基于推特数据挖掘交通事件的城市交通流深度学习预测模型
文章信息
本周阅读的论文是题目为《A deep-learning model for urban traffic flow prediction with traffic events mined from twitter》的一篇2021年发表在《World Wide Web》涉及交通事故下的城市交通客流预测的文章。
摘要
短期交通预测是现代城市交通管理和控制系统的关键。数据驱动的交通预测模型在预测非常规交通事件(如车辆事故、道路封闭和极端天气条件)下的交通流量时精度会有所下降。通过对社交网络(特别是推特)数据进行分析挖掘,使用在社交媒体数据中能够扰乱常规交通模式的事件数据来补充交通数据,以此提高城市交通流预测的精度。本文提出了一种深度学习的城市交通预测模型,该模型将从推特数据中提取的信息与交通、天气信息相结合,采用深度双向长短时记忆网络(LSTM)和堆叠自动编码器(SAE)结合的深度学习模型,进行多步交通流预测。模型在英国曼彻斯特的一个城市道路网络上进行了评估。使用真实世界数据进行的大量实证分析的结果证明,与其他经典/统计和机器学习(ML)中较为先进的模型相比,文章提出的模型可以提高预测精度。预测精度的提高可以减少道路使用者的沮丧,同时为企业节省成本,并减少对环境的危害。
介绍
交通数据科学经过多年的发展,扩展了用于搭建预测模型的大量数据源。早期通过调查天气对驾驶行为、出行需求、出行方式、道路安全和交通流特征的影响,研究天气数据对交通流参数的重要性。研究发现,恶劣天气会降低交通容量和运行速度,造成拥堵和路网生产力的损失。尽管天气因素对交通流预测有着重要影响,但大多预测模型都假定天气状况良好,忽略了环境数据的重要性,而这些环境数据可以更准确地评估交通网络状况。
因此,最近的研究调查了非交通数据集对城市交通流预测的影响,其中大部分(不是全部)被证明可以提高预测精度。这可以通过以下的事实来解释:以数据驱动的流量预测通常依赖于应用在历史数据观测的预测分析技术,以提取可用于预测未来观测的模式。由于城市交通流数据具有明显的季节性,周期性,因此这是非常有效的。一个善于从历史数据集识别和学习这些性质的模型将能够“熟练”预测未来的交通流状况。然而,在不寻常或不经常性的情况下,例如不能从历史观察中推断出的事故或事件,即使最精确的预测模型也会表现出较差的预测性能。非经常性或随机事件的典型例子包括车辆事故、车道关闭以及体育和公共事件。鉴于此类事件的突发性和随机性,有必要提出具有较强鲁棒性的预测模型以实现这种情况下的精准交通预测。
社交媒体作为一个在线讨论平台在过去几年呈现一个爆发式增长,例如,Facebook、Twitter、Instagram以及Snapchat等。这些服务被广泛应用于通讯、新闻报道以及广告活动。这些媒体平台都提供了应用程序编程接口(API)便于实现实时数据检索。Twitter作为一个公共社交媒体平台在短消息(多大280个字符)方面受到欢迎,因此使得与现实世界事件相关的信息可以高速、及时传播。由于Twitter拥有庞大的用户群,因此可以在Twitter上获取大量的信息,许多研究都试图利用这种在线数据存储库来实现各种数据挖掘目的,例如股票市场价格、犯罪率预测以及交通流量预测。通常来说,许多twitter用户报告了实时的交通流状况,道路使用者可以利用这些信息来推断未来的交通状况,并选择合适的出行方式。除了主要交通部门发布的推文之外,道路使用者还可以在各自的事件发送当前道路的交通状况,可以被挖掘以便推断未来交通状况。
