《Essential C++》读书笔记 之 面向过程编程风格
《Essential C++》读书笔记 之 面向过程编程风格
2014-06-18
在函数swap的参数中使用reference和pointer
2.4 使用局部静态对象(Local Static Objects)
2.7 定义并使用Template Functions (模板函数)
2.8 函数指针(Pointers to Functions)带来更大的弹性
2.2 调用(invoking)一个函数
2.2.1 Pass by Reference语义
reference扮演着外界与对象之间的一个间接号码牌的角色。只要在型别名称和reference名称之间插入&符号,便声明了一个reference:
1 #include <iostream> 2 using namespace std; 3 4 int main() 5 { 6 int ival=1024; //对象,型别为int 7 int *pi=&ival; //pointer(指针),指向一个int对象 8 int &rval=ival; //reference(化身),代表一个int对象 9 10 //这里不是令rval改为代表jval对象,而是将jval赋值给rval所代表的对象(也就是ival)。 11 int jval=4096; 12 rval=jval; 13 14 ival =2048; 15 pi; 16 //这里不是令pi指向rval对象,而是将ival(此为rval所代表之对象)的地址赋给pi 17 pi=&rval; 18 19 return 0; 20 }
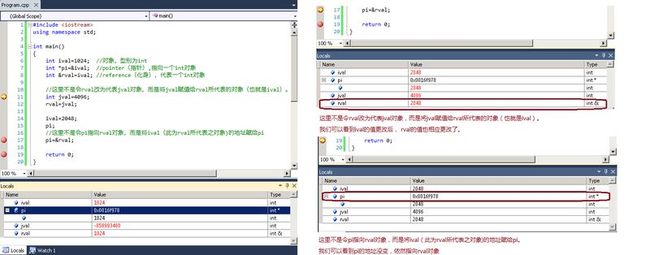
重点是:面对reference的所有操作都像面对“reference所代表的对象”所进行的操作一样。
在函数swap的参数中使用reference和pointer
当我们以reference作为函数参数时,情况是一样的,如下代码所示:
1 #include <iostream> 2 void swap(int &, int &); 3 4 int main() 5 { 6 int v1=1; 7 int v2=2; 8 swap(v1,v2); 9 10 v1; 11 v2; 12 13 return 0; 14 } 15 16 void swap(int &val1, int &val2) 17 { 18 int temp=val1; 19 val1=val2; 20 val2=temp; 21 }
运行结果如下图所示:
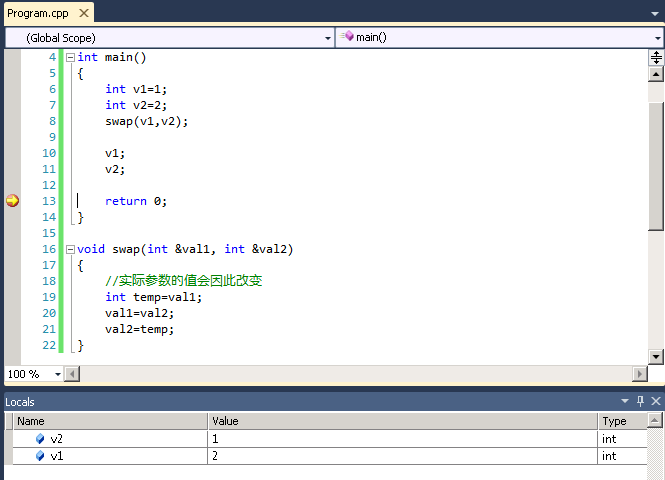
将参数声明为reference的理由有两个:
- 希望直接对所传入的对象进行修改;
- 为了降低复制大型对象的负担。
如果我们愿意,也可以将参数以pointer形式传递。这和以reference传递的效用相同:传递的是对象地址,而不是整个对象的复制品。唯一的差别是他们的用法不同。如下代码所示:
1 #include <iostream> 2 3 void swap(int *,int *); 4 5 int main() 6 { 7 int v1=1; 8 int v2=2; 9 swap(&v1,&v2); 10 11 v1; 12 v2; 13 14 return 0; 15 } 16 17 18 void swap(int *val1, int *val2) 19 { 20 int temp=*val1; 21 *val1=*val2; 22 *val2=temp; 23 }
但如果swap方法改成如下,变量v1,v2不会调换:
1 void swap(int *val1, int *val2) 2 { 3 int *temp=val1; 4 val1=val2; 5 val2=temp; 6 }
因为上述方法只是更改了指针本身的地址,如下图:
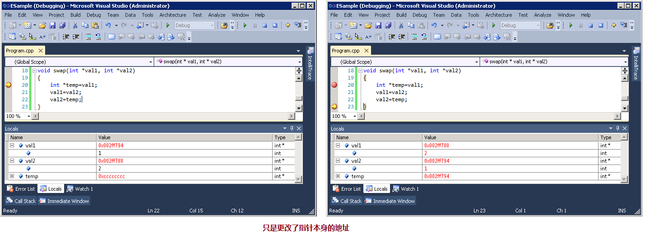
pointer参数和reference参数的差异和用法
pointer可能(也可能不)指向一个实际对象。当我门提领pointer时,一定要先确定其值并非为0。至于reference则必定会代表某个对象。
一般来说,除非你希望在函数内更改参数值,否则建议传递内建型别时,不要使用传址的方式。传址机制主要是作为传递class objects之用。
2.4 使用局部静态对象(Local Static Objects)
fibon_seq()函数是这样一个函数,每次调用时,会计算出Fibonacci数列(元数数目由用户指定),并以一个vector存储计算出来的元素值,然后返回。代码如下:
