项目四推荐系统源码(十二万字)
目录
背景指路
0 pom.xml
大概的项目框架
1.0 资源
1.1 sparkml2pmml.properties
1.2 core-site.xml
1.3 hdfs-site.xml
1.4 hive-site.xml
1.5 yarn-site.xml
2 scala部分的架构
2.1 conf
2.2 Action
2.3 Constant
2.4 transformer
2.4.1 com.qf.bigata.transformer.ItemBaseFeatureModelData
2.4.2 com/qf/bigata/transformer/ItemCFModelData.scala
2.4.3 com/qf/bigata/transformer/LRModelData.scala
2.4.4 com/qf/bigata/transformer/ModelData.scala
2.4.5 com/qf/bigata/transformer/UnionFeatureModelData.scala
2.4.6 com/qf/bigata/transformer/UserBaseFeatureModelData.scala
2.4.7 VectorSchema
2.5 udfs
2.5.1 com.qf.bigata.udfs.FeatureUDF
2.5.2 RateUDF
2.6 utils
2.6.1 DateUtils
2.6.2 com.qf.bigata.utils.HBaseUtils
2.6.3 SparkUtils
2.7 解析类就是放在src里面的(运行的main)
2.7.1 AlsCF
2.7.2 com/qf/bigata/AlsModelData.scala
2.7.3 com.qf.bigata.ArticleEmbedding
2.7.4 com.qf.bigata.transformer.ArticleEmbeddingModelData
2.7.5 com.qf.bigata.ItemBaseFeature
2.7.6 ItemCF
2.7.7 LRClass
2.7.8 UnionFeature
2.7.9 com.qf.bigata.UserBaseFeature
2.8 重写机器学习库
2.8.1 StringVector
2.8.2 org.jpmml.sparkml.feature.StringVectorConverter
3 springboot部分框架
架构浏览
3.1 resources
3.1.1 application.yml
3.1.2 lr.pmml
3.2 dao
3.2.1com.qf.bigdata.dao.impl.HBaseDaoImpl
3.2.2com.qf.bigdata.dao.impl.MilvusDaoImpl
3.2.3 com.qf.bigdata.dao.impl.PrestoDaoImpl
3.2.4com.qf.bigdata.dao.DataSourceConfig
3.2.5com.qf.bigdata.dao.HBaseConfig
3.2.6com.qf.bigdata.dao.HBaseDao
3.2.7 com.qf.bigdata.dao.MilvusConfig
3.2.8 com.qf.bigdata.dao.MilvusDao
3.2.9 com.qf.bigdata.dao.PrestoDao
3.3 pojo
3.3.1 com.qf.bigdata.pojo.DauPredictInfo
3.3.2 com.qf.bigdata.pojo.HBaseProperties
3.3.3 com.qf.bigdata.pojo.MilvusProperties
3.3.5 com.qf.bigdata.pojo.RecommendInfo
3.3.6 com.qf.bigdata.pojo.RecommendResult
3.3.7 com.qf.bigdata.pojo.RetentionCurvelInfo
3.3.8 com.qf.bigdata.pojo.Sample
3.3.9 com.qf.bigdata.pojo.UserEmbeddingInfo
3.3.10 com.qf.bigdata.pojo.UserEmbeddingResult
3.4 service
3.4.1com.qf.bigdata.service.impl.RecommendServiceImpl
3.4.2 com.qf.bigdata.service.impl.RetentionServiceImpl
3.4.3 com.qf.bigdata.service.impl.UserEmbeddingServiceImpl
3.4.4com.qf.bigdata.service.RecommendService
3.4.5 com.qf.bigdata.service.RetentionService
3.4.6 com.qf.bigdata.service.UserEmbeddingService
3.5 utils
3.5.1com.qf.bigdata.utils.HBaseUtils
3.5.2 com.qf.bigdata.utils.Leastsq
3.5.3 com.qf.bigdata.utils.MilvusUtils
3.5.5 com.qf.bigdata.utils.TimeUtils
3.6 web
3.6.1 com.qf.bigdata.web.controller.DauController
3.6.2 com.qf.bigdata.web.controller.RecommendController
3.6.3com.qf.bigdata.web.controller.UserEmbeddingController
3.6.4 com.qf.bigdata.Application
3.6.5 com.qf.bigdata.HBaseDao
3.6.6 com.qf.bigdata.TomcatConfig
4 操作
4.2 保存hbase
4.3 als
4.4 Feature
4.5 ArticleEmbedding
4.6 UserBaseFeature
4.7 回归算法
4.8 回归之后的featureEmd
4.9 cf
4.10 用户向量的嵌入
4.11 最后一个springboot的验证
5 在项目我遇到的bug们
其实这个项目字数太多了,博客都以及上升到十三万字数。类的话也有几十个类。
背景指路
项目四:使用SparkSQL开发的简易推荐系统_林柚晞的博客-CSDN博客_spark推荐系统开发案例
我摊牌了我只想躺平去多刷题了。现在我就把之前的做推荐系统的代码发一下以供参考
这里搞了两个召回策略,我不太熟悉ALS.。
0 pom.xml
4.0.0 com.qf.bigdata recommend-test 1.0-SNAPSHOT 2.11.12 2.3.9 2.10.1 3.2.0 2.6 2.4.5 compile 1.2.3 1.3.6 2.8.1 com.alibaba fastjson ${json.version} org.apache.spark spark-core_2.11 ${spark.version} ${scope.type} org.apache.spark spark-sql_2.11 ${spark.version} ${scope.type} org.apache.spark spark-hive_2.11 ${spark.version} ${scope.type} org.apache.spark spark-mllib_2.11 ${spark.version} ${scope.type} mysql mysql-connector-java 5.1.28 log4j log4j 1.2.17 ${scope.type} commons-codec commons-codec 1.6 org.scala-lang scala-library ${scala.version} ${scope.type} org.scala-lang scala-reflect ${scala.version} ${scope.type} com.github.scopt scopt_2.11 4.0.0-RC2 org.apache.spark spark-avro_2.11 ${spark.version} org.apache.hive hive-jdbc 2.3.7 ${scope.type} javax.mail org.eclipse.jetty.aggregate * org.apache.hadoop hadoop-client ${hadoop.version} ${scope.type} org.apache.hbase hbase-server ${hbase.version} ${scope.type} org.apache.hbase hbase-client ${hbase.version} ${scope.type} org.apache.hbase hbase-hadoop2-compat ${hbase.version} ${scope.type} org.jpmml jpmml-sparkml 1.5.9 alimaven http://maven.aliyun.com/nexus/content/groups/public/ never never src/main/scala src/test/ org.apache.maven.plugins maven-shade-plugin 3.2.4 package shade true jar-with-dependencies org.jpmml:jpmml-sparkml META-INF/sparkml2pmml.properties *:* META-INF/*.SF META-INF/*.DSA META-INF/*.RSA net.alchim31.maven scala-maven-plugin ${scala-maven-plugin.version} scala-compile-first process-resources add-source compile compile testCompile -dependencyfile ${project.build.directory}/.scala_dependencies org.apache.maven.plugins maven-archetype-plugin 2.2 org.codehaus.mojo build-helper-maven-plugin 1.8 add-source generate-sources add-source src/main/java add-test-source generate-test-sources add-test-source src/test/java
大概的项目框架

架构长这样
1.0 资源

1.1 sparkml2pmml.properties
# Features org.apache.spark.ml.feature.Binarizer = org.jpmml.sparkml.feature.BinarizerConverter org.apache.spark.ml.feature.Bucketizer = org.jpmml.sparkml.feature.BucketizerConverter org.apache.spark.ml.feature.ChiSqSelectorModel = org.jpmml.sparkml.feature.ChiSqSelectorModelConverter org.apache.spark.ml.feature.ColumnPruner = org.jpmml.sparkml.feature.ColumnPrunerConverter org.apache.spark.ml.feature.CountVectorizerModel = org.jpmml.sparkml.feature.CountVectorizerModelConverter org.apache.spark.ml.feature.IDFModel = org.jpmml.sparkml.feature.IDFModelConverter org.apache.spark.ml.feature.ImputerModel = org.jpmml.sparkml.feature.ImputerModelConverter org.apache.spark.ml.feature.IndexToString = org.jpmml.sparkml.feature.IndexToStringConverter org.apache.spark.ml.feature.Interaction = org.jpmml.sparkml.feature.InteractionConverter org.apache.spark.ml.feature.MaxAbsScalerModel = org.jpmml.sparkml.feature.MaxAbsScalerModelConverter org.apache.spark.ml.feature.MinMaxScalerModel = org.jpmml.sparkml.feature.MinMaxScalerModelConverter org.apache.spark.ml.feature.NGram = org.jpmml.sparkml.feature.NGramConverter org.apache.spark.ml.feature.OneHotEncoderModel = org.jpmml.sparkml.feature.OneHotEncoderModelConverter org.apache.spark.ml.feature.PCAModel = org.jpmml.sparkml.feature.PCAModelConverter org.apache.spark.ml.feature.RegexTokenizer = org.jpmml.sparkml.feature.RegexTokenizerConverter org.apache.spark.ml.feature.RFormulaModel = org.jpmml.sparkml.feature.RFormulaModelConverter org.apache.spark.ml.feature.SQLTransformer = org.jpmml.sparkml.feature.SQLTransformerConverter org.apache.spark.ml.feature.StandardScalerModel = org.jpmml.sparkml.feature.StandardScalerModelConverter org.apache.spark.ml.feature.StringIndexerModel = org.jpmml.sparkml.feature.StringIndexerModelConverter org.apache.spark.ml.feature.StopWordsRemover = org.jpmml.sparkml.feature.StopWordsRemoverConverter org.apache.spark.ml.feature.Tokenizer = org.jpmml.sparkml.feature.TokenizerConverter org.apache.spark.ml.feature.VectorAssembler = org.jpmml.sparkml.feature.VectorAssemblerConverter org.apache.spark.ml.feature.VectorAttributeRewriter = org.jpmml.sparkml.feature.VectorAttributeRewriterConverter org.apache.spark.ml.feature.VectorIndexerModel = org.jpmml.sparkml.feature.VectorIndexerModelConverter org.apache.spark.ml.feature.VectorSizeHint = org.jpmml.sparkml.feature.VectorSizeHintConverter org.apache.spark.ml.feature.VectorSlicer = org.jpmml.sparkml.feature.VectorSlicerConverter org.apache.spark.ml.feature.StringVector = org.jpmml.sparkml.feature.StringVectorConverter # Prediction models org.apache.spark.ml.classification.DecisionTreeClassificationModel = org.jpmml.sparkml.model.DecisionTreeClassificationModelConverter org.apache.spark.ml.classification.GBTClassificationModel = org.jpmml.sparkml.model.GBTClassificationModelConverter org.apache.spark.ml.classification.LinearSVCModel = org.jpmml.sparkml.model.LinearSVCModelConverter org.apache.spark.ml.classification.LogisticRegressionModel = org.jpmml.sparkml.model.LogisticRegressionModelConverter org.apache.spark.ml.classification.MultilayerPerceptronClassificationModel = org.jpmml.sparkml.model.MultilayerPerceptronClassificationModelConverter org.apache.spark.ml.classification.NaiveBayesModel = org.jpmml.sparkml.model.NaiveBayesModelConverter org.apache.spark.ml.classification.RandomForestClassificationModel = org.jpmml.sparkml.model.RandomForestClassificationModelConverter org.apache.spark.ml.clustering.KMeansModel = org.jpmml.sparkml.model.KMeansModelConverter org.apache.spark.ml.regression.DecisionTreeRegressionModel = org.jpmml.sparkml.model.DecisionTreeRegressionModelConverter org.apache.spark.ml.regression.GBTRegressionModel = org.jpmml.sparkml.model.GBTRegressionModelConverter org.apache.spark.ml.regression.GeneralizedLinearRegressionModel = org.jpmml.sparkml.model.GeneralizedLinearRegressionModelConverter org.apache.spark.ml.regression.LinearRegressionModel = org.jpmml.sparkml.model.LinearRegressionModelConverter org.apache.spark.ml.regression.RandomForestRegressionModel = org.jpmml.sparkml.model.RandomForestRegressionModelConverter
1.2 core-site.xml
fs.defaultFS hdfs://qianfeng01:8020 hadoop.tmp.dir /usr/local/hadoop/tmp hadoop.proxyuser.root.hosts * hadoop.proxyuser.root.groups *
1.3 hdfs-site.xml
dfs.namenode.name.dir file:///usr/local/hadoop/hdpdata/dfs/name dfs.datanode.data.dir file:///usr/local/hadoop/hdpdata/dfs/data dfs.replication 1 dfs.blocksize 134217728 dfs.namenode.secondary.http-address qianfeng01:50090 dfs.namenode.http-address qianfeng01:50070 dfs.namenode.name.dir file:///usr/local/hadoop/hdpdata/dfs/name dfs.namenode.checkpoint.dir file:///usr/local/hadoop/hdpdata/dfs/cname dfs.namenode.checkpoint.edits.dir file:///usr/local/hadoop/hdpdata/dfs/cname
1.4 hive-site.xml
javax.jdo.option.ConnectionUserName root javax.jdo.option.ConnectionPassword @Mmforu45 javax.jdo.option.ConnectionURL jdbc:mysql://qianfeng01:3306/hive?createDatabaseIfNotExist=true javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver hive.exec.scratchdir /tmp/hive hive.metastore.warehouse.dir /user/hive/warehouse hive.querylog.location /usr/local/hive/iotmp/root hive.downloaded.resources.dir /usr/local/hive/iotmp/${hive.session.id}_resources hive.server2.thrift.port 10000 hive.server2.thrift.bind.host 192.168.10.101 hive.server2.logging.operation.log.location /usr/local/hive/iotmp/root/operation_logs hive.metastore.uris thrift://192.168.10.101:9083 hive.cli.print.current.db true hive.exec.mode.local.auto true
1.5 yarn-site.xml
yarn.resourcemanager.hostname qianfeng01 yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.vmem-check-enabled false yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler yarn.scheduler.fair.preemption true yarn.scheduler.fair.preemption.cluster-utilization-threshold 1.0
2 scala部分的架构

2.1 conf
package com.qf.bigata.conf
import org.slf4j.LoggerFactory
/**
* 配置类,用于规定调用jar的时候的选项的使用
*/
case class Config(
env:String = "",
hBaseZK:String = "192.168.10.101",
hBasePort:String = "2181",
hFileTmpPath:String = "/tmp/hFile",
tableName:String = "",
irisPath:String = "",
proxyUser:String = "root",
topK:Int = 10
)
object Config {
private val logger = LoggerFactory.getLogger(Config.getClass.getSimpleName)
/**
* 解析参数
* @param obj : 用于判断解析参数类的类型
* @param args : 具体的参数值
*/
def parseConfig(obj: Object, args: Array[String]): Config = {
//1. 获取到程序名称
val programName = obj.getClass.getSimpleName.replace("$", "")
//2. 类似于getopts命令
//2.1 得到解析器
val parser = new scopt.OptionParser[Config](s"ItemCF ${programName}") {
head(programName, "v1.0")
opt[String]('e', "env").required().action((x, config) => config.copy(env = x)).text("dev or prod")
opt[String]('x', "proxyUser").required().action((x, config) => config.copy(proxyUser = x)).text("proxy username")
opt[String]('z', "hBaseZK").optional().action((x, config) => config.copy(hBaseZK = x)).text("hBaseZK")
opt[String]('p', "hBasePort").optional().action((x, config) => config.copy(hBasePort = x)).text("hBasePort")
opt[String]('f', "hFileTmpPath").optional().action((x, config) => config.copy(hFileTmpPath = x)).text("hFileTmpPath")
opt[String]('t', "tableName").optional().action((x, config) => config.copy(tableName = x)).text("tableName")
opt[Int]('k', "topK").optional().action((x, config) => config.copy(topK = x)).text("topK")
programName match {
case "ItemCF" => logger.info(s"ItemCF is staring ---------------------------->")
case "AlsCF" => logger.info(s"AlsCF is staring ---------------------------->")
case "ItemBaseFeature" => logger.info(s"ItemBaseFeature is staring ---------------------------->")
case "UserBaseFeature" => logger.info(s"UserBaseFeature is staring ---------------------------->")
case "ArticleEmbedding" => logger.info(s"ArticleEmbedding is staring ---------------------------->")
case "LRClass" => logger.info(s"LRClass is staring ---------------------------->")
case "UnionFeature" => logger.info(s"UnionFeature is staring ---------------------------->")
case _ =>
}
}
//2.2 解析
parser.parse(args, Config()) match {
case Some(conf) => conf
case None => {
logger.error(s"cannot parse args")
System.exit(-1)
null
}
}
}
}
2.2 Action
package com.qf.bigata.constant
/**
* 表示文章的五种行为的枚举类
*/
object Action extends Enumeration {
type Action = Value
val CLICK = Value("点击")
val SHARE = Value("分享")
val COMMENT = Value("评论")
val COLLECT = Value("收藏")
val LIKE = Value("点赞")
/**
* 将当前枚举中的所有的枚举常量打印出来
*/
def showAll = this.values.foreach(println)
/**
* 根据枚举常量名称查询枚举的值
*/
def withNameOpt(name:String):Option[Value] = this.values.find(_.toString == name)
}
2.3 Constant
package com.qf.bigata.constant
//常量类:以后公共常量都可以放在此类中
object Constant {
//在定义新闻文章的有效时间,表示文章在前100天内具备最大价值,超过一百天。价值就梯度下滑
//距离这个时间越远,时间价值下降越快
val ARTICLE_AGING_TIME = 100
}
2.4 transformer
2.4.1 com.qf.bigata.transformer.ItemBaseFeatureModelData
package com.qf.bigata.transformer
import org.apache.hadoop.hbase.KeyValue
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
class ItemBaseFeatureModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String){
/**
* 将推荐算法的结果转换RDD
* 行建:article_id
* 列簇:f1
* 列明: itemBaseFeatures
* 值:特征数据的向量的字符串表示形式:[文章字数,图片的数量,类型,距离天数]
*/
def itemBaseFeatureDF2RDD(baseFeatureDF: DataFrame) = {
baseFeatureDF.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
//1. 原始数据
val article_id: String = row.getString(0)
val features: String = row.getString(1)
//2. 集合
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
//3. 存储
val kv = new KeyValue(Bytes.toBytes(article_id), Bytes.toBytes("f1"), Bytes.toBytes("itemBaseFeatures"), Bytes.toBytes(features))
//4. 将kv添加到listBuffer
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
}
object ItemBaseFeatureModelData {
def apply(spark: SparkSession, env: String): ItemBaseFeatureModelData = new ItemBaseFeatureModelData(spark, env)
}
2.4.2 com/qf/bigata/transformer/ItemCFModelData.scala
package com.qf.bigata.transformer
import com.qf.bigata.utils.HBaseUtils
import org.apache.hadoop.hbase.KeyValue
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.slf4j.LoggerFactory
import scala.collection.mutable.ListBuffer
/**
* 基于物品的协同过滤策略的模型数据类
*/
class ItemCFModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String) {
/**
* 将推荐算法结果转换为RDD
* 需要先建立hbase的表
* 行建:uid
* 列簇:f1
* 列名:itemcf
* 值:推荐的分值
*/
def itemcf2RDD(convertDF: DataFrame) = {
convertDF.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
//1. 获取到原始数据值
val uid: String = row.get(0).toString
/*
* [(sim_aid, pre_rate), (sim_aid, pre_rate), ...]
