VLN阅读报告1:Vision-and-Language Navigation综述(2022ACL)
本博文是结合论文Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions,对VLN进行学习总结与思考,主要针对室内的VLN任务,如REVERIE,SOON,R2R等更可行的具体任务。
VLN最新进展总结: https://github.com/eric-ai-lab/awesome-vision-language-navigation
本文作者分享讲解链接【AI Drive】第113期 - 加州大学古静:视觉语言导航的任务、方法和未来方向调研】
VLN阅读报告1:Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions
- 一,VLN总体介绍:
-
- 1.1 目标与意义:
- 1.2 相关工作:
- 二,VLN相关任务/数据集,评价指标
-
- 2.1 Room-to-Room(R2R)
- 2.2 REVERIE
- 2.3 SOON
- 2.4 CVDN
- 任务比较
- 2.5 评估指标
- 三,VLN方法创新
-
- 3.1 表征学习 Representation Learning
-
- 3.1.1 预训练
- 3.1.2 语义理解 Semantic Understanding
-
-
- 3.1.3 图表示 Graph Representation
- 3.1.4 记忆增强模型 Memory-augmented Model
-
-
-
- 3.1.5 辅助任务 Auxiliary Tasks
-
-
- 3.2 行动策略学习 Action Strategy Learning
-
-
- 3.2.1 强化学习 Reinforcement Learning
- 3.2.2 导航中探索 Exploration during Navigation
-
-
-
-
- 3.2.3 导航探索 Navigation Planning
- 3.2.4 Asking for Help
-
- 3.3 数据为中心的学习 Data-centric Learning
-
-
- 3.3.1 数据增强 Data Augmentation
-
-
-
-
-
- 3.3.2 课程学习 Curriculum Learning
-
-
-
-
-
- 3.3.2 多任务学习 Multitask Learning
- 3.3.2 指令解释 Instruction Interpretation
-
- 3.4 先验探索 Prior Exploration
-
- 四,总结与展望
-
-
-
- 4.1 目前的局限性:
- 4.2 未来方向:
- 个人想法与思考
-
-
五,补充材料 -
-
- A 数据集
- B 模拟器
-
一,VLN总体介绍:
人工智能的一个长期目标是建立一个智能的,能够用自然语言与人类交流,感知现实环境,执行现实世界任务的智能agent。VLN是实现这一长期目标的垫脚石。
1.1 目标与意义:
目标: Vision-and-Language Navigation属于embodied AI,旨在通过与周围的环境交互学习。 也就是说,一个智能的agent,能够向人类一样以自我为中心感知真实的3D环境从而进行学习。具体来说,VLN的目标是让一个agent根据自然语言指令和视觉场景探索没见到过的现实环境,从而实现导航,找到具体物品等具体任务。
任务: VLN任务包含三个关键要素:agent(需要被训练和学习的机器人),oracle(模拟人的作用)和真实环境。agent可以向oracle请求指导,oracle做出回应。然后agent根据收到的指令和观察到的环境与环境交互,并完成具体任务。oracle还可能根据观察到的环境和代理状态,帮助agent。
例子: 机器人被随机放置在一个位置,然后给予一个与远处物体相关的指令,如*‘Bring me the bottom picture that is next to the top of stairs on level one’*,机器人需要根据该指令和感知的视觉图像,找到该指令所指定的目标物体。 值得注意的是,目标物体在起点是无法被观测到的,这意味着机器人必须具有常识和推理能力以到达目标可能出现的位置。并且在当前阶段,我们仅要求机器人找到目标物体(如给出目标物体在视觉感知图像中的边框,或者在一系列候选物体中选出目标物体),并不需要agent真的将目标物体带回来,因为当前场景还是不可交互的。(REVERIE)
1.2 相关工作:
这一部分文中没有,在这里罗列一些小知识,回头补,,
-
1.2.1 视觉语言学习
-
1.2.2 强化学习,
-
1.2.3 模仿学习之行为克隆,
-
1.2.4 视觉/语言导航,
-
1.2.5 Maps for navigation
-
马尔可夫预测
二,VLN相关任务/数据集,评价指标
这里先简要介绍每个任务,不具体介绍其提出的方法。
2.1 Room-to-Room(R2R)
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments
提出VLN任务的第一篇论文,任务难度和提出的方法都为VLN以后的发展奠定了基础。
提出了3D模拟器,和R2R数据集,定义了VLN的一个基础任务:给出一个详细的指令让agent室内导航。
阅读报告

Anderson等人(2018b)基于Matterport3D模拟器创建R2R数据集(Chang等人,2017)。R2R中的具体代理通过模拟器中的房屋移动,遍历导航图上的边,跳到包含全景视图的相邻节点。
基于Matterport3D环境,我们收集了Room to Room(R2R)数据集,其中包含21567个开放词汇表、众包导航指令,平均长度为29个单词。每条指令都描述了一条通常穿过多个房间的轨迹。如图1所示,相关任务要求代理按照自然语言指令导航到以前未看到的建筑物中的目标位置。
2.2 REVERIE
REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments
根据简洁的指令找到远程的目标。
阅读报告

机器人被随机放置在一个位置,然后给予一个与远处物体相关的指令,如‘Bring me the bottom picture that is next to the top of stairs on level one’,机器人需要根据该指令和感知的视觉图像,找到该指令所指定的目标物体。
