PyTorch深度学习实践(b站刘二大人)P9讲 多分类问题 Softmax Classifier
1.SoftMax分类器
在Mnist数据集中,我们要得到的输出是0-9,共有十类,这种情况下我们希望输出0-9的概率都大于0,且和为1。

使用SoftMax分类器进行多分类问题(其输入不需要Relu激活,而是直接连接线性层),经过SoftMax分类器后满足:1.大于等于0,2.所有类别概率和为1.
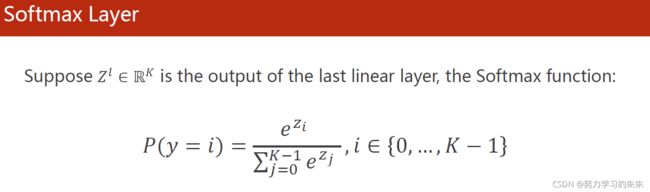

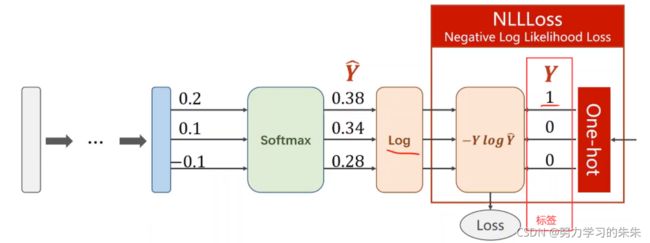
2.Loss function - Cross Entropy 交叉熵
NLLLoss(nagative log likelihood loss ):右边输入 Y是真实标签,另一个输入要求是 softmax之后求对数
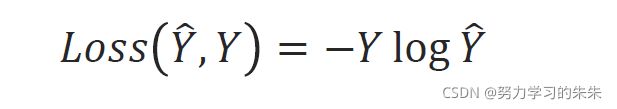
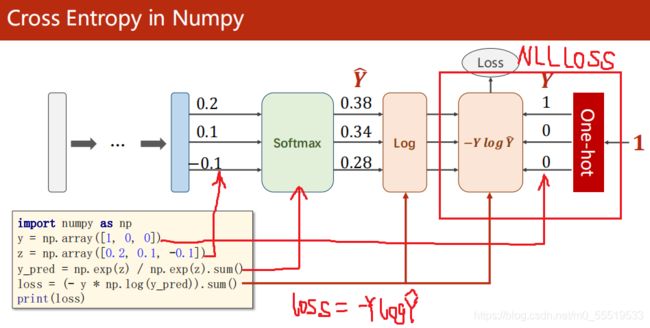
使用Numpy计算交叉熵损失的过程:(One-hot是一行或一列只有一位是1的矩阵)
使用Pytorch计算交叉熵损失:

在PyTorch中,交叉熵损失全部封装成了Torch.nn.CrossEntropyLoss() 上图的交叉熵损失就包含了softmax计算和右边的标签输入计算。
所以在使用交叉熵损失的时候,神经网络的最后一层是不要做激活的,因为激活(就是把它做成分布),是包含在交叉熵损失里面的,最后一层不要做非线性变换,直接交给交叉熵损失。
举例:

3个类别,分别是2,0,1
Y_pred1 ,Y_pred2还是线性输出,没经过softmax,还不是概率分布,比如Y_pred1,0.9最大,表示对应为第3个的概率最大,和2吻合,1.1最大,表示对应为第1个的概率最大,和0吻合,2.1最大,表示对应为第2个的概率最大,和1吻合,那么Y_pred1 的损失会比较小
对于Y_pred2,0.8最大,表示对应为第1个的概率最大,和0不吻合,0.5最大,表示对应为第3个的概率最大,和2不吻合,0.5最大,表示对应为第3个的概率最大,和2不吻合,那么Y_pred2 的损失会比较大
参考代码:
import torch
y = torch.LongTensor([2, 0, 1]) # 注意此处是LongTensor
# z_1和z_2是最后一层输出,进入Softmax之前的值,所以每个分类之和不为1
# 每行元素代表对一个对象的分类情况,共三个对象
z_1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
z_2 = torch.Tensor([[0.9, 0.2, 0.1],
[0.1, 0.1, 0.5],
[0.2, 0.1, 0.7]])
criterion = torch.nn.CrossEntropyLoss()
print(criterion(z_1, y), criterion(z_2, y))运行结果:
![]()

