基于预训练模型的Unet【超级简单】【懒人版】【Pytorch版】
基于预训练模型的Unet【超级简单】【懒人版】【Pytorch版】
在本项目开始前,首先给大家保证,本次项目只是一个最简单的Unet实现,使用现成的代码,不需要手写代码,使用预训练模型,不需要标注数据集和训练。所以,如果只是想稍微接触一下语义分割的话,放心观看!!!保证不需要脑子!!!
 大家好哇!其实在计算机视觉领域,一直有一个我很感兴趣,但是至今还没有接触的任务,就是语义分割。我们实验室面有人做语义分割,每次看到展示工作的时候,都觉得好神奇哇!智能抠图!好有意思!
大家好哇!其实在计算机视觉领域,一直有一个我很感兴趣,但是至今还没有接触的任务,就是语义分割。我们实验室面有人做语义分割,每次看到展示工作的时候,都觉得好神奇哇!智能抠图!好有意思!
现在让我们开始吧!
实验
首先我们在GitHub上面下载Pytorch版的Unet官方代码:
 下载之后,我们可以看到,在predict.py文件里面,这里‘–model’,默认是‘MODEL.pth’,这里需要我们下载一个预训练模型.pth文件,放在文件夹下,这样我们就可以直接使用预训练模型进行预测啦!
下载之后,我们可以看到,在predict.py文件里面,这里‘–model’,默认是‘MODEL.pth’,这里需要我们下载一个预训练模型.pth文件,放在文件夹下,这样我们就可以直接使用预训练模型进行预测啦!
 我们继续下拉界面
我们继续下拉界面
可以看到这里有个Pretrained model 的蓝色字体,点击会跳转
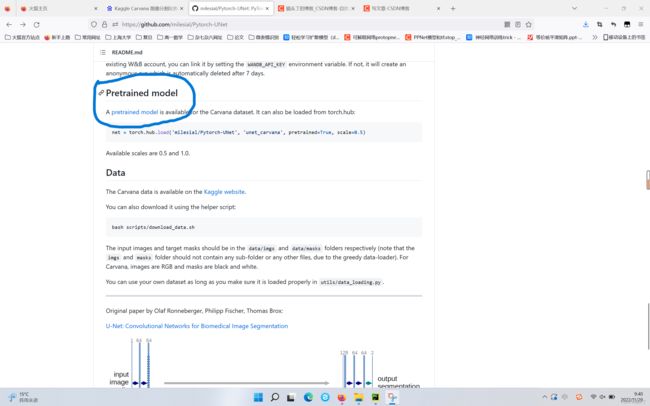
接下来就跳转到预训练模型界面啦,大家可以选择下载!
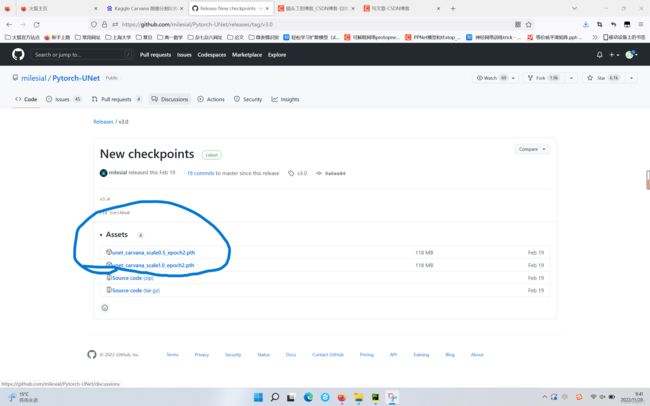 下载到本地后,就给可以更改‘–model’的默认值,
下载到本地后,就给可以更改‘–model’的默认值,
parser.add_argument('--model', '-m', default='unet_carvana_scale0.5_epoch2.pth', metavar='FILE',
help='Specify the file in which the model is stored')
接下来就可以快乐预测啦!
