用resnet50进行中文字符分类(汉字字符识别)
在项目根目录下打开终端
在终端输入以下命令进行训练:
python resnet_classifier.py --is_train=True --data_path=data/train--dict_path=key_index.txt --model_dir=model --log_dir=logs --batch_size= 8 --class_num=7 --epoch=100 --lr= 0.01 --gpu_id=0
在终端输入以下命令进行测试:
python resnet_classifier.py --is_train=False --data_path=data/test --dict_path=key_index.txt --model_dir=model --log_dir=logs --batch_size= 8 --class_num=7 --epoch=1 --gpu_id=0
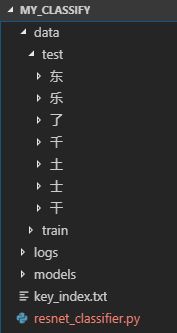
我的文件目录结构如下图所示:
train和test下文件结构一样,每个文件夹代表一类数据,文件夹名就是该文件夹下所有图片类的标签。
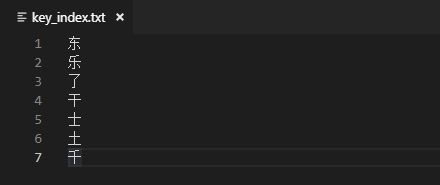
key_index.txt是字典文件,存放所有的字符标签,如下图所示:
代码实现如下:
# -*- coding: UTF-8 -*-
import os
from tensorflow.contrib.slim.nets import resnet_v1
import tensorflow as tf
import glob
import numpy as np
import cv2
import logging
slim = tf.contrib.slim
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_bool('is_train', True, 'train or test')
tf.flags.DEFINE_string('data_path', 'data/train', 'The dataset path ')
tf.flags.DEFINE_string('dict_path', 'key_index.txt',
'The directpry of chardict')
tf.flags.DEFINE_string('model_dir', 'models', 'The model saved directory ')
tf.flags.DEFINE_string('log_dir', 'logs', 'The log saved directory ')
tf.flags.DEFINE_integer('batch_size', 8, 'The batch size')
tf.flags.DEFINE_integer('class_num', 7, 'Total class number')
tf.flags.DEFINE_integer('epoch', 100, 'The repeat times')
tf.flags.DEFINE_float('lr', 0.01, 'The learning rate')
tf.flags.DEFINE_string('gpu_id','0','the gpu id')
def get_index(index_file):
#把标签值转为序号,把序号转为标签值
value2key = {}
key2value = {}
with open(index_file, 'r') as f:
for i, line in enumerate(f.readlines()):
value2key[line.strip()] = i
key2value[i] = line.strip()
return value2key, key2value
def getdata(datapath, batch_size,v2k):
#直接读取图片数据
def parse(path, label):
img = tf.read_file(path)
img = tf.image.decode_jpeg(img, 3)
img = tf.image.resize_images(img, (28, 28))
img = tf.image.rgb_to_grayscale(img) # 转为灰度图
img = tf.image.per_image_standardization(img) # 标准化
# img = img*2/255.0-1
return img, label
path = []
labels = []
for label in os.listdir(datapath):
imgs_path = glob.glob(os.path.join(datapath, label, '*.jpg'))
path += imgs_path
labels += [v2k[label]]*len(imgs_path)
data = tf.data.Dataset.from_tensor_slices((path, labels))
# tensorflow1.4
data = data.map(parse).shuffle(batch_size*10)
data = data.apply(tf.contrib.data.batch_and_drop_remainder(batch_size))
# tensorflow1.10+
# data = data.shuffle(1000).batch(batch_size, drop_remainder=True)
iterator = data.make_initializable_iterator()
imgs, labels = iterator.get_next()
return iterator, imgs, labels
def gettfdata(datapath, batch_size):
从tfrecord中读取数据
keys2features = {'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
'image/format': tf.FixedLenFeature((), tf.string, default_value='jpg'),
'image/class/label': tf.FixedLenFeature([], tf.int64, default_value=tf.zeros([], dtype=tf.int64))
}
def parse_example(example):
features = tf.parse_single_example(example, keys2features)
image = tf.image.decode_jpeg(features['image/encoded'], 1)
image = tf.image.resize(image, (28, 28))
image = tf.image.per_image_standardization(image)
label = tf.cast(features["image/class/label"], tf.int32)
return image, label
data = tf.data.TFRecordDataset(datapath).map(parse_example)
# tensorflow1.4
data = data.map(parse).shuffle(batch_size*10)
data = data.apply(tf.contrib.data.batch_and_drop_remainder(batch_size))
# tensorflow1.10+
# data = data.shuffle(1000).batch(batch_size, drop_remainder=True)
iterator = data.make_initializable_iterator()
imgs, labels = iterator.get_next()
return iterator, imgs, labels
def train(datapath, dictpath, logpath, modelpath, learning_rate, batch_size, epoch, class_num):
logging.basicConfig(filename=os.path.join(logpath,'train.log'), filemode="w", format="%(asctime)s %(name)s:%(levelname)s:%(message)s",
datefmt="%Y-%m-%d %H:%M:%S", level=logging.DEBUG)
v2k, k2v = get_index(dictpath)
# iterator, imgs, labels = gettfdata('cifar10/cifar10_train.tfrecord', batch_size)
iterator, imgs, labels = getdata(datapath, batch_size,v2k)
# 获取数据
# labels_ph = tf.placeholder(dtype=tf.int32, shape=[batch_size])
# images_ph = tf.placeholder(dtype=tf.float32, shape=[batch_size, 28, 28, 1])
with slim.arg_scope(resnet_v1.resnet_arg_scope()):
net, end_points = resnet_v1.resnet_v1_50(
imgs, class_num, is_training=True)