1 vector<int> fibon_seq( int size ) 2 { 3 if ( size <= 0 || size > 1024 ) 4 { 5 cerr << "Warning: fibon_seq(): " 6 << size << " not supported -- resetting to 8\n"; 7 size = 8; 8 } 9 10 vector<int> elems( size ); 11 12 for ( int ix = 0; ix < size; ++ix ) 13 if ( ix == 0 || ix == 1 ) 14 elems[ ix ] = 1; 15 else elems[ ix ] = elems[ix-1] + elems[ix-2]; 16 17 return elems; 18 }
以上代码有一个问题:每次调用时,都要重新计算。
我们希望,保存已经计算出来的元素。上面代码的局部变量肯定不行。如果将vector对象定义于file scope之中,又过于冒险,它会打乱不同函数之间的独立性,使它们难以理解。
本例的另一个解法便是使用局部静态对象:
1 #include <iostream> 2 #include <string> 3 #include<vector> 4 using namespace std; 5 6 //定义函数 7 const vector<int> *fibon_seq( int); 8 9 int main() 10 { 11 fibon_seq( 5 ); 12 fibon_seq( 4 ); //前4个element都已计算,不会重复计算 13 fibon_seq( 6 ); //只计算还没有计算出来的第6个element 14 15 return 0; 16 } 17 18 const vector<int> *fibon_seq( int size ) 19 { 20 const int max_size = 1024; 21 static vector< int > elems; 22 23 if ( size <= 0 || size > max_size ){ 24 cerr << "fibon_seq(): oops: invalid size: " 25 << size << " -- can’t fulfill request.\n"; 26 return 0; 27 } 28 29 // if size is equal to or greater than elems.size(), 30 // no calculations are necessary ... 31 for ( int ix = elems.size(); ix < size; ++ix ){ 32 if ( ix == 0 || ix == 1 ) 33 elems.push_back( 1 ); 34 else elems.push_back( elems[ix-1]+elems[ix-2] ); 35 } 36 37 return &elems; 38 }
2.5 声明一个inline函数
回想一下,fibon_elem()返回一个Fibonacci数列元素,其位置由用户指定。在最初的版本中,每次调用,它都会重新计算每一个数列元素,直到用户指定的位置位置。它会检验用户所指定的位置是否合理。
为了使这个函数更容易理解,我们可以将各个小工作分解为独立函数,以求更简化:
1 bool is_size_ok(int size) 2 { 3 const int max_size=1024; 4 if(size<=0||size>max_size) 5 { 6 cerr<<"Oops: requested size is not supported: " 7 <<size 8 <<" --can't fulfill request.\n"; 9 return false; 10 } 11 return true; 12 } 13 //计算Fibonacci数列中的size个元素 14 const vector<int>* fibon_seq(int size) 15 { 16 static vector<int> elems; 17 if(!is_size_ok(size)) 18 return 0; 19 for(int ix=elems.size();ix<size;++ix) 20 { 21 if(ix==0||ix==1) 22 elems.push_back(1); 23 else elems.push_back(elems[ix-1]+elems[ix-2]); 24 } 25 return &elems; 26 } 27 //返回Fibonaci数列中位置为pos的元素 28 bool fibon_elem(int pos,int &elem) 29 { 30 const vector<int> *pseq=fibon_seq(pos); 31 if(!pseq) 32 { 33 elem=0; 34 return false; 35 } 36 elem=(*pseq)[pos-1]; 37 return true; 38 }