* |
* sim_aid:pre_rate, sim_aid:pre_rate, ...
*/
val items: String = row.getAs[Seq[Row]](1).map(item => {
item.getInt(0).toString + ":" + item.getDouble(1).formatted("%.4f")
}).mkString(",")
//2. 创建集合准备存放这个结果
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
//3. 存放
val kv = new KeyValue(Bytes.toBytes(uid), Bytes.toBytes("f1"), Bytes.toBytes("itemcf"), Bytes.toBytes(items))
//4. 将kv添加到listBuffer
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
/**
* (1, 2, 11) --> (uid, (sim_aid, pre_rate))
* (1, 3, 12)
* ---> (uid, [(sim_aid, pre_rate), (sim_aid, pre_rate)])
* e.g.
* (1, [(2,11), (3,12), ...])
*/
def recommendDataConvert(recommendDF: DataFrame) = {
import spark.implicits._
recommendDF.rdd.map(row => (row.getInt(0), (row.getInt(1), row.getDouble(2))))
.groupByKey().mapValues(sp => {
var seq: Seq[(Int, Double)] = Seq[(Int, Double)]()
sp.foreach(tp => {
seq :+= (tp._1, tp._2)
})
seq.sortBy(_._2)
}).toDF("uid", "recommendactions")
}
private val logger = LoggerFactory.getLogger(ItemCFModelData.getClass.getSimpleName)
/**
* 通过测试数据预测结果
*/
def predictTestData(joinDF: DataFrame, test: Dataset[Row]) = {
//1. 建立虚表
joinDF.createOrReplaceTempView("rate_sim")
test.createOrReplaceTempView("test_data")
//2. 执行sql
/*
* rsp:用户对于与原文中相似的文章的评分
* sim:用户对于原文章的评分
*/
spark.sql(
s"""
|with t1 as( -- 用户对于相似文章的预测评分:预测值
|select uid, sim_aid, sum(rsp) / sum(rate) as pre_rate
|from rate_sim group by uid, sim_aid
|),
|t2 as ( -- 用户对于原文中的评分:真实值
|select uid, aid, rate from test_data
|)
|select t2.*, t1.pre_rate from t2 inner join t1 on t2.aid = t1.sim_aid and t1.uid = t2.uid
|where t1.pre_rate is not null
|""".stripMargin)
}
/**
* 将矩阵转换为一个Dataframe
*/
def simMatrix2DF(simMatrix: CoordinateMatrix) = {
//1. 获取到矩阵内部的数据:RDD
val transformerRDD: RDD[(String, String, Double)] = simMatrix.entries.map {
case MatrixEntry(row: Long, column: Long, sim: Double) => (row.toString, column.toString, sim)
}
//2. rdd-->dataframe
val simDF: DataFrame = spark.createDataFrame(transformerRDD).toDF("aid", "sim_aid", "sim")
//3. 合并结果
simDF.union(simDF.select("aid", "sim_aid", "sim"))
}
/**
* 将评分数据表转化为评分矩阵
*
* uid aid rate uid/aid 1 2 3
* 1 1 0.8 1 0.8 0.1
* 1 2 0.1 2 0.6
* 2 1 0.6 -> 3 0.8
* 3 1 0.8 4 0.25
* 4 3 0.25
*/
def rateDF2Matrix(df: DataFrame) = {
//1. Row --> MatrixEntry
val matrixRDD: RDD[MatrixEntry] = df.rdd.map {
case Row(uid: Long, aid: Long, rate: Double) => MatrixEntry(uid, aid, rate)
}
//2. 返回分布式矩阵
new CoordinateMatrix(matrixRDD)
}
}
object ItemCFModelData {
def apply(spark: SparkSession, env: String): ItemCFModelData = new ItemCFModelData(spark, env)
}
2.4.3 com/qf/bigata/transformer/LRModelData.scala
package com.qf.bigata.transformer
import org.apache.spark.ml.classification.{LogisticRegressionModel, LogisticRegressionTrainingSummary}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 逻辑回归的数据模型
*/
class LRModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String) {
/**
* 打印逻辑回归模型处理之后的结果
* @param lrModel
*/
def printlnSummary(lrModel: LogisticRegressionModel): Unit = {
val summary: LogisticRegressionTrainingSummary = lrModel.summary
//1. 获取到每个迭代目标函数的值
val history: Array[Double] = summary.objectiveHistory
println("history----------->")
history.zipWithIndex.foreach {
case (loss, iter) => println(s"iterator: ${iter}, loss:${loss}")
}
//2. 打印命中率
println(s"accuracy : ${summary.accuracy}")
}
/**
* 获取到原始的训练数据
*/
def getVectorTrainingData(): DataFrame = {
spark.sql(
s"""
|with t1 as ( -- 查询到用户对哪些文章进行了点击
|select uid, aid, label from dwb_news.user_item_training
|),
|t2 as ( -- 将用户的向量关联
|select
|t1.*,
|ubv.features as user_features
|from t1 left join dwb_news.user_base_vector as ubv
|on t1.uid = ubv.uid where ubv.uid is not null and ubv.features <> ''
|),
|t3 as ( -- 将文章的向量关联
|select
|t2.*,
|abv.features as article_features
|from t2 left join dwb_news.article_base_vector as abv
|on t2.aid = abv.article_id where abv.article_id is not null and abv.features <> ''
|),
|t4 as ( -- 将文章的embedding关联
|select
|t3.*,
|ae.article_vector as article_embedding
|from t3 left join dwb_news.article_embedding as ae
|on t3.aid = ae.article_id
|where ae.article_id is not null and ae.article_vector <> ''
|)
|select
|uid,
|aid,
|user_features,
|article_features,
|article_embedding,
|cast(label as int) as label from t4
|""".stripMargin)
}
}
object LRModelData {
def apply(spark: SparkSession, env: String): LRModelData = new LRModelData(spark, env)
}
2.4.4 com/qf/bigata/transformer/ModelData.scala
package com.qf.bigata.transformer
import com.qf.bigata.udfs.RateUDF
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.slf4j.LoggerFactory
/**
* 所有的协同过滤模型的父类,提供通用的工具函数类
*/
class ModelData(spark:SparkSession, env:String) {
private val logger = LoggerFactory.getLogger(ModelData.getClass.getSimpleName)
def loadSourceDataUserBaseInfos(): DataFrame = {
spark.sql(
s"""
|select
|uid,
|gender,
|cast(age as int) as age,
|email_suffix
|from dwb_news.user_base_feature
|""".stripMargin)
}
// 注册udf函数
spark.udf.register("action2rate", RateUDF.action2rate _)
/**
* 加载文字的基本特征数据
* dwb_news.article_base_info
* article_id | article_num | img_num | type_name | pub_gap
* ------------+-------------+---------+-----------+---------
* 24854 | 855 | 5 | 育儿 | 89
* 24858 | 459 | 4 | 育儿 | 89
*/
def loadSourceDataArticleBaseInfo(): DataFrame = {
spark.sql(
s"""
|select
|article_id,
|cast(article_num as int) as article_num,
|cast(img_num as int) as img_num,
|type_name,
|cast(pub_gap as int) as pub_gap
|from dwb_news.article_base_info
|""".stripMargin)
}
/**
* 生成评分表
*/
def generateEachAction() = {
spark.sql(
//1. 读取原始数据并建立了虚表
s"""
|select uid, aid, action, action_date from dwb_news.user_acticle_action
|""".stripMargin).createOrReplaceTempView("source_data")
//2. 计算
spark.sql(
s"""
|select uid, aid, action, action_date,
|action2rate(action, action_date) as rate
|from source_data
|""".stripMargin).createOrReplaceTempView("source_data_rate")
}
/**
* 将原始数据转换为(uid, aid, rate)
* rete:一个用户对一个文章的所有的行为的评分之和
* 原始数据:
* uid | aid | action | action_date
* ------+-------+--------+-------------
* 3713 | 21957 | 点赞 | 20211225
* 3187 | 3976 | 收藏 | 20211225
* 2554 | 14202 | 分享 | 20211225
* 1937 | 18172 | 点击 | 20211225
* 4500 | 23407 | 分享 | 20211225
*
* 处理之后:
* uid | aid | rate
* ------+-------+------
* 3713 | 21957 | 13
* 3187 | 3976 | 14
*/
def getUserRatingData():DataFrame = {
//1. 生成每个评分的评分表
generateEachAction()
//2. 计算评分
spark.sql(
s"""
|select
|cast(uid as bigint) as uid,
|cast(aid as bigint) as aid,
|cast(sum(rate) as double) as rate
|from source_data_rate group by uid, aid order by uid
|""".stripMargin)
}
/**
* 关联训练和相似的dataframe,从而获取到文章的相似度的评分
*/
def joinRateDFAndSimDF(trainning: Dataset[Row], simDF:Dataset[Row]) = {
//1. 创建评分表
trainning.createOrReplaceTempView("user_rate")
simDF.createOrReplaceTempView("sim_item")
//2. 执行sql
spark.sql(
s"""
|select
|t1.uid, t1.aid, t1.rate,
|t2.aid as aid2, t2.sim_aid, t2.sim, t1.rate * t2.sim as rsp
|from user_rate as t1 left join sim_item as t2 on t1.aid = t2.aid
|where t2.sim is not null
|""".stripMargin)
}
/**
* 为用户推荐topk的内容,同时多虑已经有的行为的内容
*/
def recommendAllUser(joinDF: DataFrame, topK: Int) = {
joinDF.createOrReplaceTempView("rate_sim")
spark.sql(
s"""
|with t1 as(-- 用户对于相似文章的预测评分:预测值
|select uid, sim_aid, sum(rsp) / sum(rate) as pre_rate
|from rate_sim group by uid, sim_aid
|),
|t2 as ( -- 剔除一部分已经阅读
|select t1.* from t1
|left join user_rate as ur on t1.uid = ur.uid and t1.sim_aid = ur.aid
|where ur.rate is not null
|),
|t3 as ( -- 排名
|select
|uid, sim_aid, pre_rate,
|row_number() over(partition by uid order by pre_rate desc) as rank
|from t2
|)
|select
|cast(uid as int) as uid,
|cast(sim_aid as int) as sim_aid,
|cast(pre_rate as double) as pre_rate
|from t3 where rank <= ${topK}
|""".stripMargin)
}
}
object ModelData {
def apply(spark: SparkSession, env: String): ModelData = new ModelData(spark, env)
}
2.4.5 com/qf/bigata/transformer/UnionFeatureModelData.scala
package com.qf.bigata.transformer
import org.apache.hadoop.hbase.KeyValue
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import scala.collection.mutable.ListBuffer
class UnionFeatureModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String) {
import spark.implicits._
def getALSFeature() = {
spark.sql(
s"""
|with t1 as (
|select * from dwb_news.als
|),
|t2 as (
|select
|t1.*,
|abv.features
|from dwb_news.article_base_vector as abv inner join t1
|on t1.pre_aid = cast(abv.article_id as int)
|),
|t3 as (
|select
|t2.*,
|ae.article_vector
|from dwb_news.article_embedding as ae inner join t2
|on t2.pre_aid = cast(ae.article_id as int)
|)
|select * from t3
|""".stripMargin)
}
def featuresDF2HFile(itemCFConvert: DataFrame, column: String) = {
itemCFConvert.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
val uid = row.getInt(0).toString
val items = row.getAs[Seq[Row]](1).map(item => item.getInt(0).toString + ":" + item.getDouble(1).formatted("%.4f") + ":"
+ item.getString(2) + ":" + item.getString(3)).mkString(";")
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
val kv = new KeyValue(Bytes.toBytes(uid), Bytes.toBytes("f1"), Bytes.toBytes(column), Bytes.toBytes(items))
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
def featureDataConvert(itemCFFeatureDF: DataFrame) = {
itemCFFeatureDF.rdd.map(row => (row.getInt(0), (row.getInt(1), row.getDouble(2), row.getString(3), row.getString(4))))
.groupByKey().mapValues(sr => {
var seq = Seq[(Int, Double, String, String)]()
sr.foreach(x => {
seq :+= (x._1, x._2, x._3, x._4)
})
seq.sortBy(-_._2)
}).toDF("uid", "recommendations")
}
/**
* 结果和文章向量关联
*/
def getItemFeature() = {
spark.sql(
s"""
|with t1 as (
|select * from dwb_news.itemcf
|),
|t2 as (
|select
|t1.*,
|abv.features
|from dwb_news.article_base_vector as abv inner join t1
|on t1.sim_aid = cast(abv.article_id as int)
|),
|t3 as (
|select
|t2.*,
|ae.article_vector
|from dwb_news.article_embedding as ae inner join t2
|on t2.sim_aid = cast(ae.article_id as int)
|)
|select * from t3
|""".stripMargin)
}
def userFeaturesDF2HFile(userBaseFeatureDF: DataFrame, column: String) = {
userBaseFeatureDF.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
val uid = row.getInt(0).toString
val items = row.getString(1)
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
val kv = new KeyValue(Bytes.toBytes(uid), Bytes.toBytes("f1"), Bytes.toBytes(column), Bytes.toBytes(items))
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
/**
* als和itemcf两个结果的用户和用户稀疏特征向量关联
*/
def getUserFeature(): DataFrame = {
spark.sql(
s"""
|with t1 as (
|select uid from dwb_news.als
|union
|select uid from dwb_news.itemcf
|),
|t2 as (
|select
|t1.*,
|ubv.features
|from t1 inner join dwb_news.user_base_vector as ubv
|on t1.uid = cast(ubv.uid as int)
|)
|select uid, features as user_features from t2
|""".stripMargin)
}
}
object UnionFeatureModelData {
def apply(spark: SparkSession, env: String): UnionFeatureModelData = new UnionFeatureModelData(spark, env)
}
2.4.6 com/qf/bigata/transformer/UserBaseFeatureModelData.scala
package com.qf.bigata.transformer
import org.apache.hadoop.hbase.KeyValue
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
class UserBaseFeatureModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String){
/**
* 行建:uid
* 列簇:f1
* 列明:userBaseFeatures
* 值:用户的基本特征
* @param baseFeatureDF
*/
def userBaseFeatureDF2RDD(baseFeatureDF: DataFrame) = {
baseFeatureDF.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
//1. 原始数据
val uid: String = row.getString(0)
val features: String = row.getString(1)
//2. 集合
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
//3. 存储
val kv = new KeyValue(Bytes.toBytes(uid), Bytes.toBytes("f1"), Bytes.toBytes("userBaseFeatures"), Bytes.toBytes(features))
//4. 将kv添加到listBuffer
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
}
object UserBaseFeatureModelData {
def apply(spark: SparkSession, env: String): UserBaseFeatureModelData = new UserBaseFeatureModelData(spark, env)
}
2.4.7 VectorSchema
package com.qf.bigata.transformer
import com.qf.bigata.udfs.FeatureUDF
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{DoubleType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row}
import scala.collection.mutable.ArrayBuffer
class VectorSchema {
/**
* 根据dataframe的向量字符串,将这些向量的每个值设置为一个字段
* 例如:
* featrues = f0 f1 f2 f3
* [0, 1, 2, 3]
*/
def getVectorSchemaByColumn(mergeDF: DataFrame, arrayCols: Array[String]):org.apache.spark.sql.types.StructType = {
//1. 构建基础数据结果准备存放对应的数据
val featuresSchema = ArrayBuffer[StructField]() // 所有列的元数据
val featuresCol = ArrayBuffer[String]()
/*
* 2. [1,2,3,4,5,6,7,8,9,a,b,c,d]
* -->
* [(1,0), (2,1), (3,2), (4,3),...]
