从理论和Pytorch代码 一步步了解RNN(Recurrent Neural Network)循环神经网络+EmBedding层通俗理解
初学者学习Pytorch系列
第一篇 Pytorch初学简单的线性模型 代码实操
第二篇 Pytorch实现逻辑斯蒂回归模型 代码实操
第三篇 Pytorch实现多特征输入的分类模型 代码实操
第四篇 Pytorch实现Dataset数据集导入 必要性解释及代码实操
第五篇 Pytorch实现多分类问题 样例解释 通俗易懂 新手必看
第六篇 Pytorch使用CNN实现基本的MNIST数据集学习 通俗理解CNN
第七篇 Pytorch使用CNN实现Inception及Residual 解决代码冗余 梯度为零
第八篇 从理论和Pytorch代码 一步步了解RNN(Recurrent Neural Network)循环神经网络
文章目录
- 初学者学习Pytorch系列
- 前言
- 一、RNN理论
-
- 1.RNN的R在哪里体现?
- RNN为什么行?
- RNN有不同的循环模式(拓展)
- 二、RNN的pytorch代码
-
- 方式一:使用torch.nn.RNNCell
- 方式二:使用torch.nn.RNN
- 使用pytorch实现序列转换小案例
-
- 问题一:输入是Hello,怎么转化为可以输入模型的数字
- 使用RNNCell版本
- RNN版本
- 可能有人会对交叉熵的维度有疑问
- 改变编码方式,使用Embedding层
- Embedding在上述例子的应用
- 为什么使用Embedding后就能更快收敛,loss减小
- 总结
前言
RNN是专门用来处理具有序列模式的数据,也就是带有时间前后的时序数据,或者有先后顺序关系的序列数据,例如一个视频(每一帧的都有前后序列关系)、语言的处理(每一个词的前后序列)。而像我们的MNIST数据集,其是没有前后或者时间的序列关系。
一、RNN理论
1.RNN的R在哪里体现?
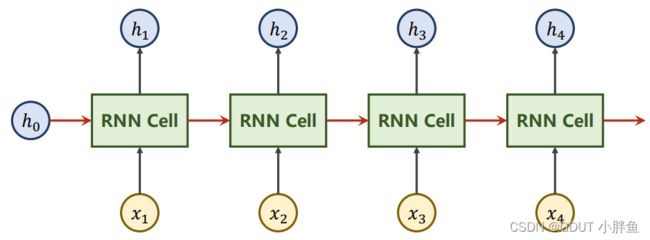 上图是RNN一个工作机理的简图,对于一个样本来说,X1,X2等的输入的一个样本的序列,例如我们要根据前三天的的天气状况,预测第四天的天气状况,那么X1,X2等输入的是第一天的天气,第二天的天气,至于某一天中有什么特征,那就是X1,X2中去表示。RNN Cell本质是线形层。
上图是RNN一个工作机理的简图,对于一个样本来说,X1,X2等的输入的一个样本的序列,例如我们要根据前三天的的天气状况,预测第四天的天气状况,那么X1,X2等输入的是第一天的天气,第二天的天气,至于某一天中有什么特征,那就是X1,X2中去表示。RNN Cell本质是线形层。
RNN Cell是怎么工作的呢?
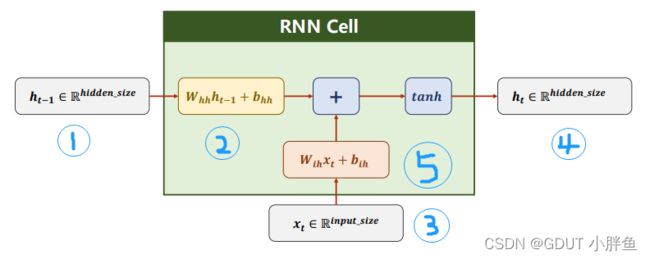
上图的几个模块用序号标记,下文直接用1,2,3代表。
3是输入的数据,input_size是指你一个序列有多大,例如在天气序列中,一个序列是一天,一天可能有气压,气温,风向,湿度四个指标,那就说明input_size = 4。在RNN Cell中可以看到,2和5都是一个线性层,它们的结果会相加作为下一次的输入,也就是模块1,第一个RNN Cell输入的模块1没有来着上一个RNNCell的结果,所以我们一般会定义一个全零初始值,当然它的维度为hidden_size。其中,5中是对输入数据3做了线性变化,将其维度变化至hidden_size的大小。而2对输入1也是乘上了相对的权重矩阵,结果2和5的维度是一样的(这样才能相加)。而在RNN Cell中,我们使用的激活函数是tanh,它映射的范围是[-1,1]。
RNN为什么行?