值得注意的是,目标物体在起点是无法被观测到的,这意味着机器人必须具有常识和推理能力以到达目标可能出现的位置。并且在当前阶段,我们仅要求机器人找到目标物体(如给出目标物体在视觉感知图像中的边框,或者在一系列候选物体中选出目标物体),并不需要agent真的将目标物体带回来,因为当前场景还是不可交互的。
2.3 SOON
SOON: Scenario Oriented Object Navigation with Graph-based Exploration
阅读报告
 代理接收由多种描述组成的复杂自然语言指令(左侧)。代理在不同房间之间导航时,首先搜索更大范围的区域,然后根据视觉场景和指令逐渐缩小搜索范围。(由粗到细地查找)
代理接收由多种描述组成的复杂自然语言指令(左侧)。代理在不同房间之间导航时,首先搜索更大范围的区域,然后根据视觉场景和指令逐渐缩小搜索范围。(由粗到细地查找)
该任务是从任意地方到指定的目标,相对于REVERIE任务,不依赖起始地点
相比之下,在分步导航任务中,如视觉语言导航或协作视觉和对话导航,任何偏离定向路径的行为都可能被视为错误
2.4 CVDN
Vision-and-dialog navigation
阅读报告

视觉对话导航中,CVDN是比较靠谱的。其目标也是找到物体。难点在于1.什么时候发出问题,2.提出什么样的问题。其他的论文如VNLA和HANNA是有点类似于一步一步的控制指令了,偏离了本意。
TEACh是目前最自由最有挑战的VLN任务。
Teach: Task-driven embodied agents that chat.
任务比较


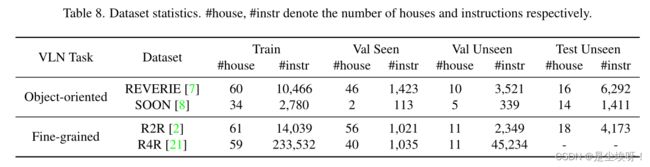
根据 Communication Complexity与 Task Objective可以将VLN分为以上任务。我们主要fellow:Room-to Room(R2R),REVERIE,SOON和CVDN任务。coarse-graied是要求agent具有高级的理解语义的能力,不需要详细具体的指令。dialogue任务具有两个难点:1.什么时候发出问题,2.提出什么样的问题。
这里可以引出其他视觉对话导航任务的一些缺点比如:
一个叫VLNA【4】,一个叫HANNA【5】,都是基于R2R的数据。其中VLNA是会在中途当navigator提出需要帮助时,由另外一个agent给出一个非常直接的关于转多少度,往哪个方向走的指令。HANNA是会给一条新的instruction以及路径交点的图片作为参考。
吴琦认为与其这样的‘控制’,不如直接去拿controller控制方向了。VLN的一个基本前提就是无法获取这类详细信息,我个人认为这两个任务有些‘本末倒置
2.5 评估指标
- 评价指标可以简单分为 三类:导航距离(越小越好),导航成功率和执行远程命令(识别objects)的成功率(都是越大越好)
Goal-oriented Metrics 主要考虑代理人与目标的接近程度
Success Rate (SR) ⬆
最直观的是成功率(SR),它衡量代理在距离目标一定距离内完成任务的频率。Success weighted by Path Length (SPL) ⬆
平衡成功率和路径长度Oracle Success Rate (OSR) ⬆
测量路径中的任何节点是否在距目标位置的阈值内Trajectory Length (TL):
平均路径长度(米)Remote Grounding Success (RGS) ⬆
成功执行指令的比例RGS penalized by Path Length (RGSPL)
Goal Progress (GP)
衡量距离目标的剩余距离的减少(m)Navigation Error (NE):
average distance in meters between agent’s final location and the target; 代理人最终位置与目标之间的平均距离(米);
其他
Path Length (PL)
测量导航路径的总长度。Shortest-Path Distance (SPD)
测量代理人的最终位置与目标之间的平均距离。Success weighted by Edit Distance (SED)
将专家的行动/轨迹与代理人的行动/轨道进行比较,同时平衡SR和PLOracle Navigation Error (ONE)
从路径中的任何节点(而不仅仅是最后一个节点)获取最短距离
Path-fidelity Metrics 评估代理遵循期望路径的程度。有些任务要求代理不仅要找到目标位置,还要遵循特定的路径。Fidelity测量专家演示中的动作序列与代理轨迹中的动作顺序之间的匹配。 。比如,指令中要求先去客厅再去厨房,直接去了厨房也不是被期待的。
Coverage weighted by LS (CLS) Length Score (LS) Path Coverage (PC)
LS(CLS)加权的覆盖率(Jain等人,2019)是路径覆盖率(PC)和长度分数(LS)相对于参考路径的乘积Normalized Dynamic Time Warping (nDTW)
柔和地惩罚与参考路径的偏差,以计算两条路径之间的匹配Success weighted by normalized Dynamic Time Warping (SDTW)
进一步限制nDTW只拍摄成功的剧集,以获得成功和忠实。
三,VLN方法创新

根据VLN任务需求可以将VLN方法分为以下四类:表征学习,行动策略学习,以数据为中心的学习以继先验探索。
3.1 表征学习 Representation Learning
表征学习方法有助于agent 理解多个模态(语言,环境等)之间的关系
3.1.1 预训练
使用预训练的方法能够使得模型理解单个模态知识以及不同模态之间的关系。VLN预训练方法需要image-text-action三元组。
三个推荐的预训练论文
Pierre-Louis Guhur, Makarand Tapaswi, Shizhe Chen, Ivan Laptev, and Cordelia Schmid. 2021. Airbert: In-domain pretraining for
vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. 2020. Towards learning a generic agent for vision-and-language navigation via pretraining. Conference on Computer Vision and Pattern Recognition (CVPR).
Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh, and Dhruv Batra. 2020. Improving vision-and-language
navigation with image- text pairs from the web. In Proceedings of the European Conference on Computer Vision (ECCV).
3.1.2 语义理解 Semantic Understanding
相当于之前看VQA的注意力机制的方法,这些效果应该都不会优于预训练方法,这一块简单了解即可
Ronghang Hu, Daniel Fried, Anna Rohrbach, Dan Klein, Trevor Darrell, and Kate Saenko. 2019. Are you looking? grounding to multiple modalities in vision- and-language navigation. In ACL
Chen Gao, Jinyu Chen, Si Liu, Luting Wang, Qiong Zhang, and Qi Wu. 2021. Room-and-object aware knowledge reasoning for remote embodied referring expression. In CVPR
Wanrong Zhu, Y uankai Qi, Pradyumna Narayana, Ka- zoo Sone, Sugato Basu, Xin Eric Wang, Qi Wu, Miguel Eckstein, and William Yang Wang. 2021b. Diagnosing vision-and-language navigation: What really matters.
3.1.3 图表示 Graph Representation
构建图可以结合来自指令和环境观察的结构化信息,提供明确的语义关系来指导导航。
graph的使用有两个方向一个是建模语言与图像对象之间的关系(根据VQA的经验,这样做无非是细化理解视觉中的object以及句子中的单词之间的关系,其实transformer往往效果比这个好)。另一个方向是构造graph去指导导航路径,这个应该是个很好的方式,比如下文:
Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
参考:论文及代码链接,阅读报告
3.1.4 记忆增强模型 Memory-augmented Model
这个和我的一个想法很相似,充分利用所有的history内容。极端情况下就是学习所有内容,按照这种想法应该会提高成功率,但也会增加导航长度。
Yicong Hong, Qi Wu, Y uankai Qi, Cristian Rodriguez- Opazo, and Stephen Gould. 2021. Vln bert: A re- current vision-and-language bert for navigation. In CVPR
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. 2021b. History aware multimodal trans- former for vision-and-language navigation. arXiv preprint arXiv:2110.13309 利用了完整的导航历史进行决策
3.1.5 辅助任务 Auxiliary Tasks
根据经验,辅助学习任务通常简单巧妙有效,不需要额外标签,结合预训练方法。
Fengda Zhu, Yi Zhu, Xiaojun Chang, and Xiaodan Liang. 2020a. Vision-language navigation with self- supervised auxiliary reasoning tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Haoshuo Huang, Vihan Jain, Harsh Mehta, Alexander Ku, Gabriel Magalhaes, Jason Baldridge, and Eu- gene Ie. 2019. Transferable representation learning in vision-and-language navigation. In ICCV
3.2 行动策略学习 Action Strategy Learning
早期的VLN目标只是room-to-room,从一个房间到另一个目标房间,试想一下,如果agent每次都能到达正确的位置,然后实现具体任务的成功率将会大幅提升。(之前看EQA的时候,准确率低的原因主要是agent甚至无法导航到准确的位置)
任务结果取决于累积的步骤,更好的行动策略有助于决策过程。由于有许多可能的行动选择和复杂的环境,行动策略学习提供了多种方法来帮助代理人决定最佳行动。
策略:强化学习,模仿学习(各有优缺点,目前交叉使用效果更好)
3.2.1 强化学习 Reinforcement Learning
RL方法的一个关键挑战是VLN代理只在事件结束时接收到成功信号,因此很难知道将成功归因于哪些行为,以及惩罚哪些行为。
Keji He, Yan Huang, Qi Wu, Jianhua Yang, Dong An, Shuanglin Sima, and Liang Wang. 2021. Landmark- rxr: Solving vision-and-language navigation with fine-grained alignment supervision. In NeurIPS.