因此,文章提出了一种城市交通流预测方法,除了交通和天气相关数据集以外,还利用了来自twitter的信息,其中包含了非周期性交通事故的信息。文章的贡献主要有以下两个方面:(1)通过经验评估,判断除了天气和交通流数据集以外,是否将推文数据纳入交通流预测;(2)提出了一个端到端的双向LSTM自编码的交通流预测模型,使用推特数据、天气数据以及交通流数据进行训练。使用来自英国曼彻斯特A56(切斯特路)的交通流数据、特定地理位置的推特数据以及天气数据集对提出的模型进行评估。值得注意的是,由于深度学习模型的训练时间较长,增加一个额外的数据源(tweets)可能会显著影响整个模型的计算需求。因此,文章为双向LSTM神经网络模型采用了一种自动编码器结构。该自动编码器可以作为降维组件,将输入向量降维到更低的维度,由此减小训练模型的时间。在顺序数据集中,包含考虑向后传播的双向结构可以将反向序列传递给LSTM模型,有可能提高预测精度。从直观上看,使用双向LSTM模型对城市交通流的预测应该会有所提高,因为它有时可能对“反向学习”数据很有用。比如,天气预报说明天会下雪,这可能会影响今天的交通,因为人们可能想要提前在今日出去购物,以避开明天恶劣天气。在文章提出的模型中,加入了双向LSTM来提高模型的预测性能。此外,由于城市交通数据集的高度复杂化和模式化结构,双向序列可能被证明是一种更具有鲁棒性的解决方案。
另外在利用推特数据进行交通流量预测中所遇到的一个重大挑战是确定非结构化数据集的真实性、准确性以及过滤高维噪声。
模型方法细节
文章首先描述了自动编码器,包含了底层逻辑和功能,然后提出了深度双向LSTM预测模型。自动编码器的主要优点是学习一组输入数据向量的压缩表示(编码)。换句话说,自动编码器可以实现短时间内对大量数据集进行训练,可以作为时间序列数据的降维技术和图像分析中的数据压缩工具。因此,与普通深度LSTM神经网络相比,使用LSTM自编码器可以在更短的时间内处理高维度的大数据。
lAutoencoders
自动编码器是一个前馈神经网络,它接受一个输入向量x,并将其转换为一个隐藏的表示或“潜在”空间h。换句话说,自动编码器对输入向量进行压缩到一个低维度的“编码”,并尝试从给定的表示中重建输出。自动编码器由三个主要组件组成:编码器、代码以及解码器。输入向量变换或者编码器函数,主要由以下公式实现:
![]()
其中,W和b分别表示隐藏权重和偏差成分,σ在代表sigmoid函数。解码器将得到的隐藏表示h转换为重构的特征空间y,公式如下:
![]()
其中![]() 和
和![]() 分别代表权重和偏置。堆栈自编码器是由一组自编码器堆叠而成,以无监督的方式学习。学习过程为逐层训练,为了最小化输入和输出向量之间的误差。自动编码器的后面一层是前一层的隐藏层,每一层都是由梯度下降算法使用一个优化函数进行训练的,这个优化函数为单个自动编码器层的平方重构误差J,公式如下:
分别代表权重和偏置。堆栈自编码器是由一组自编码器堆叠而成,以无监督的方式学习。学习过程为逐层训练,为了最小化输入和输出向量之间的误差。自动编码器的后面一层是前一层的隐藏层,每一层都是由梯度下降算法使用一个优化函数进行训练的,这个优化函数为单个自动编码器层的平方重构误差J,公式如下:
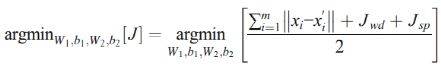
其中J表示单个自动编码器的平方重构误差,![]() 和
和![]() 分别代表输入向量第i个值及其对应的重构值。m代表训练集的大小,对应输入时间序列的长度。
分别代表输入向量第i个值及其对应的重构值。m代表训练集的大小,对应输入时间序列的长度。
lDeep bi-directional LSTMs
应用深度LSTM网络的显著优势在于可以逐层学习复杂数据结构中的长期依赖关系。与单层或双层LSTM网络相比,深层LSTM可以逐层提取复杂时间序列数据集中的时间相关性。
