人体捕捉:《SMPL-X》
《Expressive Body Capture: 3D Hands, Face, and Body from a Single Image》
作者:Georgios Pavlakos
主页:https://smpl-x.is.tue.mpg.de/
时间:2019.04
文章目录
- 0 Abstract
- 1 Introduction
- 2 Related work
-
- 2.1 Modeling the body
- 2.2 Inferring the body
- 3 Technical approach
-
- 3.1 Unified model: SMPL-X
-
- 3.1.1 Defined Function
- 3.1.2 Parameters
- 3.2 SMPLify-X: SMPL-X from a single image
- 3.3 Variational Human Body Pose Prior
- 3.4 Collision penalizer
- 3.5 Deep Gender Classifier
- 3.6 Optimization
- 4 Experiments
-
- 4.1 Evaluation datasets
- 4.2 Qualitative & Quantitative evaluations
- 5 Conclusion
0 Abstract
为了更为方便的分析人体动作(human actions)、互动(interactions)和情感(emotions),本文提出了一种从单帧RGB图像计算身体姿态(body pose)、手部姿态(hand pose)和面部表情(facial expression)的3d模型–SMPL-X。SMPL-X其实是在SMPL的body基础上无缝扩展了hand和face,并用数千的3d扫描样本来训练完成。
在没有成对的图像和3d模型( paired images and 3D ground truth)情况下,直接从图像中回归出SMPL-X的参数是很困难的,庆幸的是有SMPLify方法可以效仿。SMPLify先预测2d特征,然后优化参数拟合这些特征,但本文相对SMPLify做出了几点改进:
- 本文检测与body相应的face、hand和feet 2d特征并拟合完整的SMPL-X模型
- 本文采用大量的动捕(MoCap)数据训练一个新的姿态先验神经网络(new neural network pose prior),采用的是变分自编码器(variational auto-encoder),这个先验(pose prior)在2D特征到3D pose映射模棱两可时是很重要的
- 本文定义一种又快又准的新的惩罚项(new interpenetration penalty)
- 本文自动检测性别并匹配身体模型((male, female, or neutral))
- 本文Pytorch版本提速8倍
本文使用SMPLify-X方法来拟合SMPL-X,使其适用于约束图像和自然图像,并在一个100张带有伪标签(pseudo ground-truth)数据集上评估3D精度,这是从单帧RGB图像上自动进行人体捕获的重要一步。
1 Introduction
人往往是图像或视频内容的中心,读懂人们姿态、交流线索和互动含义是理解真个场景至关重要的。近年来对body、hand和face的2d 关键点研究取得小有成就,但我们交流往往是3D的;当然最近直接从单图中粗略进行3D姿态估计的研究也小有成就。
但是要理解人的行为,光3D姿态远远不够,需要完整的body、hands和face的3d曲面(full 3D surface)。由于缺乏合适的3D模型和丰富的3D训练数据,目前还没有系统可以做到,如图所示