3.2.2 导航中探索 Exploration during Navigation
在导航时探索和收集环境信息可以更好地理解状态空间.勘探与开采之间存在权衡:随着勘探的增加,代理人会以更长的路径和更长的持续时间为代价看到更好的表现.
Hanqing Wang, Wenguan Wang, Tianmin Shu, Wei Liang, and Jianbing Shen.2020a. Active visual infor- mation gathering for vision-language navigation. In ECCV
Jing Y u Koh, Honglak Lee, Yinfei Yang, Jason Baldridge, and Peter Anderson. 2021. Pathdreamer: A world model for indoor navigation. In ICCV, pages 14738–14748.
3.2.3 导航探索 Navigation Planning
规划未来的导航步骤将导致更好的行动策略。根据语言与视觉内容的预测下一步往哪走
Dong An, Y uankai Qi, Y an Huang, Qi Wu, Liang Wang, and Tieniu Tan. 2021. Neighbor-view enhanced model for vision and language navigation. arXiv preprint arXiv:2107.07201
3.2.4 Asking for Help
Xiaofeng Gao, Qiaozi Gao, Ran Gong, Kaixiang Lin, Govind Thattai, and Gaurav S Sukhatme. 2022. Dial- fred: Dialogue-enabled agents for embodied instruc- tion following. arXiv preprint arXiv:2202.13330.
3.3 数据为中心的学习 Data-centric Learning
此外,VLN任务在其训练数据中面临挑战。一个严重的问题是稀缺性。为VLN收集训练数据既昂贵又耗时,而且现有的VLN数据集对于VLN任务的复杂性来说相对较小。因此,以数据为中心的方法有助于利用现有数据并创建更多训练数据让模型学习。这一类方法也比较好。VQA中的数据增强方法是增加负样本。
3.3.1 数据增强 Data Augmentation
Trajectory-Instruction Augmentation
扩充路径指令对可直接用于VLN
Environment Augmentation
生成更多的环境数据不仅有助于生成更多的轨迹,而且还可以缓解在可见环境中过度拟合的问题。
Amin Parvaneh, Ehsan Abbasnejad, Damien Teney, Qin- feng Shi, and Anton van den Hengel. 2020. Counter- factual vision-and-language navigation: Unravelling the unseen. In NeurIPS
Chong Liu, Fengda Zhu, Xiaojun Chang, Xiaodan Liang, Zongyuan Ge, and Yi-Dong Shen. 2021. Vision-language navigation with random environmental mixup. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 1644–1654.
3.3.2 课程学习 Curriculum Learning
这种不熟悉,好像挺有意思的
Jiwen Zhang, Zhongyu Wei, Jianqing Fan, and Jiajie Peng. 2021.
Curriculum learning for vision-and-language navigation. In NeurIPSBaby-Walk: Going farther in vision-and-language navigation by taking baby steps
张等人(2021)使用每条路径穿过的房间数重新排列R2R数据集。他们发现,课程学习有助于消除损失,并找到更好的本地优化方案。
3.3.2 多任务学习 Multitask Learning
比如EQA等基于VLN的其他任务
3.3.2 指令解释 Instruction Interpretation
以不同方式多次解释轨迹指令可能有助于代理人更好地理解其目标
3.4 先验探索 Prior Exploration
这种不能与前面的方法结果比较,因为他们提前探索了环境。
在可见环境中的良好性能通常不能推广到不可见的环境。先前的探索有助于使代理适应以前看不到的环境,提高他们的概括能力,缩小可见环境与不可见环境之间的性能差距。
Xin Wang, Qiuyuan Huang, Asli Celikyilmaz, Jian feng Gao, Dinghan Shen, Y uan-Fang Wang, William Wang, and Lei Zhang. 2019. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In CVPR
Xinzhe Zhou, Wei Liu, and Y adong Mu. 2021. Rethinking the spatial route prior in vision-and-language navigation.