举个例子,如文本数据,I like beijing, 在输入RNN网络的时候,它通过编码后,并不是一整串数据直接输入进去,而是先输入I,接着是like,最后才是beijing,记住这只是一个样本。它输入的数据不再是孤立的,输入的数据之间有关联性(这个时候权重还没更新),在一个样本中,每输入一个序列会考虑前面的数据。所以我们通俗的理解上,它是将当前信息与历史信息做融合,它能更加综合地考虑前后的关系。这就是为什么有效!
RNN有不同的循环模式(拓展)
除了基本的模式,还有特殊的结构,如下面这种,从先往后学习,再从后往前,最后把两个加起来,这样子模型不仅能看到序列正向的特征,还能看到序列逆向的特征,视野更广阔,准确率更高。如下图,这样子的RNN称为Bidirectional RNN。
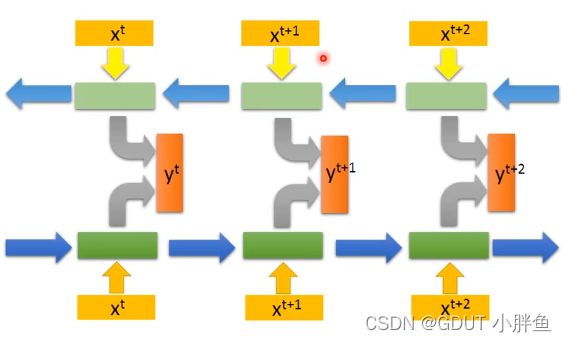
又或者有进阶的版本,如LSTM
二、RNN的pytorch代码
方式一:使用torch.nn.RNNCell
使用这个方法生成一个对象,创建的时候需要给出两个参数,input_size和hidden_size。而在使用的时候,不是直接传入数据集,需要我们自己去遍历数据集。而我们数据集的张量维度会有所不同。我们以前使用batch小批量处理数据集的时候,数据集的维度第一维都是batch_size,第二维开始才是每一个数据具体的维度,例如在MNIST数据集中,一个图片28*28,一个batch_size为64,那么输入的时候,维度为[64,28,28]。但是在RNN中,我们第一个维度设置为 [seq_len, batch_size, input_size],第一个维度为seq_size,这因为,seq_size在前面,我们遍历的时候,输入的是每一个样本第一个序列的集合,这时候数据特征都是第一个序列,而使用batch_size在第一维,遍历的时候,输入的是第一个样本的全部序列特征,这并不符合我们的需求,我们RNN是需要一个个序列去输入的。(一个样本有多个序列)
具体代码如下:
import torch
batch_size = 2
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
dataset = torch.randn(seq_len, batch_size, input_size) # 随机生成测试数据
hidden = torch.zeros(batch_size, hidden_size) # 初始化hidden,全部为0
for index, input in enumerate(dataset):
print(index, "-" * 20)
print("input_size", input.shape)
hidden = cell(input, hidden) # hidden 记录上一次的数据
print("out_size", hidden.shape)
print(hidden)
输出结果如下:
0 --------------------
input_size torch.Size([2, 4])
out_size torch.Size([2, 2])
tensor([[-0.0454, 0.4357],
[-0.0059, -0.7380]], grad_fn=<TanhBackward0> )
1 --------------------
input_size torch.Size([2, 4])
out_size torch.Size([2, 2])
tensor([[-0.5145, -0.0131],
[-0.7017, 0.8675]], grad_fn<TanhBackward0>)
2 --------------------
input_size torch.Size([2, 4])
out_size torch.Size([2, 2])
tensor([[-0.2853, -0.7647],
[-0.7544, 0.2117]], grad_fn<TanhBackward0>)
- 输入cell 的 input的shape为[batch_size,input_size],因为enumerate按照第一个维度去迭代,所以只有两个维度