CrossEntropyLoss与NLLLoss的总结
3.应用在MINIST数据集
第零步:首先导入包
transoform是用来对图像处理的 ,functional用的relu激活函数,optium优化器的包

第一步:准备数据集
为什么要用transform?
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, )) ])
PyTorch读图像用的是python的imageLibrary,就是PIL,现在用的都是pillow,pillow读进来的图像用神经网络处理的时候,神经网络有一个特点就是希望输入的数值比较小,最好是在-1到+1之间,最好是输入遵从正态分布,这样的输入对神经网络训练是最有帮助的
transform把Pillow图像转换成Tensor,把0-255像素值转换成0-1,然后把维度28*28变成1*28*28的张量,这个过程用transform中的totensor实现,normalize(mean均值,std标准差)变成0-1分布~给神经网络训练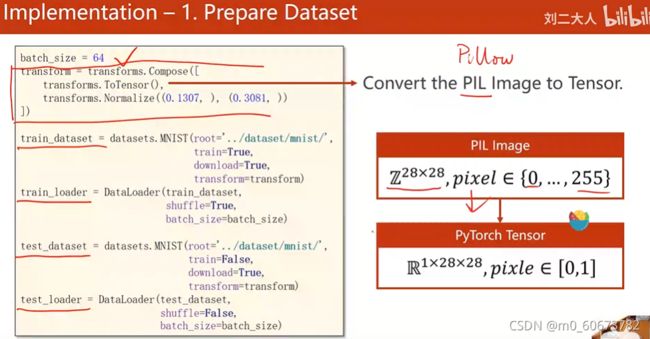

这里的0.1307,0.3081是对Mnist数据集所有的像素求均值方差得到的
也就是说,将来拿到了图像,先变成张量,然后Normalize,切换到0,1分布,然后供神经网络训练 如上图,定义好transform变换之后,直接把它放到数据集里面,为什么要放在数据集里面呢,是为了在读取第i个数据的时候,直接用transform处理
如上图,定义好transform变换之后,直接把它放到数据集里面,为什么要放在数据集里面呢,是为了在读取第i个数据的时候,直接用transform处理
在视觉里面,灰度图就是一个矩阵,但实际上并不是一个矩阵,我们把它叫做单通道图像,彩色图像是RGB三通道图像,通道有宽度和高度,一般我们读进来的图像张量是WHC(宽高通道)
在PyTorch里面我们需要转化成CWH,把通道放在前面是为了在PyTorch里面进行更高效的图像处理,卷积运算
第二步:设计模型
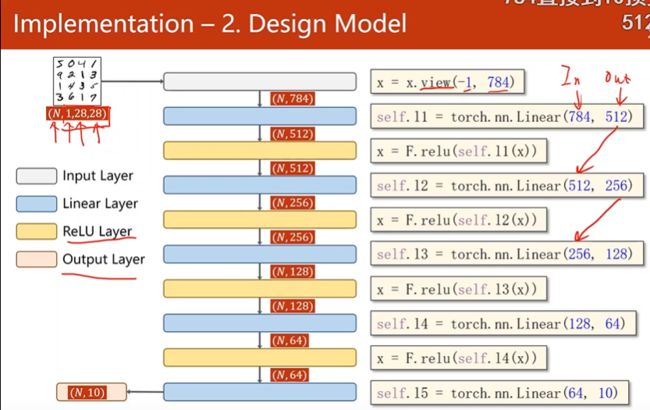
改动:激活层采用ReLu,最后一个输出层并不做激活因为用交叉熵做softmax

输入维度(N,1,28,28):N个样本,每个样本是一维,28*28的图像,为4阶张量(4个参数),但在神经网络中要求输入样本为矩阵,所以第一步把1*28*28的三阶张量变成一阶的向量,怎么变呢?把图片的每一行拼起来构成一行,每一行有784个元素
view(-1,784)把张量变成2阶张量(2个参数),矩阵784列,-1表示自动去算batchsize
经过view之后变成了(N,784)的矩阵
torch.view()详解
然后经过第一个线性层变成512,然后做relu
然后512降成256,然后relu激活~数字一样就可以对接起来~
最后降成10,表示0-9对应的线性值,再用softmax把它变成概率
网络:
需要5层将784-10层
forward 第一步view改变形状,用relu对每一层结果激活,最后一层不激活,直接接softmax
将网络定义成model=Net()

