样例的索引构造了mask,后续针对正、负样例分别计算loss值后再汇总
pos_inds = gt.eq(1).float()
neg_inds = gt.lt(1).float()
(2)分别计算正、负样例的loss值并汇总
neg_weights = torch.pow(1 - gt, 4)
pos_loss = torch.log(pred) * torch.pow(1 - pred, 2) * pos_inds
neg_loss = torch.log(1 - pred) * torch.pow(pred, 2) * neg_weights * neg_inds
num_pos = pos_inds.float().sum()
pos_loss = pos_loss.sum()
neg_loss = neg_loss.sum()
(3)汇总正负样例的loss值
loss = loss - (pos_loss + neg_loss) / num_pos
3、L1Loss计算流程
本流程同时适用于wh和reg的loss计算。
计算wh的loss时输入:
crit_reg(output['wh'], target['reg_mask'], target['ind'], target['wh'])
计算reg的loss时输入:
crit_reg(output['reg'], target['reg_mask'], target['ind'], target['reg'])
以下都以wh介绍loss的计算。
(1)输入:
Output[‘wh’]的shape为1*2*128*128,表示batch * wh的2个位置 * 特征图的width * 特征图的height
Target[‘wh’]的shape为1*128*2,表示max_objs(最大目标个数为128个,与特征图的128无关) * wh的2个位置
(2)获取128*128 heatmap中keypoint对应的wh
将预测的二维空间1*2*128*128的值转为一维空间的值1*16384*2,方便ind从一维空间中找到keypoint对应的wh值。16384=128*128。
接着根据ind获取一维中中心点对应的wh。
最后输出数据的shape是1*128*2,即batch * max_obs * wh的2个位置,假如只有一个obj,则后续只要取第一个obj的wh的2个值即可。
(3)计算l1 loss
通过mask获取预测pred(1*128*2)与实际target(1*128*2)中对应obj的wh值,然后通过F.l1_loss计算损失值,再除以obj的个数得到最终的loss值。
4、最终loss值汇总
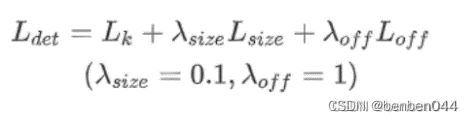
三、预测推理过程之图像预处理
函数功能见:CtdetDetector.pre_process函数
1、将原始图仿射变换到512*512,将值除以255归一化,再通过mean和std进行z-score归一化
2、计算原始图的中心点center,(height、weight)的较大值
3、输出信息为:
(1)images:1*3*512*512
(2)meta:{‘c’:c ,’s’:s, ‘out_height’:128, ‘out_width’:128}
四、预测推理过程之预测结果解析
函数功能见:CtdetDetector.process函数
1、获取模型的输出
(1)hm:预测的heatmap值,1*2*128*128,即batch * class_num * feat_height * feat_width
(2)wh: 预测的wh值,1*2*128*128, 即batch * 2 * feat_height * feat_width,该值表示在特征图(128*128)中每个点预测出来的目标的width和height
(3)reg:预测的offset值,1*2*128*128,即batch * 2 * feat_height * feat_width,该值表示在特征图(128*128)中每个点预测出来的目标x和y的偏移量
2、heatmap通过sigmoid映射到0~1之间
hm = output['hm'].sigmoid_()
3、nms在heatmap中寻找中心点
中心点的定义为:在3*3的矩阵中满足中心点最大,其他值均小于该值。
通过max_pool2d进行处理,kernel_size=1, padding=1, stride=1,取出特征图中每个点的kernel_size构建矩阵中的最大值,如果该最大值就是当前值,则当前值就是中心点的值。
上面的判断构建了mask码,heat乘以mask就只剩下了中心点。
pad = (kernel - 1) // 2
hmax = nn.functional.max_pool2d(
heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float()
return heat * keep
4、取topK的中心点的分数、索引、分类、特征图中的中心点坐标值
假设K=100