但是,先前的做法中,fibon_elem()只须调用一个函数便可完成所有运算,如今必须动用3个函数。这成了它的缺点。这项负担是否很重要呢?这和应用时的形势有关。如果其执行效能不符合理想,只能在将3个函数重新组合成一个。
然而C++还提供了另一个解决方法,就是将这些函数声明为inline。
将函数声明为inline,表示要求编译器在每个函数调用点上,将函数的内容展开。面对一个inline函数,编译器可将该函数的调用操作改为一份函数代码副本取而代之。只要在函数前面加上关键字inline即可:
1 //ok:现在fibon_elem()成了inline函数 2 inline bool fibon_elem(int pos,int &elem) 3 { 4 /*函数定义与先前版本相同*/ 5 }
注意:将函数指定为inline,只是对编译器提出一种要求而没有强制性,具体分析,请参考7.1.1节
inline函数的定义常常被置于头文件中。由于编译器必须在它被调用的时候加以展开,所有这个时候起定义必须是有效的,2.9节有更深入的讨论。
2.7 定义并使用Template Functions (模板函数)
假设有3个diplay_messaeg()函数,分别用以处理元数型别为int、double、string的3中vectors:
1 void display_message(const string&, const vector<int>&); 2 void display_message(const string&, const vector<double>&); 3 void display_message(const string&, const vector<string>&);
我们在假设他们的函数主体也很相似,唯一的差别仅在于第二个参数的型别。
这样的情况很多,C++提供一种机制,函数模板(function template),将参数表中指定的参数的型别信息抽离出来。
1 #include <iostream> 2 #include <string> 3 #include<vector> 4 using namespace std; 5 6 //在mian()之前,就不用声明函数了 7 template <typename elemType> 8 void display_message(const string &msg, const vector<elemType> &vec ) 9 { 10 cout<<msg; 11 for ( int ix = 0; ix < vec.size(); ++ix ) 12 { 13 elemType t =vec[ix]; 14 cout<<t 15 <<' '; 16 } 17 } 18 19 int main() 20 { 21 string iMsg="show int vector: "; 22 int iArr[3]={1,2,3}; 23 vector<int> iVec(iArr,iArr+3); 24 display_message(iMsg,iVec); 25 cout<<'\n'; 26 27 string cMsg="show char vector: "; 28 char cArr[3]={'a','b','c'}; 29 vector<char> cVec(cArr,cArr+3); 30 display_message(cMsg,cVec); 31 32 return 0; 33 }
2.8 函数指针(Pointers to Functions)带来更大的弹性
假设有一个函数"fibon_elem()"要返回fibon数列指定位置的元素:
1 bool fibon_elem( int pos, int &elem ) 2 { 3 const vector<int> *pseq=fibon_seq(pos); //(A) 4 5 if(!pseq) 6 { 7 elem=0; 8 return false; 9 } 10 elem=(*pseq)[pos-1]; 11 return true; 12 }
上述代码,调用了函数"fibon_seq()",但除了fibon,还有其它5种数列和相应的"数列_seq()"函数:
1 const vector<int> *lucas_seq(int size); 2 const vector<int> *pell_seq(int size); 3 //...
难道我们要实现其他5种“数列_elem()”?
