Jetson系列——基于python API部署Paddle Inference GPU预测库(2.1.1)
已测试通过的硬件平台:
Jetson nanoJetson Xavier NXJetson Xavier AGX
已测试通过的系统环境:
JetPack4.4JetPack4.5
文章目录
-
- 一、安装PaddlePaddle
-
- 1.直接下载编译好的Python预测库
-
- 下载地址
- 下载
- 2.安装whl
- 3.测试
- (3)报错问题解决
- 二、测试Paddle Inference
-
- 1.环境准备
- 2.测试跑通GPU预测模型
- 3.报错解决
- (1)运行demo过程中卡住
- 三、部署自己的目标检测 / 图像分类模型
-
- 1.图像分类部署demo
- 2.目标检测模型部署demo
- 四、基于Jetson nano的性能分析(CPU、GPU、GPU+TensorRT预测时间对比)
-
- 关于如何更改预测模式
- 测试模型:`mobilenet v1`
- 测试模型:`yolov3_r50vd`
开发板基础环境配置博客:Jetson系列——Ubuntu18.04版本基础配置(换源、远程桌面、ROS)
镜像下载地址:Jetson 下载中心
一、安装PaddlePaddle
有两种方式,因为Jetson系列开发板在PaddlePaddle官方有已经编译好的python3.6的whl,所以我们直接下载就好,不用编译。
1.直接下载编译好的Python预测库
下载地址
- PaddlePaddle官方whl包下载
下载
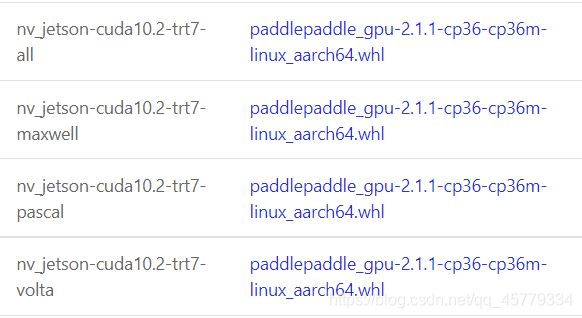
选择Python3.6版本的下载即可,其中:
- Jetson nano(4GB版本) 的GPU是
Maxwell架构,选择第一种nv_jetson-cuda10.2-trt7-all或第二种nv_jetson-cuda10.2-trt7-maxwell - Jetson nano(2GB版本) 的GPU是
Maxwell架构,选择第一种nv_jetson-cuda10.2-trt7-all或第二种nv_jetson-cuda10.2-trt7-maxwell - Jetson Xavier NX 的GPU是
Volta架构,选择第四种nv_jetson-cuda10.2-trt7-volta
2.安装whl
将下载好的whl文件传送到开发板上,然后安装whl:
pip3 install paddlepaddle_gpu-2.1.1-cp36-cp36m-linux_aarch64.whl
3.测试
打开python3:
import paddle
paddle.fluid.install_check.run_check()
报warning忽略即可,不影响使用。如果遇到报错,请继续往下看。

(3)报错问题解决
- 报错信息:
ImportError: cannot import name 'collections_abc'

解决方法:重装一下six模块就可以。
sudo pip3 uninstall six
pip3 install six
二、测试Paddle Inference
1.环境准备
拉取Paddle-Inference-Demo:
git clone https://github.com.cnpmjs.org/PaddlePaddle/Paddle-Inference-Demo.git
- Tips:这里用了一个Github国内镜像源的小技巧来加快
git clone速度,想学的小伙伴可以参考博客:Git——git clone速度加快方法
2.测试跑通GPU预测模型
给可执行权限:
cd Paddle-Inference-Demo/python
chmod +x run_demo.sh
需要注意的是,需要将所有子文件夹中的run.sh最后的python修改为python3:
然后执行即可。
./run_demo.sh
也可以选择运行单个模型的run.sh。如果过程中有报错,请继续往下看。
3.报错解决
(1)运行demo过程中卡住
此处需要注意,使用时需要将开发板工作模式调成最大功率模式,同时保证开发的实际内存+虚拟内存为12G。
解决方法:
Jetson nano:扩大运行内存- 内存总和:
12G(给虚拟内存6-8G,保证总内存为12G) - 显存数:
500MB(Jetson nano最大为500)
- 内存总和:
sudo fallocate -l 8G /var/swapfile8G
sudo chmod 600 /var/swapfile8G
sudo mkswap /var/swapfile8G
sudo swapon /var/swapfile8G
sudo bash -c 'echo "/var/swapfile8G swap swap defaults 0 0" >> /etc/fstab'
Jetson NX:不需要再扩大内存 ,只需要将板子调成最大性能模式即可。- 内存总和:
12G(已满足) - 显存数:
2500MB(Jetson NX最大为4000MB)
- 内存总和:
扩大虚拟内存后,务必重启,释放所有内存和显存后执行。 随后运行正常:
三、部署自己的目标检测 / 图像分类模型
1.图像分类部署demo
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import PrecisionType
from paddle.inference import create_predictor
import time
# ————————————————图像预处理函数————————————————
def resize_short(img, target_size):
""" resize_short """
percent = float(target_size) / min(img.shape[0], img.shape[1])
resized_width = int(round(img.shape[1] * percent))
resized_height = int(round(img.shape[0] * percent))
resized = cv2.resize(img, (resized_width, resized_height))
return resized
def crop_image(img, target_size, center):
""" crop_image """