- hidden的shape为[batch_size,hidden_size]
方式二:使用torch.nn.RNN
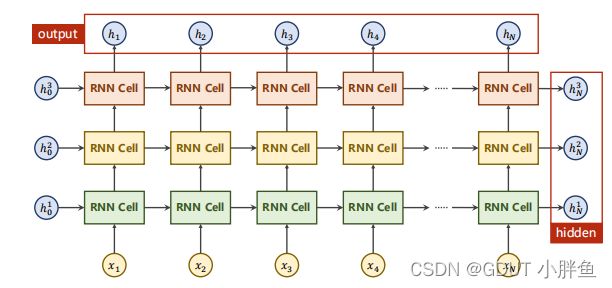
使用这种方式创建的类不一样,传入参数也不同,这里需要传入三个参数input_size,hidden_size和num_layers。num_layers是指定有多少个RNN Cell层。但是和RNNCell第一个不同的是,在使用的时候,我们不需要自己去遍历数据集,直接把数据集交给RNN即可。第二个不同是RNN的输出有两个参数,一个是ouput,一个是hidden,他们的区别如下图。
此外,在程序中,我们同样要初始化hidden,但是由于我们有多层的num_layers,所以初始化维度会多考虑一个num_layers维度。而输入的数据,维度依旧和RNNCell是一样的。
import torch
input_size = 4
seq_size = 3
hidden_size = 2
num_layers = 3
batch_size = 2
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers) # 定义RNN
inputs = torch.randn(seq_size, batch_size, input_size) # 输入数据
hidden = torch.zeros(num_layers, batch_size, hidden_size) # 初始化hidden,注意多了num_layers维度
out, hidden = cell(inputs, hidden) # 输出有两个
print('Output size:', out.shape)
print('Output:', out)
print('Hidden size: ', hidden.shape)
print('Hidden: ', hidden)
代码结果如下:
Output size: torch.Size([3, 2, 2])
Output: tensor([[[-0.6000, -0.1455],
[-0.6175, -0.1514]],
[[-0.4070, 0.0970],
[-0.4465, 0.0839]],
[[-0.4894, 0.1308],
[-0.4135, 0.1664]]], grad_fn=<StackBackward0>)
Hidden size: torch.Size([3, 2, 2])
Hidden: tensor([[[-0.0903, 0.8416],
[-0.6701, 0.8851]],
[[ 0.6462, -0.9428],
[ 0.8133, -0.8924]],
[[-0.4894, 0.1308],
[-0.4135, 0.1664]]], grad_fn=<StackBackward0>)
- hidden 的shape为[num_layers,batch_size,hidden_size]
- output 的shape为[seq_size, batch_size, hidden_size]
使用pytorch实现序列转换小案例
这里我们想让模型不断学习,以至于我们输入Hello,它能帮我们转换成ohlol。
问题一:输入是Hello,怎么转化为可以输入模型的数字
答案就是:编码!这里我们使用one-hot 编码。我们有四个字符[‘e’, ‘h’, ‘l’, ‘o’],分别给一种字符一个向量去表示。如下:
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
但是我们知道我们输入的时候,数据维度是(seq_size, batch_size, input_size),所以我们会使用view进行变化维度。变化后如下:
tensor([[[0., 1., 0., 0.]],
[[1., 0., 0., 0.]],
[[0., 0., 1., 0.]],
[[0., 0., 1., 0.]],
[[0., 0., 0., 1.]]])