可以发现在函数"fibon_elem()"中,唯一和数列相关的部分,只有(A)。如果我们可以消除这个关联性,就可以不必提供多个相似函数了。
所谓函数指针,必须指明其所指向之函数的返回值类型及参数表,此外,函数指针必须将*置于某个位置,表示这份定义所表现的是一个指针。当然,最后还必须给于一个名称。
const vector<int>* *seq_ptr(int); //几乎是对的了
但这其实不是我们所要的。上述这行将seq_ptr定义为一个函数,参数表中仅有一个int类型,返回值类型是个指针,这个指针指向另一个指针,后者指向一个const vector,其元素类型为int。为了让seq_ptr被视为一个指针,我们必须以小括号改变运算顺序:
const vector<int>* (*seq_ptr)(int); //ok
现在,seq_ptr可以指向“具有所列之返回值类型及参数表”的任何一个函数。让我们将fibon_elem()重新写国,使它蜕变成更为通用的seq_elem():
1 bool seq_elem( int pos, int &elem, const vector<int>* (*seq_ptr)(int)) 2 { 3 //调用seq_ptr所指的函数 4 const vector<int> *pseq=seq_ptr(pos); //(A) 5 6 if(!pseq) 7 { 8 elem=0; 9 return false; 10 } 11 elem=(*pseq)[pos-1]; 12 return true; 13 }
现在的问题是如何取得函数的地址呢?只要给于函数名称就可以了:
1 //将pell_seq()地址赋给seq_ptr 2 seq_ptr=pess_seq;
如何想把函数指针放入一个数组,可以这么定义:
1 //seq_array是数组,内放函数指针 2 const vector<int* (*seq_array[])(int)= 3 {fibon_seq, lucas_seq, pell_seq, triang_seq, squqre_seq, pent_seq};
函数指针和指针函数区别
指针函数是指带指针的函数,即本质是一个函数。函数返回类型是某一类型的指针:
//类型标识符 *函数名(参数表) int *f(x,y);
函数指针是指向函数的指针变量,即本质是一个指针变量。
int (*f) (int x); /* 声明一个函数指针 */ f=func; /* 将func函数的首地址赋给指针f */
2.9 设定头文件(Header Fiels)
调用seq_elem()之前,必须先声明它,以便让程序知道它的存在。如果它被5个程序文件调用,就必须调用5次。C++提供一种简单的方法,把函数声明置于头文件中,并在每个程序文件代码文件中含入(include)这些函数声明。
头文件的扩展名,习惯上是.h。标准程序库例外,它们没有扩展名。我把我们的头文件命名为NumSeq.h,并将于数列处理相关的所有函数的声明都置于此文件中:
1 //NumSeq.h 2 bool seq_elem(int pos, int &elem); 3 const vector<int> *fibon_seq(int size); 4 const vector<int> *lucas_seq(int size); 5 const vector<int> *pell_seq(int size); 6 //...
注意:函数的定义只能有一份,不过声明可以有很多份。我们不能把函数的定义纳入头文件,因为同一个程序的多个代码文件可能都会含入这个头文件。
“只定义一份”的规则有个例外:inlne函数的定义。 为了能扩展inline函数的内容,在每个调用点上,编译器都得取得其定义。这意味着我们必须将inline函数的定义置于头文件中。
另外,const object和inline函数一样,是“一次定义规则”的例外。下面代码显示了把const object seq_cnt的定义加入到头文件NumSeq.h:
const int seq_cnt=6;
为什么const object是是“一次定义规则”的例外?
因为const object的定义只要一出文件之外便不可见。这意味着我们可以在多个文件中加以定义,不会导致任何错误。
我们何时将const object加入头文件呢?
当它需要跨文件使用时。
如果想把指针放入头文件NumSeq.h,需要加上关键字extern:
const int seq_cnt=6; //seq_array是指向const object的指针 extern const vector<int>* (*seq_array[seq_cnt])(int);
以下代码是含入头文件iostream和NumSeq.h:
#include <iostream> #include "NumSeq.h"
为什么头文件iostream用尖括号,而NumerSeq.h用双引号?
如果此文件被认定是标准的、或项目专属的头文件,我们便以尖括号括住:编译器搜索此文件时,会现在某些默认驱动器目录中寻找。
如果文件名由成队双引号括住,此文件 便被认为是一个用户自行提供的头文件:编译器搜索此文件时,会由含入此文件所在的驱动器目录开始找起。