Fengda Zhu, Xiwen Liang, Yi Zhu, Qizhi Y u, Xiaojun Chang, and Xiaodan Liang. 2021a. Soon: Scenario oriented object navigation with graph-based exploration. In CVPR
参考:吴琦:AI研究一路走到“黑”, 从VQA到VLN
四,总结与展望
4.1 目前的局限性:
-
1.没有结合外部知识
-
2.没有实现交互
-
3.环境数据多样性匮乏
4.2 未来方向:
-
协同 VLN
当前的VLN基准和方法主要集中于只有一个代理导航的任务,但复杂的现实世界场景可能需要多个机器人协作。未来的工作可能针对多个代理之间或人与代理之间的协作VLN -
Simulation to Reality
仿真到现实当转移到现实生活中的机器人导航时,会出现性能损失(Anderson等人,2020年)。真实的机器人在连续空间中工作,但大多数模拟器只允许代理“跳跃”通过预定义的导航图,这有三个原因是不现实的(Krantz等人,2020年)。导航图假设:(1)现实世界中的完美定位是一个有噪声的估计;(2) oracle导航真正的机器人无法“传送”到新节点;(3) 在现实中,代理可能无法访问可导航节点的预设列表。真实环境的连续实现可能包含图像的补丁、模糊或具有视差误差,从而使它们变得不现实。基于3D模型和真实图像的仿真可以改善虚拟传感器(仿真中)和真实传感器之间的匹配。最后,大多数模拟器假设静态环境只由代理更改。这并没有考虑到其他动态因素,例如人行走或物体移动,也没有考虑到白天的照明条件。具有概率转移函数的VLN环境也可以缩小仿真与现实之间的差距。 -
Ethics & Privacy
VLN代理可能会观察并存储可能被泄露或滥用的敏感信息。
有效的导航和隐私保护至关重要。相关领域,如联合学习(KoneÖcn`y等人,2016年)或差异隐私(Dwork等人,2006年)也可以在VLN领域进行研究,以保护训练和推理环境的隐私。 -
多元 VLN
VLN在3D环境中缺乏多样性:大多数户外VLN数据集使用美国主要城市记录的谷歌街景,但缺乏发展中国家的数据。
受过美国数据培训的代理人在其他城市或住房布局中面临潜在的泛化问题。未来的工作应该探索跨多种文化和地区的更加多样化的环境。
多语言VLN数据集(Yan等人,2020;Ku等人,2020)可能是从语言角度研究多元文化差异的良好资源
个人想法与思考
-
VLN与VQA有着相似的发展历史。相较于视觉与自然语言之间的模态差异,VLN任务更为复杂,不仅需要学习模态之间的知识,还需要完成导航任务。所以个人认为解决VLN主要是学习环境内容和决策导航行为两个主要任务,根据VQA的经验,预训练,数据增强,辅助任务是较为有效的方法,所以下面会重点看这方面的论文。
-
泛化,先验。
之前在研究VQA的时候,VQA任务具有严重的语言先验问题,因此提出了VQA-CP数据集,即训练集和测试集内容分布及不相同,后来模型致力于提高测试集上的精确率。类似的,VLN中没见过的环境中的泛化表现很差,VQA的部分经验放到VLN中。 -
有个极端的想法:收集所有的环境信息,将任务简化为类似于VQA的任务尽可能提高成功率,然后任务变成降低复杂度和导航轨迹长度
-
数据多样性
-
利用如数据增强的方式充分利用现有的数据。
五,补充材料
A 数据集
相对数据集而言,模拟器的数量有限,目前绝大部分的任务是室内且基于Matterport3D。之前想要研究的是EmbodiedQA,复现的时候发现其基于的SUNCG 数据集缺失。
B 模拟器
数据集的虚拟特征与构建数据集的模拟器紧密相连。
Matterport3D(Anderson et al.,2018b)模拟器是一个大规模视觉强化学习仿真环境,用于基于Matterport 3D数据集(Chang et al.,2017)的人工智能研究。Matterport3D包含各种室内场景,包括房屋、公寓、酒店、办公室和教堂。代理可以沿着预定义的图形在视点之间导航。大多数室内VLN数据集(如R2R及其变体)都基于Matterport3D模拟器
official R2R leaderboard