HOW POWERFUL ARE GRAPH NEURAL NETWORKS? 论文阅读
HOW POWERFUL ARE GRAPH NEURAL NETWORKS?
Code link: https://github.com/weihua916/powerful-gnns
摘要:GNN对于图形的特征很有效,其可以通过不断汇聚领节点的信息,GNN的变体在节点还是图形分类方面都取得很多的成就,然后即便GNN革命性的特征表达,然后还是存在属性的理解限制,因此提出了能够从不同的GNN框架来分析其表达能力的框架,实验结果能够区别GNN变体等表达能力,比如GCN与GraphSAGE,表面他们不能处理简短的图;我们发明了简单的框架其想过如WEISFEILER-LEHMAN 的图同构测试;我们重点评估了很多图分类掩模,证明了模型的健壮性;
- 引言
GNN不断的进行领节点的信息汇聚并产生新的节点特征向量,在K迭代之后,节点被表示为特征向量,其捕捉了很多结构性的信息(k-hop邻居跳跃点),整个图的表达特征可以通过池化来实现;很多在领节点汇聚与图水平池化方面改进的gnn被大量提出,成果应用于节点分类、连接预测、图形分类等,然而都是依赖于实现反复性、直觉、经验等、很少有理论上的分析gnn的限制性,以及对GNN表达能力的形成;
作者提出理论框架的分析其GNN的表达能力,刻画了区别不同GNN变体对区分的图结构的能力,我们的灵感来自GNN与WEISFEILER-LEHMAN 的图同构测试的紧密连接;
GNN与wl测试同样是拥有强大的内射汇聚能力来映射不同的领节点到不同的特征向量,我们的观点是GNN拥有如同WL测试一样的区别能力并模拟建立内射函数;
为了在数学上形式化上述见解,我们的框架首先将给定节点的邻居的特征向量集表示为多集,即具有可能重复元素的集合。然后,GNN中的邻居聚合可以被认为是多集合上的聚合函数。因此,为了具有强大的表征能力,GNN必须能够将不同的多重集合聚合成不同的表示。我们严格研究多集函数的几种变体,并在理论上表征它们的判别能力,即不同聚合函数如何区分不同的多集合。多集函数越具有判别性,底层GNN的表示能力就越强大
贡献:
(1)、GNN区别图像结构方面如WL 测试几乎相近的能力
(2)、在领节点汇聚与图读取函数上建立条件,在这些函数下,生成的GNN与wl test效果相同
(3)、有些著名的GNN变体(GCN graphSAGE)不能识别的图结构,作者的框架可以识别到
(4)、提出了简单的神经网络框架,图形同构网络(GIN graph isomorphism network)展示了其区分能力/特征表达能力如同wl test相同;
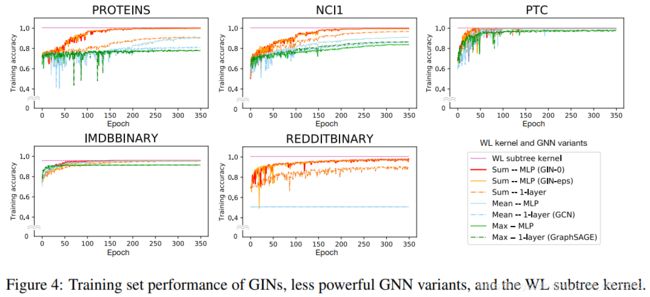
我们通过实验验证了我们的理论在图形分类数据集上,GNN强大的表达能力对于识别图结构起到关节作用,特别的对比了GNN 与 大量汇聚函数的性能; 我们的结果证实, 图形同构网络(GIN),在经验上也具有很高的代表性能力,因为它几乎完全适合训练数据,而功能较弱的GNN变体通常严重不适合训练数据。此外,代表性更强大的GNN通过测试集精度优于其他GNN,并在许多图分类基准上实现最先进的性能
2预备知识
最为常见的模型就是:点分类 与 图分类两种
GNN(graph neural networks):
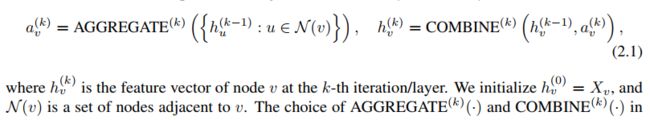