使用RNNCell版本
import torch
input_size = 4
batch_size = 1
hidden_size = 4 # 因为总的序列类型只有4,所以hidden需要设置为4
inx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0], # one-hot编码表
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] #给序列编码成向量
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size) # 改变输入的维度
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size # 这些输入是初始化传入的
self.input_size = input_size
self.hidden_size = hidden_size
self.rnnCell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size) # 定义RnnCell
def forward(self, input, hidden):
hidden = self.rnnCell(input, hidden)
return hidden
def init_hidden(self): # hidden初始化函数
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimize = torch.optim.Adam(net.parameters(), lr=0.1) # 使用Adam的优化器
for epoch in range(15):
loss = 0
optimize.zero_grad()
hidden = net.init_hidden() #初始化hidden,全为0
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label) # 每次只是一个样本中一个序列,所以loss要加起来
_, idx = hidden.max(dim=1) # 提取下标
print(inx2char[idx.item()],end='') # 输入预测的值,这里一次输入一个字母,所以输出也只有一个字母
# 记得要等遍历完所以序列再更新参数
loss.backward()
optimize.step()
print(',Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
- RNNCell在实际应用的时候,与RNN的区别就是数据的维度不一样,例如输出的维度就不一样,RNNCell输出是hidden,而RNN是直接输出output,又或者hidden的维度不一样,这个都需要考虑。
- 在RNNCell中,我们去遍历序列,每次计算的loss只是一个序列的loss,在计算的时候需要把loss加起来。
- 记住我们是在遍历完样本后才更新权重,所以optimize.step()不能写在for循环中
代码结果如下:
oeeee,Epoch [1/15] loss=7.5488
oleee,Epoch [2/15] loss=5.9819
ohlll,Epoch [3/15] loss=5.0428
ohlll,Epoch [4/15] loss=4.5036
ohlll,Epoch [5/15] loss=4.1299
ohlll,Epoch [6/15] loss=3.8504
ohlll,Epoch [7/15] loss=3.6446
ohlll,Epoch [8/15] loss=3.4796
ohlll,Epoch [9/15] loss=3.3314
ohlll,Epoch [10/15] loss=3.1920
ohlll,Epoch [11/15] loss=3.0597
ohlol,Epoch [12/15] loss=2.9324
ohlol,Epoch [13/15] loss=2.8076
ohlol,Epoch [14/15] loss=2.6886
ohlol,Epoch [15/15] loss=2.5873
可以看到我们的Hello输入后,成功转换成ohlol。
RNN版本
import torch
input_size = 4
batch_size = 1
hidden_size = 4 # 因为总的序列类型只有4,所以hidden需要设置为4
num_layers = 1
seq_size=5
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
inx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_size, batch_size, input_size)
labels = torch.LongTensor(y_data)
class RNN(torch.nn.Module):
def __init__(self, batch_size, input_size, hidden_size, num_layers):
super(RNN, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = torch.nn.RNN(input_size=input_size, hidden_size=self.hidden_size, num_layers=self.num_layers)
def forward(self, input, hidden):
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
def init_hidden(self):
return torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
rnn = RNN(batch_size, input_size, hidden_size, num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.05)