*/
var i = 0
for ((columnName, index) <- arrayCols.zipWithIndex) {
//2.1 获取到向量的数组的整个长度
val outputColumn: String = columnName + index // features0
val arrayRow: Array[Row] = mergeDF.withColumn(outputColumn, FeatureUDF.vecStr2Size(col(columnName)))
.select(outputColumn).head(1)
val size: Int = arrayRow(0).getAs[Int](outputColumn)
//2.2 封装列数据
for (i <- 1 to size) {
val feature = "features" + i
featuresCol.append(feature)
featuresSchema.append(StructField(feature, DoubleType, true))
}
}
StructType(featuresSchema.toList)
}
}
object VectorSchema {
def apply(): VectorSchema = new VectorSchema()
}
2.5 udfs
就是搞presto的udfs的状态
2.5.1 com.qf.bigata.udfs.FeatureUDF
package com.qf.bigata.udfs
import org.apache.commons.lang.StringUtils
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.{Column, Row}
import org.apache.spark.sql.functions.udf
/**
* 为特征数据转换提供的UDF函数
*/
object FeatureUDF {
/**
* 求一个字符串向量表示的向量的长度
*/
val vecStr2Size = udf((vecStr:String) => Vectors.parse(vecStr).asML.size)
/**
* 将多个vector合并为一个
* 例如:
* [1,2] [4,5]
* 合并:[1,2,4,5]
*/
val mergeColumns = udf((row:Row) => {
val res: String = row.toSeq.foldLeft("")((x, y) => StringUtils.strip(x, "[]") + "," + StringUtils.strip(y.toString, "[]"))
"[" + res.substring(1) + "]"
})
/**
* 将vector向量转换为向量的字符串的表示形式
*/
val vector2str = udf((vec:org.apache.spark.ml.linalg.Vector) => vec.toDense.toString())
/**
* 将数组转换为一个向量
*/
val arr2vec = udf((array:Seq[Double]) => Vectors.dense(array.toArray))
}
2.5.2 RateUDF
package com.qf.bigata.udfs
import com.qf.bigata.constant.{Action, Constant}
import com.qf.bigata.utils.DateUtils
/**
* 函数工具类
*/
object RateUDF {
/**
* 归一化函数不
* 无论d是多少,返回的结果都是0~1之间的
*/
private def sigmoid(d: Double):Double = 1 / (1 + Math.exp(1.0 - d))
/**
* 求行为的权重
*/
def getActionWeight(action: String) = {
Action.withNameOpt(action).getOrElse() match {
case Action.CLICK => 0.1f
case Action.LIKE => 0.15f
case Action.COLLECT => 0.2f
case Action.SHARE => 0.25f
case Action.COMMENT => 0.3f
case _ => 0.0f
}
}
/**
* 求时间的权重
* 公式不理解没有关系,只需要知道这是在计算时间给行为带来的影响
* sigmoid: 归一化时间权重, 将值控制0~1
* sigmoid = 1 / (1 + Math.exp(1-x))
* w = sigmoid((AGING_TIME - x - 7) * 0.8)
*
* date:行为产生的时间
*/
def getDateWeight(date: String) = {
try {
//1. 获取(数据价值时间范围-数据行为时间距今的时间)的差
var interval:Int = Constant.ARTICLE_AGING_TIME - DateUtils.diffDay2Now(date)
if (interval < 0) interval = 1 // 表示行为发生的时间已经超过了数据最有价值的时间
val x: Double = interval.toDouble - 7
sigmoid(x * 0.8).toFloat
}catch {
case e:Exception => e.printStackTrace()
0.0f
}
}
/**
* 根据行为和时间求出评分
*/
def action2rate(action:String, date:String) : Float = {
// 行为的权重 * 时间的权重
val rate = getActionWeight(action) * getDateWeight(date)
return rate
}
}
2.6 utils
2.6.1 DateUtils
package com.qf.bigata.utils
import java.text.SimpleDateFormat
import java.util.{Calendar, Date}
/**
* 时间工具类
*/
object DateUtils {
/**
* date日期距今的天数
*/
def diffDay2Now(date: String) = {
//1. 获取当天
val now: Calendar = Calendar.getInstance()
//2. 获取当天的毫秒
val today: Long = now.getTimeInMillis
//3. 获取到事件发生的时间
val current: Long = string2date(date).getTime
//4. 求相差的天数
val between: Long = (today - current) / (1000 * 3600 * 24)
//5. 返回结果
Integer.parseInt(String.valueOf(between))
}
private val date_format = "yyyyMMdd"
/**
* 将字符串的日期转换为date的类型
*/
def string2date(date:String):Date = {
val fmt = new SimpleDateFormat(date_format)
fmt.parse(date)
}
}
2.6.2 com.qf.bigata.utils.HBaseUtils
package com.qf.bigata.utils
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants, KeyValue, TableName}
import org.apache.hadoop.hbase.client.{Admin, Connection, ConnectionFactory, Table}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.{HFileOutputFormat2, LoadIncrementalHFiles}
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.slf4j.LoggerFactory
/**
* 工具类型
*/
class HBaseUtils(spark:SparkSession, hbaseZk:String, hbasePort:String) {
private val logger = LoggerFactory.getLogger(HBaseUtils.getClass.getSimpleName)
/**
* 获取到HBase的配置类
*/
def hbaseConfig():Configuration = {
val configuration: Configuration = HBaseConfiguration.create()
configuration.set(HConstants.ZOOKEEPER_QUORUM, hbaseZk)
configuration.set(HConstants.ZOOKEEPER_CLIENT_PORT, hbasePort)
configuration
}
/**
* 获取到HBase的Connection
*/
def getConnection(config:Configuration):Connection = ConnectionFactory.createConnection(config)
/**
* 校验hdfs指定路径是否存在,如果存在就删除
*/
def deletePath(path:String) = {
val hdfsPath = new Path(path)
val fs: FileSystem = FileSystem.get(new URI(path), new Configuration())
if (fs.exists(hdfsPath)) {
fs.delete(hdfsPath, true)
}
}
/**
* 将hfile的数据写入到hbase
*/
def loadHFile2HBase(hfileRDD:RDD[(ImmutableBytesWritable, KeyValue)], tableName:String, hFileTmpPath:String) = {
//1. 获取到真实路径
val hFilePath = s"${hFileTmpPath}/${String.valueOf(System.currentTimeMillis())}"
//2. 获取到HBase的配置
val configuration: Configuration = hbaseConfig()
//3. 设置保存到hbase的表
configuration.set(TableOutputFormat.OUTPUT_TABLE, tableName)
//4. 获取到连接对象
val connection: Connection = getConnection(configuration)
logger.warn(s"hbase connection create successful!!!")
//5. 获取到admin和table
val admin: Admin = connection.getAdmin
val table: Table = connection.getTable(TableName.valueOf(tableName))
//6. 获取到job
val job: Job = Job.getInstance()
job.setMapOutputKeyClass(classOf[ImmutableBytesWritable])
job.setMapOutputValueClass(classOf[KeyValue])
job.setOutputFormatClass(classOf[HFileOutputFormat2])
//7. 校验hfile路径是否存在,如果存在就删除
deletePath(hFilePath)
//8. 将RDD数据写入到指定的HDFS路径
hfileRDD.coalesce(10)
.saveAsNewAPIHadoopFile(
hFilePath,
classOf[ImmutableBytesWritable],
classOf[KeyValue],
classOf[HFileOutputFormat2],
job.getConfiguration
)
//9. 获取到增量导入数据的对象
val loader = new LoadIncrementalHFiles(configuration)
//10. 增量导入到hbase
loader.doBulkLoad(
new Path(hFilePath),
admin,
table,
connection.getRegionLocator(TableName.valueOf(tableName))
)
logger.info(s"load hFile 2 hBase successful, hFilePath:${hFilePath}")
}
}
object HBaseUtils {
def apply(spark: SparkSession, hbaseZk: String, hbasePort: String): HBaseUtils = new HBaseUtils(spark, hbaseZk, hbasePort)
}
2.6.3 SparkUtils
package com.qf.bigata.utils
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.slf4j.LoggerFactory
/**
* Spark工具类
*/
object SparkUtils {
private val logger = LoggerFactory.getLogger(SparkUtils.getClass.getSimpleName)
/**
* 获取到sparksession对象
*/
def getSparkSession(env: String, appName: String): SparkSession = {
val conf = new SparkConf()
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.sql.hive.metastore.version", "1.2.1")
.set("spark.sql.cbo.enabled", "true")
.set("spark.hadoop.dfs.client.block.write.replica-datanode-on=failure.enable", "true")
.set("spark.hadoop.dfs.client.block.write.replica-datanode-on=failure.policy", "NEVER")
env match {
case "prod" => {
conf.setAppName(appName+"_prod")
SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
}
case "dev" => {
conf.setMaster("local[*]").setAppName(appName+"_dev").set("spark.sql.hive.metastore.jars", "maven")
SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
}
case _ =>{
logger.error("not match env")
System.exit(-1)
null
}
}
}
}
2.7 解析类就是放在src里面的(运行的main)
2.7.1 AlsCF
package com.qf.bigata
import com.qf.bigata.AlsCF.logger
import com.qf.bigata.ItemCF.logger
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.{AlsCFModelData, ItemCFModelData}
import com.qf.bigata.utils.{HBaseUtils, SparkUtils}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.recommendation.{ALS, ALSModel}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession}
import org.slf4j.LoggerFactory
/**
* 基于model的协同过滤:矩阵分解
*/
object AlsCF {
private val logger = LoggerFactory.getLogger(AlsCF.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//1. 准备工作
//1.1 基本准备
Logger.getLogger("org").setLevel(Level.WARN)
val params:Config = Config.parseConfig(AlsCF, args)
System.setProperty("HADOOP_USER_NAME", params.proxyUser)
logger.warn("job is running, please wait for a moment")
val spark:SparkSession = SparkUtils.getSparkSession(params.env, "alscf app")
import spark.implicits._
//1.2 将spark的运算进行checkpoint, 因为als迭代很深,DAG过深,RDD的lineage很长,造成内存溢出。
spark.sparkContext.setCheckpointDir("/checkpoint/als")
//2. 基础数据处理
//2.1 获取到ItemCF的模型对象
val modelData = AlsCFModelData(spark, params.env)
//2.2 将原始数据转换(uid, aid, rate)
val rateDF: DataFrame = modelData.getUserRatingData()
logger.warn("rateDF ---------------------------------------->")
rateDF.show()
//2.3 将得到的总数居分为两部分:1. 测试数据, 2.训练数据
val Array(training, test) = rateDF.randomSplit(Array(0.6, 0.4))
training.cache()
//2.4 ALS训练模型
//2.4.1 als的配置设置
val als = new ALS()
.setMaxIter(6) // 设置交替最小二乘法的迭代次数,次数越大猜测的值就越接近真实,但是资源消耗越大
.setRegParam(0.01) // 防止过渡拟合
.setUserCol("uid") // 用户了列
.setItemCol("aid") // 物品列
.setRatingCol("rate") // 评分列
.setColdStartStrategy("drop") // 表示删除这些用户和物品的数据
.setNonnegative(true) // 设置非负数
.setImplicitPrefs(true) // 开启隐式反馈
.setRank(10) // topk
//2.4.2 训练出的模型
val model: ALSModel = als.fit(training)
training.unpersist()
//2.5 预测出结果
val predictDF: DataFrame = model.transform(test)
logger.warn("predictDF ---------------------------------------->")
predictDF.show()
//2.6 为用户取topk:(id, recommendations)
val recommendDF: DataFrame = model.recommendForAllUsers(params.topK)
logger.warn("recommendDF ---------------------------------------->")
recommendDF.show()
//2.7 过滤掉自己不要的值
val filterDF = modelData.recommendFilterAlsDataForAllUsers(rateDF, recommendDF)
logger.warn("filterDF ---------------------------------------->")
filterDF.show()
//2.8 先在HDFS保存
filterDF.write.mode(SaveMode.Overwrite).format("ORC").saveAsTable("dwb_news.als")
//2.9 再在HBase保存
val hBaseUtils: HBaseUtils = HBaseUtils(spark, params.hBaseZK, params.hBasePort)
logger.warn("hBaseUtils ---------------------------------------->")
val convertDF = modelData.recommendDataConvert(filterDF)
val hfileRDD = modelData.alscf2RDD(convertDF)
hBaseUtils.loadHFile2HBase(hfileRDD, params.tableName, params.hFileTmpPath)
//释放资源
spark.stop()
logger.info("job successful")
}
}
2.7.2 com/qf/bigata/AlsModelData.scala
package com.qf.bigata.transformer
import org.apache.hadoop.hbase.KeyValue
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.functions.explode
import scala.collection.mutable.ListBuffer
/**
* 为als算法模型提供模型数据
*/
class AlsCFModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String) {
/**
* 将推荐算法的结果转换RDD
* 先要新建hbase的表
* 行建:uid
* 列簇:f1
* 列明:als
* 值:推荐的分值
*/
def alscf2RDD(convertDF: DataFrame) = {
convertDF.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
//1. 获取到原始数据值
val uid: String = row.get(0).toString
/*
* [(sim_aid, pre_rate), (sim_aid, pre_rate), ...]