重要是通过 汇聚与传播/连接两个方面做改进:
In the pooling variant of GraphSAGE
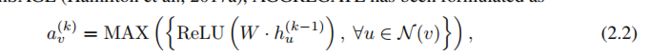
In Graph Convolutional Networks (GCN)
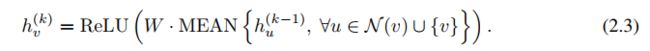
Wl test: 图同构问题是指两个图在拓扑上是否相同。这是一个具有挑战性的问题:目前还没有多项式时间的算法;wl test通过领节点汇聚可以解决这个问题;WL迭代测试(1)聚合节点及其邻近节点的标签,(2)将聚合的标签哈希为唯一的新标签。如果在某些迭代中,两个图之间节点的标签不同,则该算法判定两个图是非同构的
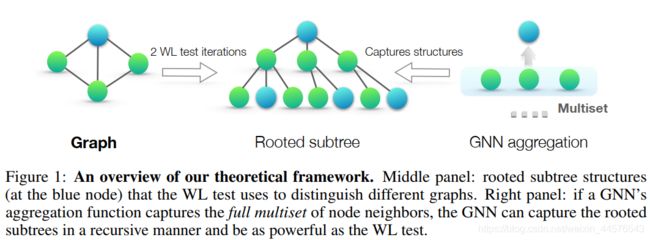
3理论框架:概述
每个特征向量都拥有一个标签,然后每个特征向量有其领节点在不同的集合中,其中存在大量的相同特征向量;
主要思想是:两个节点具有相同的子树结构与对应节点 时才可以映射到嵌入空间的相同位置;这就是GNN的能力
4 建立强大的GNN
- 基于GNN能够与wl test一样区别异构同构图(领节点汇聚与图的输出 函数都是单射的)
- GNN同时可以判定图结构的相似性,然后 wl test 不能
4.1 提出一个图形同构网络
在多重数据集上统一参数化通用函数,(比如均值聚合器,都不是单射多集函数)

把多层感知机引入更新策略中,保证了映射的单一性
4.2 图层面上的gin读出函数
Gin可以直接用于节点分类与连接预测;对于图形的分类提出了为每个节点产生嵌入进而代表图的读出函数;
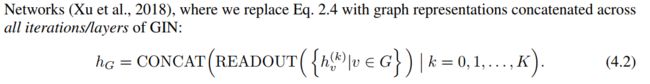
5 有趣的gnn
使用公式4.1 代替 多层感知机
使用sum 代替max mean-pooling,为了更好刻画GNN变体的捕获特征能力
5.1 单层感知机是不充分的
5.2 解构混淆了均值与最大池化
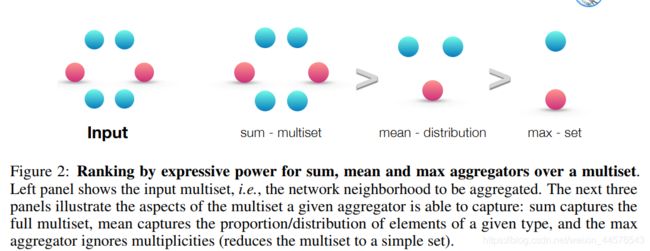
描述了汇聚策略中,表达节点能力的强弱
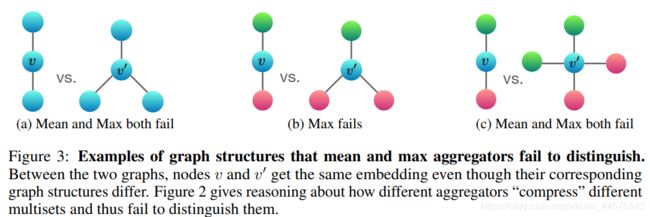
均值与最大值汇聚策略的局限性例子;
A 图颜色相同代表 节点相同,使用mean max 可以表示一样,不能表示解构信息
B图 这两个解构会得到相同的表达 但是不属于相同的结构
C图 同理
5.3 均值学习分布
均值汇聚对于节点分类性能很好,因为均值汇聚包含了统计信息、结构、分布信息,随着不能的迭代其能力区域sum聚类器
5.4 max-pooling学习不同元素的集合
其不能捕获结构与分布信息,但是更适用于特征元素的集合 并非集合结构等;比如说3D点云 对噪声与外点很强的鲁棒性;
5.5 其他的非标准的汇聚策略 比如说注意力机制、lstm池化 等
7 实验部分
Gin与gnn的变体比较 特征表达能力
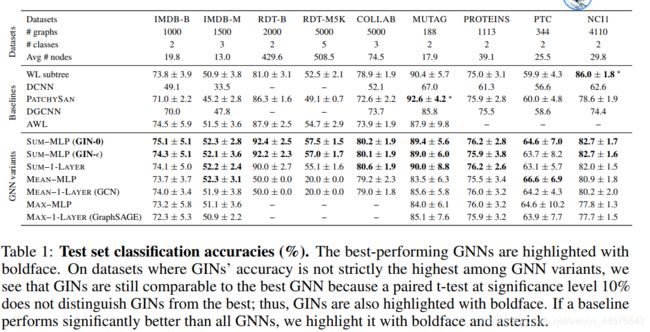
数据集:
9个图分类mask:4 bioinformatics datasets (MUTAG, PTC, NCI1,PROTEINS)
5 social network datasets (COLLAB, IMDB-BINARY, IMDB-MULTI, REDDITBINARY and REDDIT-MULTI5K)
