yolov5训练voc数据集
1.数据集

下载好voc数据集,以2007为例,把数据集(VOCtrainval_06-Nov-2007和VOCtest_06-Nov-2007)都解压同一个文件夹里,记住解压后的图片是从000001.jpg-009963.jpd的。
在VOCdevkit/目录下 运行voc2yolo.py代码
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 这里就体现出来了咱们在1.2步骤的时候我说的尽量按照那个目录名进行操作的优势,
# 在这可以剩下很多去修改名称的精力
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] # 我只用了VOC2007
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"]
#classes = ["face"] # 修改为自己的label
def convert(size, box):
dw = 1./(size[0]) # 有的人运行这个脚本可能报错,说不能除以0什么的,你可以变成dw = 1./((size[0])+0.1)
dh = 1./(size[1]) # 有的人运行这个脚本可能报错,说不能除以0什么的,你可以变成dh = 1./((size[0])+0.1)
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
# 这块是路径拼接,暂时用不上,先都注释了
# os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
# os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
之后会生成三个.txt文件和一个labels文件夹。labels文件夹在VOCdevkit\VOC2007里

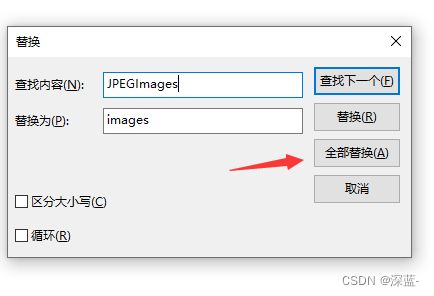
yolov5训练需要的就是JPEGImages下的所有图片以及labels下的所有标签。主要通过train.txt和val.txt里面的内容查找images和labels去训练。所以在yolov5里,images和labels的目录结构和名字最好以下面格式出现。
.
├── images
│ ├── 000001.jpg
│ ├── 000002.jpg
│ └── 000003.jpg
├── labels
│ ├── 000001.txt
│ ├── 000002.txt
│ └── 000003.txt
图片文件放在images,标签放在labels。images和labels需要在同一个根目录里。否则训练时找不到标签。如下
Traceback (most recent call last):
File "train.py", line 669, in <module>
train(hyp, opt, device, tb_writer)
File "train.py", line 246, in train
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train: '))
File "/home/yolov5/yolov5/utils/datasets.py", line 72, in create_dataloader
prefix=prefix)
File "/home/yolov5/yolov5/utils/datasets.py", line 396, in __init__
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {help_url}'
AssertionError: train: No labels in /home/yolov5/yolov5/data/2007_train.cache. Can not train without labels. See https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
所以可以把JPEGImages的名字修改为images,同时也要修改train.txt,val.txt和test.text里面的目录,这里在windos下打开train.txt然后使用替换就行非常方便。