* |
* sim_aid:pre_rate, sim_aid:pre_rate, ...
*/
val alses: String = row.getAs[Seq[Row]](1).map(als => {
als.getInt(0).toString + ":" + als.getDouble(1).formatted("%.4f")
}).mkString(",")
//2. 创建集合准备存放这个结果
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
//3. 存放
val kv = new KeyValue(Bytes.toBytes(uid), Bytes.toBytes("f1"), Bytes.toBytes("alscf"), Bytes.toBytes(alses))
//4. 将kv添加到listBuffer
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
import spark.implicits._
/**
* 过滤als算法推荐的数据中我们不要的数据
*/
def recommendFilterAlsDataForAllUsers(rateDF: DataFrame, recommendDF: DataFrame) = {
//1. recommendations数组转化为多列:(uid, recommendations, pre_aid, pre_rate)
val transDF: DataFrame = recommendDF.withColumn("recommendations", explode($"recommendations"))
.withColumn("pre_aid", $"recommendations.aid")
.withColumn("pre_rate", $"recommendations.rating")
//2. 创建虚表
rateDF.createOrReplaceTempView("user_rating")
transDF.createOrReplaceTempView("als_pred")
//3. 过滤掉已有的行为
spark.sql(
s"""
|select
|cast(t1.uid as int) as uid,
|cast(t1.pre_aid as int) as pre_aid,
|cast(t1.pre_rate as double) as pre_rate
|from als_pred as t1 left join user_rating as t2 on t1.pre_aid = t2.aid and t1.uid = t2.uid
|where t2.rate is not null
|""".stripMargin)
}
/**
* (1, 2, 11) --> (uid, (sim_aid, pre_rate))
* (1, 3, 12)
* ---> (uid, [(sim_aid, pre_rate), (sim_aid, pre_rate)])
* e.g.
* (1, [(2,11), (3,12), ...])
*/
def recommendDataConvert(recommendDF: DataFrame) = {
import spark.implicits._
recommendDF.rdd.map(row => (row.getInt(0), (row.getInt(1), row.getDouble(2))))
.groupByKey().mapValues(sp => {
var seq: Seq[(Int, Double)] = Seq[(Int, Double)]()
sp.foreach(tp => {
seq :+= (tp._1, tp._2)
})
seq.sortBy(_._2)
}).toDF("uid", "recommendactions")
}
}
object AlsCFModelData {
def apply(spark: SparkSession, env: String): AlsCFModelData = new AlsCFModelData(spark, env)
}
2.7.3 com.qf.bigata.ArticleEmbedding
package com.qf.bigata
import com.qf.bigata.ItemCF.logger
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.{ArticleEmbeddingModelData, ItemCFModelData}
import com.qf.bigata.udfs.FeatureUDF
import com.qf.bigata.utils.{HBaseUtils, SparkUtils}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.stat.Summarizer
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.slf4j.LoggerFactory
object ArticleEmbedding {
private val logger = LoggerFactory.getLogger(ArticleEmbedding.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//1. 准备工作
Logger.getLogger("org").setLevel(Level.WARN)
val params: Config = Config.parseConfig(ArticleEmbedding, args)
System.setProperty("HADOOP_USER_NAME", params.proxyUser)
logger.warn("job is running, please wait for a moment")
val spark: SparkSession = SparkUtils.getSparkSession(params.env, "ArticleEmbedding app")
import spark.implicits._
//2. 基础数据处理
//2.1 获取到ItemCF的模型对象
val modelData = ArticleEmbeddingModelData(spark, params.env)
//2.2 将原始的数据转换为(uid, aid, rate)
val articleTermDF:DataFrame = modelData.loadSourceDataArticleTerm()
logger.warn("articleTermDF ---------------------------------------->")
articleTermDF.show()
//2.3 转换数组为向量
val articleEmbedTermsDF: DataFrame = articleTermDF.withColumn("vector", FeatureUDF.arr2vec($"vector"))
.groupBy("article_id").agg(Summarizer.mean($"vector").alias("article_vector"))
//2.4 为了HDFS存放一份,需要将向量转化为字符串
val embedDF: DataFrame = articleEmbedTermsDF.withColumn("article_vector", FeatureUDF.vector2str($"article_vector"))
.select("article_id", "article_vector")
//3. 存放结果到HDFS
embedDF.write.mode(SaveMode.Overwrite).format("ORC").saveAsTable("dwb_news.article_embedding")
//4. 存放到HBase
val hBaseUtils: HBaseUtils = HBaseUtils(spark, params.hBaseZK, params.hBasePort)
logger.warn("hBaseUtils ---------------------------------------->")
val hFileRDD = modelData.articleEmbeddingDF2RDD(embedDF)
hBaseUtils.loadHFile2HBase(hFileRDD, params.tableName, params.hFileTmpPath)
//5. 释放资源
spark.stop()
logger.info("job successful!!!")
}
}
2.7.4 com.qf.bigata.transformer.ArticleEmbeddingModelData
package com.qf.bigata.transformer
import org.apache.hadoop.hbase.KeyValue
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
class ArticleEmbeddingModelData(spark:SparkSession, env:String) extends ModelData(spark:SparkSession, env:String) {
def articleEmbeddingDF2RDD(embedDF: DataFrame) = {
embedDF.rdd.sortBy(x => x.get(0).toString).flatMap(row => {
//1. 原始数据
val article_id: String = row.getString(0)
val article_vector: String = row.getString(1)
//2. 集合
val listBuffer = new ListBuffer[(ImmutableBytesWritable, KeyValue)]
//3. 存储
val kv = new KeyValue(Bytes.toBytes(article_id), Bytes.toBytes("f1"), Bytes.toBytes("article_embedding"), Bytes.toBytes(article_vector))
//4. 将kv添加到listBuffer
listBuffer.append((new ImmutableBytesWritable(), kv))
listBuffer
})
}
/**
* 加载原始表数据
*/
def loadSourceDataArticleTerm(): DataFrame = {
spark.sql(
s"""
|select article_id, topterms, vector from dwb_news.news_article_top_terms_w2v
|where vector is not null
|""".stripMargin)
}
}
object ArticleEmbeddingModelData {
def apply(spark: SparkSession, env: String): ArticleEmbeddingModelData = new ArticleEmbeddingModelData(spark, env)
}
2.7.5 com.qf.bigata.ItemBaseFeature
package com.qf.bigata
import com.qf.bigata.ItemCF.logger
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.{ItemBaseFeatureModelData, ItemCFModelData}
import com.qf.bigata.udfs.FeatureUDF
import com.qf.bigata.utils.{HBaseUtils, SparkUtils}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.feature.{MinMaxScaler, OneHotEncoderEstimator, StringIndexer, VectorAssembler}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.slf4j.LoggerFactory
/**
* 提取文字的基础特征数据
*/
object ItemBaseFeature {
private val logger = LoggerFactory.getLogger(ItemBaseFeature.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//1. 准备工作
Logger.getLogger("org").setLevel(Level.WARN)
val params:Config = Config.parseConfig(ItemBaseFeature, args)
System.setProperty("HADOOP_USER_NAME", params.proxyUser)
logger.warn("job is running, please wait for a moment")
val spark:SparkSession = SparkUtils.getSparkSession(params.env, "ItemBaseFeature app")
import spark.implicits._
//2. 基础数据处理
//2.1 获取到ItemBaseFeature的模型对象
val modelData = ItemBaseFeatureModelData(spark, params.env)
//2.2 将原始的数据转换为(uid, aid, rate)
val itemBaseFeatureDF:DataFrame = modelData.loadSourceDataArticleBaseInfo()
logger.warn("itemBaseFeatureDF ---------------------------------------->")
itemBaseFeatureDF.show()
/*
* 2.3 type_name进行ont-hot-encoder
* spark OneHotEncoderEstimator, 只接受数值类型的列作为ont-hot的输入,
* 所以我们先把type_name进行处理,使用StringIndexer将type_name转换对应的索引
* type_name
* 娱乐
* 体育
* 八卦
* 星座
* 军事
* 政治
* 游戏
*
* StringIndexer处理之后
* type_name_index
* 0
* 1
* 2
* 3
* 4
* 5
* 6
*/
// 2.3.1 获取到字符串的索引器
val indexer = new StringIndexer()
.setInputCol("type_name")
.setOutputCol("type_name_index")
// 2.3.2 对转换之后的列:type_name_index进行独热编码
val encoder = new OneHotEncoderEstimator()
.setInputCols(Array(indexer.getOutputCol))
.setOutputCols(Array("type_name_vec"))
//2.4 其余的数值类型的值进行最大最小归一化处理
/*
*
article_id | article_num | img_num | pub_gap
------------+-------------+---------+-----------+---------
24854 | 855 | 5 | 89
24858 | 459 | 4 | 89
*
* 归一化:
* article_id, numFeatures
* 24854, [855,5,89]
*/
//2.4.1 将数据转换为向量
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("article_num", "img_num", "pub_gap"))
.setOutputCol("numFeatures")
//2.4.2 对各个列的数据使用最大最小归一化函数处理
/*
* numFeatures
* [24854,855,5,89]
*
* 处理之后
* article_id, numFeaturesScalar
* 24854, [0.8, 0.1, 0.25]
*/
val scaler: MinMaxScaler = new MinMaxScaler()
.setInputCol("numFeatures")
.setOutputCol("numFeaturesScalar")
//2.5 合并归一化处理和独热编码处理之后的数据
val total_assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("numFeaturesScalar", "type_name_vec"))
.setOutputCol("features")
//3. 执行
//3.1 创建流程
val pipeline: Pipeline = new Pipeline()
.setStages(Array(indexer, encoder, assembler, scaler, total_assembler))
//3.2 执行:训练
val model: PipelineModel = pipeline.fit(itemBaseFeatureDF)
//3.3 转换dataframe:测试
val featureDF: DataFrame = model.transform(itemBaseFeatureDF)
logger.warn("featureDF ---------------------------------------->")
featureDF.show()
//3.4 只保留文章id和处理后的features
val baseFeatureDF: DataFrame = featureDF.withColumn("features", FeatureUDF.vector2str($"features"))
.select("article_id", "features")
logger.warn("baseFeatureDF ---------------------------------------->")
baseFeatureDF.show()
//3.5 保存HDFS
baseFeatureDF.write.mode(SaveMode.Overwrite).format("ORC").saveAsTable("dwb_news.article_base_vector")
//3.6 保存HBase
val hBaseUtils: HBaseUtils = HBaseUtils(spark, params.hBaseZK, params.hBasePort)
logger.warn("hBaseUtils ---------------------------------------->")
val hFileRDD = modelData.itemBaseFeatureDF2RDD(baseFeatureDF)
hBaseUtils.loadHFile2HBase(hFileRDD, params.tableName, params.hFileTmpPath)
//4. 释放资源
spark.stop()
logger.info("job successful")
}
}
2.7.6 ItemCF
package com.qf.bigata
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.ItemCFModelData
import com.qf.bigata.utils.{HBaseUtils, SparkUtils}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.mllib.linalg.distributed.CoordinateMatrix
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.slf4j.LoggerFactory
/**
* 基于物品的协同过滤
*/
object ItemCF {
private val logger = LoggerFactory.getLogger(ItemCF.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//1. 准备工作
Logger.getLogger("org").setLevel(Level.WARN)
val params:Config = Config.parseConfig(ItemCF, args)
System.setProperty("HADOOP_USER_NAME", params.proxyUser)
logger.warn("job is running, please wait for a moment")
val spark:SparkSession = SparkUtils.getSparkSession(params.env, "itemcf app")
import spark.implicits._
//2. 基础数据处理
//2.1 获取到ItemCF的模型对象
val modelData = ItemCFModelData(spark, params.env)
//2.2 将原始的数据转换为(uid, aid, rate)
val rateDF:DataFrame = modelData.getUserRatingData()
logger.warn("rateDF ---------------------------------------->")
rateDF.show()
//2.3 将得到的数据分为两部分:1. 测试数据; 2. 训练数据
val Array(training, test) = rateDF.randomSplit(Array(0.6, 0.4))
training.cache()
//2.4 将dataframe转换坐标矩阵:源数据的矩阵
val rateMatrix = modelData.rateDF2Matrix(training)
//2.5 求相似矩阵——底层就是利用了求余弦相似度
val simMatrix: CoordinateMatrix = rateMatrix.toRowMatrix().columnSimilarities()
//2.6 相似度矩阵对象转换dataframe
val simDF = modelData.simMatrix2DF(simMatrix)
logger.warn("simDF ---------------------------------------->")
simDF.show()
//2.7 将评分的训练用的df和相似的df关联起来
val joinDF = modelData.joinRateDFAndSimDF(training, simDF)
logger.warn("joinDF ---------------------------------------->")
joinDF.show()
training.unpersist()
joinDF.cache()
//2.8 使用测试数据和之前的散点数据对文章进行预测评分
val predictDF = modelData.predictTestData(joinDF, test)
logger.warn("predictDF ---------------------------------------->")
predictDF.show()
joinDF.unpersist()
//2.9 计算推荐效果好不好
//2.9.1 创建评估器
val evaluator = new RegressionEvaluator()
.setLabelCol("rate") // 真实值
.setPredictionCol("pre_rate") // 预测值
//2.9.2 计算误差
// val rmse: Double = evaluator.setMetricName("rmse").evaluate(predictDF)
// logger.warn(s"itemcf rmse:${rmse}")
//2.10 取用户topk
val recommendDF = modelData.recommendAllUser(joinDF, params.topK)
logger.warn("recommendDF ---------------------------------------->")
recommendDF.show()
//2.11 将结果先在HDFS存放一份,然后再存HBase
recommendDF.write.mode(SaveMode.Overwrite).format("ORC").saveAsTable("dwb_news.itemcf")
//2.12 将数据保存到HBase
//2.12.1 获取到hbase工具类
val hBaseUtils: HBaseUtils = HBaseUtils(spark, params.hBaseZK, params.hBasePort)
logger.warn("hBaseUtils ---------------------------------------->")
//2.12.2 df --> rdd
val convertDF = modelData.recommendDataConvert(recommendDF)
val hfileRDD = modelData.itemcf2RDD(convertDF)
//2.12.3 保存到hbase
hBaseUtils.loadHFile2HBase(hfileRDD, params.tableName, params.hFileTmpPath)
//释放资源
spark.stop()
logger.info("job successful")
}
}
2.7.7 LRClass
package com.qf.bigata
import java.io.FileOutputStream
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.{LRModelData, UserBaseFeatureModelData, VectorSchema}
import com.qf.bigata.udfs.FeatureUDF
import com.qf.bigata.utils.SparkUtils
import javax.xml.transform.stream.StreamResult
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{LogisticRegression, LogisticRegressionModel}
import org.apache.spark.ml.feature.StringVector
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.slf4j.LoggerFactory
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{IntegerType, StructType}
import org.dmg.pmml.PMML
import org.jpmml.model.JAXBUtil
import org.jpmml.sparkml.PMMLBuilder
/**
* 利用逻辑回归算法对各路召回策略的结果进行综合排序
*/
object LRClass {
private val logger = LoggerFactory.getLogger(LRClass.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//1. 准备工作
Logger.getLogger("org").setLevel(Level.WARN)
val params: Config = Config.parseConfig(LRClass, args)
System.setProperty("HADOOP_USER_NAME", params.proxyUser)
logger.warn("job is running, please wait for a moment")
val spark: SparkSession = SparkUtils.getSparkSession(params.env, "LRClass app")
import spark.implicits._
//2. 基础数据处理
//2.1 获取到LRModelData的模型对象
val modelData = LRModelData(spark, params.env)
//2.2 将原始的数据转换为(uid, aid, label, userFeatures, articleFeatures, articleEmbedding)
val sourceDF: DataFrame = modelData.getVectorTrainingData()
logger.warn("sourceDF ---------------------------------------->")
sourceDF.show()
//2.3 将userFeatures, articleFeatures, articleEmbedding合并为一个列
val mergeDF = sourceDF.withColumn("features", FeatureUDF.mergeColumns(struct($"user_features", $"article_features", $"article_embedding")))
logger.warn("mergeDF ---------------------------------------->")
mergeDF.show(false)
//2.4 推荐好的数据存储到PMML:预测模型标记语言:本质其实还是XML
//2.4.1 获取features的schema,为了生产pmml需要的schema
val schema = VectorSchema.apply.getVectorSchemaByColumn(mergeDF, Array("features"))
//2.4.2 获取到schema对应的列名
val columns: Seq[String] = schema.map(line => line.name) // [f1, f2, f3, f4, ...]
