新闻分类作业
目录
一、资料与方法
1.数据整理
2.加载数据
3.数据预处理
3.1文本数据
3.2缺失值处理
3.3重复值处理
3.4文本内容清洗
3.5分词
3.6停用词处理
4.数据可视化分析
4.1类别数量分布
4.2词汇统计
5文本向量化
5.1词袋模型
5.2TF-IDF
二、实验与结果
1.构建训练集与测试集
2.特征选择
2.1特征选择-方差分析
3.分类模型评估
4.逻辑回归
5.KNN
6.决策树
7.多层感知器
8.朴素贝叶斯
三、讨论
3.1讨论准确率
3.2讨论F1-score
3.2.1财经
3.2.2房产
3.2.3教育
3.2.4科技
3.2.5军事
3.2.6汽车
3.2.7体育
3.2.8综合体育最新
3.2.9游戏
3.2.10娱乐
3.2.11体育焦点
3.3整体讨论
实验环境:在anaconda中的jupyter notebook编写
摘要:
一、在资料与方法中,主要内容有数据整理、加载数据、文本预处理(缺失值处理、重复值处理、文本内容清洗、分词、停用词处理)、数据可视化。
二、在实验与结果中,主要内容有构建训练集与测试集、特征选择、分类模型评估、逻辑回归、KNN、决策树、多层感知器、朴素贝叶斯。
三、在讨论中,主要根据5中分类模型:逻辑回归、KNN、决策树、多层感知器、朴素贝叶斯,进行对比。其主要内容有,讨论准确率、在每个领域都列表对比F1-score,整体讨论。通过实验发现多层感知器在整个新闻文本分类中较好,朴素贝叶斯在我这个数据集中相对较差。
一、资料与方法
1.数据整理
原始数据以及整理好的数据,还有项目源代码,在链接中自取:
链接:https://pan.baidu.com/s/11JHzlWxddUsPVEZev-9Hrw
提取码:1234
原始数据中,共有9个sheet,分别为财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐。第一步,新建一个excel表格,分别将这9个sheet数据复制到新建的new.xlsx表格中,这样可以将9个sheet数据,合并为一个sheet数据。第二步,将新建好的数据另存为csv格式。第三步,利用editplus编辑工具,将gbk格式的文本转化为utf-8格式。此时原始数据整理完毕。
2.加载数据
使用anaconda3环境下的jupyter notebook,需要安装jieba,wordcloud等库。
加载原始数据,并预览前5行,如下图所示,可以发现原始数据中共有14632个样本,有3列,分别为content,channelName,title。
代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
plt.rcParams['font.family']='SimHei'
plt.rcParams['axes.unicode_minus']='False'
plt.rcParams['font.size']=15#加载数据
news=pd.read_csv('./news.csv')
print(news.shape)
news.head()结果:

3.数据预处理
3.1文本数据
结构化数据,是可以表示成多行多列的形式,并且,每行(列)都有着具体的含义。非结构化数据,无法合理地表示为多行多列的形式,即使那样表示,每行(列)也没有具体的含义。文本数据,是一种非结构化数据,其预处理的步骤与方式也会与结构化数据有所差异。文本数据预处理主要包含:
- 缺失值处理
- 重复值处理
- 文本内容清洗
- 分词
- 停用词处理
3.2缺失值处理
如果整个数据集中缺失值较少或者缺失值数量对于整个数据集来说可以忽略不计的情况下,那么可以直接删除含有缺失值的样本记录。
news.isnull().sum()![]()
#缺失值处理
news.dropna(inplace=True)news.isnull().sum()
print(news.shape) 可以发现content中共有98个缺失样本,相对于整个样本14632来说,显得微不足道,因此将缺失的98个样本删除。删除之后共有14534个样本。如下图所示。![]()
3.3重复值处理
#重复值处理