for epoch in range(15):
hidden = rnn.init_hidden()
optimizer.zero_grad()
out = rnn(inputs, hidden)
loss = criterion(out, labels)
loss.backward()
optimizer.step()
_, idx = out.max(dim=1)
print(''.join(inx2char[x] for x in idx), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
- 这份代码的主题逻辑和上一份的差不多,这里就不做过多的备注。主要的不同还是数据维度的不同
- 在RNN中,我们不需要去遍历整个样本了,直接把样本丢给它。
运行结果如下:
hoeee, Epoch [1/15] loss = 1.629
hooee, Epoch [2/15] loss = 1.499
ooooo, Epoch [3/15] loss = 1.381
ooooo, Epoch [4/15] loss = 1.279
ooooo, Epoch [5/15] loss = 1.195
ooloo, Epoch [6/15] loss = 1.127
ooloo, Epoch [7/15] loss = 1.071
ooloo, Epoch [8/15] loss = 1.020
ooloo, Epoch [9/15] loss = 0.971
oolol, Epoch [10/15] loss = 0.922
ohlol, Epoch [11/15] loss = 0.873
ohlol, Epoch [12/15] loss = 0.826
ohlol, Epoch [13/15] loss = 0.783
ohlol, Epoch [14/15] loss = 0.741
ohlol, Epoch [15/15] loss = 0.702
可能有人会对交叉熵的维度有疑问
数据维度[5]和[5,4]是能做交叉熵的,但是[5,1]和[5,4]是做不了交叉熵的。例如在上面例子RNN版本中的out和label,就是[5]和[5,4],他们是能做交叉熵的。
out:tensor([[-0.6276, -0.0094, 0.4876, 0.8977],
[-0.7712, 0.6199, -0.0840, 0.3055],
[-0.8253, 0.0306, 0.8742, 0.8950],
[-0.9027, 0.1658, 0.8473, 0.6830],
[-0.7908, -0.7214, 0.7088, 0.2062]], grad_fn=<ViewBackward0>)
label:tensor([3, 1, 2, 3, 2])
改变编码方式,使用Embedding层
我们上面所使用的编码方式是one-hot编码,这个编码方式虽然可以实现我们的需求,但是却存在很多缺点,如下:
- 它的数据维度非常长,我们有4个人字母,就需要4维的数据去编码,假如我们有10000维,这个数量级的增长非常快。
- 它的数据非常稀疏,我们希望稠密一点
- 它的数据是固定的,并非学习过来的
针对上面问题,我们提出了Embedding层。网上很多资料说了本质是什么,但是很多人看了还是一头雾水,其实我们来看它的计算就知道了,它通过一个矩阵的变化,将一个高维的数据映射到低维,我们one-hot是高维的编码数据,我们用Embedding层直接降到低维,然后再去计算,这就能节省很多资源!而降到低维后,我们依然能用低维的数据去唯一表示一个数据。这就是为什么使用Embedding层最最最简单的理解!!!!
那它是怎么工作的呢????非常简单,看下面!!!
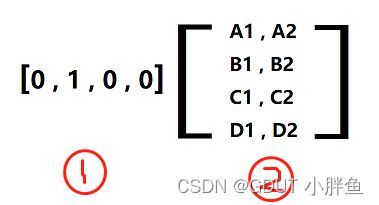
序号1 是我们的one-hot编码的数据,注意!!它只有一个数值为1,序号2是Embedding的矩阵,我们就是通过这样子一个矩阵进行线性变化!!!,当我们输入为[0,1,0,0]的时候,我们做矩阵运算,结果为[B1,B2],而[B1,B2]就是用低维去代表了我们原来高维的[0,1,0,0]。
- 注意这个矩阵是不断变化的,在有监督的学习中,它也是一个层,也是我们模型中的一种,里面的值也随着梯度下降去变化。
- 至于其他文章讲的例子,公主王妃等,其实就是想说,数据映射到另一个维度,本质就是线性变化。大家可以配合着去理解!!
- 当然编码也可以去升维,好处就是感受野更大了,更好拟合曲线。我觉得有一个比喻很好,比如前一个高维embedding是1x4,分别表示牛马花草四种属性值,后一个低维embedding是1x2,分别表示动物植物两种属性值。从高维embedding降维成低维embedding是信息的聚合,即牛马聚合成动物,花草聚合成植物: 从低维embedding升维成高维embedding是信息的解耦,动物解耦成牛马,植物解耦成花草。当然,这些是感性的理解,在模型中都是数值。 大家能做感性直观理解即可!
Embedding在上述例子的应用
加入Embedding后,我们需要稍微改变我们模型的结构,如下:
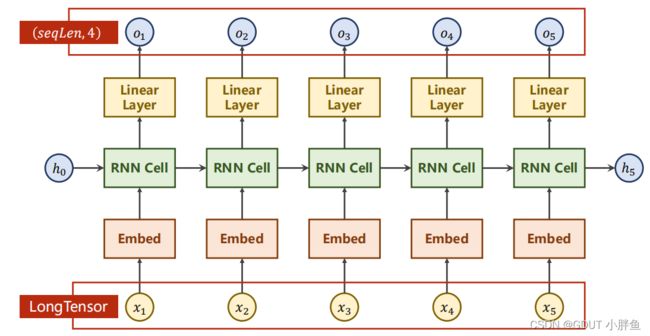
- 我们在embedding层输入数据的时候,是使用LongTensor,它的维度我们一般是设置为(, ),而且里面的数值我们不需要去转化为one-hot编码了,应该直接给出了下标。例如,我们上面的例子Hello,不需要转化为one-hot编码,但是我们还是应该保留[‘e’, ‘h’, ‘l’, ‘o’]这几个字母对应的下标,Hello对应的下标是[1, 0, 2, 2, 3]。所以hello转化为张量并进行维度转换后的LongTensor 为 tensor([[1, 0, 2, 2, 3]])(我们的batch_size只有1)。
- 我们最后还接入了一个Linear Layer层,把最后的维度转为我们需要的
在pytorch中,我们使用torch.nn.Embedding去创建Embedding类
一般构造的时候我们需要两个参数,torch.nn.Embedding(num_embeddings, embedding_dim)