//3. 定义逻辑回归模型
//3.1 StringVector, pmml没有这个类型,得自定义
val vector:StringVector = new StringVector("")
.setInputCol(columns.toArray)
.setOutputCol("feature_vec")
//3.2 逻辑回归的模型
val lr:LogisticRegression = new LogisticRegression()
.setFitIntercept(true) // 开启带截距的回归
.setMaxIter(100)
.setRegParam(0)
.setStandardization(true)
.setTol(1E-6)
// .setFeaturesCol("features") // 直接给这个列不行,因为pmml不支持stringvector
.setFeaturesCol("feature_vec")
.setLabelCol("label")
//4. 使用pipeline
val pipeline = new Pipeline()
.setStages(Array(vector, lr))
//5. 执行管道
val pipelineModel: PipelineModel = pipeline.fit(mergeDF)
//5.1 获取到逻辑回归阶段的模型对象
val lrModel: LogisticRegressionModel = pipelineModel.stages(1).asInstanceOf[LogisticRegressionModel]
//5.2 打印逻辑回归评估指标
modelData.printlnSummary(lrModel)
val newSchema: StructType = schema.add("label", IntegerType)
//6. 从pipline模型构建PMML
val pmml: PMML = new PMMLBuilder(newSchema, pipelineModel).build
//7. 保存
var pmmlName = "lr.pmml"
JAXBUtil.marshalPMML(pmml, new StreamResult(new FileOutputStream(pmmlName)))
}
}
2.7.8 UnionFeature
package com.qf.bigata
import com.qf.bigata.ItemCF.logger
import com.qf.bigata.UserBaseFeature.logger
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.UnionFeatureModelData
import com.qf.bigata.utils.{HBaseUtils, SparkUtils}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.slf4j.LoggerFactory
//使用召回算法的用户以及物品存储Hbase
object UnionFeature {
private val logger = LoggerFactory.getLogger(UnionFeature.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//准备工作
Logger.getLogger("org").setLevel(Level.WARN)
val params:Config = Config.parseConfig(UnionFeature,args)
System.setProperty("HADOOP_USER_NAME",params.proxyUser)
logger.warn("job is running,please wait for a moment")
val spark:SparkSession = SparkUtils.getSparkSession(params.env,"UnionFeature app")
import spark.implicits._
val modelData = UnionFeatureModelData(spark,params.env)
//把原始数据转换为(uid,user_features)
val userBaseFeatureDF:DataFrame = modelData.getUserFeature()
logger.warn("userBaseFeatureDF------------->")
userBaseFeatureDF.show(false)
//处理userFeatureHFileRDD,转换存入HBase的HFile的RDD格式
val userFeatureHFileRDD = modelData.userFeaturesDF2HFile(userBaseFeatureDF,"uf")
logger.warn("userFeatureHFileRDD--------------->")
//获取到HBaseUtils
val hBaseUtils:HBaseUtils = HBaseUtils(spark,params.hBaseZK,params.hBasePort)
logger.info("hBaseUtils--------------->")
hBaseUtils.loadHFile2HBase(userFeatureHFileRDD,params.tableName,params.hFileTmpPath)
//3.1ItemCF关联文章特征
val itemCFFeatureDF = modelData.getItemFeature()
itemCFFeatureDF.show(false)
logger.warn("itemCFFeatureDF---------------->")
val itemCFConvert = modelData.featureDataConvert(itemCFFeatureDF)
val itemCFHFileRDD = modelData.featuresDF2HFile(itemCFConvert,"itemcf")
logger.warn("itemCFHFileRDD----------->")
hBaseUtils.loadHFile2HBase(itemCFHFileRDD,params.tableName,params.hFileTmpPath)
//als关联文章特征
val alsFeatureDF = modelData.getALSFeature()
alsFeatureDF.show(false)
logger.warn("alsFeatureDF---------------------->")
val alsConvert = modelData.featureDataConvert(alsFeatureDF)
val alsHFileRDD = modelData.featuresDF2HFile(alsConvert,"als")
logger.warn("alsHFileRDD-------------->")
hBaseUtils.loadHFile2HBase(alsHFileRDD,params.tableName,params.hFileTmpPath)
//释放资源
spark.stop()
logger.info("job success!!!")
}
}
2.7.9 com.qf.bigata.UserBaseFeature
package com.qf.bigata
import com.qf.bigata.conf.Config
import com.qf.bigata.transformer.UserBaseFeatureModelData
import com.qf.bigata.udfs.FeatureUDF
import com.qf.bigata.utils.{HBaseUtils, SparkUtils}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.feature.{Bucketizer, MinMaxScaler, OneHotEncoderEstimator, StringIndexer, VectorAssembler}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.slf4j.LoggerFactory
/**
* 提取用户的基础特征数据
*/
object UserBaseFeature {
private val logger = LoggerFactory.getLogger(UserBaseFeature.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
//1. 准备工作
Logger.getLogger("org").setLevel(Level.WARN)
val params:Config = Config.parseConfig(UserBaseFeature, args)
System.setProperty("HADOOP_USER_NAME", params.proxyUser)
logger.warn("job is running, please wait for a moment")
val spark:SparkSession = SparkUtils.getSparkSession(params.env, "UserBaseFeature app")
import spark.implicits._
//2. 基础数据处理
//2.1 获取到userBaseFeature的模型对象
val modelData = UserBaseFeatureModelData(spark, params.env)
//2.2 将原始的数据转换为(uid, aid, rate)
val userBaseFeatureDF:DataFrame = modelData.loadSourceDataUserBaseInfos()
logger.warn("userBaseFeatureDF ---------------------------------------->")
userBaseFeatureDF.show()
/*
* 2.3 gender和email_suffix进行ont-hot-encoder
* spark OneHotEncoderEstimator, 只接受数值类型的列作为ont-hot的输入,
* 所以我们先把type_name进行处理,使用StringIndexer将type_name转换对应的索引
* type_name
* 娱乐
* 体育
* 八卦
* 星座
* 军事
* 政治
* 游戏
*
* StringIndexer处理之后
* type_name_index
* 0
* 1
* 2
* 3
* 4
* 5
* 6
*/
// 2.3.1 获取到字符串的索引器
val genderIndexer = new StringIndexer()
.setInputCol("gender")
.setOutputCol("gender_index")
val emailIndexer = new StringIndexer()
.setInputCol("email_suffix")
.setOutputCol("email_suffix_index")
// 2.3.2 对转换之后的列:type_name_index进行独热编码
val encoder = new OneHotEncoderEstimator()
.setInputCols(Array(genderIndexer.getOutputCol, emailIndexer.getOutputCol))
.setOutputCols(Array("gender_vec", "email_vec"))
//2.4 其余的数值类型的值进行最大最小归一化处理
/*
*
article_id | article_num | img_num | pub_gap
------------+-------------+---------+-----------+---------
24854 | 855 | 5 | 89
24858 | 459 | 4 | 89
*
* 归一化:
* article_id, numFeatures
* 24854, [855,5,89]
*/
//2.4.0 将年龄分段: 0-15, 15-25, 25-35, 35-50, 50-60, 60+
val splits: Array[Double] = Array(0, 15, 25, 35, 50, 60, Double.PositiveInfinity)
val bucketizer = new Bucketizer()
.setInputCol("age")
.setOutputCol("age_bucket")
.setSplits(splits)
//2.4.1 将数据转换为向量
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("age_bucket"))
.setOutputCol("age_vec")
//2.4.2 对各个列的数据使用最大最小归一化函数处理
/*
* numFeatures
* [24854,855,5,89]
*
* 处理之后
* article_id, numFeaturesScalar
* 24854, [0.8, 0.1, 0.25]
*/
val scaler: MinMaxScaler = new MinMaxScaler()
.setInputCol("age_vec")
.setOutputCol("age_scalar")
//2.5 合并归一化处理和独热编码处理之后的数据
val total_assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("gender_vec", "email_vec", "age_scalar"))
.setOutputCol("features")
//3. 执行
//3.1 创建流程
val pipeline: Pipeline = new Pipeline()
.setStages(Array(genderIndexer, emailIndexer, encoder, bucketizer, assembler, scaler, total_assembler))
//3.2 执行:训练
val model: PipelineModel = pipeline.fit(userBaseFeatureDF)
//3.3 转换dataframe:测试
val featureDF: DataFrame = model.transform(userBaseFeatureDF)
logger.warn("featureDF ---------------------------------------->")
featureDF.show()
//3.4 只保留文章id和处理后的features
val baseFeatureDF: DataFrame = featureDF.withColumn("features", FeatureUDF.vector2str($"features"))
.select("uid", "features")
logger.warn("baseFeatureDF ---------------------------------------->")
baseFeatureDF.show()
//3.5 保存HDFS
baseFeatureDF.write.mode(SaveMode.Overwrite).format("ORC").saveAsTable("dwb_news.user_base_vector")
//3.6 保存HBase
val hBaseUtils: HBaseUtils = HBaseUtils(spark, params.hBaseZK, params.hBasePort)
logger.warn("hBaseUtils ---------------------------------------->")
val hFileRDD = modelData.userBaseFeatureDF2RDD(baseFeatureDF)
hBaseUtils.loadHFile2HBase(hFileRDD, params.tableName, params.hFileTmpPath)
//4. 释放资源
spark.stop()
logger.info("job successful")
}
}
2.8 重写机器学习库
2.8.1 StringVector
package org.apache.spark.ml.feature
import org.apache.spark.annotation.Since
import org.apache.spark.ml.Transformer
import org.apache.spark.ml.linalg.VectorUDT
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.param.shared._
import org.apache.spark.ml.util._
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Dataset}
/**
* 自定义字符串向量
* Transformer, 直接对vector string列进行转换,必须列明features
*/
class StringVector(override val uid:String) extends Transformer with HasInputCols with HasOutputCol {
/**
* 提供StringVector输入列,会将输入列复制给inputCols变量,这个变量我们在Transformer阶段会要使用它进行对dataframe的列进行转换
*/
def setInputCol(value: Array[String]): this.type = set(inputCols, value)
/*
* 提供StringVector的输出列,会将输出列复制给outputcol变量,这个变量我们在Transformer阶段会要使用它进行对dataframe的列进行转换
*/
def setOutputCol(value:String): this.type = set(outputCol, value)
/**
* 进行数据转换的时候自动调用
*/
override def transform(dataset: Dataset[_]): DataFrame = {
//1. 向量字符串转换向量
val string2vector = (x:String) => org.apache.spark.mllib.linalg.Vectors.parse(x).asML
//2. 赋值spark sql functions
val str2vec: UserDefinedFunction = udf(string2vector)
//3. 列值转换
dataset.withColumn($(outputCol), str2vec(col("features")))
}
/**
* 进行数据转换的时候自动的调用
* @param extra
* @return
*/
override def copy(extra: ParamMap): Transformer = defaultCopy(extra)
/**
* 进行元数据转换的时候被自动调用
*/
@Since("1.4.0")
override def transformSchema(schema: StructType): StructType = schema.add(StructField($(outputCol), new VectorUDT(), false))
}
2.8.2 org.jpmml.sparkml.feature.StringVectorConverter
package org.jpmml.sparkml.feature; import org.apache.spark.ml.feature.StringVector; import org.jpmml.converter.Feature; import org.jpmml.sparkml.FeatureConverter; import org.jpmml.sparkml.SparkMLEncoder; import java.util.ArrayList; import java.util.List; public class StringVectorConverter extends FeatureConverter{ public StringVectorConverter(StringVector transformer) { super(transformer); } @Override public List encodeFeatures(SparkMLEncoder encoder) { StringVector transformer = getTransformer(); // spark model --》 pmml List result = new ArrayList (); String[] inputCols = transformer.getInputCols(); for (String inputCol : inputCols) { List features = encoder.getFeatures(inputCol); result.addAll(features); } return result; } }
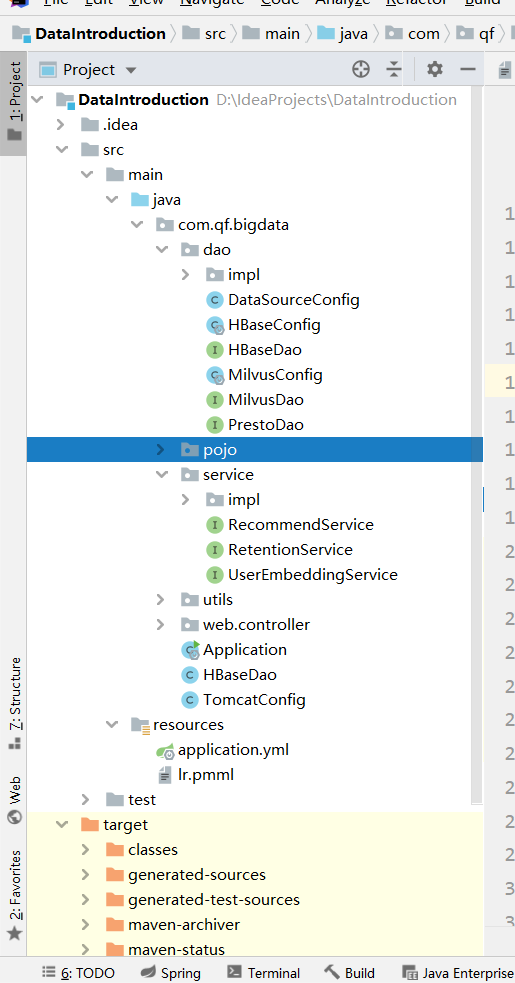
3 springboot部分框架
我突然发现之前项目是把用户画像的框架直接套用了。这里面代码包括了presto的函数(dau预测的时候的代码)以及milvus的保存的代码。(有多余的代码希望大家别介意)
所以这里有三十多个类(其实是用户画像中的milvus的嵌入和推荐系统的milvus的嵌入,UAD预测)
整个第三部分是另开了一个项目,添加了springboot。
pom.xml
4.0.0 com.qf.bigata data-api 1.0 8 8 1.8 1.2.68 org.springframework.boot spring-boot-starter-parent 2.3.1.RELEASE org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-aop org.ujmp ujmp-core 0.3.0 com.facebook.presto presto-jdbc 0.235 org.apache.hbase hbase-shaded-client 1.3.6 io.milvus milvus-sdk-java 0.8.2 org.springframework.boot spring-boot-starter-jdbc com.alibaba fastjson ${fastjson.version} compile ru.yandex.clickhouse clickhouse-jdbc 0.2.4 guava com.google.guava org.jpmml pmml-evaluator 1.5.1 org.jpmml pmml-evaluator-extension 1.5.1 org.springframework.boot spring-boot-starter-actuator io.micrometer micrometer-registry-prometheus org.springframework.boot spring-boot-starter-test test org.junit.vintage junit-vintage-engine com.vaadin.external.google android-json alimaven http://maven.aliyun.com/nexus/content/groups/public/ never never org.springframework.boot spring-boot-maven-plugin
架构浏览
3.1 resources
3.1.1 application.yml
spring:
# application:
# name: data-api
main:
lazy-initialization: false # disable lazy
server:
port: 7088 # 端口
maxThreads: 500 # 最大线程数,值决定了并发处理能力
acceptorThreadCount: 4 # 与CPU核心相等
protocol: org.apache.coyote.http11.Http11Nio2Protocol # 链接协议
datasource:
presto:
name: presto
driver-class-name: com.facebook.presto.jdbc.PrestoDriver
jdbc-url: jdbc:presto://192.168.10.101:8080/hive
username: root
type: com.zaxxer.hikari.HikariDataSource
connection-timeout: 300
pool-name: hikari-pool-1
idle-timeout: 100
milvus:
# milvus的端口号回根据docker映射的端口变化而变化
host: 192.168.10.101
port: 49153
hbase:
quorum: 192.168.10.101
rootDir: hdfs://192.168.10.101:8020/hbase
nodeParent: /hbase
logging:
level:
org.springframework.jdbc.core.JdbcTemplate: DEBUG
3.1.2 lr.pmml
这个我没记错的话,好像是机器训练得出来的数据(不是敲的)
这个代码不用敲,是最后的机器学习之后产生的数据(我那时候就拿出来看而已)
2022-03-28T15:43:40Z
3.2 dao

3.2.1com.qf.bigdata.dao.impl.HBaseDaoImpl
package com.qf.bigdata.dao.impl;
import com.qf.bigdata.dao.HBaseDao;
import com.qf.bigdata.utils.HBaseUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.util.HashMap;
import java.util.Map;
/**
* 查询在HBase中存储的数据
*/
@Repository
public class HBaseDaoImpl implements HBaseDao {
@Autowired
private HBaseUtils hBaseUtils;
private static String FEATURE_TABLE_NAME = "recommend:union-feature";