双向LSTM模型是由两个单向LSTM堆叠在相反方向组成的。因此在双向LSTM训练周期中要同时应用时间序列的前向量和后向量。通过这种方式,使用两个独立的隐藏层在两个方向上分别处理数据,然后前向传播到单个输出层。下图显示了双向LSTM的结构。从图片可以看出,网络同时计算前向隐藏序列![]() 以及反向隐藏序列
以及反向隐藏序列![]() 。然后,通过逆向时间逻辑顺序(即从t = T到1)迭代向后层来计算输出,而前向层则是从t = 1到T。如前所述,深度学习网络可以在复杂数据集中逐层构建层表示。深度双向LSTM模型是通过将多层双向LSTM垂直叠加而成。这样一来,前一层的输出序列就可以作为下一层的输入序列。
。然后,通过逆向时间逻辑顺序(即从t = T到1)迭代向后层来计算输出,而前向层则是从t = 1到T。如前所述,深度学习网络可以在复杂数据集中逐层构建层表示。深度双向LSTM模型是通过将多层双向LSTM垂直叠加而成。这样一来,前一层的输出序列就可以作为下一层的输入序列。
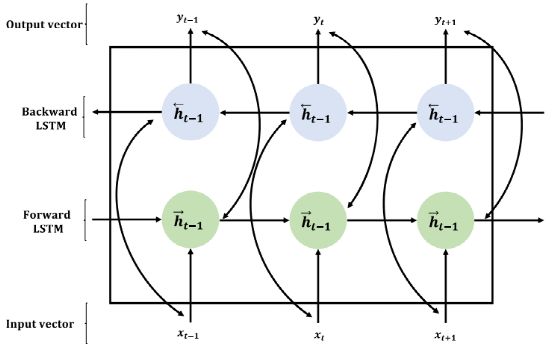
图1双向LSTM模型构架
lData fusion
数据融合是指对来自多个数据源的数据进行自动检测、集成、预测和组合的多层处理过程。现有文献中,主要存在5类数据融合过程:(1)数据输入-数据输出(DAI-DAO);(2)数据输入-特征输出(DAIFEO);(3)特征输入-特征输出(FEI-DEO);(4)特征不确定输出(FEI-DEO);(5)决策输入-决策输出(DEIDEO)。在文章的研究中,作者采用了DAI-DAO的数据融合技术,将交通和天气信息相结合在一起。如前所述,这融合数据技术避免了在特征或预测/决策级别融合时可能引入的错误,导致了更可靠的输出。
lDeep bi-directional LSTM model
下图描绘了文章提出模型的整体框架,该模型旨在预测t时刻未来12个时间步长的交通流量(12个5分钟的流量预测,即未来一个小时的交通流量)。文章的预测方法遵循双向LSTM模型,并以无监督的方式学习。该模型由编码器层、重复向量层、解码器层和全连接层四部分组成。
第一部分表示输入层,该层接收输入向量,包括流量、天气和tweet数据整合在一起,作为一个二维的m × n向量,其中m表示训练数据集中的样本数量,n表示特征数量(本例中为5个)。第二部分由双向LSTM层组成,共同构成编码器层。堆栈的双向LSTM读取输入的向量序列。读取最后一个序列之后,应用一个重复向量层,正如名称所暗示那样,该层复制了由编码器层所生成的向量序列。接着,解码器层由重复向量层获取输出序列,并将预测输出为单行向量序列并传递到全连接层,以预测目标序列。
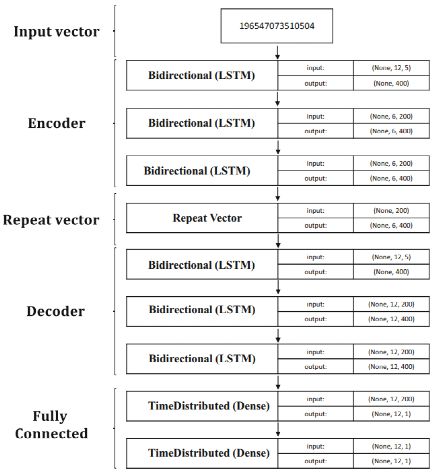
图2 整体模型体系结构
案例分析
本文所记录的实验数据集由曼彻斯特运输(TfGM)提供,时间由2016年4月1日到2017年4月16日。在研究期间获得的天气数据包括每小时对温度(摄氏度)和降水(以毫米为单位)的观测。推文数据来自两个(2)道路交通信息推特用户账户。这两个账号分别是TfGM (@OfficialTfGM) 和Waze Manchester (@WazeTrafficMAN) 的官方推特账号。
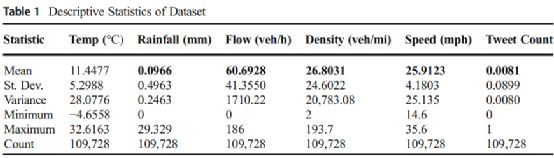
本研究采用重叠滑动窗口方法将输入的多元时间序列数据集重构为监督学习格式。因此,建立预测模型以学习历史时间序列数据集中的特征,利用表1所示的聚合数据集进行训练,进行多步提前1小时 (12步5分钟预测期)的交通流预测。
