【机器学习】nce_loss
目录
一、前置知识
二、理论回顾
Logistic Regression
三、Noise Contrastive Estimation
举例
四、特别注意
五、NCE in tensorflow
一、前置知识
【机器学习】tf.nn.softmax
【机器学习】sampled softmax loss
因为我觉得nce loss是这几个里面最难理解的。Noise-contrastive estimation
nce loss 与 sampled softmax loss 到底有什么区别?怎么选择? - 我要给主播生猴子的回答 - 知乎
这个博主认为NCE loss的直观想法:把多分类问题转化成二分类。之前计算softmax的时候class数量太大,NCE索性就把分类缩减为二分类问题。之前的问题是计算某个类的归一化概率是多少,二分类的问题是input和label正确匹配的概率是多少。二分类问题群众喜闻乐见,直接上logistic regression估算一下概率。Sampled softmax则是只抽取一部分样本计算softmax。这个想法也很好理解,训练的时候我不需要特别精准的softmax归一化概率,我只需要一个粗略值做back propoagation就好了。
二分类问题:目标就是input和label正确匹配的概率越大越好。
文章的主要内容都是来自softmax的近似之NCE详解 — carlos9310,我觉得这里讲的更详细。
摘录下来,以防有一天这个网站失效了。(●ˇ∀ˇ●)
二、理论回顾
逻辑回归和softmax回归是两个基础的分类模型,它们都属于线性模型。前者主要处理二分类问题,后者主要处理多分类问题。事实上softmax回归是逻辑回归的一般形式。
Logistic Regression
逻辑回归的模型(函数/假设)为:

三、Noise Contrastive Estimation
softmax的假设函数可知,在学习阶段,每进行一个样本的类别估计都需要计算其属于各个类别的得分并归一化为概率值。当类别数特别大时,如语言模型中从海量词表中预测下一个词(词表中词即这里的类别)。用标准的softmax进行预测就会出现瓶颈。
NCE是基于采样的方法,将多分类问题转为二分类问题。以语言模型为例,利用NCE可将从词表中预测某个词的多分类问题,转为从噪音词中区分出目标词的二分类问题。具体如图所示:

用概率来表示,这个问题由之前的P(y|x) 通过x预测所有y,换成了P(x,y),计算x,y同时存在的概率。
下面从数学角度看看具体如何构造转化后的目标函数(损失函数)

上述损失函数中共有k+1个样本。可看成从两种不同的分布中分别采样得到的,一个是依据训练集的经验分布Ptrain每次从词表中采样一个目标样本,其依赖于上下文c;而另一个是依据噪音分布Q每次从词表中采样k个噪音样本(不包括目标样本)。基于上述两种分布,有如下混合分布时的采样概率:
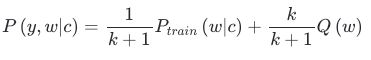
更进一步地,有


备注:NCE具有很好的理论保证:随着噪音样本数k的增加,NCE的导数趋向于softmax的梯度。 有研究证明25个噪音样本足以匹配常规softmax的性能,且有45X的加速。
提示:由上述描述可知,由于每一个目标词 w 往往会采样不同的噪音词,因此噪音样本及其梯度无法存储在矩阵中,从而无法进行矩阵乘法操作。有研究者提出可在小批量的目标词中共享噪音词,从而可利用矩阵运算加速NCE的计算。
举例
假设当前用户行为 abcd->e,
则正样本是e,负样本(召回时从其他用户点击中随机选择的)h、m、n。
共有(1+k)个样本。这里是(1+3)个样本。
就这一条,batchsize=1来说,损失函数如下:
四、特别注意
通俗易懂的NCE Loss
另外training和testing的时候,还不一样,在于:
training的时候我们使用nce loss,可以减少计算量,但testing的时候,我们通常使用sigmoid cross entropy,因为我们还是要衡量所有可能class的probability,在所有可能结果中做选择。
NCE解决了归一化项中(积分,或太多项和)无法计算的问题。
五、NCE in tensorflow
下面以训练词向量为例(完整代码见tensorflow词向量训练实战或https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/word2vec/word2vec_basic.py),详细解读下tensorflow中是如何实现nce_loss的。
先看看tensorflow的nce-loss的API:Tensorflow 的NCE-Loss的实现和word2vec
def nce_loss(weights, biases, inputs, labels, num_sampled, num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy="mod",
name="nce_loss")首先是图的构造,这里主要关注tf.nn.nce_loss这个函数的入参,具体说明见源码。
在调用tf.nn.nce_loss函数时,
只需关注正样本的标签id(labels)、
初始mini_batch的词向量(inputs)、
负样本个数(num_sampled)、
总样本个数,即词表大小(num_classes)
以及与NCE相关的两个参数weights、biases。
实际训练时,tensorflow内部会像上述描述的那样自动采集负样本,并使实际预测的某个词为正样本的概率较大,而为采集的多个负样本的概率较小。
假设nce_loss之前的输入数据是K维的,一共有N个类,那么
- weight.shape = (N, K)
- bias.shape = (N)
- inputs.shape = (batch_size, K)
- labels.shape = (batch_size, num_true)
- num_true : 实际的正样本个数
- num_sampled: 采样出多少个负样本
- num_classes = N
- sampled_values: 采样出的负样本,如果是None,就会用不同的sampler去采样。待会儿说sampler是什么。
- remove_accidental_hits: 如果采样时不小心采样到的负样本刚好是正样本,要不要干掉
- partition_strategy:对weights进行embedding_lookup时并行查表时的策略。TF的embeding_lookup是在CPU里实现的,这里需要考虑多线程查表时的锁的问题。
nce_loss的实现逻辑如下:
- _compute_sampled_logits: 通过这个函数计算出正样本和采样出的负样本对应的output和label
- sigmoid_cross_entropy_with_logits: 通过 sigmoid cross entropy来计算output和label的loss,从而进行反向传播。这个函数把最后的问题转化为了num_sampled+num_real个两类分类问题,然后每个分类问题用了交叉熵的损伤函数,也就是logistic regression常用的损失函数。TF里还提供了一个softmax_cross_entropy_with_logits的函数,和这个有所区别。
再来看看TF里word2vec的实现,他用到nce_loss的代码如下:
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels,
num_sampled, vocabulary_size))可以看到,它这里并没有传sampled_values,那么它的负样本是怎么得到的呢?继续看nce_loss的实现,可以看到里面处理sampled_values=None的代码如下:
if sampled_values is None:
sampled_values = candidate_sampling_ops.log_uniform_candidate_sampler(
true_classes=labels,
num_true=num_true,
num_sampled=num_sampled,
unique=True,
range_max=num_classes)所以,默认情况下,他会用log_uniform_candidate_sampler去采样。那么log_uniform_candidate_sampler是怎么采样的呢?他的实现在这里:
- 他会在[0, range_max)中采样出一个整数k
- P(k) = (log(k + 2) - log(k + 1)) / log(range_max + 1)
可以看到,k越大,被采样到的概率越小。那么在TF的word2vec里,类别的编号有什么含义吗?看下面的代码:
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0 # dictionary['UNK']
unk_count += 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary可以看到,TF的word2vec实现里,词频越大,词的类别编号也就越大。因此,在TF的word2vec里,负采样的过程其实就是优先采词频高的词作为负样本。
在提出负采样的原始论文中, 包括word2vec的原始C++实现中。是按照热门度的0.75次方采样的,这个和TF的实现有所区别。但大概的意思差不多,就是越热门,越有可能成为负样本。
没看的:
知乎:求通俗易懂解释下nce loss? - 知乎