/**
* 从HBase中读取特征数据,然后转换为每个文章列表以及对应相关的向量
*/
@Override
public Map transItemFeatureList(String uid) {
//1. 将HBase中的数据加载到map中,key为列名,value为列值
Map parseFeatures = parseFeature(uid);
if (null == parseFeatures) return null;
//2. 校验从HBase获取到的数据的结果
String userVector = parseFeatures.get("uf");
String itemcf = parseFeatures.get("itemcf");
String als = parseFeatures.get("als");
if (itemcf == null || als == null || userVector == null) {
System.err.println("user info[uv, als, itemcf] some features is null!!!");
return null;
}
//3. 先获取到各个不同的向量
Map itemFeatureMap = new HashMap<>();
//3.1 als
String[] alsItemArray = als.split(";");
for (String alsItem : alsItemArray) {
String[] alsInfo = alsItem.split(":");
String alsItemId = alsInfo[0];
String alsItemVector = alsInfo[2];
String alsItemEmbedding = alsInfo[3];
String unionFeature = StringUtils.strip(alsItemVector, "[]")
+ StringUtils.strip(alsItemEmbedding, "[]")
+ StringUtils.strip(userVector, "[]");
itemFeatureMap.put(alsItemId, unionFeature);
}
//3.2 itemcf
String[] itemcfArray = itemcf.split(";");
for (String itemCF : itemcfArray) {
String[] itemcfInfo = itemCF.split(":");
String itemCFId = itemcfInfo[0];
String itemCFVector = itemcfInfo[2];
String itemCFEmbedding = itemcfInfo[3];
String unionFeature = StringUtils.strip(itemCFVector, "[]")
+ StringUtils.strip(itemCFEmbedding, "[]")
+ StringUtils.strip(userVector, "[]");
itemFeatureMap.put(itemCFId, unionFeature);
}
return itemFeatureMap;
}
/**
* 读取HBase数据并解析
*/
public Map parseFeature(String uid) {
//1. 创建map用于存放最终结果
Map map = new HashMap<>();
try {
//2. 获取到table对象
Get get = new Get(Bytes.toBytes(uid));
Table table = hBaseUtils.getConnection().getTable(TableName.valueOf(FEATURE_TABLE_NAME));
//3. 查询结果
Result result = table.get(get);
if (result.isEmpty()) { // 说明没有uid这个用户
System.err.println("use not exists : " + uid);
return null;
}else { // 说明查到了数据
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
String qualifier = new String(CellUtil.cloneQualifier(cell));
String value = new String(CellUtil.cloneValue(cell));
if (!"".equals(value)) {
map.put(qualifier, value);
}
}
}
}catch (Exception e) {
e.printStackTrace();
}
return map;
}
}
3.2.2com.qf.bigdata.dao.impl.MilvusDaoImpl
package com.qf.bigdata.dao.impl;
import com.google.gson.JsonObject;
import com.qf.bigdata.dao.MilvusDao;
import com.qf.bigdata.pojo.UserEmbeddingInfo;
import com.qf.bigdata.utils.MilvusUtils;
import io.milvus.client.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
@Repository
public class MilvusDaoImpl implements MilvusDao {
@Autowired
private MilvusUtils milvusUtils;
/**
* 判断milvus是否有这个集合
*/
@Override
public boolean hasCollection(String collectionName) {
//1. 连接到milvus服务器的客户端
MilvusClient milvusClient = milvusUtils.getMilvusClient();
//2. 判断
HasCollectionResponse response = milvusClient.hasCollection(collectionName);
//3. 判断
if (!response.hasCollection()) return false;
return true;
}
/**
* 在milvus中创建指定名称的集合
*/
@Override
public void createCollection(String collectionName, int dimension) {
//1. 判断如果集合在milvus中没有
if (!hasCollection(collectionName)) {
//2. 创建集合的配置对象
CollectionMapping collectionMapping = new CollectionMapping.Builder(collectionName, dimension)
.withIndexFileSize(1024L)
.withMetricType(MetricType.IP)
.build();
//3. 创建集合
Response response = milvusUtils.getMilvusClient().createCollection(collectionMapping);
//4. 判断
if (!response.ok()) {
System.err.println("create milvus collection error:" + response.getMessage());
}
}
}
/**
* 向milvus插入数据
*/
@Override
public boolean loadData(List vectorId, List> vectors, String collectionName) {
//1. 处理距离
vectors = vectors.stream().map(MilvusDaoImpl::normalVector).collect(Collectors.toList());
//2. 插入参数对象
InsertParam insertParam = new InsertParam.Builder(collectionName)
.withVectorIds(vectorId) // 向量维度的编号:uid
.withFloatVectors(vectors) // 向量的距离: 用户的特征的向量表示
.build();
//3. 插入数据
InsertResponse response = milvusUtils.getMilvusClient().insert(insertParam);
//4. 根据判断
if (!response.ok()) {
System.err.println("load data 2 milvus error:" + response.getResponse().getMessage());
return false;
}
return true;
}
/**
* 在milvus的指定的集合中检索维度id是uid的topk个值
*/
@Override
public List searchVectorByVectorId(String collectionName, long uid, long topk) {
//1. 查询数据
//1.1 造数据给milvus提供查询条件
List ids = new ArrayList<>();
ids.add(uid);
//1.2 查询的结果:包含了用户的向量
GetEntityByIDResponse entityResponse = milvusUtils.getMilvusClient().getEntityByID(collectionName, ids);
//1.3 获取其中的向量:uid对应的向量
List> searchVec = entityResponse.getFloatVectors();
//2. 校验
if (searchVec.isEmpty()) {
System.err.println("vectorId : " + uid + " is not exists!!!");
return null;
}
//3. 构建Json对象
JsonObject jsonObject = new JsonObject();
jsonObject.addProperty("nprobe", 20);
//3.1 构建搜索对象
SearchParam searchParam = new SearchParam.Builder(collectionName)
.withFloatVectors(searchVec) // 查询于SearchVec向量相似的向量
.withTopK(topk + 1)
.withParamsInJson(jsonObject.toString())
.build();
//3.2 搜索结果
SearchResponse searchResponse = milvusUtils.getMilvusClient().search(searchParam);
//4. 判断结果
if (searchResponse.ok()) {
//4.1 获取到结果集:获取到第一个对象,因为第一个对象一定是自己。
/*
*queryResultsList : 表示的总的结果
* List : 表示一个uid对应的所有结果
* 因为searchVec可能会包含多个uid
* SearchResponse.QueryResult : 表示一个uid对应的一个结果
*/
List> queryResultsList = searchResponse.getQueryResultsList();
//4.2 获取到第一个对象 : 自己
SearchResponse.QueryResult firstQueryResult = queryResultsList.get(0).get(0);
//4.3 判断:如果不是自己,说明查询有误
if (firstQueryResult.getVectorId() != ids.get(0)) {
System.err.println("select user from milvus error !!!");
return null;
}
}
//5. 查询到的相似用户id
List> resultIdsList = searchResponse.getResultIdsList();
List simIds = resultIdsList.get(0); // 相似结果id
//6. 获取到查询用户的相似距离(相似度)
List> resultDistancesList = searchResponse.getResultDistancesList();
List simDistance = resultDistancesList.get(0); // 相似距离
//7. 准备存放最终结果的List
List ulist = new ArrayList<>();
for (int index = 0; index < simDistance.size(); index++) {
if (simIds.get(index).equals(uid)) continue;
UserEmbeddingInfo userEmbeddingInfo = new UserEmbeddingInfo();
userEmbeddingInfo.setUid(simIds.get(index).toString());
userEmbeddingInfo.setDistance(simDistance.get(index));
ulist.add(userEmbeddingInfo);
}
return ulist;
}
/**
* 使用内积去度量向量之间的距离
*/
static List normalVector(List vector) {
//1. 求一个向量中的所有的元素的平方和
Float squareSum = vector.stream().map(x -> x * x).reduce(0.0f, Float::sum);
//2. 开根号
final float norm = (float) Math.sqrt(squareSum);
//3. 重新
vector = vector.stream().map(x -> x / norm).collect(Collectors.toList());
return vector;
}
}
3.2.3 com.qf.bigdata.dao.impl.PrestoDaoImpl
package com.qf.bigdata.dao.impl;
import com.qf.bigdata.dao.PrestoDao;
import com.qf.bigdata.pojo.Sample;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.support.rowset.SqlRowSet;
import org.springframework.stereotype.Repository;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 操作presto的jdbc的dao
*/
@Repository
public class PrestoDaoImpl implements PrestoDao {
@Autowired
@Qualifier("prestoTemplate") // 使用指定的ioc对象注入到jdbcTemplate
private JdbcTemplate jdbcTemplate;
/**
* 查询指定时间范围的样本数据
* @param start_date
* @param end_date
* @param scale
* @return
*/
@Override
public List selectRetentionRate(String start_date, String end_date, int scale) {
//1. sql
String sql = "select\n" +
"gap,\n" +
"sum(retention_num) * 1.000 / sum(new_num) as rr\n" +
"from dwb_news.rsu\n" +
"where biz_date between ? and ? and gap between 1 and ?\n" +
"group by gap order by gap";
//2. 执行sql
SqlRowSet sqlRowSet = jdbcTemplate.queryForRowSet(sql, start_date, end_date, scale);
//3. 封装结果并返回
List samples = new ArrayList<>();
while (sqlRowSet.next()) {
Sample sample = new Sample();
sample.setX(sqlRowSet.getInt("gap"));
sample.setY(sqlRowSet.getDouble("rr"));
samples.add(sample);
}
return samples;
}
/**
* 根据参数的sql语句,返回对应的数据并数据封装到List中的map集合中
*/
@Override
public List> queryForSql(String sql) {
try {
return jdbcTemplate.queryForList(sql);
}catch (Exception e) {
System.err.println("presto query error : " + e.getMessage());
return null;
}
}
}
3.2.4com.qf.bigdata.dao.DataSourceConfig
package com.qf.bigdata.dao;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
/**
* 在ioc容器中创建prestoDataSource的数据源对象
* @return
*/
@Bean(name = "prestoDataSource")
public DataSource prestoDataSource() {
return new HikariDataSource(hikariConfig()); // 创建一个presto的数据源
}
/**
* 在ioc容器中传创建hikariConfig的对象
* 我想要把presto的jdbc的几大参数设置进这个配置对象中
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.presto")
public HikariConfig hikariConfig() {
return new HikariConfig(); // presto的配置对象
}
@Bean(name = "prestoTemplate")
public JdbcTemplate prestoTemplate(@Qualifier("prestoDataSource") DataSource prestoDataSource) {
return new JdbcTemplate(prestoDataSource);
}
}
3.2.5com.qf.bigdata.dao.HBaseConfig
package com.qf.bigdata.dao;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
/**
* 在ioc容器中创建prestoDataSource的数据源对象
* @return
*/
@Bean(name = "prestoDataSource")
public DataSource prestoDataSource() {
return new HikariDataSource(hikariConfig()); // 创建一个presto的数据源
}
/**
* 在ioc容器中传创建hikariConfig的对象
* 我想要把presto的jdbc的几大参数设置进这个配置对象中
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.presto")
public HikariConfig hikariConfig() {
return new HikariConfig(); // presto的配置对象
}
@Bean(name = "prestoTemplate")
public JdbcTemplate prestoTemplate(@Qualifier("prestoDataSource") DataSource prestoDataSource) {
return new JdbcTemplate(prestoDataSource);
}
}
3.2.6com.qf.bigdata.dao.HBaseDao
package com.qf.bigdata.dao;
import java.util.Map;
public interface HBaseDao {
Map transItemFeatureList(String uid);
}
3.2.7 com.qf.bigdata.dao.MilvusConfig
package com.qf.bigdata.dao;
import com.qf.bigdata.pojo.MilvusProperties;
import com.qf.bigdata.utils.MilvusUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableAutoConfiguration
@EnableConfigurationProperties(MilvusProperties.class)
public class MilvusConfig {
@Autowired
private MilvusProperties milvusProperties;
@Bean
public MilvusUtils milvusUitls() {
return new MilvusUtils(milvusProperties.getHost(), milvusProperties.getPort());
}
}
3.2.8 com.qf.bigdata.dao.MilvusDao
package com.qf.bigdata.dao;
import com.qf.bigdata.pojo.UserEmbeddingInfo;
import java.util.List;
public interface MilvusDao {
boolean hasCollection(String collectionName);
void createCollection(String collectionName, int i);
boolean loadData(List vectorId, List> vectors, String collectionName);
List searchVectorByVectorId(String collectionName, long uid, long topk);
}
3.2.9 com.qf.bigdata.dao.PrestoDao
package com.qf.bigdata.dao;
import com.qf.bigdata.pojo.Sample;
import java.util.List;
import java.util.Map;
public interface PrestoDao {
List selectRetentionRate(String start_date, String end_date, int scale);
List> queryForSql(String sql);
}
3.3 pojo
3.3.1 com.qf.bigdata.pojo.DauPredictInfo
package com.qf.bigdata.pojo;
import java.util.LinkedHashMap;
/**
* Dau预测分析的返回结果的JavaBean
*/
public class DauPredictInfo {
private RetentionCurvelInfo rci; // 拟合曲线参数
private int code; // 结果码, 0表示成功,非0表示失败
private String msg; // 结果信息
private LinkedHashMap preDau = new LinkedHashMap<>(); // 预测的每日的留存人数
public RetentionCurvelInfo getRci() {
return rci;
}
public void setRci(RetentionCurvelInfo rci) {
this.rci = rci;
}
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public LinkedHashMap getPreDau() {
return preDau;
}
public void setPreDau(LinkedHashMap preDau) {
this.preDau = preDau;
}
}
3.3.2 com.qf.bigdata.pojo.HBaseProperties
package com.qf.bigdata.pojo;
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = "spring.datasource.hbase")
public class HBaseProperties {
private String quorum;
private String rootDir;
private String nodeParent;
public String getQuorum() {
return quorum;
}
public void setQuorum(String quorum) {
this.quorum = quorum;
}
public String getRootDir() {
return rootDir;
}
public void setRootDir(String rootDir) {
this.rootDir = rootDir;
}
public String getNodeParent() {
return nodeParent;
}
public void setNodeParent(String nodeParent) {
this.nodeParent = nodeParent;
}
}
3.3.3 com.qf.bigdata.pojo.MilvusProperties
package com.qf.bigdata.pojo;