(1)Model Description
本模型集成了一个八层的双向LSTM堆栈式自动编码器体系结构。对于所有互连层(输出层除外),激活函数采用ReLU函数,可以将非线性引入学习过程。深度学习网络的性能取决于关键参数,这些参数必须通过超参数的优化预先确定。为了识别最优的超参数集,文章采用了网格搜索框架,这提供了一种可重复和灵活的方法以达到最佳的参数集。总体预测算法在算法1中表示。文章采用了增强深度双向LSTM流量预测模型提前预测12个时间步的交通流量(即以5分钟为一个时间步一共12个时间步,等于下一小时的交通流)。文章采用的深度学习具体方法步骤如表2。


关于评价指标的选取,文章选择了时序预测中常用的几个指标,即MAE、RMSE以及sMAPE,具体计算公式如下:
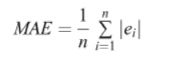
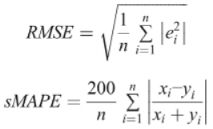
(2)Baseline models
文章比较了提出的模型与选定的最先进的基准机器学习模型的预测性能。使用上述的性能评估指标,将文章提出的模型与下面的基线模型进行比较。(1)Support Vector Regressor;(2)Extreme Gradient Boosting;(3)RandomForest regressor。
(3)Result
表3展示了文章所提出模型和基线模型的性能评价结果。如表所示,当使用推特、天气和交通数据集时,预测精度有显著提高。从图表中也可以看出,本文提出的模型优于传统的机器学习基准模型,但有较长训练时间。图6显示了各模型使用三种不同数据组合训练得到的效果指标MAE条形图。可以看出来,使用推特、天气和交通数据组合的模型进行训练获得了最低MAE。类似地,从表3可以看出,与文章提出模型的预测结果相比,SVR模型在预测效果方面比较有竞争力。xGBoosting算法返回的结果集最差,但训练时间最短。总之,与仅使用交通和天气数据集训练的模型相比,结果清楚表明了使用多个数据组合进行预测会有显著的改进(减少了误差)。尽管仅使用流量预测的模型训练时间最短,但它们却导致了更高的预测误差(MAE、RMSE和sMAPE)。这使得我们可以得出这样的结论:当在综合流量、天气和推文数据进行训练时,包含推文分析可以显著提高预测精度。
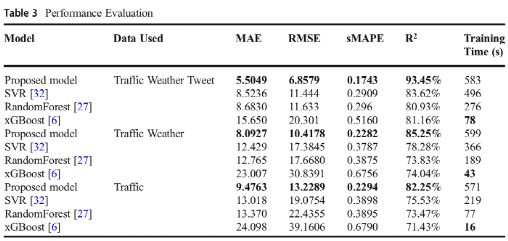
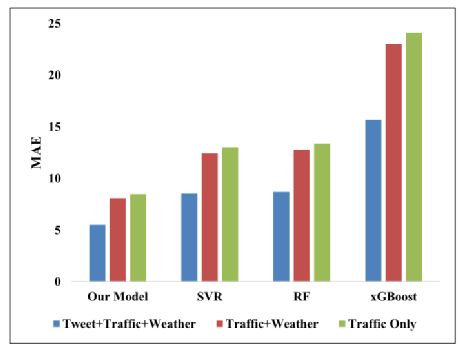
图6使用多种数据组合进行预测的各模型MAE指标
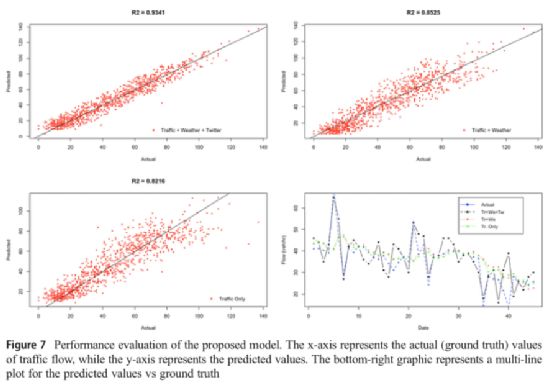
图7展示了表2中阶段3、4和5中描述的三个预测模型的预测值和实际观察值的散点图,其中x轴代表实际的交通流量值,y轴表示预测值。子图标题表示预测模型的![]() 值,从表3中可以推断出来。图7右下方的图是研究区在某一特定时段发生车道关闭时,各自模型的预测值与实际值的多重图,y轴表示交通流(vehicles / h),而x轴表示车道关闭后4天(48个时间步)内的5分钟时间步。从图中可以看出,只使用交通流数据或交通流和天气数据集进行训练的预测模型的准确性不如整合了交通流、天气以及推特数据的模型。
值,从表3中可以推断出来。图7右下方的图是研究区在某一特定时段发生车道关闭时,各自模型的预测值与实际值的多重图,y轴表示交通流(vehicles / h),而x轴表示车道关闭后4天(48个时间步)内的5分钟时间步。从图中可以看出,只使用交通流数据或交通流和天气数据集进行训练的预测模型的准确性不如整合了交通流、天气以及推特数据的模型。