不仅容许模型依赖输入特征信息,并且学习网络结构 ,生物信息数据中有 但是社会信息数据集没有;对于reddit 数据集 设置所有特征向量都相同 因此特征不一样,对于其他社会图,使用one-hot 节点编码
模型参数配置:
数据集:
使用两个类别的数据集 生物/社会 相关的;生物信息拥有节点特征 社会数据集REDDIT没有则设置成相同的;其他社会的 使用one-hot 编码方式,统计特性在表一中体现
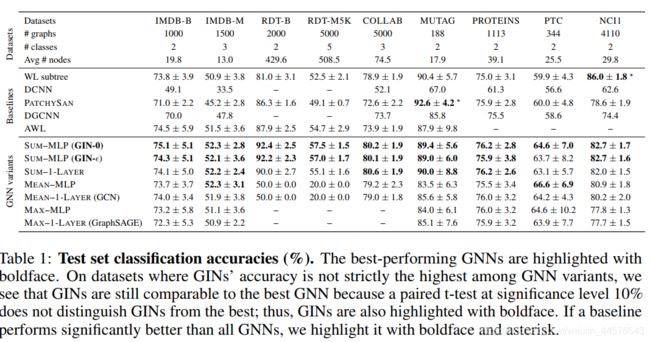
4个生物数据集
(MUTAG PTC NCI1 PROTEINS )
5个社会数据集
(COLLAB IMDB-BINARY IMDB-MULTI REDDIT-BINARY REDDIT-MULTI5K)
REDDIT-BINARY REDDIT-MULTI 此是合作数据集,每个图对应每个演员的自我网络,节点代表演员,在同一部电影出现则绘制一条边;每个图都是从预先指定电影类型中衍生出来的,任务是对其衍生出来的 类型图进行分类;
REDDIT-BINARY REDDIT-MULTI5k是平衡的数据集,其中每个图对应一个在线讨论的线程,节点对应用户;如果两个节点至少一个响应另一个用户的评论,则绘制一条边,任务把每个图分到特定的社区中;
COLLAB 是社会公共数据集,来源于三个 high energy physics ,condensed matter physics Astro physics ,每个图来自不同领域的自我网络,任务分为不同的研究领域;
MUTAG是由188个诱变芳族和异芳族硝基组成的数据集具有7个离散标签的化合物;
proteins是一个数据集,其中节点是二级结构元素(SSEs),如果它们是氨基酸序列或三维空间中的邻居,则两个节点之间存在一条边;3个标签代表螺旋/片/转。
PTC是一个包含344种化合物的数据集,报告了雄性和雌性大鼠的致癌性,它有19个离散标签;
NCI1是美国国家癌症研究所(NCI)公开提供的数据集,它是化合物平衡数据集的子集,这些化合物经过筛选具有抑制或抑制一系列人类肿瘤细胞系生长的能力,有37个离散标签。
模型与参数配置:
公式4.1 4.2
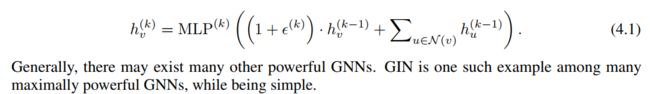

根据4.1 的 来分为 GIN-c GIN-0
GIN-0 性能要更好一些;
10-fold交叉验证,5层的GCN ;MLP 为2 个;每个隐藏层都是用batch 归一化,adam 优化器,学习率为0.01 每个50个epoch衰减0.5;
超参数设置如下:
隐藏层节点单元{16,32} 对应生物 64 社会,batch size 在32-128,dropout {0 0.5}
对于MUTAG,验证集只包含18个数据点。我们还报告了不同GNN的训练精度,其中所有的超参数都是固定的跨数据集:5个GNN层(包括输入层),大小为64的隐藏单元,大小为128的小批量,以及0.5的dropout比率。为了进行比较,我们报告了WL子树内核的训练精度,我们将迭代次数设置为4次,这与5个GNN层相当
7 结果与结论
在本文中,我们理论表达gnn的特征表达能力,进行比较了的表征能力GNN变体。我们也设计了一个强大GNN聚合框架下的gin图形同构网络。一个有趣的未来工作方向是超越社区聚合(或消息传递)为了追求甚至更强大的架构与图形学。