height, width = img.shape[:2]
size = target_size
if center == True:
w_start = (width - size) / 2
h_start = (height - size) / 2
else:
w_start = np.random.randint(0, width - size + 1)
h_start = np.random.randint(0, height - size + 1)
w_end = w_start + size
h_end = h_start + size
img = img[int(h_start):int(h_end), int(w_start):int(w_end), :]
return img
def preprocess(img):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = resize_short(img, 224)
img = crop_image(img, 224, True)
# bgr-> rgb && hwc->chw
img = img[:, :, ::-1].astype('float32').transpose((2, 0, 1)) / 255
img_mean = np.array(mean).reshape((3, 1, 1))
img_std = np.array(std).reshape((3, 1, 1))
img -= img_mean
img /= img_std
return img[np.newaxis, :]
#——————————————————————模型配置、预测相关函数——————————————————————————
def predict_config(model_file, params_file):
# 根据预测部署的实际情况,设置Config
config = Config()
# 读取模型文件
config.set_prog_file(model_file)
config.set_params_file(params_file)
# Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。
config.enable_use_gpu(500, 0)
# 可以设置开启IR优化、开启内存优化。
config.switch_ir_optim()
config.enable_memory_optim()
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Float32,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
predictor = create_predictor(config)
return predictor
def predict(image, predictor):
img = preprocess(image)
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
input_tensor.reshape(img.shape)
input_tensor.copy_from_cpu(img.copy())
# 执行Predictor
predictor.run()
# 获取输出
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu()
print("output_names", output_names)
print("output_tensor", output_tensor)
print("output_data", output_data)
return output_data
# 展示结果
def post_res(label_dict, res):
res = res.tolist()
# print(type(res))
# print(max(res))
target_index = res.index(max(res))
print("结果是:" + " " + label_dict[target_index])
if __name__ == '__main__':
label_dict = {0:"metal", 1:"paper", 2:"plastic", 3:"glass"}
model_file = "./mobilenetv1/inference.pdmodel"
params_file = "./mobilenetv1/inference.pdiparams"
predictor = predict_config(model_file, params_file)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# 预测
print('Predict Start')
time_start=time.time()
res = predict(frame, predictor)
post_res(label_dict, res)
print('Time Cost:{}'.format(time.time()-time_start) , "s")
print('Predict End')
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
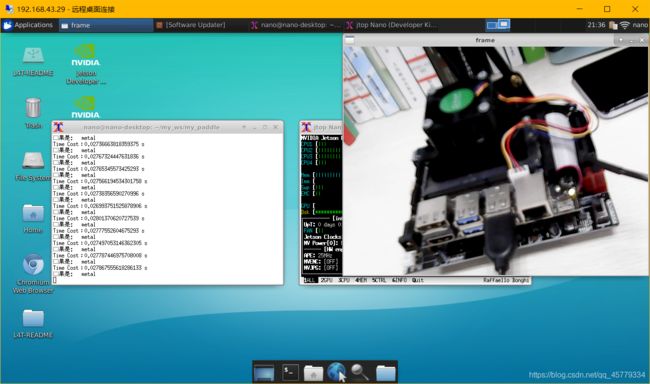
效果展示
采用模型为mobilenet v1:
2.目标检测模型部署demo
import cv2
import numpy as np
from paddle.inference import Config
from paddle.inference import PrecisionType
from paddle.inference import create_predictor
import yaml
import time
# ————————————————图像预处理函数———————————————— #
def resize(img, target_size):
"""resize to target size"""
if not isinstance(img, np.ndarray):
raise TypeError('image type is not numpy.')