print(news.duplicated().sum())
display(news[news.duplicated()])
结果发现共有1877个样本重复,按理来说应该删除这些样本,但是通过肉眼观察数据并未发生重复,只是前面几个字重复,因此对于重复值来说,不做任何处理。
3.4文本内容清洗
文本中存在对分析作用不大的标点符号与特殊字符,使用re库中正则匹配方法去除。
#文本内容清洗
import re
re_obj=re.compile(r"[!\"#$%&'()*+,-./:;<=>?@[\\\]{|}~——!\"<>,;:。?、¥()【】《》‘’“”\s]+")
# re_obj=re.compile(r"[z0-9_.!+-=——,$%^,。?、~@#¥%……&*《》<>「」{}【】()/\\\[\]'\"]")
def clear(text):
return re_obj.sub('',text)
news['content']=news['content'].apply(clear)
news.sample(5)3.5分词
分词是将连续的文本,分割成语意合理的若干词汇序列,中文分词需要用jieba库中的方法实现分词功能。
#分词
def cut_word(text):
return jieba.cut(text)
news['content']=news['content'].apply(cut_word)
news.sample(5)3.6停用词处理
停用词,指的是在我们语句中大量出现,但却对语义分析没有帮助的词。对于这样的词汇,我们通常可以将其删除,这样的好处在于:可以降低存储空间消耗、可以减少计算时间消耗。对于哪些词属于停用词,已经有统计好的停用词列表,直接使用就好。在这里我是用的是百度的停用词表baidu_stopwords.txt。
#停用词处理
def get_stopword():
s=set()
with open('./stopwords.txt','r',encoding='UTF-8') as f:
for line in f:
s.add(line.strip())
return s
def remove_stopword(words):
return [word for word in words if word not in stopword]
stopword=get_stopword()
news['content']=news['content'].apply(remove_stopword)
news.sample(5)定义函数remove_stopword():遍历文本数据词汇,去掉存在于停用词表中的词汇。
4.数据可视化分析
4.1类别数量分布
统计新闻文本中每种channelName的数量。
#类别数量分布
t=news['channelName'].value_counts()
print(t)
t.plot(kind='bar')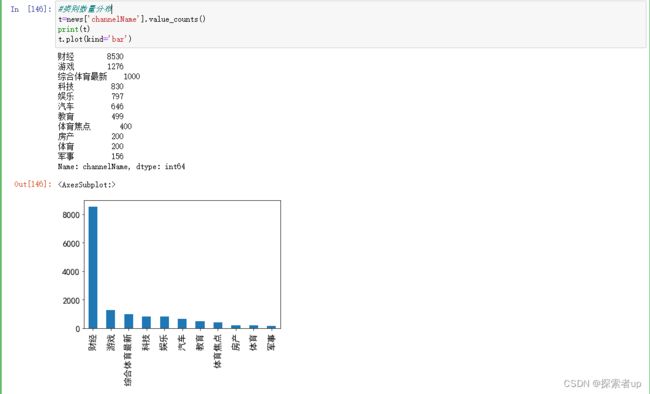
结果发现:一共共有11中类别,和之前9个sheet相比,说明其中某个sheet里面具有多个类别。通过图可以发现属于财经的比较多,属于军事的较少。
4.2词汇统计
4.2.1统计在所有新闻中出现频数最多的15个词汇
#出现最多的前15个词
from itertools import chain
from collections import Counter
li_2d=news['content'].tolist()
li_1d=list(chain.from_iterable(li_2d))
print(f'总词汇量:{len(li_1d)}')
c=Counter(li_1d)
print(f'不重复词汇量:{len(c)}')
common=c.most_common(15)
print(common)
结果发现:
总词汇量:4895183
不重复词汇量:164074
出现最多的15个词汇,及其数量如下:
[('年', 33083), ('发展', 28876), ('中国', 28355), ('月', 28055), ('企业', 22364), ('中', 20457), ('新', 19456), ('上', 18020), ('市场', 16240), ('经济', 15899), ('增长', 14383), ('日', 14355), ('建设', 12536), ('都', 12521), ('更', 12433)]
4.2.2可视化
1)根据出现最多的15个词汇的频数做条形图。
d=dict(common)
plt.figure(figsize=(15,5))
plt.bar(d.keys(),d.values())
2)根据出现最多的15个词汇的频数做条形图。
total=len(li_1d)
percentage=[v*100/total for v in d.values()]
plt.figure(figsize=(15,5))
plt.bar(d.keys(),percentage)
4.2.3频数分布统计
plt.figure(figsize=(15,5))
t=pd.Series(c)
plt.hist(c.values(),bins=15,log=True)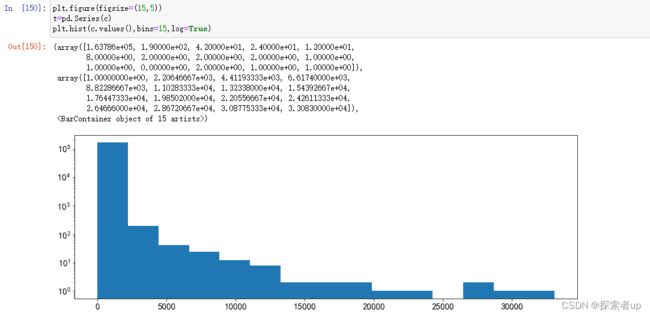
5文本向量化
对文本数据进行建模,有两个问题需要解决:
- 模型进行的是数学运算, 因此需要数值类型的数据, 而文本不是数值类型数据。
- 模型需要结构化数据, 而文本是非结构化数据。
将文本转换为数值特征向量的过程,称为文本向量化。将文本向量化可以分为如下步骤:
- 对文本分词, 拆分成更容处理的单词。
- 将单词转换为数值类型, 即使用合适的数值来表示每个单词。
文本是非结构化数据,在向量化过程中,需要将其转换为结构化数据。
5.1词袋模型
词袋模型,直观上理解,就是一个装满单词的袋子。实际上,词袋模型是一种能够将文本向量化的方式。在词袋模型中,每个文档为一个样本,每个不重复的单词为一个特征,单词在文档中出现的次数作为特征值。运词袋模型,我们也将文本数据转换为结构化数据。
默认情况下,CountVectorizer 只会对字符长度不小于2 的单词进行处理,如果单词长度小于2(单词仅有一个字符),则会忽略该单词。经过训练后,countvectorizer 就可以对未知文档(训练集外的文档)进行向量化。当然,向量化的特征仅为训练集中出现的单词特征,如果未知文档中的单词不在训练集中,则在词袋模型中无法体现。
5.2TF-IDF
通过CountVectorizer 类,我们能够将文档向量化处理。在向量化过程中,我们使每个文档中单词的频数作为对应待征的取值。这是合理的,因为,单词出现的次数越多,我们就认为该单词理应比出现次数少的单词更加重要。然而,这是相对的,有些单词,我们不能仅以当前文档中的频数来进行衡量,还要考虑其在语料库中,在其他文档中出现的次数。因为有些单词,确实是非常常见的,其在语料库所有的文档中,可能都会频繁出现,对于这样的单词,我们就应该降低其重要性。例如,在新闻联播中,”中国“、”发展“等单词,在语料库中出现的频率非常高,即使这些词在某篇文档中频繁出现,也不能说明这些词对当前文档是非常重要的,因为这些词并不含有特别有意义的信息。 TF-IDF 可以用来调整单词在文档中的权重,其由两部分组成:
- TF (Term-Frequency) 词频, 指一个单词在文档中出现的次数。
- IDF (lnverse Document-Frequency)逆文档频率。
计算方式为:

使用TfidfTransformer进行TF-IDF转化,此外,scikit-learn同时提供了一个类TfidfVectorizer, 其可以直接将文档转换为TF-IDF值,也就是说,该类相当于集成了CountVectorizer 与TfidfTransformer两个类的功能,十分便利。
二、实验与结果
1.构建训练集与测试集
我们需要将每条新闻的词汇进行整理。目前,我们文本内容已经完成了分词处理,但词汇是以列表类型呈现的,为了方便后续的向量化操作(文本向量化需要传递空格分开的字符串数组类型),我们将每条新闻的词汇组合在一起,成为字符串类型,使用空格分隔。将chanelName转换为离散值,之后对样本数据进行切分,构建训练集与测试集。