光有2d信息或3d特征,表情和互动是很呈现的,即缺乏hand和face细节,为了解决这一问题,首先我们需要一个包括body、hands和faces的人体3D模型,其次需要一种方法来从单图中提取这样一个模型。
深度神经网络的发展及大量的数据,促使3D body、3D hand和3D face重建方面的研究广泛,但将3者或其中2者结合在一起的研究是最近几年才开始的,例如:
- 2017 body+hand(MANO)Embodied hands: Modeling and capturing hands and bodies together》
- 2018 body+hand+face(Frank model):《Total capture: A 3D deformation model for tracking faces, hands, and bodies》,该模型是在SMPL的基础上,简单的结合hand蒙皮(hand rig)和FaceWarehouse face模型,这些不同模型缝合在一起,导致不太真实。
本文提出新的SMPL-X(SMPL eXpressive)模型,它结合body的SMPL模型,hand的MANO模型和head的FLAME模型,并注册该模型5586个3D扫描以保证质量。通过数据训练模型,使得模型在body、hand和face之间的自然相关性上没有人工痕迹,如图
虽然最近有一些论文采用深度学习来回归SMPL的参数,但缺乏数据来训练估计3D body结合hand和face的模型,为了解决这一问题,本文参考SMPLify,首先利用OpenPose进行“bottom up”的2d关键点(body、hands、face、feet)检测,然后使用SMPLify方法将SMPL-X模型与这些2D点“top down”匹配,当然本文做了几点改进,见上。
2 Related work
2.1 Modeling the body
Face Model:
- 1999 3DMM:《A morphable model for the synthesis of 3D faces》
- 1978 FACS:《Facial Action Coding System: A Technique for the Measurement of Facial Movement》
- 2017 FLAME:《Learning a model of facial shape and expression from 4D scans》
Body Model:
- 2003 CAESAR dataset:《The space of human body shapes: Reconstruction and parameterization from range scans》
- 2005 SCAPE:《 SCAPE: Shape Completion and Animation of PEople.》
- 2015 SMPL:《SMPL: A Skinned Multi-Person Linear Model》
Hand Model:
- 2017 MANO:《Embodied hands: Modeling and capturing hands and bodies together》
Unified Models:
- 2018 Frank model:《Total capture: A 3D deformation model for tracking faces, hands, and bodies》
- 2017 SMPL+H(MANO):《Embodied hands: Modeling and capturing hands and bodies together》
2.2 Inferring the body
- RGB-D
- SMPL
- SMPLify
- HMR
- NBF
- MonoPerfCap
3 Technical approach
3.1 Unified model: SMPL-X
本文提出的统一模型(Unified model)—SMPL-X—是将face、hands和body联合在一起训练形状参数( shape parameters);SMPL-X应用标准的顶点线性混合蒙皮( vertex-based linear blend skinning)学习矫正混合变形(blend shapes),拥有N=10475个顶点,K=45个关键点,包括脖子、下巴、眼球和手指( neck, jaw, eyeballs and fingers)。
3.1.1 Defined Function
SMPL-X定义为函数:
M ( θ , β , ψ ) : R ∣ θ ∣ × ∣ β ∣ × ∣ ψ ∣ ⟶ R 3 N M(\theta,\beta,\psi):\mathbb{R}^{|\theta|\times|\beta|\times|\psi|}\longrightarrow\mathbb{R}^{3N} M(θ,β,ψ):R∣θ∣×∣β∣×∣ψ∣⟶R3N 其中
- 姿态参数( pose parameters): θ ∈ R 3 ( K + 1 ) \theta\in\mathbb{R}^{3(K+1)} θ∈R3(K+1),K表示关键点个数,多3维全局旋转参数,本文并将 θ \theta θ分解为下巴点参数 θ f \theta_f θf,手指点参数 θ h \theta_h θh,剩余身体点参数 θ b \theta_b θb;
- 统一形状参数(joint shape parameters): β ∈ R ∣ β ∣ \beta\in\mathbb{R}^{|\beta|} β∈R∣β∣
- 表情参数( facial expression parameters): ψ ∈ R ∣ ψ ∣ \psi\in\mathbb{R}^{|\psi|} ψ∈R∣ψ∣
更明确些M函数表示为:
W ( . ) W(.) W(.)是一个标准的线性混合蒙皮函数(A standard linear blend skinning function),下面分别来看看W函数中几个部分的含义:

- 首先 T p T_p Tp部分

-
T ‾ \overline{T} T表示模板网络( template mesh),参见SMPL论文;
-
B S B_S BS表示形状混合变形函数( shape blend shape function)
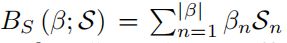
其中
-
β \beta β:线性形状系数( linear shape coefficients)
-
S \mathcal S S:位移矩阵

-
其中各项代表顶点位移的标准正交主成分( orthonormal principle components),捕获不同人的不同形状变化
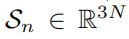
-
B E B_E BE表示表情混合函数( expression blend shape function)
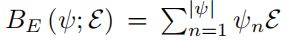
其中
-
E \mathcal E E:是捕获人脸表情变化的重要参数,
-
ψ \psi ψ:PCA系数
-
B P B_P BP表示姿态混合函数(pose blend shape function)

其中
-
θ ∗ \theta^* θ∗:表示初始化姿态( the rest pose)
-
R R R:是姿态向量(pose vector θ \theta θ)向局部相关旋转矩阵的映射函数, 通过 罗德里格公式(Rodrigues formula)计算;
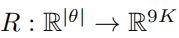
-
P n \mathcal P_n Pn表示顶点位移标准正交分量
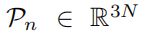
-
P \mathcal P P表示所有姿态混合形状( all pose blend shapes)矩阵