相似地,图8显示了各个模型使用推特+流量+天气数据集训练的模型的前400个时间步的预测情况。对于每个子图,x轴表示时间步,每个子图上半部分的y轴表示车流量(veh/h),下半部分的y轴则表示预测值与实际值之间的绝对误差。从图8可以看出,本文提出的模型准确捕捉了时间模式,并且预测效果显著优于目前最先进的机器学习基准模型,同时SVR模型取得了第二好的预测效果。比较两个模型的计算时间,文章提出的模型耗时更久(即583s vs. 496s,大约增加了17%),而误差指标MAE大概降低了35.4%(即由8.5 veh/h降低到5.5 veh/h)。
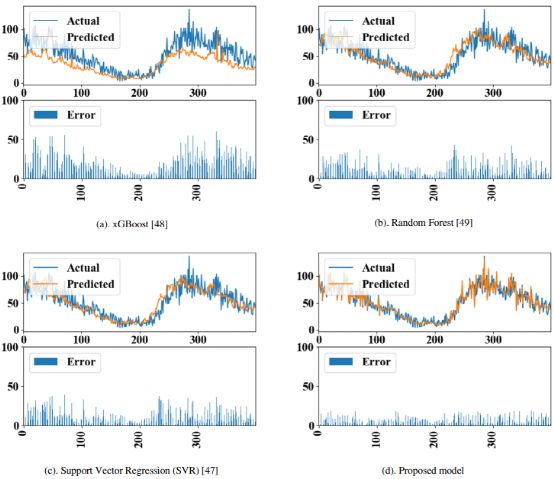
图8使用推特+交通+天气数据集进行预测的效果指标
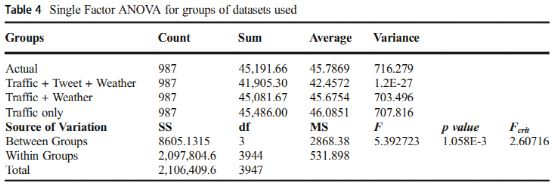
为了检验所得到结果集之间的统计显著性,文章进行了方差分析(ANOVA),比较了使用训练数据集推特数据+天气+交通流数据、天气+交通流数据以及交通流数据的预测结果的方差。使用方差分析检验以下假设:
![]()
其中,![]() 和
和![]() 表示分别使用tweet + traffic + weather、traffic only和traffic + weather从实际、模型中得到的平均估计。采用假设为0.05的显著性水平进行检验(p < 0.05)。表4展示了使用不同数据组合的预测值的单因素方差分析结果。如果
表示分别使用tweet + traffic + weather、traffic only和traffic + weather从实际、模型中得到的平均估计。采用假设为0.05的显著性水平进行检验(p < 0.05)。表4展示了使用不同数据组合的预测值的单因素方差分析结果。如果![]() 大于
大于![]() ,则拒绝原假设,即对应结果存在显著差异。从图表可以看出,
,则拒绝原假设,即对应结果存在显著差异。从图表可以看出,![]() =2.6072 <
=2.6072 < ![]() =5.3927,组间有显著性差异(p < 0.05),因此拒绝原假设。另外,组间p值展示了统计学意义,支持拒绝原假设的主张,因为p=0.001058 < 0.05。
=5.3927,组间有显著性差异(p < 0.05),因此拒绝原假设。另外,组间p值展示了统计学意义,支持拒绝原假设的主张,因为p=0.001058 < 0.05。
总结
文章提出了一种城市交通流预测模型,探讨了将来自推特数据的丰富信息整合到城市交通预测中的有效性,对现有的基于天气和交通数据集的城市交通预测模型进行了扩充。其提出的增广模型采用双向LSTM自动编码方法,可以接收来自道路交通信息Twitter账号@OfficialTfGM和@WazeTrafficMAN的地理特定推文。英国曼彻斯特的城市道路实验分析结果表明,除了交通、降雨和温度数据集,推特数据集的加入将MAE从8 veh/h降低到5.5 veh/h,提供了更准确的交通流预测模型。
尽管文章仅仅在一个数据集上进行实验,但使用模型来考虑大城市中其他城市道路时也可以整合一些额外的数据特征来运用文章提出的模型架构。例如,数据集、推特的定位以及推特数据源可以被修改以满足考虑,同时保留模型架构和组成。另一方面,还可以通过一些附加的数据特征来考虑道路之间的相关性。未来的工作将考虑对推文进行额外的过滤,并添加额外的关键字,以进一步提高预测模型的准确性和预测性能。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!