如下图所示,我把content内容作为特征值,把channelName作为标签值,另外channelName中共有11种,分别是:财经,房产,教育,科技,军事,汽车,体育,综合体育最新,游戏,娱乐,体育焦点。并将其转化为离散值0,1,2,3,4,5,6,7,8,9,10分别代表。将数据集按3:1的比例划分为训练集和测试集,其中训练集样本有10900条,测试集有3634条。
news['channelName']=news['channelName'].map({'财经':0, '房产':1,'教育':2,'科技':3,'军事':4,'汽车':5,'体育':6,'综合体育最新':7,'游戏':8,'娱乐':9,'体育焦点':10})
news['channelName'].value_counts()#构建训练集与测试集
from sklearn.model_selection import train_test_split
x=news['content']
y=news['channelName']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=1)
print('训练集样本数:',y_train.shape[0],'测试集样本数:',y_test.shape[0])2.特征选择
2.1特征选择-方差分析
到目前为止,数据集还是文本类型,我们需要对其进行向量化操作。这里,我们使用TfidfVectorizer类,在训练集上进行训练,然后分别对训练集与测试集实施转换。 使用词袋模型向量化后,会产生过多的特征,这些特征会对存储与计算造成巨大的压力,同时,并非所有的特征都对建模有帮助,基于以上原因,在将数据送入模型之前,先进行特征选择。这里,使用方差分析(ANOVA) 来进行特征选择,选择与目标分类变量最相关的14000 个特征。方差分析用来分析两个或多个样本(来自不同总体)的均值是否相等,进而可以用来检验分类变量与连续变量之间是否相关。
from sklearn.feature_selection import SelectKBest
x_train_tran=x_train_tran.astype(np.float32)
x_test_tran=x_test_tran.astype(np.float32)
selector=SelectKBest(f_classif,k=min(14000,x_train_tran.shape[1]))
selector.fit(x_train_tran,y_train)
x_train_tran=selector.transform(x_train_tran)
x_test_tran=selector.transform(x_test_tran)
print(x_train_tran.shape,x_test_tran.shape)3.分类模型评估
混淆矩阵:可以来评估模型分类的正确性。该矩阵是一个方阵, 矩阵的数值来表示分类器预测的结果, 包括真正例(True Positive ) 假正例(FaIsePositive) 真负例(True Negative )假负例(False Negative)。

分类模型的评估标准一般最常见使用的是准确率,即预测结果正确的百分比。
准确率是相对所有分类结果;精确率、召回率、F1-score是相对于某一个分类的预测评估标准。一般都是用准确率来作为评价指标,然而对于类别不均衡的任务来说,或者在任务中某一个类的准确率非常重要。如果再使用单纯的准确率肯定是不合理的,对任务来说 没有意义。所以我们需要一个好的评价指标来。目前一般都是用精准率,召回率,F1-score来评价模型;
准确率(Accuracy):预测结果正确的百分比 —— (TP+TN)/(TP+TN+FP+FN) 。
精确率(Precision):预测结果为正例样本中真实为正例的比例(查的准)—— TP/(TP+FP) 。召回率(Recall):真实为正例的样本中预测结果为正例的比例(查的全)—— TP/(TP+FN) 综合指标(F1-score):综合评估准确率与召回率,反映了模型的稳健型 —— 2PrecisionRecall/(Precision+Recall)