im_shape = img.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
im_scale_x = float(target_size) / float(im_shape[1])
im_scale_y = float(target_size) / float(im_shape[0])
img = cv2.resize(img, None, None, fx=im_scale_x, fy=im_scale_y)
return img
def normalize(img, mean, std):
img = img / 255.0
mean = np.array(mean)[np.newaxis, np.newaxis, :]
std = np.array(std)[np.newaxis, np.newaxis, :]
img -= mean
img /= std
return img
def preprocess(img, img_size):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = resize(img, img_size)
img = img[:, :, ::-1].astype('float32') # bgr -> rgb
img = normalize(img, mean, std)
img = img.transpose((2, 0, 1)) # hwc -> chw
return img[np.newaxis, :]
# ——————————————————————模型配置、预测相关函数—————————————————————————— #
def predict_config(model_file, params_file):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
# 根据预测部署的实际情况,设置Config
config = Config()
# 读取模型文件
config.set_prog_file(model_file)
config.set_params_file(params_file)
# Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。
config.enable_use_gpu(500, 0)
# 可以设置开启IR优化、开启内存优化。
config.switch_ir_optim()
config.enable_memory_optim()
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Float32,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
predictor = create_predictor(config)
return predictor
def predict(predictor, img):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 执行Predictor
predictor.run()
# 获取输出
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
# ——————————————————————后处理函数—————————————————————————— #
def draw_bbox_image(frame, result, label_list, threshold=0.5):
for res in result:
cat_id, score, bbox = res[0], res[1], res[2:]
if score < threshold:
continue
xmin, ymin, xmax, ymax = bbox
cv2.rectangle(frame, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (255,0,255), 2)
print('category id is {}, bbox is {}'.format(cat_id, bbox))
try:
label_id = label_list[int(cat_id)]
# #cv2.putText(图像, 文字, (x, y), 字体, 大小, (b, g, r), 宽度)
cv2.putText(frame, label_id, (int(xmin), int(ymin-2)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
cv2.putText(frame, str(round(score,2)), (int(xmin-35), int(ymin-2)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,255,0), 2)
except KeyError:
pass
if __name__ == '__main__':
# 从infer_cfg.yml中读出label
infer_cfg = open('yolov3_r50vd_dcn_270e_coco/infer_cfg.yml')
data = infer_cfg.read()
yaml_reader = yaml.load(data)
label_list = yaml_reader['label_list']
print(label_list)
# 配置模型参数
model_file = "./yolov3_r50vd_dcn_270e_coco/model.pdmodel"
params_file = "./yolov3_r50vd_dcn_270e_coco/model.pdiparams"
# 初始化预测模型
predictor = predict_config(model_file, params_file)
cap = cv2.VideoCapture(0)
# 图像尺寸相关参数初始化
ret, img = cap.read()
im_size = 608