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = "spring.datasource.milvus")
public class MilvusProperties {
private String host;
private int port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
}
3.3.5 com.qf.bigdata.pojo.RecommendInfo
package com.qf.bigdata.pojo;
/**
* 查询结果
*/
public class RecommendInfo {
private int aid;
private Double probability;
public int getAid() {
return aid;
}
public void setAid(int aid) {
this.aid = aid;
}
public Double getProbability() {
return probability;
}
public void setProbability(Double probability) {
this.probability = probability;
}
}
3.3.6 com.qf.bigdata.pojo.RecommendResult
package com.qf.bigdata.pojo;
import java.util.List;
public class RecommendResult {
private int code; // 返回状态码
private String msg; // 状态码对应的信息
private List data; // 数据
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public List getData() {
return data;
}
public void setData(List data) {
this.data = data;
}
}
3.3.7 com.qf.bigdata.pojo.RetentionCurvelInfo
package com.qf.bigdata.pojo;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
/**
* 拟合曲线的对象
*/
public class RetentionCurvelInfo {
private Double theta0; //a
private Double theta1; //b
private String equation; // 拟合公式
private List samples = new ArrayList<>(); // 样本数据
private LinkedHashMap rrMap = new LinkedHashMap<>();
public Double getTheta0() {
return theta0;
}
public void setTheta0(Double theta0) {
this.theta0 = theta0;
}
public Double getTheta1() {
return theta1;
}
public void setTheta1(Double theta1) {
this.theta1 = theta1;
}
public String getEquation() {
return equation;
}
public void setEquation(String equation) {
this.equation = equation;
}
public List getSamples() {
return samples;
}
public void setSamples(List samples) {
this.samples = samples;
}
public LinkedHashMap getRrMap() {
return rrMap;
}
public void setRrMap(LinkedHashMap rrMap) {
this.rrMap = rrMap;
}
}
3.3.8 com.qf.bigdata.pojo.Sample
package com.qf.bigdata.pojo;
/**
* 公式的x,y的模型类
*/
public class Sample {
private double x; // 天数
private double y; // 留存率
public Sample() {
}
public Sample(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() {
return x;
}
public void setX(double x) {
this.x = x;
}
public double getY() {
return y;
}
public void setY(double y) {
this.y = y;
}
}
3.3.9 com.qf.bigdata.pojo.UserEmbeddingInfo
package com.qf.bigdata.pojo;
public class UserEmbeddingInfo {
private String uid;
private Float distance;
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public Float getDistance() {
return distance;
}
public void setDistance(Float distance) {
this.distance = distance;
}
}
3.3.10 com.qf.bigdata.pojo.UserEmbeddingResult
package com.qf.bigdata.pojo;
import java.util.List;
public class UserEmbeddingResult {
private int code;
private String msg;
private List data;
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public List getData() {
return data;
}
public void setData(List data) {
this.data = data;
}
}
3.4 service
3.4.1com.qf.bigdata.service.impl.RecommendServiceImpl
package com.qf.bigdata.service.impl;
import com.qf.bigdata.dao.HBaseDao;
import com.qf.bigdata.pojo.RecommendResult;
import com.qf.bigdata.service.RecommendService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Map;
@Service
public class RecommendServiceImpl implements RecommendService {
@Autowired
private HBaseDao hBaseDao;
/**
* 根据uid,从HBase中查询两路召回策略的结果:als和itemcf。
* 除此之外,还可以获取到用户和文章的向量
* 然后根据上面提到的数据送入到排序模型中进行计算分数
*/
@Override
public RecommendResult recommend(String uid) {
//一、 读取HBase中的数据信息
RecommendResult result = new RecommendResult();
result.setCode(0);
result.setMsg("ok");
//1. 从HBase中读取特征信息
Map featureMap = hBaseDao.transItemFeatureList(uid);
if (null == featureMap || featureMap.isEmpty()) {
String msg = String.format("User %s not exists or user some info is null", uid);
result.setCode(-1);
result.setMsg(msg);
result.setData(null);
return result;
}
return null;
}
}
3.4.2 com.qf.bigdata.service.impl.RetentionServiceImpl
package com.qf.bigdata.service.impl;
import com.qf.bigdata.dao.PrestoDao;
import com.qf.bigdata.pojo.RetentionCurvelInfo;
import com.qf.bigdata.pojo.Sample;
import com.qf.bigdata.service.RetentionService;
import com.qf.bigdata.utils.Leastsq;
import com.qf.bigdata.utils.TimeUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.ujmp.core.Matrix;
import java.math.BigDecimal;
import java.util.*;
/**
* dau预测的业务类
*/
@Service
public class RetentionServiceImpl implements RetentionService {
@Autowired
private PrestoDao prestoDao;
/**
* 计算拟合曲线,最终求留存率
* y = a * x ^ b
* @param start_date
* @param end_date
* @param gap
* @param scale
* @return
*
* "rci":{
* "theta0": 123,
* "theta1": 12,
* "equation": "a * x ^ b",
* "samples": [
* {x:111, y:111},
* {x:112, y:123},
* ...
* ],
* "rrMap":{
* 20211223:0.321,
* 20211224:0.123,
* ...
* }
* }
*/
@Override
public RetentionCurvelInfo curvel(String start_date, String end_date, int gap, int scale) {
//一、 通过jdbc从presto中查询到样本数据
//1. 从presto中查询样本数据
List samples = prestoDao.selectRetentionRate(start_date, end_date, scale);
//2. 判断样本数据是否存在,如果不存在就直接结束程序
if (samples.isEmpty()) {
System.err.println("presto query no data!!!!");
return null;
}
//二、 通过最小二乘算法,计算出a和b的值
//1. 变化样本数据的样本空间
List convertSamples = new ArrayList<>();
for (Sample sample : samples) {
Sample newSample = new Sample();
newSample.setX(Math.log(sample.getX()));
newSample.setY(Math.log(sample.getY()));
convertSamples.add(newSample);
}
//2.通过最小二乘法获取a和b的值
Matrix theta = Leastsq.matrixSolve(convertSamples);
Double[] thetaAB = Leastsq.getThetaAB(theta);
double a = thetaAB[0], b = thetaAB[1];
//3. 将这些值封装到rci
RetentionCurvelInfo rci = new RetentionCurvelInfo();
rci.setTheta0(a);
rci.setTheta1(b);
rci.setEquation("y = " + a + "* x ^ " + b);
rci.setSamples(samples);
rci.setRrMap(calRR(a, b, start_date, scale));
return rci;
}
/**
* 计算留存率
*/
private LinkedHashMap calRR(double a, double b, String start_date, int scale) {
//1. 创建map准备存放最终的结果
LinkedHashMap rrMap = new LinkedHashMap<>();
//2. 获取日历时间
Calendar calendar = Calendar.getInstance();
//3. 遍历scale
for (int i = 1; i <= scale; i++) {
//3.1 转换开始时间
Date date = TimeUtils.toDate(start_date, "yyyy-MM-dd");
//3.2 将日历类型设置为开始时间的日历时间
calendar.setTime(date);
//3.3 叠加日历
calendar.add(Calendar.DAY_OF_YEAR, i); // 20211223, 20211224,...
//3.4 将处理好增量的我日志的日期转换为字符串
String rrDate = TimeUtils.toStringDate(calendar.getTime(), "yyyy-MM-dd");
//3.5 获取留存率:y = a * x ^ b
double rr = a * Math.pow(i, b);
//3.6 处理小数点问题:0.23213123123123123 --》 0.232
BigDecimal bigDecimal = new BigDecimal(rr);
rr = bigDecimal.setScale(3, BigDecimal.ROUND_HALF_UP).doubleValue();
//3.7 返回map
rrMap.put(rrDate, rr);
}
return rrMap;
}
}
3.4.3 com.qf.bigdata.service.impl.UserEmbeddingServiceImpl
package com.qf.bigdata.service.impl;
import com.facebook.presto.jdbc.PrestoArray;
import com.qf.bigdata.dao.MilvusDao;
import com.qf.bigdata.dao.PrestoDao;
import com.qf.bigdata.pojo.UserEmbeddingInfo;
import com.qf.bigdata.pojo.UserEmbeddingResult;
import com.qf.bigdata.service.UserEmbeddingService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
@Service
public class UserEmbeddingServiceImpl implements UserEmbeddingService {
@Autowired
private PrestoDao prestoDao;
@Autowired
private MilvusDao milvusDao;
/**
* 把presto的数据读取出来,然后向milvus插入数据
*/
@Override
public UserEmbeddingResult loadEmbedding() {
//一、从presto查询到向量并封装
//1. sql
String sql = "select * from dws_news.user_content_embedding";
//2. 获取结果
List> rawResult = prestoDao.queryForSql(sql);
//3. 根据情况将结果进行封装
UserEmbeddingResult result = new UserEmbeddingResult();
if (null == result) {
result.setCode(-1);
result.setMsg("sql error, please check your sql statement!!!");
return result;
} else {
result.setCode(0);
result.setMsg("ok");
}
//4. 将查询结果转换封装
List vectorId = new ArrayList<>(); // 在本项目中就是uid
List> vectors = new ArrayList<>(); // vector
//5. 遍历
for (int i = 0;i < rawResult.size(); i++) {
//5.1 将presto的list的map的user_vector
Object user_vector = rawResult.get(i).get("user_vector"); // 取值向量,这个向量类型
PrestoArray prestoArray = (PrestoArray) user_vector; // 向量类型转换为presto的数组类型
List
3.4.4com.qf.bigdata.service.RecommendService
package com.qf.bigdata.service;
import com.qf.bigdata.pojo.RecommendResult;
public interface RecommendService {
RecommendResult recommend(String uid);
}
3.4.5 com.qf.bigdata.service.RetentionService
package com.qf.bigdata.service;
import com.qf.bigdata.pojo.RetentionCurvelInfo;
public interface RetentionService {
RetentionCurvelInfo curvel(String start_date, String end_date, int gap, int scale);
}
3.4.6 com.qf.bigdata.service.UserEmbeddingService
package com.qf.bigdata.service;
import com.qf.bigdata.pojo.UserEmbeddingResult;
public interface UserEmbeddingService {
UserEmbeddingResult loadEmbedding();
UserEmbeddingResult searchSimilarUser(long uid, long topk);
}
3.5 utils

3.5.1com.qf.bigdata.utils.HBaseUtils
package com.qf.bigdata.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
public class HBaseUtils {
private Configuration configuration;
private volatile Connection connection;
public HBaseUtils() {}
public HBaseUtils(Configuration configuration) {
this.setConfiguration(configuration);
}
public Configuration getConfiguration() {
return configuration;
}
public void setConfiguration(Configuration configuration) {
this.configuration = configuration;
}
public Connection getConnection() {
if (null == this.connection) {
synchronized (this) {
if (null == this.connection) {
try {
this.connection = ConnectionFactory.createConnection(configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
return this.connection;
}
}
3.5.2 com.qf.bigdata.utils.Leastsq
(这是最小二乘回归方程就是DAU预测的代码,我想起来了,之前搞了jvm模型之后就不想换了一直沿用到使用springboot。我后面新创建了springboot项目,但是环境有问题,打包的时候不能打全。)
package com.qf.bigdata.utils;
import com.qf.bigdata.pojo.Sample;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.ujmp.core.DenseMatrix;
import org.ujmp.core.Matrix;
import java.math.BigDecimal;
import java.util.List;
/**
* @Description: 矩阵法求解线性最小二乘,当前只支持 y=a+bx的形式,不支持多项式
*/
public class Leastsq {
private static Logger logger = LoggerFactory.getLogger(Leastsq.class);
/**
* 矩阵解法的公式 = (^ * )^-1 * ^T* 及 X的转置乘以X求逆矩阵之后再乘以X的转置再乘以Y
*
* @param samples 样本数据
* @return theta
**/
public static Matrix matrixSolve(List samples) {
try {
int coefCount = 2;
// 初始化一个矩阵 samples.size * coefCount ,存储样本特征数据, 因为我们支持 y=a+bx ,因此这个矩阵是一个
// samples.size * 2 的矩阵 ,矩阵第一列时常数项1 第二列是会赋值为 x 的值,就是样本特征值
Matrix matrixX = DenseMatrix.Factory.ones(samples.size(), coefCount);
// 赋值矩阵第二列X的值
for (int i = 0; i < samples.size(); i++) {
// 第 i 行,第2列 ,
matrixX.setAsDouble(samples.get(i).getX(), i, 1);
}
// 初始化 samples.size * 1 的矩阵,存储样本标签值,即y的值
Matrix matrixY = DenseMatrix.Factory.ones(samples.size(), 1);
// 把y的值赋值给矩阵
for (int i = 0; i < samples.size(); i++) {
matrixY.setAsDouble(samples.get(i).getY(), i, 0);
}
// 求Y的转置
Matrix matrixXTrans = matrixX.transpose();
// X^T*X X转置乘以X
Matrix matrixMtimes = matrixXTrans.mtimes(matrixX);
// (X^T*X)^-1 X转置乘以X的逆矩阵
Matrix matrixMtimesInv = matrixMtimes.inv();
// (X^T*X)^-1 * X^T X转置乘以X的逆矩阵再乘X的转置
Matrix matrixMtimesInvMtimes = matrixMtimesInv.mtimes(matrixXTrans);
// (X^T*X)^-1 * X^T * Y X转置乘以X的逆矩阵再乘X的转置再乘Y 得到最终我们要求的参数矩阵
return matrixMtimesInvMtimes.mtimes(matrixY);
} catch (Exception e) {
logger.error("leastsq error, samples", samples, e);
return null;
}
}
/**
* 二阶函数线性拟合,函数形式 y=ax^2+bx
* @param samples 样本点
* @return 求解出的参数矩阵
*/
public static Matrix matrixSolveSO(List samples) {
try {
int coefCount = 2;
// 初始化一个矩阵 samples.size * coefCount ,存储样本特征数据, 我们支持 y=ax^2+bx
// 这个矩阵是一个samples.size * 2 的矩阵
// 矩阵第一列复制为样本x^2, 第二列是会赋值为x
Matrix matrixX = DenseMatrix.Factory.ones(samples.size(), coefCount);
// 赋值矩阵第一列X^2的值 这里是唯一和我们拟合 y= a+bx 函数不同的地方,大家应该注意到
// 不同点在于参数a ,b 对应的系数
for (int i = 0; i < samples.size(); i++) {
// 第 i 行,第1列 ,
matrixX.setAsDouble(Math.pow(samples.get(i).getX(),2), i, 0);
}
// 赋值矩阵第二列X的值
for (int i = 0; i < samples.size(); i++) {
// 第 i 行,第2列 ,
matrixX.setAsDouble(samples.get(i).getX(), i, 1);
}
// 初始化 samples.size * 1 的矩阵,存储样本标签值,即y的值
Matrix matrixY = DenseMatrix.Factory.ones(samples.size(), 1);
// 把y的值赋值给矩阵
for (int i = 0; i < samples.size(); i++) {
matrixY.setAsDouble(samples.get(i).getY(), i, 0);