end_points = tf.reshape(end_points['predictions'], (batch_size, -1))
end_net = tf.reshape(net, (batch_size, -1))
logits = tf.argmax(end_points, dimension=-1,
output_type=tf.int32)
acc = tf.reduce_mean(tf.cast(tf.equal(labels, logits), tf.float32))
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=end_net, labels=labels))
tf.summary.scalar('accuracy', acc)
tf.summary.scalar('loss', loss)
global_step = tf.Variable(0, name='global_step', trainable=False)
decay_lr = tf.train.exponential_decay(
learning_rate, global_step, 10000, 0.9)
opt = tf.train.GradientDescentOptimizer(
decay_lr).minimize(loss, global_step=global_step)
saver = tf.train.Saver(max_to_keep=3, keep_checkpoint_every_n_hours=5)
with tf.Session() as sess:
kpt = tf.train.latest_checkpoint(modelpath)
if kpt:
step = int(kpt.split("-")[-1])
saver.restore(sess, kpt)
else:
step = 0
sess.run(tf.initialize_all_variables())
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter(logpath, sess.graph)
for epc in range(epoch):
sess.run(iterator.initializer)
logging.info("====the epoch%s is begin====" % epc)
# print("====the epoch%s is begin====" % epc)
while True:
try:
# imgs_, labels_ = sess.run([imgs, labels])
if step > 0:
step -= 1
# print('跳过')
continue
# labels_ = [v2k[label] for label in labels_]
merged_, global_step_, opt_, acc_, loss_, decay_lr_ = sess.run(
[merged, global_step, opt, acc, loss, decay_lr]) # , feed_dict={labels_ph: labels_, images_ph: imgs_}
writer.add_summary(merged_, global_step=global_step_)
if global_step_ % 1000 == 0:
logging.info("global_step:{},decay_lr:{},loss:{},acc:{}".format(
global_step_, decay_lr_, loss_, acc_))
saver.save(sess, modelpath +
"/model.ckpt", global_step=global_step)
except tf.errors.OutOfRangeError:
logging.info("====the epoch%s is finished====" % epc)
break
def test(datapath, dictpath, logpath, modelpath, batch_size, class_num):
logging.basicConfig(filename=os.path.join(logpath,'test.log'), filemode="w", format="%(asctime)s %(name)s:%(levelname)s:%(message)s",
datefmt="%Y-%m-%d %H:%M:%S", level=logging.DEBUG)
# iterator, imgs, labels = gettfdata('cifar10/cifar10_train.tfrecord', batch_size)
v2k, k2v = get_index(dictpath)
iterator, imgs, labels = getdata(datapath, batch_size,v2k)
# 获取数据
labels_ph = tf.placeholder(dtype=tf.int32, shape=[batch_size])
images_ph = tf.placeholder(dtype=tf.float32, shape=[batch_size, 28, 28, 1])
# v2k, k2v = get_index(dictpath)
with slim.arg_scope(resnet_v1.resnet_arg_scope()):
net, end_points = resnet_v1.resnet_v1_50(
images_ph, class_num, is_training=True)
end_points = tf.reshape(end_points['predictions'], (batch_size, -1))
end_net = tf.reshape(net, (batch_size, -1))
logits = tf.argmax(end_points, dimension=-1,
output_type=tf.int32)
acc = tf.reduce_mean(tf.cast(tf.equal(labels_ph, logits), tf.float32))
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=end_net, labels=labels_ph))
tf.summary.scalar('accuracy', acc)
tf.summary.scalar('loss', loss)
saver = tf.train.Saver()
with tf.Session() as sess:
kpt = tf.train.latest_checkpoint(modelpath)
if kpt:
saver.restore(sess, kpt)
else:
logging.info("model not found")
os._exit(0)
sess.run(iterator.initializer)
logging.info("====the test is begin====")
total_acc = 0
total_loss = 0
step = 0
while True:
try:
imgs_, labels_ = sess.run(
[imgs, labels])
# labels_ = [v2k[label] for label in labels_]
acc_, loss_, logits_ = sess.run(
[acc, loss, logits], feed_dict={labels_ph: labels_, images_ph: imgs_})
total_acc += acc_
total_loss += loss_
step += 1
logstr = 'gt=>pre:'
for i, label_ in enumerate(labels_):
logstr += k2v[label_]
logstr += '=>'
logstr += k2v[logits_.tolist()[i]]
logstr += ' '
logging.info(logstr)
logging.info(
"this batch acc is {},loss is {}".format(acc_, loss_))
except tf.errors.OutOfRangeError:
logging.info("====the test is finished====")
break
logging.info("avg_acc:{},avg_loss:{}".format(
total_acc/step, total_loss/step))
if __name__ == "__main__":
tf.reset_default_graph()
os.environ["CUDA_VISIBLE_DEVICES"] = FLAGS.gpu_id
print('gpu_id:'+FLAGS.gpu_id)
print('data_path:'+FLAGS.data_path+',dict_path:'+FLAGS.dict_path+',log_dir:'+FLAGS.log_dir+',model_dir:'+FLAGS.model_dir)
if FLAGS.is_train:
train(FLAGS.data_path, FLAGS.dict_path, FLAGS.log_dir, FLAGS.model_dir,
FLAGS.lr, FLAGS.batch_size, FLAGS.epoch, FLAGS.class_num)
else:
test(FLAGS.data_path, FLAGS.dict_path, FLAGS.log_dir,
FLAGS.model_dir, FLAGS.batch_size, FLAGS.class_num)