注意
Unet官方有提供预训练模型unet_carvana_scale0.5_epoch2.pth,该模型是在Carvana数据集上进行训练。
2017 年 7 月,美国二手汽车零售平台 Carvana 在知名机器学习竞赛平台 kaggle 上发布了名为 Carvana 图像掩模挑战赛(Carvana Image Masking Challenge)的比赛项目,吸引了许多计算机视觉等相关领域的研究者参与。Carvana 希望为消费者提供全面、透明的购车信息,以提升购买体验。传统的二手车销售平台向消费者提供的车辆展示图片往往是模糊的,缺少标准规范的汽车信息图片往往也不能全面地向消费者展示全面的信息。这严重降低了二手车的销售效率。为了解决这一问题,Carvana 设计了一套用以展示 16 张可旋转的汽车图片的系统。然而,反光以及车身颜色与背景过于相似等问题会引起一系列视觉错误,使得 Carvana 不得不聘请专业的图片编辑来修改汽车图片。这无疑是一件费时费力的工作。因此,Carvana 希望此次比赛的参赛者设计出能够自动将图片中的汽车从背景中抽离的算法,以便日后将汽车融合到新的背景中去。
所以,该模型其实是一个汽车语义分割的2分类模型,大家在测试的时候,一定记得测试的图片是汽车的图片,最好背景也干净一点,这样效果会比价好。
将两张图片水平拼接
因为我想看到一个语义分割结果和原图的对比,所以就增加了一个图像水平拼接函数。
# 定义图像拼接函数
def join_two_image(img_1, img_2, flag='horizontal'): # 默认是水平参数
size1, size2 = img_1.size, img_2.size
if flag == 'horizontal':
joint = Image.new("RGB", (size1[0] + size2[0], size1[1]))
loc1, loc2 = (0, 0), (size1[0], 0)
joint.paste(img_1, loc1)
joint.paste(img_2, loc2)
return joint
测试结果



完整的predict.py代码
import argparse
import logging
import os
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms
from utils.data_loading import BasicDataset
from unet import UNet
from utils.utils import plot_img_and_mask
def predict_img(net,
full_img,
device,
scale_factor=1,
out_threshold=0.5):
net.eval()
img = torch.from_numpy(BasicDataset.preprocess(full_img, scale_factor, is_mask=False))
img = img.unsqueeze(0)
img = img.to(device=device, dtype=torch.float32)
with torch.no_grad():
output = net(img)
if net.n_classes > 1:
probs = F.softmax(output, dim=1)[0]
else:
probs = torch.sigmoid(output)[0]
tf = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((full_img.size[1], full_img.size[0])),
transforms.ToTensor()
])
full_mask = tf(probs.cpu()).squeeze()
if net.n_classes == 1:
return (full_mask > out_threshold).numpy()
else:
return F.one_hot(full_mask.argmax(dim=0), net.n_classes).permute(2, 0, 1).numpy()
def get_args():
parser = argparse.ArgumentParser(description='Predict masks from input images')
parser.add_argument('--model', '-m', default='unet_carvana_scale0.5_epoch2.pth', metavar='FILE',
help='Specify the file in which the model is stored')
parser.add_argument('--input', default='images', metavar='INPUT', help='Filenames of input images')
parser.add_argument('--output', '-o', metavar='OUTPUT', nargs='+', help='Filenames of output images')
parser.add_argument('--viz', '-v', action='store_true',
help='Visualize the images as they are processed')
parser.add_argument('--no-save', '-n', action='store_true', help='Do not save the output masks')
parser.add_argument('--mask-threshold', '-t', type=float, default=0.5,
help='Minimum probability value to consider a mask pixel white')
parser.add_argument('--scale', '-s', type=float, default=0.5,
help='Scale factor for the input images')
parser.add_argument('--bilinear', action='store_true', default=False, help='Use bilinear upsampling')
return parser.parse_args()
def get_output_filenames(args):
def _generate_name(fn):
return f'{os.path.splitext(fn)[0]}_OUT.png'
return args.output or list(map(_generate_name, args.input))
def mask_to_image(mask: np.ndarray):
if mask.ndim == 2:
return Image.fromarray((mask * 255).astype(np.uint8))
elif mask.ndim == 3:
return Image.fromarray((np.argmax(mask, axis=0) * 255 / mask.shape[0]).astype(np.uint8))
# 定义图像拼接函数
def join_two_image(img_1, img_2, flag='horizontal'): # 默认是水平参数
size1, size2 = img_1.size, img_2.size
if flag == 'horizontal':
joint = Image.new("RGB", (size1[0] + size2[0], size1[1]))
loc1, loc2 = (0, 0), (size1[0], 0)
joint.paste(img_1, loc1)
joint.paste(img_2, loc2)
return joint
if __name__ == '__main__':
args = get_args()
in_files = args.input
out_files = get_output_filenames(args)
net = UNet(n_channels=3, n_classes=2, bilinear=args.bilinear)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'Loading model {args.model}')
logging.info(f'Using device {device}')
net.to(device=device)
net.load_state_dict(torch.load(args.model, map_location=device))
logging.info('Model loaded!')
print(in_files)
for filename in os.listdir(in_files):
print(filename)
logging.info(f'\nPredicting image {filename} ...')
img = Image.open(os.path.join(in_files, filename))
mask = predict_img(net=net,
full_img=img,
scale_factor=args.scale,
out_threshold=args.mask_threshold,
device=device)
result = mask_to_image(mask)
result = join_two_image(img, result)
result.save(os.path.join('out', filename))
嘿嘿!完结撒花!!!