-
其次 J ( β ) J(\beta) J(β)部分
J \bm{J} J是稀疏线性回归器( sparse linear regressor),它从mesh vertices中回归出3D关键点
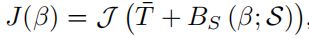
其中
- J \mathcal J J:稀疏线性回归器,从mesh顶点回归出3d关节点
- 再次 θ \theta θ部分
姿态参数向量( pose parameters vector): θ ∈ R 3 ( K + 1 ) \theta\in\mathbb{R}^{3(K+1)} θ∈R3(K+1) - 最后 W W W部分
W \mathcal W W表示混合权重(blend weights)

在通过关键点 J ( β ) J(\beta) J(β)进行顶点旋转 T p ( . ) T_p(.) Tp(.)计算时起平滑作用。
3.1.2 Parameters
SMPL-X首先通过设计3D模板,并匹配FLAME的face模型和MANO的hands模型,在4个不同的3D人体扫描数据集上训练:
- { S } \{\mathcal S\} {S}:形状空间参数(shape space parameters),在3800个A-pose捕捉不同性别的变化的数据集上训练
- { W , P , J } \{\mathcal {W,P,J}\} {W,P,J}:身体姿态空间参数(body pose space parameters),在1786个不同姿态的数据集上训练
- MANO:姿态空间及姿态相关混合形状( pose space and pose corrective blendshapes),1500 hand扫描数据
- FLAME:表情空间 ε \bm{\varepsilon} ε( expression space ),3800 头部高精度扫描数据
手指拥有30个关键点,则关联90维姿态参数(每个点3维轴旋转参数)。 SMPL-X手部姿态参数采用低维PCA:
其中
- M \mathcal M M是捕获手指姿态变化的主成分
- m h m_h mh是相应PCA系数。
- 如上所述,我们使用MANO的PCA姿态空间,它是在一个大的3D关节人手数据集上训练的。
SMPL-X中的模型参数总数为119:75个用于全局身体旋转( global body rotation)和{身体、眼睛、下巴}关节,24个用于低维手部姿态(hand pose)PCA空间,10个用于主体形状(subject shape),10个用于面部表情(facial expressions)。此外还有男性模型、女性模型、中性模型,前两者用于在性别可识别情况下,后者用于性别不可识别情况。
3.2 SMPLify-X: SMPL-X from a single image
从单图拟合SMPL-X,可以看成SMPLify-X,本文相仿SMPLify-X但有改进了几个部分,将拟合问题转换为优化问题,首先看看需要最小化的目标函数:

其中
E J ( β , θ , K , J e s t ) E_J (β, θ, K, J_{est}) EJ(β,θ,K,Jest):2D和3D关键点重投影误差
E θ b ( θ b ) E_{θ_b} (θ_b ) Eθb(θb):身体姿态先验(body pose prior)
E θ f ( θ f ) E_{θ_f} (θ_f ) Eθf(θf):人脸姿态(facial pose)
E m h ( m h ) E_{m_h} (m_h) Emh(mh):手部姿态(hand pose)
E β ( β ) E_β(β) Eβ(β):身体形状(body shape)
E ε ( ψ ) E_{\varepsilon}(ψ) Eε(ψ):人脸表情(facial expressions)
E α ( θ b ) E_α(θ_b) Eα(θb):极端弯曲惩罚项,只针对手肘和膝盖( elbows and knees)
E C ( θ b , h , f , β ) E_C(θ_b,h,f , β) EC(θb,h,f,β):惩罚项
3.3 Variational Human Body Pose Prior
本文寻求一个先验身体姿态,SMPLify采用的是一种负对数的高斯混合模型在MoCap数据上训练逼近,虽然有效,但这种先验不够强。
本文采取变分自编码(VAE)—VPoser来学习人体姿态的隐特征(latent representation),并规范化这种隐编码(latent code)分布为正太分布(normal distribution)。
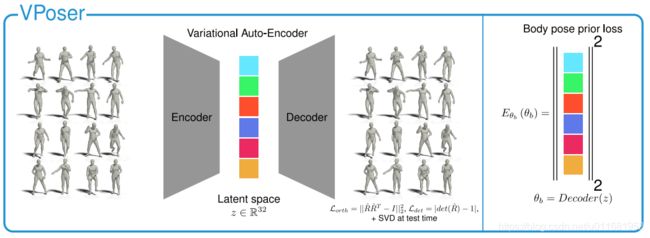
为了训练这个先验,本文在多个数据集( CMU、Human3.6M、PosePrior)上训练恢复身体姿态参数( recover body pose parameters)。VAE训练Loss函数如下:

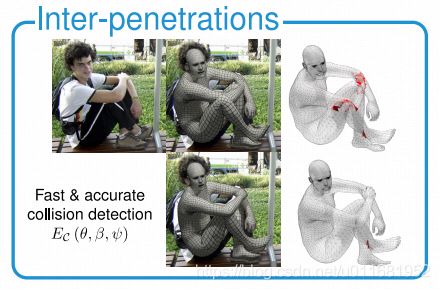
3.4 Collision penalizer
在将模型与观测结果进行拟合时,经常会出现几个身体部位的自碰撞和穿透,这在物理上是不可能的。本文受到SMPLify的启发,它通过基于基本形状的碰撞模型(即胶囊集合)来惩罚穿透。虽然这个模型在计算上是有效的,但它只是对人体的一个粗略的近似。
对于像SMPL-X这样的模型,它更要求模拟手指和面部细节,这就需要一个更精确的碰撞模型( collision model)。因此本文采用来自文献【8,74】的模型(detailed collision-based model meshes),并通过文献【72】中的BVH( Bounding Volume Hierarchies)检测碰撞三角 C \mathcal C C(colliding triangles C \mathcal C C),计算局部二次曲面3维距离场 ψ \bm{\psi} ψ(local conic 3D distance fields),对于两个碰撞三角 f s f_s fs和 f t f_t ft,及 f t f_t ft的顶点 v t v_t vt,定义这膨胀项 E C E_{\mathcal C} EC(the collision term )为:

3.5 Deep Gender Classifier
男人和女人有不同的比例和形状,因此,使用合适的身体模型来拟合2D数据意味着应该应用合适的形状空间。据了解,之前没有任何一种方法能在拟合3D人体姿态时自动考虑性别因素。在这项工作中,本文训练一个性别分类器,它以包含全身和Openpose关节点的图像作为输入,并为分配一个性别标签。
数据来自LSP[33]、LSP扩展[34]、MPII[5]、MS-COCO[45]和LIP datset[44]的大型图像数据集,最后的数据集包括50216个训练示例和16170个测试样本。并使用一个预先训练好的用于二元性别分类的ResNet18进行微调。
此外,通过平衡选择一个0.9的阈值来预测类,产生62.38%的正确预测,以及7.54%的错误预测。在应用时,运行检测器并选择匹配的男/女模型,若当检测到的类概率低于阈值时,选择中性模型。

3.6 Optimization
SMPLify中使用Chumpy和OpenDR,优化速度较慢。本文使用PyTorch和Limited-memory BFGS optimizer (L-BFGS)的强化Wolfe line search。
4 Experiments

4.1 Evaluation datasets
Expressive hands and faces dataset (EHF)
在SMPL+H数据集中获取包含全身的RGB图像,并通过4D扫描对其SMPL-X。根据标注质量及有趣的手势和表情选择100帧可靠的伪标签(pseudo ground-truth)数据作为测试数据集。这伪标签网络(pseudo ground-truth meshes)允许使用比 3D joint error更为严格的vertex-to-vertex (v2v)error进行误差评估。

4.2 Qualitative & Quantitative evaluations
- SMPL vs SMPL+H vs SMPL-X

在EHF数据集上,SMPL-X的v2v误差及Joint误差更小
-
SMPL-X each component

-
SMPL-X vs Frank

相比Frank,SMPL-X模型更加真实,表现力也更加丰富,在关节周围没有蒙皮的痕迹,如手肘。
- SMPL-X vs MANO

在2d检测干扰较小时,第一行,两者表现相当;但在2d检测存在噪声时,SMPL-X具有更好的鲁棒性。
5 Conclusion

SMPL-X在自然场景下的整体表现,强大的包含身体、手和脸的整体模型,表现自然,具有丰富的表达力,如前三列识别为女性,后三列识别为男性,中间两列识别为中性。