(1)获取每个分类下的topK中心点分数和索引值
[batch, cat, height, width] 转化为[batch, cat, height * width],然后求出每个cat下的topk,得到[batch, cat, K],并记录这些中心点的x,y信息
topk_scores, topk_inds = torch.topk(scores.view(batch, cat, -1), K)
topk_inds = topk_inds % (height * width)
topk_ys = (topk_inds / width).int().float()
topk_xs = (topk_inds % width).int().float()
(2)获取所有分类下的topK中心点分数和索引值
topk_score, topk_ind = torch.topk(topk_scores.view(batch, -1), K)
[batch, cat, K] 转换为[batch, cat * K]
获取了top100的分数值,两个的shape为[1,100]
通过topk_ind / K就得到了每个中心点对应的cat信息
获取topK个中心点在特征图(128*128)中的一维位置信息,x和y值。
在_gather_feat(feat, ind)中,feat的shape为[1,200,1],200存放的是128*128中的索引值。Ind的shape为[1,100],100存放的是feat的200里面的索引值。所以该函数可以获取top100个中心点在128*128中的信息。
_topk返回:
Topk_score:top100的分数值
Topk_inds: top100的中心点在特征图中的一维索引值
Topk_clses:top100的中心点对应的类别信息
Topk_ys:top100的中心点在特征图中的二维y索引值
Topk_xs:top100的中心点在特征图中的二维x索引值
(3)获取topK预测的reg和wh的信息
_transpose_and_gather_feat(feat, ind)中,feat对应预测出来的reg和wh信息,shape为[1,2,128*128],ind为上一步中topk_inds的信息。
Reg的[1,2,128*128] 转化为[1, 128*128, 2],然后在128*128的一维数组中找到ind对应的值。
对于reg来说,预测的中心点的偏移值为中心点的位置+偏移量。比如x坐标,为xs+reg中的x的偏移量。
对于wh来说,预测的中心点的width、height不需要再做处理。
(4)计算特征图中的bbox信息
左上角为:[xs - width/2, ys - width/2]
右下角为:[xs + width/2, ys + width/2]
(5)最终输出
包含bboxes,scores,clses这3部分的信息,
Bboses:[1, 100, 4]
Scores: [1, 100, 1]
Clses: [1, 100, 1]
3部分信息通过dim=2进行concat
detections = torch.cat([bboxes, scores, clses], dim=2)
dets的shape为:[1, 100, 6]
五、预测推理过程之原始图标记
本步操作主要是将特征图中的结果信息反馈到原始图中进行标记。
函数功能见:CtdetDetector. post_process函数
1、将bbox的2个点仿射变化到原图中(比如800* 1200)
首先计算出仿射变化矩阵
然后top100个点分别乘以仿射变化矩阵,得到原图中100个点的bbox信息
2、将top100个点按照分类class_id放到不同的key中
比如num_classes=2
Top_preds={}
Top_preds[0]存放分类1的40个bbox和中心点分数信息,(40,5)
Top_preds[1]存放分类2的60个bbox和中心点分数信息,(60,5)
3、最终返回值
字典形式的dets,存放的就是上面的top_preds的信息
六、小结
1、几种维度图片的关系
本算法涉及到3种维度的图片,分别是800*1200的原始图,512*512的输入图,128*128的特征图。
在训练的图片预处理阶段,我们是将800*1200的原始图的中心点,wh,reg直接对应到128*128的特征图中,这些在特征图中的值就是target目标值。同时还会将800*1200的图片仿射变化到512*512的图片。
神经网络是将512*512的图片信息提取特征到128*128的特征图中。
最后还要将128*128特征图中得到的中心点、wh、offset信息重新反馈到800*1200的原始图中。
2、特征图中topK处理说明
在class_num*128*128的featmap中,首先在每个class_num中选取topK个中心点,然后再选取所有分类的topK个中心点。所以在特征图中最终是输出topK个中心点以及附带的wh、reg等信息。
在原始图中展示时,需要根据阈值过滤topK中score过低的值,最后再展示0~K个目标。