4.逻辑回归
采用逻辑回归编写代码,如下:
#逻辑回归
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
param =[{'penalty':['l1','l2'],'C':[0.1,1,10],'solver':['liblinear']},{'penalty':['elasticnet'],'C':[0.1,1,10],'solver':['saga'],'l1_ratio':[0.5]}]
gs=GridSearchCV(estimator=LogisticRegression(),param_grid=param,cv=2,scoring='f1',n_jobs=-1,verbose=10)
gs.fit(x_train_tran,y_train)
print(gs.best_params_)
y_hat=gs.best_estimator_.predict(x_test_tran)
labels=[0,1,2,3,4,5,6,7,8,9,10]
target_names=['财经', '房产','教育','科技','军事','汽车','体育','综合体育最新','游戏','娱乐','体育焦点']
print(classification_report(y_test,y_hat,labels=labels,target_names=target_names))
5.KNN
采用KNN算法编写代码如下:
#KNN
from sklearn.neighbors import KNeighborsClassifier
param={'n_neighbors':[5,7],'weights':['uniform','distance'],'p':[2]}
gs=GridSearchCV(estimator=KNeighborsClassifier(),param_grid=param,cv=2,scoring='f1',n_jobs=-1,verbose=10)
gs.fit(x_train_tran,y_train)
print(gs.best_params_)
y_hat=gs.best_estimator_.predict(x_test_tran)
labels=[0,1,2,3,4,5,6,7,8,9,10]
target_names=['财经', '房产','教育','科技','军事','汽车','体育','综合体育最新','游戏','娱乐','体育焦点']
print(classification_report(y_test,y_hat,labels=labels,target_names=target_names))
6.决策树
采用决策树编写代码如下:
#决策树
from sklearn.tree import DecisionTreeClassifier
param={'criterion':['gini','entropy'],'max_depth':[10,15]}
gs=GridSearchCV(estimator=DecisionTreeClassifier(),param_grid=param,cv=2,scoring='f1',n_jobs=-1,verbose=10)
gs.fit(x_train_tran,y_train)
print(gs.best_params_)
y_hat=gs.best_estimator_.predict(x_test_tran)
labels=[0,1,2,3,4,5,6,7,8,9,10]
target_names=['财经', '房产','教育','科技','军事','汽车','体育','综合体育最新','游戏','娱乐','体育焦点']
print(classification_report(y_test,y_hat,labels=labels,target_names=target_names))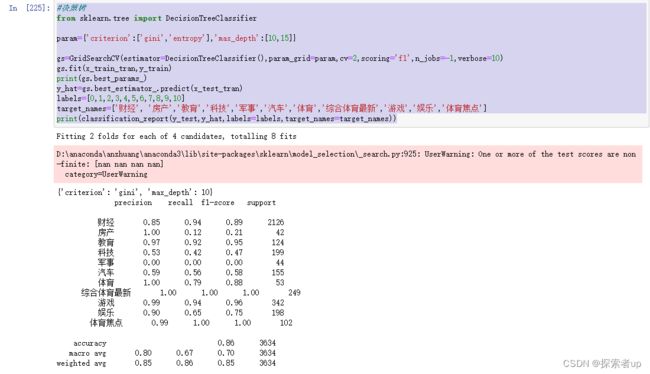
7.多层感知器
采用多层感知器编写代码如下:
#多层感知器
from sklearn.neural_network import MLPClassifier