- num_embeddings :字典中词的个数,例如我们有[‘e’, ‘h’, ‘l’, ‘o’]这4个字母,所以为4
- embedding_dim:想要用几个维度的数据去编码我们的序列。
构造完毕后,输入输出的数据维度如下
- input维度 :[batch_size,seq_size],因为输入batch_size是在前面了,所以RNN构造的时候,需要设置batch_first=True
- output维度:[input维度,embedding_size] ,如果代入input维度,就为[batch_size , seq_size,embedding_size],embedding_size为构造参数embedding_dim时候我们输入的值。
代码如下:
import torch
input_size = 4 # 有4个字母所以是4维
batch_size = 1
hidden_size = 8 # 因为总的序列类型只有4,所以hidden需要设置为4
num_layers = 2 # RnnCell的层数
seq_size = 5 # 序列长度
embedding_size = 10 # 嵌入层输出的维度
num_class = 4 # 最终序列的类型可能总数
inx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 3, 2]
inputs = torch.LongTensor(x_data) # (batch_size,seq_size)
labels = torch.LongTensor(y_data)
class RNN(torch.nn.Module):
def __init__(self, batch_size, input_size, hidden_size, num_layers, embedding_size):
super(RNN, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding_size = embedding_size
self.rnn = torch.nn.RNN(input_size=self.embedding_size,
hidden_size=self.hidden_size,
num_layers=self.num_layers,
batch_first=True)
self.emb = torch.nn.Embedding(self.input_size, self.embedding_size)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, input, hidden):
input = self.emb(input) # (batch_size,seq_list,embedding_size)
input, _ = self.rnn(input, hidden) # (batch_size,seq_list,hidden_size)
input = self.fc(input) # (batch_size,seq_list,num_class)
return input.view(-1, num_class)
def init_hidden(self):
return torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
rnn = RNN(batch_size, input_size, hidden_size, num_layers, embedding_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.05)
for epoch in range(15):
hidden = rnn.init_hidden()
optimizer.zero_grad()
out = rnn(inputs, hidden)
loss = criterion(out, labels)
loss.backward()
optimizer.step()
_, idx = out.max(dim=1)
print(''.join(inx2char[x] for x in idx), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
代码结果如下:
heeee, Epoch [1/15] loss = 1.904
hhehh, Epoch [2/15] loss = 1.408
ohhoh, Epoch [3/15] loss = 1.172
ohhoh, Epoch [4/15] loss = 0.981
ohlol, Epoch [5/15] loss = 0.798
ohlol, Epoch [6/15] loss = 0.616
ohlol, Epoch [7/15] loss = 0.463
ohlol, Epoch [8/15] loss = 0.349
ohlol, Epoch [9/15] loss = 0.264
ohlol, Epoch [10/15] loss = 0.201
ohlol, Epoch [11/15] loss = 0.154
ohlol, Epoch [12/15] loss = 0.118
ohlol, Epoch [13/15] loss = 0.091
ohlol, Epoch [14/15] loss = 0.070
ohlol, Epoch [15/15] loss = 0.054
通过上面的结果,我们可以看到我们的代码收敛得更快,更快达到我们所要的结果,loss也下降得更小。
为什么使用Embedding后就能更快收敛,loss减小
这里我的个人理解是,如果是Emdedding是升维的话,感受野扩大了,所以能可以加快拟合。如果是降维的话,感受野虽然没有增大,但是我们要把embdedding层看作模型中的一个层,我们神经网络层数越多,越能拟合(但是也不能过多!),embedding层中的参数是学习得到的,相当于权重的数量增加了,所以更能拟合。
总结
以上就是我个人对RNN和Embedding的理解,希望配合上其他文章,能让初学者更容易理解。如果觉得有用,请大家点赞支持!!!!。