scale_factor = np.array([im_size * 1. / img.shape[0], im_size * 1. / img.shape[1]]).reshape((1, 2)).astype(np.float32)
im_shape = np.array([im_size, im_size]).reshape((1, 2)).astype(np.float32)
while True:
ret, frame = cap.read()
# 预处理
data = preprocess(frame, im_size)
time_start=time.time()
# 预测
result = predict(predictor, [im_shape, data, scale_factor])
print('Time Cost:{}'.format(time.time()-time_start) , "s")
draw_bbox_image(frame, result[0], label_list, threshold=0.1)
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
效果展示
采用模型为yolov3_r50vd_dcn_270e:
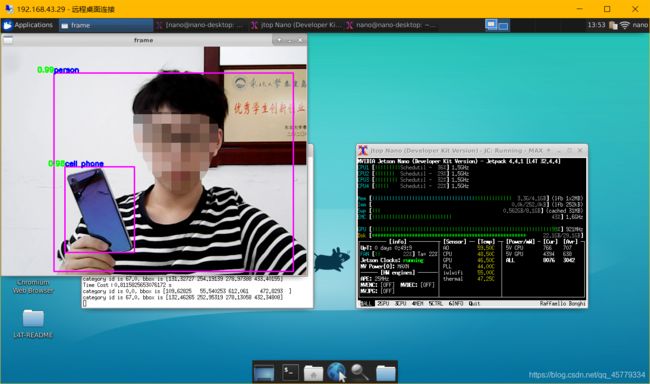
四、基于Jetson nano的性能分析(CPU、GPU、GPU+TensorRT预测时间对比)
关于如何更改预测模式
所有的模式都在predict_config()函数中,其中:
- GPU预测:
config.enable_use_gpu(500, 0)(注释掉该代码即为CPU模式) - 开启IR优化、开启内存优化:
config.switch_ir_optim()和config.enable_memory_optim()(一般都开启) - TensorRT加速:
config.enable_tensorrt_engine()- 具体参数配置参考:Paddle-TensorRT库
def predict_config(model_file, params_file):
'''
函数功能:初始化预测模型predictor
函数输入:模型结构文件,模型参数文件
函数输出:预测器predictor
'''
# 根据预测部署的实际情况,设置Config
config = Config()
# 读取模型文件
config.set_prog_file(model_file)
config.set_params_file(params_file)
# Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。
config.enable_use_gpu(500, 0)
# 可以设置开启IR优化、开启内存优化。
config.switch_ir_optim()
config.enable_memory_optim()
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Float32,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
predictor = create_predictor(config)
return predictor
测试模型:mobilenet v1
1.图像尺寸为224
-
(1)使用CPU预测:平均每帧预测时间为0.24s
-
(2)开启GPU加速:平均每帧预测时间为0.039s
-
(3)使用TensorRT加速后:平均每帧预测时间为0.027s
测试模型:yolov3_r50vd
1.图像尺寸为:608
-
(1)使用CPU预测:平均每帧预测时间为12.8s(因为时间太长,没有过多测试,但是前5帧基本都这个速度)
-
(2)开启GPU加速:平均每帧预测时间为0.81s
-
(3)使用TensorRT加速后:
- Float32模式:平均每帧预测时间为0.54s
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Float32,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False) - Float16(Half)模式:平均每帧预测时间为0.34s
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=PrecisionType.Half,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
- Float32模式:平均每帧预测时间为0.54s
2.图像尺寸为:224
-
(1)使用CPU预测:平均每帧预测时间为1.8s
-
(2)开启GPU加速:平均每帧预测时间为0.18s
-
(3)使用TensorRT加速后:会报错(因为在模型内部训练时的输入即为608*608,而当前版本TRT不支持动态调整input,所以只能将在模型训练时的尺寸修改后再使用TRT,报错如下所示)
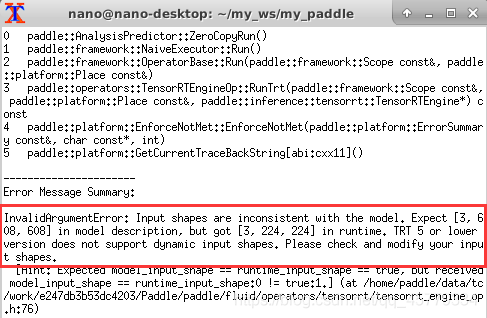
具体关于TRT的资料可以参考:https://paddle-inference.readthedocs.io/en/master/optimize/paddle_trt.html,这里说的很清楚关于TRT动态shape和静态shape都分别支持哪些模型,同时可以调整TRT的对应参数,从而实现对模型预测速度的进一步提升。
参考文章:
-
PaddlePaddle/Paddle-Inference-Demo
-
预测示例 (Python)
-
在Jetson nano上编译paddle(带TensorRT)并跑通Paddle-Inference-Demo
-
从0到1教你在Jetson Xavier NX玩转PaddlePaddle
-
教你如何在三步内Jetson系列上安装PaddlePaddle
-
ImportError: cannot import name ‘collections_abc‘ from ‘six.moves‘ (unknown location)