对sklearn的DBSCAN代码的抽离和修改
最近在深入研究sklearn的DBSCAN代码,就想着能够把官方代码抽离出,进行自己的修改,加上自己的想法
PS:此时我还是没有系统学Python,或者说我目前还是不会Python的,如果有错误,欢迎指正
参考文献链接: link.
参考文献链接: link.
参考文献链接: link.
# -*- coding: utf-8 -*-
"""
DBSCAN: Density-Based Spatial Clustering of Applications with Noise
"""
# Author: Robert Layton 对于将官方代码的抽离,其实复制粘贴就行,然后改一下相关库的导入,但问题是这里面有个_dbscan_inner并不是正常的库,emm,如果你将代码弄成以下这样
import numpy as np
from scipy import sparse
from sklearn.base import BaseEstimator, ClusterMixin
from sklearn.utils import check_array, check_consistent_length
from sklearn.utils.testing import ignore_warnings
from sklearn.neighbors import NearestNeighbors
from _dbscan_inner import dbscan_inner
其实是会出问题的,主要是没有_dbscan_inner这个模块,你点击官方的_dbscan_inner也是不存在的,那么这个_dbscan_inner是什么呢?
于是我翻阅了大量资料,发现_dbscan_inner并不是用Python写的库,在网上也可以查到_dbscan_inner.pyx文件。
事情逐渐变得明朗,pyx文件是由 Cython 编程语言 “编写” 而成的 Python 扩展模块源代码文件,于是我去了Cython的官网以及查阅了大量的博客和文献,可能会有遗漏,就不一一列举了。(抱有严谨精神是应该列出来的)
如果想调用_dbscan_inner,想把它当作一个Python库一样调用,首先要把它转换成C/C++语言,然后合成Python的动态链接库。官方也有很多明确的说明
首先你得创建一个setup.py文件,使用这个文件来将_dbscan_inner.pyx文件转换成C/C++,然后再生成windows下的_dbscan_inner.pyd文件
# setup.py
from distutils.core import setup, Extension
from Cython.Build import cythonize
import numpy
setup(ext_modules = cythonize(Extension(
'_dbscan_inner',
sources=['_dbscan_inner.pyx'],
language='c++',
include_dirs=[numpy.get_include()],
library_dirs=[],
libraries=[],
extra_compile_args=[],
extra_link_args=[]
)))
这里本来想弄成C的,结果出了很多bug,于是就换成了C++成功了,哈哈。有点碰运气的成分。
运行如下命令 python setup.py build_ext --inplace
生成的文件
这个时候再Copy的源代码文件里面使用结果还是报错,但是我调用了这个文件结果发现是没问题的。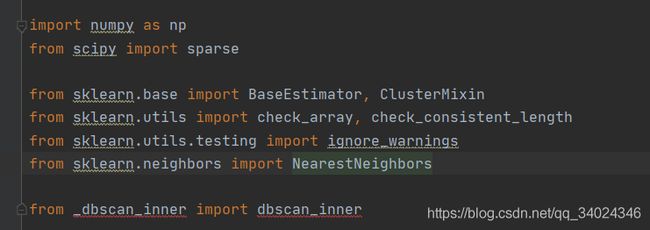
在这里导入的DBSCAN是我复制的一份代码,其实在这里你就会发现这篇博客的无聊之处。你可能会问,我花费这么多时间把官方的代码抽离出来有什么用,我直接调用不香吗?我也是这么想的。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from DBSCANtest import DBSCAN
X1, y1=datasets.make_circles(n_samples=5000, factor=.6,
noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]],
random_state=9)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()

加了一句话,用来验证DBSCANtest有没有正常运行,这样,你就可以对官方代码进行一些自己的修改了。或许作用就这点吧,探索的过程往往是最有意思的。