}
// 求Y的转置
Matrix matrixXTrans = matrixX.transpose();
// X^T*X X转置乘以X
Matrix matrixMtimes = matrixXTrans.mtimes(matrixX);
// (X^T*X)^-1 X转置乘以X的逆矩阵
Matrix matrixMtimesInv = matrixMtimes.inv();
// (X^T*X)^-1 * X^T X转置乘以X的逆矩阵再乘X的转置
Matrix matrixMtimesInvMtimes = matrixMtimesInv.mtimes(matrixXTrans);
// (X^T*X)^-1 * X^T * Y X转置乘以X的逆矩阵再乘X的转置再乘Y 得到最终我们要求的参数矩阵
return matrixMtimesInvMtimes.mtimes(matrixY);
} catch (Exception e) {
logger.error("leastsq so fit error, samples", samples, e);
return null;
}
}
/**
* 获取转换求导之后的数据
* @param theta
* @return
*/
public static Double[] getThetaAB(Matrix theta) {
// 求出的参数结果也是一个矩阵,他是一个 2 * 1 的矩阵,每一行代表一个求出参数值
// 变换后的线性函数 lna 的值 ,0,0 第一行第一列的值
double theta0 = theta.getAsDouble(0, 0);
// 变换后的线性函数 b 的值, 1,0 第二行第一列的值
double theta1 = theta.getAsDouble(1, 0);
// 这里的theta0是变换后的函数a的值。 原函数 a 的值应该是 e^a
Double a = Math.pow(Math.E, theta0);
// 这里的theta1是变换后的函数b的值,也是原函数b的值,不理解看变换的公式
Double b = theta1;
BigDecimal bda = new BigDecimal(a);
a = bda.setScale(3, BigDecimal.ROUND_HALF_UP).doubleValue();
BigDecimal bdb = new BigDecimal(b);
b = bdb.setScale(3, BigDecimal.ROUND_HALF_UP).doubleValue();
Double[] bds = new Double[2];
bds[0] = a;
bds[1] = b;
return bds;
}
}
3.5.3 com.qf.bigdata.utils.MilvusUtils
package com.qf.bigdata.utils;
import io.milvus.client.ConnectParam;
import io.milvus.client.MilvusClient;
import io.milvus.client.MilvusGrpcClient;
import io.milvus.client.Response;
public class MilvusUtils {
private volatile MilvusClient milvusClient; // 将这个成员变量加上了乐观锁
private String host;
private int port;
public MilvusUtils(String host, int port) {
this.host = host;
this.port = port;
}
/**
* 获取到连接milvus服务端的客户端对象
* @return
*/
public MilvusClient getMilvusClient() {
if (milvusClient == null) {
//1. 创建客户端对象
MilvusClient milvusClient = new MilvusGrpcClient();
//2. 连接
//2.1 创建连接对象
ConnectParam connectParam = new ConnectParam.Builder().withHost(host).withPort(port).build();
//2.2 连接并返回
try {
Response response = milvusClient.connect(connectParam);
}catch (Exception e) {
System.err.println("connect milvus error" + e.getMessage());
return null;
}
System.out.println("milvusClient create successful");
this.milvusClient = milvusClient;
}
return milvusClient;
}
}
3.5.5 com.qf.bigdata.utils.TimeUtils
package com.qf.bigdata.utils;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* 时间工具类
*/
public class TimeUtils {
/**
* 将一个字符串时间,以指定的时间格式转换为一个date类型
*/
public static Date toDate(String date, String fmt) {
try{
DateFormat df = new SimpleDateFormat(fmt);
Date d = df.parse(date);
return d;
}catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 将一个date类型时间转换为一个指定格式的字符串时间
*/
public static String toStringDate(Date date, String fmt) {
try{
DateFormat df = new SimpleDateFormat(fmt);
String d = df.format(date);
return d;
}catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
3.6 web
3.6.1 com.qf.bigdata.web.controller.DauController
package com.qf.bigdata.web.controller;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONPath;
import com.qf.bigdata.pojo.DauPredictInfo;
import com.qf.bigdata.pojo.RetentionCurvelInfo;
import com.qf.bigdata.service.RetentionService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.*;
import java.util.LinkedHashMap;
import java.util.Map;
@RestController
@SpringBootApplication
@RequestMapping("/api/v1") // 请求的路径
public class DauController {
@Autowired
private RetentionService retentionService;
/**
* 表示这个方法在浏览器中的请求的url
* curl ip:port/api/v1/dau
* @param json : 请求过程中的传递的json参数会被自动封装到json对象中
*/
@RequestMapping(value ="/dau", method = {RequestMethod.POST}, produces = "application/json;charset=UTF-8")
@ResponseBody
public DauPredictInfo preDau(@RequestBody JSONObject json) {
//1. 取出json的字段值
String start_date = JSONPath.eval(json, "$.start_date").toString();
String end_date = JSONPath.eval(json, "$.end_date").toString();
// String end_date = json.getString("end_date");
int gap = Integer.parseInt(JSONPath.eval(json, "$.gap").toString());
int dnu = Integer.parseInt(JSONPath.eval(json, "$.dnu").toString());
int scale = Integer.parseInt(JSONPath.eval(json, "$.scale").toString());
//2. 根据参数的值,使用业务层代码来进行业务操作,从而得到DauPredictInfo
//2.1 创建返回结果对象
DauPredictInfo dauPredictInfo = new DauPredictInfo();
//2.2 获取rci对象
RetentionCurvelInfo rci = retentionService.curvel(start_date, end_date, gap, scale);
//2.3 校验
if (null == rci || rci.getRrMap().size() == 0) {
dauPredictInfo.setCode(1); // 0表示成功,1表示失败
dauPredictInfo.setMsg("sorry, some error is happened!!!");
return dauPredictInfo;
}
//2.4 预测人数
Double tmp = 0.0d;
LinkedHashMap preDau = new LinkedHashMap<>(); // 预测的每日的留存人数
for (Map.Entry entry : rci.getRrMap().entrySet()) {
String date = entry.getKey(); // 日期
Double rr = entry.getValue(); // 留存率
tmp = dnu * rr; // 留存人数
// 2.5 将预测的留存人数存放到map中
preDau.put(date, dnu + tmp.intValue()); // 指定日期的活跃人数
}
//2.6 将结果封装到dauPredictInfo
dauPredictInfo.setRci(rci);
dauPredictInfo.setCode(0);
dauPredictInfo.setMsg("ok");
dauPredictInfo.setPreDau(preDau);
//3. 返回
return dauPredictInfo;
}
}
3.6.2 com.qf.bigdata.web.controller.RecommendController
package com.qf.bigdata.web.controller;
import com.qf.bigdata.pojo.RecommendResult;
import com.qf.bigdata.service.RecommendService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@RequestMapping("/api/v1")
public class RecommendController {
@Autowired
private RecommendService recommendService;
@RequestMapping(value = "/recommend/{uid}", method = {RequestMethod.GET})
public RecommendResult recommend(@PathVariable String uid) {
return recommendService.recommend(uid);
}
}
3.6.3com.qf.bigdata.web.controller.UserEmbeddingController
package com.qf.bigdata.web.controller;
import com.qf.bigdata.pojo.UserEmbeddingResult;
import com.qf.bigdata.service.UserEmbeddingService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
@RequestMapping("/api/v1")
public class UserEmbeddingController {
@Autowired
private UserEmbeddingService userEmbeddingService;
/**
* 向milvus插入数据
*/
@RequestMapping("/user/embedding/load")
@ResponseBody
public UserEmbeddingResult loadEmbedding() {
return userEmbeddingService.loadEmbedding();
}
/**
* 从milvus中检索数据
*/
@RequestMapping("/user/embedding/search/{uid}/{topk}")
@ResponseBody
public UserEmbeddingResult searchSimilarUser(@PathVariable String uid, @PathVariable String topk) {
return userEmbeddingService.searchSimilarUser(Long.parseLong(uid), Long.parseLong(topk));
}
}
3.6.4 com.qf.bigdata.Application
package com.qf.bigdata;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Configuration : 在类上这个注解,表示这个类是一个配置类,你的配置就可以写在这个配置类上
* @EnableAutoConfiguration : springboot会根据你的jar或者你的依赖自动生成配置
* @ComponentScan : 告诉你的spring扫描那个包,哪个类上标记了这个注解,可以通过ioc创建这个对象
*/
@SpringBootApplication // 这个注解以上三个注解的综合
//view
public class Application {
public static void main(String[] args) {
//启动spring的程序,当springboot程序扎起启动的时候会自动的加载application.yml配置
SpringApplication.run(Application.class, args);
}
}
3.6.5 com.qf.bigdata.HBaseDao
我不知道为什么我之前没敲这个代码,漏敲了
package com.qf.bigdata;
public class HBaseDao {
}
3.6.6 com.qf.bigdata.TomcatConfig
package com.qf.bigdata;
import org.apache.catalina.connector.Connector;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.web.embedded.tomcat.TomcatConnectorCustomizer;
import org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory;
import org.springframework.boot.web.servlet.server.ServletWebServerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 自定义tomcat配置
*/
@Configuration
public class TomcatConfig {
@Value("${spring.server.port}")
private String port;
@Value("${spring.server.maxThreads}")
private String maxThreads;
@Value("${spring.server.acceptorThreadCount}")
private String acceptorThreadCount;
@Value("${spring.server.protocol}")
private String protocol;
/**
* 工厂适用于帮助我们创建servlet的
*/
@Bean
public ServletWebServerFactory servletContainer() {
//1.创建tomcatservlet工厂对象
TomcatServletWebServerFactory tomcat = new TomcatServletWebServerFactory();
tomcat.addConnectorCustomizers(new MyTomcatConnectorCustomizer());
return tomcat;
}
public class MyTomcatConnectorCustomizer implements TomcatConnectorCustomizer {
@Override
public void customize(Connector connector) {
connector.setPort(Integer.parseInt(port));
connector.setProperty("maxThreads", maxThreads);
connector.setProperty("protocol", protocol);
connector.setProperty("acceptorThreadCount", acceptorThreadCount);
}
}
}
4 操作
时代久远忘记了一些操作步骤了,但是我还有之前的一些草稿。搞时间推算我应该是清明节之前两周都在搞推荐系统。真的忘记了。

我真的忘记了怎么搞的(就是我把打包之后的jar上传到指定目录,然后改名了,在虚拟机里面运行jar包)
4.2 保存hbase
start-hbase.sh
hbase shell
create_namespace 'recommend'
create_table 'recommend:itemcf','f1'
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name itemcf \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.ItemCF \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:itemcf -k 3
4.3 als
create 'recommend:alscf', 'f1'
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name als \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.AlsCF \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:alscf -k 3
4.4 Feature
hbase> create 'recommend:item-base-feature', 'f1'
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name itemBaseFeature \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.ItemBaseFeature \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:item-base-feature -k 3
4.5 ArticleEmbedding
create 'recommend:item-embedding', 'f1'
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name articleEmbedding \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.ArticleEmbedding \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:item-embedding -k 3
4.6 UserBaseFeature
hbase> create 'recommend:user-base-feature', 'f1'
##2. 提交spark程序
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name userBaseFeature \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.UserBaseFeature \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:user-base-feature -k 3
4.7 回归算法
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name lr \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode client \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.LRClass \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root
4.8 回归之后的featureEmd
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name union-feature \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode client \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.UnionFeature \
/data/jar/recommend-test-1.0.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:union-feature -k 3
4.9 cf
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name lr \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode client \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.LRClass \
/data/jar/recommend-test-1.0.jar \
-e prod -x root
4.10 用户向量的嵌入
${SPARK_HOME}/bin/spark-submit \
--jars /usr/local/hive/auxlib/hudi-spark-bundle_2.11-0.5.2-incubating.jar \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.executor.heartbeatInterval=120s \
--conf spark.network.timeout=600s \
--conf spark.sql.catalogImplementation=hive \
--conf spark.yarn.submit.waitAppCompletion=false \
--name userBaseFeature \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode cluster \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.UserBaseFeature \
/data/jar/recommend-1.0-jar-with-dependencies.jar \
-e prod -x root -z 192.168.10.101 -p 2181 -f /tmp/hfile -t recommend:user-base-feature -k 3
4.11 最后一个springboot的验证
java -Xmx512m -Xms512m -XX:+UseConcMarkSweepGC -jar /data/jar/data-api-1.0.jar
验证:
curl -XGET http://192.168.10.101:7088/api/v1/recommend/809
5 在项目我遇到的bug们
YarnClusterScheduler: Initial job has not accepted any resources;_林柚晞的博客-CSDN博客
Hbase报错:/usr/local/hbase/bin/hbase:行445: /usr/local/bin/java: 没有那个文件或目录_林柚晞的博客-CSDN博客_启动hbase没有那个文件或目录
有关java.lang.ClassNotFoundException报错的总结_林柚晞的博客-CSDN博客
为什么能在Presto中可以运行的sql却在SparkSQL中报错?_林柚晞的博客-CSDN博客
HBase的异常:ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing_林柚晞的博客-CSDN博客
Error running ‘spring-boot-helloworld [package]’: No valid Maven installation found._林柚晞的博客-CSDN博客
其实我遇到的bug远大于上面提的,有些小bug根本没记录到。
这算是对过去三月份的总结吧。
最后推荐系统,我流程都搞完了,但是有一张表没搞到数据,机器训练的数据倒是有。
但是我确定这个代码是没错的。
我一定要学好机器学习!