param={'hidden_layer_sizes':[(8,),(4,)],}
gs=GridSearchCV(estimator=MLPClassifier(),param_grid=param,cv=2,scoring='f1',n_jobs=-1,verbose=10)
gs.fit(x_train_tran,y_train)
print(gs.best_params_)
y_hat=gs.best_estimator_.predict(x_test_tran)
labels=[0,1,2,3,4,5,6,7,8,9,10]
target_names=['财经', '房产','教育','科技','军事','汽车','体育','综合体育最新','游戏','娱乐','体育焦点']
print(classification_report(y_test,y_hat,labels=labels,target_names=target_names))其结果为:

8.朴素贝叶斯
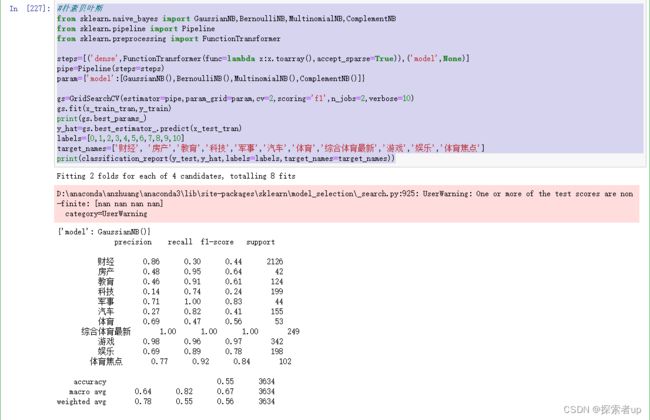
采用朴素贝叶斯算法编写代码如下:
#朴素贝叶斯
from sklearn.naive_bayes import GaussianNB,BernoulliNB,MultinomialNB,ComplementNB
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer
steps=[('dense',FunctionTransformer(func=lambda x:x.toarray(),accept_sparse=True)),('model',None)]
pipe=Pipeline(steps=steps)
param={'model':[GaussianNB(),BernoulliNB(),MultinomialNB(),ComplementNB()]}
gs=GridSearchCV(estimator=pipe,param_grid=param,cv=2,scoring='f1',n_jobs=2,verbose=10)
gs.fit(x_train_tran,y_train)
print(gs.best_params_)
y_hat=gs.best_estimator_.predict(x_test_tran)
labels=[0,1,2,3,4,5,6,7,8,9,10]
target_names=['财经', '房产','教育','科技','军事','汽车','体育','综合体育最新','游戏','娱乐','体育焦点']
print(classification_report(y_test,y_hat,labels=labels,target_names=target_names))其计算结果为:
三、讨论
以下是根据输出的评估模型报告进行讨论。
3.1讨论准确率
根据评估模型报告,把5份报告合并为一张表中,如下表所示。
| 算法 |
准确率(accuracy) |
| 逻辑回归 |
0.74 |
| KNN |
0.85 |
| 决策树 |
0.86 |
| 多层感知器 |
0.94 |
| 朴素贝叶斯 |
0.55 |
讨论:由结果可知多层感知器在整个数据集中准确率较高,而朴素贝叶斯准确率较低,其中KNN算法与决策树则差不多。
3.2讨论F1-score
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。F1分数认为召回率和精确率同等重要,F1-score反映了模型的稳健型,因此在此讨论F1-score,而不再讨论精确率和召回率。
3.2.1财经
| 算法 |
F1-score |
| 逻辑回归 |
0.82 |
| KNN |
0.90 |
| 决策树 |
0.89 |
| 多层感知器 |
0.95 |
| 朴素贝叶斯 |
0.44 |
有上表可知,多层感知器、决策树、KNN都分别达到90%以上,其中多层感知器用于财经分类问题上较好,达到了95%。
3.2.2房产
| 算法 |
F1-score |
| 逻辑回归 |