第三步:损失函数和优化器
交叉熵损失,由于样本较大,优化器用带冲量的SGD梯度下降

第四步:训练、测试
train:把训练的一轮循环封装成函数
每训练300轮打印一次running loss

test:
不用计算梯度~with torch.no_grad
步骤:
从test_loader拿数据,做预测,预测出了output,output是一个矩阵,每一个样本有一行,一行有10个量,求每一行里最大值的下标,把每行最大值的下标拿出来,对应他的分类
用max(,dim=1)dim=1表示第一个维度,行,找每一行里最大值的下标
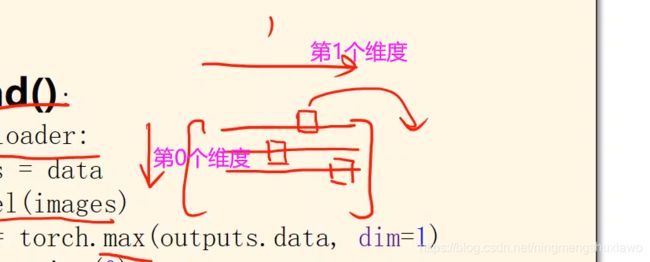 然后torch.max 返回的值有两个,第一个是最大值,第二个是最大值的下标。找完之后total总数先加批量的总数,labels是一个N*1矩阵,size就是元组(N,1),labels.size(0) 就是取N。
然后torch.max 返回的值有两个,第一个是最大值,第二个是最大值的下标。找完之后total总数先加批量的总数,labels是一个N*1矩阵,size就是元组(N,1),labels.size(0) 就是取N。
然后预测与标签做等于比较,真就是1,假就是0,然后求和,把标量拿出来,这就是我们猜对的数量。
等所有数据跑完之后用正确的/总数求accuracy
假设训练10轮:

结果:
损失不断降低。测试的准确率上升!但最后准确率上不去是因为对图像用全连接神经网络忽略了对局部信息的利用,把所有的元素都全连接了,处理时权重不够多,处理图像时更关心高级别的特征~如果特征提取会好一点~人工特征提取方法:傅里叶变换、小波变化,深度学习中可以自动特征提取
完整代码:
import torch
from torchvision import transforms # 图像处理工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F # 使用 ReLU 作为激活函数
import torch.optim as optim # 使用优化器
# prepare dataset
batch_size = 64
# transform中的ToTensor把pillow图像转换成tensor,将单通道的像素值[0, 255]转变成像素张量[0, 1],把维度变28*28变成1*28*28;
# Normalize(均值,标准差)变成0-1分布;
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
#从torchvision.datasets中加载MNIST数据集
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # 改变维数,变为二阶张量(矩阵);-1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换,直接传入softmax
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch): # 每轮循环封装成函数
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data # 数据x, y
optimizer.zero_grad() # 梯度清零(优化器优化之前清零)
outputs = model(inputs) # 前馈
loss = criterion(outputs, target) # 计算损失
loss.backward() # 反馈
optimizer.step() # 优化
running_loss += loss.item() # 累计loss,使用.item()取loss
if batch_idx % 300 == 299: # 每300个样本输出一次
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0 # (训练轮次, 该轮的样本次, 平均损失值)
def test():
correct = 0 # 正确多少
total = 0 # 总数多少
with torch.no_grad(): # 不需要计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
# 沿第一个维度找最大值,返回最大值及其下标,下标用作标签
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0) # 取size元组的第0个元素(N,1)N
correct += (predicted == labels).sum().item() # 张量之间的比较运算,预测对的数量
print('accuracy on test set: %d %% ' % (100 * correct / total)) # 正确数 correct ÷ 总数 total = 准确率 accuracy
if __name__ == '__main__':
for epoch in range(10): # 循环训练10个Epoch
train(epoch)
test()
运行结果:


参考链接