0.00 |
| KNN |
0.39 |
| 决策树 |
0.21 |
| 多层感知器 |
0.92 |
| 朴素贝叶斯 |
0.64 |
有上表可知,多层感知器用于房产分类问题上较好,达到了92%。
3.2.3教育
| 算法 |
F1-score |
| 逻辑回归 |
0.36 |
| KNN |
0.67 |
| 决策树 |
0.95 |
| 多层感知器 |
0.94 |
| 朴素贝叶斯 |
0.61 |
有上表可知,决策树和多层感知器都到了90%以上,其中决策树用于教育分类问题上较好,达到了95%。
3.2.4科技
| 算法 |
F1-score |
| 逻辑回归 |
0.09 |
| KNN |
0.60 |
| 决策树 |
0.47 |
| 多层感知器 |
0.73 |
| 朴素贝叶斯 |
0.24 |
有上表可知,多层感知器用于科技分类问题上较好,达到了73%。
3.2.5军事
| 算法 |
F1-score |
| 逻辑回归 |
0.00 |
| KNN |
0.20 |
| 决策树 |
0.00 |
| 多层感知器 |
0.98 |
| 朴素贝叶斯 |
0.83 |
有上表可知,多层感知器用于军事分类问题上较好,达到了98%。
3.2.6汽车
| 算法 |
F1-score |
| 逻辑回归 |
0.41 |
| KNN |
0.69 |
| 决策树 |
0.58 |
| 多层感知器 |
0.82 |
| 朴素贝叶斯 |
0.41 |
有上表可知,多层感知器用于汽车分类问题上较好,达到了82%。
3.2.7体育
| 算法 |
F1-score |
| 逻辑回归 |
0.00 |
| KNN |
0.08 |
| 决策树 |
0.88 |
| 多层感知器 |
0.98 |
| 朴素贝叶斯 |
0.56 |
有上表可知,多层感知器用于体育分类问题上较好,达到了98%。
3.2.8综合体育最新
| 算法 |
F1-score |
| 逻辑回归 |
0.93 |
| KNN |
0.99 |
| 决策树 |
1.00 |
| 多层感知器 |
1.00 |
| 朴素贝叶斯 |
1.00 |
有上表可知,这个5个模型在分类上都比较好,达到了90%以上,其中决策树、多层感知器、朴素贝叶斯用于综合体育最新分类问题上较好,达到了100%。
3.2.9游戏
| 算法 |
F1-score |
| 逻辑回归 |
0.78 |
| KNN |
0.91 |
| 决策树 |
0.96 |
| 多层感知器 |
0.99 |
| 朴素贝叶斯 |
0.97 |
有上表可知,除了逻辑回归外,其它4个模型在分类上都比较好,达到了90%以上,其中多层感知器用于游戏分类问题上较好,达到了99%。
3.2.10娱乐
| 算法 |
F1-score |
| 逻辑回归 |
0.41 |
| KNN |
0.82 |
| 决策树 |
0.75 |
| 多层感知器 |
0.94 |
| 朴素贝叶斯 |
0.78 |
有上表可知,多层感知器用于娱乐分类问题上较好,达到了94%。
3.2.11体育焦点
| 算法 |
F1-score |
| 逻辑回归 |
0.24 |
| KNN |
0.69 |
| 决策树 |
1.00 |
| 多层感知器 |
0.99 |
| 朴素贝叶斯 |
0.84 |
有上表可知,决策树、多层感知器都达到了90%以上,其中决策树用于体育焦点分类问题上较好,达到了100%。
3.3整体讨论
有上述表格中的数据可知,在整个新闻文本分类中多层感知机最好。最不好的是逻辑回归,在5个算法模型比较中偏低,在某些领域分类问题中不能分出。
注:这是自然语言处理的作业,数据集是老师发的,做个新闻分类,后期可以自己看看,做个记录
灵感来源于这个,参考它的,做的自己的。
python文本数据分析案例—新闻分类 - 知乎前言 数据分析不只是对数值型数据的分析,对文本数据的分析也是十分常见的。大家常看到的新闻类APP,如:今日头条,UC头条等,通常都已按新闻类型分好类别,读者可根据自己的喜好查看相应的新闻内容。本案例从数据… https://zhuanlan.zhihu.com/p/134082749
https://zhuanlan.zhihu.com/p/134082749